Command Palette
Search for a command to run...
Sélectionné Pour l'AAAI 2025 ! Il Peut Réaliser l'alignement Et La Fusion d'images Médicales multimodales. Deux Grandes Universités Nationales Ont Proposé Conjointement BSAFusion
Fin 2024, la 39e conférence annuelle de l'AAAI sur l'intelligence artificielle (AAAI 2025), la plus grande conférence internationale sur l'intelligence artificielle, a annoncé les résultats de l'acceptation des articles de cette conférence. Au final, sur les 12 957 soumissions reçues, un total de 3 032 articles se sont distingués et ont été inclus, avec un taux d'acceptation de seulement 23,4%.
dans,Un projet de recherche mené conjointement par Li Huafeng, Zhang Yafei, Su Dayong de l'École d'ingénierie de l'information et d'automatisation de l'Université des sciences et technologies de Kunming et Cai Qing de l'École d'informatique et de technologie du Département des sciences de l'information et de l'ingénierie de l'Université océanique de Chine——« BSAFusion : un réseau bidirectionnel d'alignement de fonctionnalités par étapes pour la fusion d'images médicales non alignées », a attiré l'attention des chercheurs en IA pour la science.Ce sujet se concentre sur le domaine du traitement d'images médicales, qui a connu un essor sans précédent ces dernières années, et propose une méthode de fusion d'images médicales non alignées par alignement bidirectionnel de caractéristiques par étapes (BSFA).
Par rapport aux méthodes traditionnelles, cette étude a permis d’aligner et de fusionner simultanément des images médicales multimodales non alignées grâce à une approche en une seule étape dans un cadre de traitement unifié. Il permet non seulement de coordonner les tâches doubles, mais réduit également efficacement le problème de complexité du modèle causé par l'introduction de plusieurs encodeurs de fonctionnalités indépendants.

Suivez le compte officiel et répondez « Images médicales multimodales » pour obtenir le PDF complet
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Focus médical — Fusion d'images médicales multimodales
La fusion d'images médicales multimodales (MMIF)Il s'agit de fusionner les données d'images médicales provenant de différentes méthodes d'imagerie, telles que la tomodensitométrie, l'IRM, la TEP, etc., pour générer de nouvelles images contenant des informations sur les lésions plus complètes et plus précises. Les recherches dans cette direction sont d’une grande valeur pour la médecine moderne et les applications cliniques.
La raison est simple. Après des décennies de développement et d’accumulation technologiques, l’imagerie médicale est non seulement devenue plus diversifiée dans ses formes, mais aussi de plus en plus largement utilisée. Par exemple, lorsque les gens font une chute importante, la première chose à laquelle ils pensent est d’aller à l’hôpital pour faire des « radiographies » afin de déterminer s’ils ont des fractures. « Prendre des radiographies » fait généralement référence à des examens d’imagerie médicale tels que les radiographies, la tomodensitométrie ou l’IRM.
Cependant, il ne suffit évidemment pas d'extraire suffisamment d'informations pour garantir l'exactitude du diagnostic clinique à travers une seule image médicale en médecine clinique, en particulier face à des maladies difficiles et compliquées, telles que les tumeurs, les cellules cancéreuses, etc. La fusion d'images médicales multimodales est devenue l'une des tendances importantes dans le développement de l'imagerie médicale moderne. La fusion d'images médicales multimodales intègre des images provenant de différentes époques et sources dans un seul système de coordonnées pour l'enregistrement, ce qui non seulement améliore considérablement l'efficacité du diagnostic des médecins, mais génère également des informations plus précieuses, qui peuvent aider les médecins à effectuer une surveillance plus professionnelle des maladies et à fournir des plans de traitement efficaces.
Avant l'application des images médicales, de nombreux chercheurs ont remarqué le problème de la fusion d'images et ont exploré davantage les méthodes permettant d'intégrer l'enregistrement et la fusion d'images multi-sources dans un cadre unifié, tel que le célèbre MURF. Il s’agit de la première méthode permettant de discuter et de résoudre l’enregistrement et la fusion d’images en une seule dimension. Ses modules principaux comprennent un module d'extraction d'informations partagées, un module d'enregistrement grossier multi-échelles et un module d'enregistrement fin et de fusion.
Cependant, comme mentionné ci-dessus, premièrement, ces méthodes ne sont pas conçues pour la fusion d’images médicales multimodales, et elles ne présentent pas les avantages attendus dans le domaine de l’imagerie médicale ; Deuxièmement, ces méthodes ne peuvent pas résoudre le défi le plus critique rencontré dans la fusion d’images médicales multimodales :Le problème d'incompatibilité entre les fonctionnalités utilisées pour la fusion et les fonctionnalités utilisées pour l'alignement.
Plus précisément, l’alignement des fonctionnalités nécessite que les fonctionnalités correspondantes soient cohérentes, tandis que la fusion des fonctionnalités nécessite que les fonctionnalités correspondantes soient complémentaires.
En fait, ce n’est pas difficile à comprendre. L'alignement des fonctionnalités consiste à réaliser la correspondance et la mise en correspondance de différentes données modales au niveau des fonctionnalités par divers moyens techniques ; tandis que la fusion de caractéristiques consiste à pouvoir exploiter pleinement la complémentarité entre différentes modalités, afin d'intégrer les informations extraites de différentes modalités dans un modèle multimodal stable.
On peut donc imaginer la difficulté pour le MMIF. Cette lacune doit non seulement être comblée par quelqu’un, mais doit également pouvoir s’appuyer sur le travail des prédécesseurs pour rendre la fusion d’images médicales multimodales plus efficace et plus pratique. Dans le journal,L'équipe du professeur Li Huafeng et celle du professeur associé Cai Qing ont toutes deux exprimé cette intention initiale et l'ont mise en pratique à travers des expériences de recherche.
D'un point de vue technique, cette méthode propose plusieurs conceptions à valeur innovante :
* Tout d'abord, en partageant l'encodeur de fonctionnalités, cette méthode résout le problème de la complexité accrue du modèle causée par l'introduction d'encodeurs supplémentaires pour l'alignement, et conçoit avec succès un cadre unifié et efficace qui intègre l'alignement et la fusion intermodaux des fonctionnalités, obtenant ainsi un alignement et une fusion transparents.
* Deuxièmement, la méthode de représentation des caractéristiques sans divergence modale (MDF-FR) est intégrée pour réaliser une intégration globale des caractéristiques en attachant une tête de représentation des caractéristiques de modalité (MFRH) à chaque image d'entrée, ce qui réduit considérablement l'impact des différences de modalité et de l'incohérence des informations multimodales sur l'alignement des caractéristiques.
* Enfin, une stratégie de prédiction du champ de déformation bidirectionnelle étape par étape basée sur l'indépendance du chemin de déplacement vectoriel entre deux points est proposée, ce qui peut résoudre efficacement les problèmes de grande portée et de prédiction inexacte du champ de déformation rencontrés dans la méthode d'alignement traditionnelle à une seule étape.
BSAFusion ouvre la voie à une nouvelle technologie pour la fusion d'images médicales
Le cadre d’enregistrement et de fusion d’images médicales multimodales en une seule étape proposé par l’équipe de recherche,Il se compose principalement de trois composants principaux, à savoir MDF-FR, BSFA et MMFF (Multi-Modal Feature Fusion).Les détails sont présentés dans la figure ci-dessous.
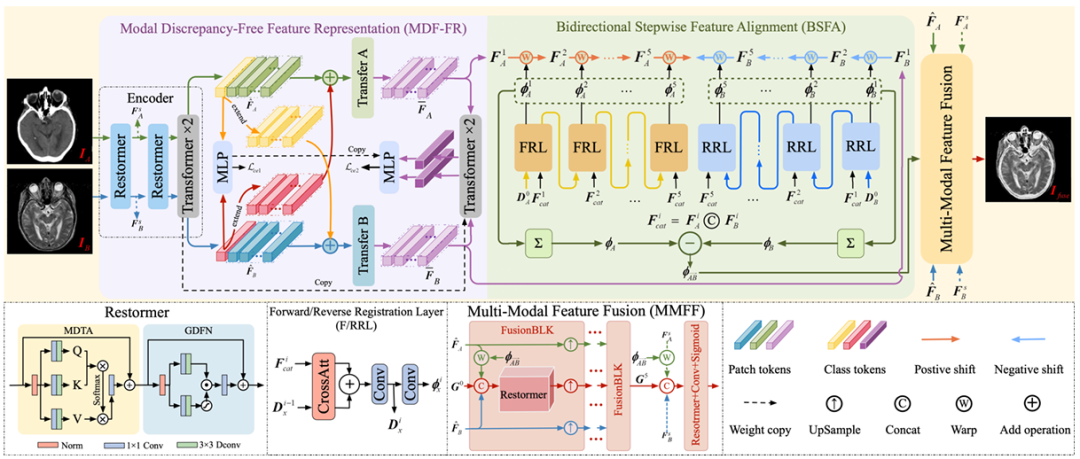
Il n’est pas difficile de voir que dans le MDF-FR,Les couches Restormer et Transformer forment l'encodeur du réseau pour extraire les caractéristiques des paires d'images non alignées, où Restormer et Transformer ont chacun deux couches. Après l'alignement et la fusion de deux fonctionnalités, les fonctionnalités sont entrées dans le MLP suivant pour obtenir les résultats de prédiction.
Ici, étant donné que les deux modalités sont très différentes, la correspondance intermodale et la prédiction du champ de déformation de ces caractéristiques seront également confrontées à de grands défis. Par conséquent, en générant des têtes de représentation de caractéristiques spécifiques à la modalité, nous pouvons réduire l'impact des différences de modalité sur la prédiction du champ de déformation et empêcher la perte d'informations non partagées en raison de l'extraction d'informations partagées.
Plus tard, l’équipe a continué à utiliser le transfert A et le transfert B pour éliminer les différences entre les modes. Chaque bloc de transfert est constitué de deux couches de transformateur, et aucun paramètre n'est partagé entre elles, afin d'extraire davantage les fonctionnalités nécessaires pour prédire le site de déformation.
En arrivant au BSFA,L'équipe de recherche a conçu un champ de déformation pour prédire les caractéristiques de l'image d'entrée à partir de deux directions - une méthode d'alignement des caractéristiques étape par étape bidirectionnelle. Une opération de prédiction de champ de déformation à cinq couches a été conçue pour les prédictions directes et inverses, correspondant aux cinq nœuds intermédiaires insérés entre les deux images sources d'entrée. Cette méthode améliore la robustesse globale du processus d’alignement. La couche responsable de l'enregistrement direct est FRL et la couche responsable de l'enregistrement inverse est RRL.
Enfin, dans le module MMFF,Le champ de déformation prédit est appliqué pour aligner les fonctionnalités, puis plusieurs modules FusionBLK sont utilisés pour fusionner les fonctionnalités. Enfin, l'image fusionnée est obtenue grâce à la couche de reconstruction et diverses fonctions de perte sont utilisées pour optimiser les paramètres du réseau.
Bien entendu, afin de garantir l’efficacité et la rigueur de l’expérience, l’équipe de recherche a soigneusement organisé les détails de l’expérience. Dans les expériences basées sur ce modèle, l’équipe de recherche a suivi le protocole des méthodes existantes.Les ensembles de données CT-MRI, PET-MRI et SPECT-MRI de Harvard ont été utilisés pour la formation du modèle.Ces ensembles de données se composent respectivement de 144, 194 et 261 paires d'images strictement enregistrées, et la taille de chaque paire d'objets est de 256 x 256.
Afin de simuler les paires d'images mal alignées collectées dans des scénarios réels, les images IRM sont spécialement spécifiées comme références dans cette expérience, et un mélange de déformations rigides et non rigides est appliqué aux images non IRM pour créer l'ensemble d'entraînement requis. De plus, l’équipe de recherche a également appliqué la même déformation à 20, 55 et 77 paires d’images strictement enregistrées pour construire un ensemble de tests non alignés.
Le processus de formation adopte une méthode de bout en bout, entraînant 3 000 époques sur chaque ensemble de données avec une taille de lot de 32. Dans le même temps, l'optimiseur Adam est utilisé pour mettre à jour les paramètres du modèle avec un taux d'apprentissage initial de 5 x 10⁻⁵. Utilisez un taux d'apprentissage de recuit cosinus (LR), qui diminue à 5 x 10⁻⁷ au fil du temps.
Les expériences ont utilisé le framework PyTorch et ont été formées sur un seul GPU NVIDIA GeForce RTX 4090.
S'appuyant sur les détails expérimentaux précis de l'équipe de recherche et sur les ensembles de données standard pour la formation, cette méthode a également démontré d'excellents résultats dans les expériences expérimentales.
Les objets de comparaison expérimentaux sont les cinq méthodes d'enregistrement conjoint les plus avancées, notamment UMF-CMGR, superFusion, MURF, IMF et PAMRFuse. À l’exception du dernier groupe, les quatre premiers ne sont pas spécialement conçus pour la fusion d’images médicales multimodales, mais ils constituent actuellement les meilleures méthodes de fusion d’images et conviennent au MMIF. Comme le montre la figure suivante :
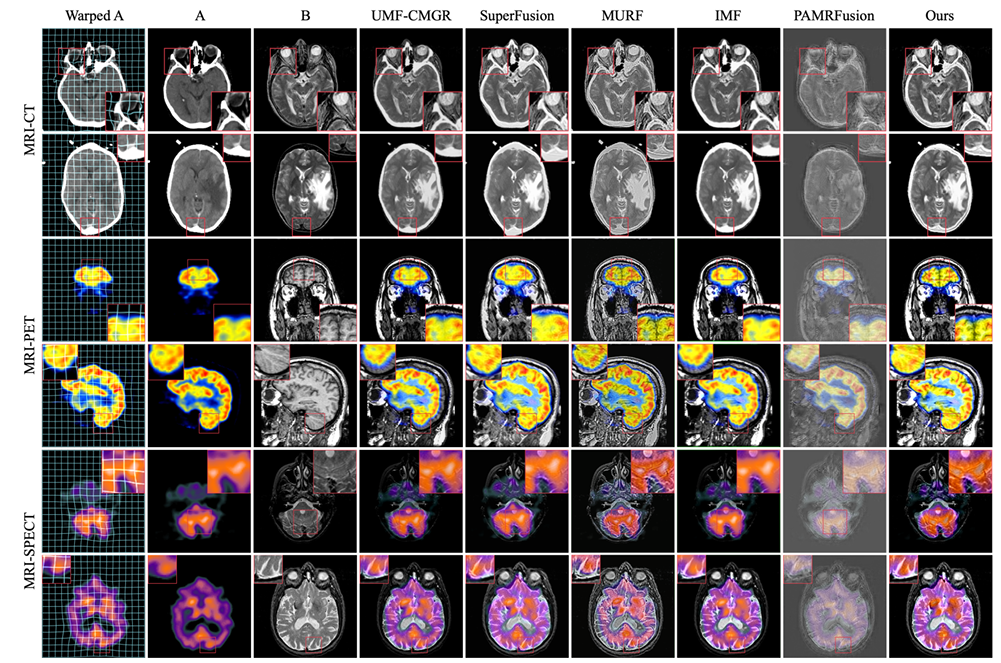
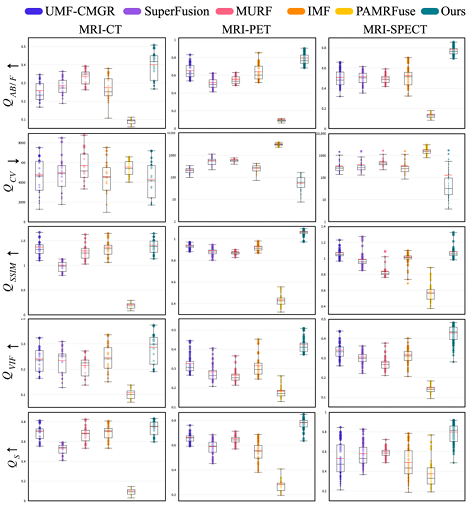
Les résultats sont évidents. La méthode proposée par l’équipe de recherche montre une plus grande supériorité en termes d’alignement des caractéristiques, de préservation du contraste et de rétention des détails, et présente la meilleure performance moyenne parmi tous les indicateurs.
Les équipes travaillent ensemble pour protéger les applications cliniques médicales
L'un des auteurs correspondants de ce sujet de recherche est Cai Qing, professeur associé de l'École d'informatique et de technologie, Faculté des sciences de l'information et de l'ingénierie, Université océanique de Chine. En plus de travailler à l'Université océanique de Chine, il occupe également des postes importants dans plusieurs institutions universitaires importantes telles que la Fédération informatique de Chine (CCF).
Les principaux domaines de recherche du professeur Cai Qing sont l’apprentissage profond, la vision par ordinateur et le traitement d’images médicales.La fusion d'images médicales multimodales, en tant que sous-domaine du traitement d'images médicales, présente une forte barrière de connaissances professionnelles, et les nombreuses années d'expérience de Cai Qing peuvent fournir des conseils et une assistance pour ce projet.
Il convient de mentionner qu'après que le professeur associé Cai Qing ait été le premier auteur d'un article sélectionné pour l'AAAI 2024 l'année dernière, il était cette année à nouveau le co-premier auteur et l'auteur correspondant, et un total de 3 projets de recherche ont été inclus dans l'AAAI 2025. Cela comprend une autre étude sur le traitement d'images médicales, intitulée « SGTC : Semantic-Guided Triplet Co-training for Sparsely Annotated Semi-Supervised Medical Image Segmentation ». Dans cet article, les chercheurs ont proposé un nouveau cadre de co-formation de triplets guidé sémantiquement, qui peut réaliser une segmentation fiable des images médicales en annotant seulement 3 tranches orthogonales d'un petit nombre d'échantillons de volume, résolvant ainsi le problème du processus d'annotation d'images long et laborieux.
Adresse du document :
https://arxiv.org/abs/2412.15526
L'autre équipe de ce projet est celle du professeur Li Huafeng et de Zhang Yafei de l'École d'ingénierie de l'information et d'automatisation de l'Université des sciences et technologies de Kunming.Parmi eux, le professeur Li Huafeng a été sélectionné dans la dernière liste des 21 meilleurs scientifiques TP3T au monde en 2021. Il est principalement engagé dans la recherche en vision par ordinateur, en traitement d'images et dans d'autres domaines. Un autre auteur correspondant de cet article, le professeur associé Zhang Yafei, dont les principaux domaines de recherche sont le traitement d'images et la reconnaissance de formes, a présidé de nombreux projets régionaux de la Fondation nationale des sciences naturelles de Chine et des projets généraux de la Fondation des sciences naturelles du Yunnan de Chine.
Le professeur Li Huafeng, l'un des principaux responsables universitaires de ce projet, a publié à de nombreuses reprises des recherches sur le traitement des images médicales, notamment une étude intitulée « Medical Image Fusion Based on Sparse Representation » dès 2017, et une étude intitulée « Feature dynamic alignment and refinement for infrared–visible image fusion: Translation robust fusion » en 2023.
Adresse du document :
https://liip.kust.edu.cn/servletphoto?path=lw/00000311.pdf
Adresse du document :
https://www.sciencedirect.com/science/article/abs/pii/S1566253523000519
En outre, Li Huafeng s'est associé à plusieurs reprises au professeur Zhang Yafei pour publier conjointement des recherches connexes, telles que la recherche publiée conjointement en 2022 intitulée « Medical Image Fusion with Multi-Scale Feature Learning and Edge Enhancement ». Dans cette étude, l’équipe a proposé un modèle de fusion d’images médicales basé sur l’apprentissage de caractéristiques multi-échelles et l’amélioration des contours, qui peut atténuer le problème des limites floues entre différents organes dans la fusion d’images médicales. Les résultats obtenus par la méthode proposée sont meilleurs que la méthode comparative tant en termes d’effets visuels subjectifs que d’évaluation quantitative objective.
Adresse du document :
https://researching.cn/ArticlePdf/m00002/2022/59/6/0617029.pdf
Comme le dit le proverbe, une alliance forte est impeccable. Les capacités académiques professionnelles du professeur Li Huafeng, de l'équipe de Zhang Yafei et du professeur associé Cai Qing dans le domaine du traitement d'images médicales sont sans aucun doute la clé du succès de ce projet. Nous espérons que la coopération entre les deux parties se poursuivra et que des résultats de pointe dans le domaine de l’IA pour la science continueront d’être publiés à l’avenir.
La fusion d'images médicales multimodales hybrides devient une tendance
La fusion d’images médicales multimodales jouant un rôle de plus en plus important, son développement technologique est voué à s’orienter vers l’intégration et l’intelligence.
Comme mentionné dans ce sujet, dans l’étude des méthodes de fusion basées sur l’apprentissage profond, les chercheurs ont remarqué que la méthode basée sur CNN et la méthode basée sur Transformer présentent des avantages complémentaires. C'est pourquoi certains chercheurs ont proposé DesTrans, DFENet et MRSC-Fusion. Ces études utilisent une approche hybride pour rendre complémentaires les avantages des deux technologies, améliorant ainsi l’efficacité de la méthode de fusion.
Outre les méthodes de fusion basées sur l'apprentissage profond, les méthodes de fusion d'images médicales multimodales incluent également les méthodes de fusion traditionnelles, telles que la transformation multi-échelle, la représentation clairsemée, les modèles basés sur le sous-espace, les caractéristiques saillantes, les modèles hybrides, etc. De même, des approches hybrides basées sur l'apprentissage profond + les méthodes traditionnelles ont également émergé.
À partir des tendances de recherche ci-dessus, nous pouvons voir queÀ l’avenir, la méthode de fusion d’images médicales multimodales montrera inévitablement une tendance de développement basée sur l’apprentissage profond comme courant dominant, tout en mélangeant une variété d’assistance technique.









