Command Palette
Search for a command to run...
Le Tutoriel Sur La Façon d'utiliser A6000 Avec Une Seule Carte Pour Démarrer AlphaFold3 En Un Clic Est Maintenant En Ligne ! Publication d'un Ensemble De Données De Capture De Mouvement À 360 Degrés, Comprenant Plus De 70 000 Vidéos Et 50 Objets Physiques

La semaine dernière, HyperAl a mis à jour la base de données de dépendances AlphaFold3, mais de nombreux amis ont signalé que les données étaient trop volumineuses et difficiles à déployer.
Cette semaine,Le site officiel hyper.ai a lancé la « démo de prédiction des protéines AlphaFold3 », les données et modèles pertinents ont été installés et configurés, occupant moins de 300 Mo de stockage personnel, et une seule carte A6000 est nécessaire pour déployer et utiliser rapidement AlphaFold3 pour prédire les protéines.
Utilisation en ligne :https://go.hyper.ai/KHIRR
Du 16 au 20 décembre, le site officiel hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec dates limites en janvier : 9
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de détection de drones
L'ensemble de données comprend plus de 10 000 images de drones avec des cadres de délimitation annotés autour de chaque drone. Les cadres de délimitation fournissent des informations de positionnement précises pour détecter et suivre les drones dans une variété d'arrière-plans et d'environnements. L'ensemble de données convient à la formation et à l'évaluation de modèles de vision par ordinateur pour les tâches de détection d'objets, en particulier dans des applications telles que la surveillance, la détection de drones et le suivi autonome.
Utilisation directe :https://go.hyper.ai/686JV

2. 360Motion-Dataset Ensemble de données de capture de mouvement
La version V1 de cet ensemble de données contient 72 000 vidéos couvrant 50 entités différentes, telles que divers animaux, et 6 scènes Unreal Engine (UE), dont 1 scène de désert et 2 scènes HDRI. En outre, l'ensemble de données contient également 121 modèles de trajectoire différents, fournissant aux chercheurs des modèles de mouvement riches et des changements de comportement.
Utilisation directe :https://go.hyper.ai/rsmeQ

3. Ensemble de données sur les tumeurs cérébrales
Cet ensemble de données est utilisé pour classer et segmenter les tumeurs cérébrales à l’aide de divers modèles. Il contient 7 153 images au total, dont 1 621 images de gliome, 1 775 images de méningiome, 1 757 images d'hypophyse et 2 000 images sans tumeur (cerveau sain).
Utilisation directe :https://go.hyper.ai/zgX7A
4. Ensemble de données de compréhension d'images de haute qualité à grande échelle LAION-SG
LAION-SG contient 540 005 paires de graphiques de scène-images avec des annotations d'objet, d'attribut et de relation, qui sont divisées en ensembles d'entraînement, de validation et de test. Les images de l'ensemble de données proviennent de l'ensemble de données LAION-Aesthetics V2 (6.5+) et le processus d'annotation utilise GPT-4o pour l'annotation automatique.
Utilisation directe :https://go.hyper.ai/HHT6V

L'ensemble de données contient 1 856 images avec 26 attributs vestimentaires de base, tels que des manches longues, un col et un motif rayé. Les étiquettes ont été collectées à l'aide d'Amazon Mechanical Turk.
Utilisation directe :https://go.hyper.ai/7f3ej

6. Détecter les visages générés par l'IA Ensemble de données de détection faciale
L'ensemble de données contient 3 203 images de haute qualité de visages réels et de visages synthétiques générés par l'IA, dont 2 202 images réelles et 1 001 images générées par l'IA, et est conçu pour les applications d'apprentissage automatique et d'apprentissage en profondeur. Son objectif est de fournir des ressources d’images faciales capables de distinguer les visages réels des visages générés par l’IA. Il convient aux tâches telles que la détection de faux renseignements profonds, la vérification de l'authenticité des images et l'analyse des images faciales, et peut prendre en charge la recherche et les applications de pointe.
Utilisation directe :https://go.hyper.ai/SwMXL

7. Ensemble de données de raisonnement mathématique U-MATH
L'ensemble de données contient 1,1 000 problèmes mathématiques de niveau universitaire non publiés dérivés de matériel pédagogique réel et couvre six sujets mathématiques de base : mathématiques élémentaires, algèbre, calcul différentiel, calcul intégral, calcul multivariable et suites et séries.
Utilisation directe :https://go.hyper.ai/FcNc2
8. Ensemble de données de réglage fin supervisé Open01-SFT
L'ensemble de données OpenO1-SFT est un ensemble de données qui se concentre sur l'activation de la capacité de chaîne de pensée des modèles de langage à l'aide de la méthode de réglage fin supervisé (SFT), visant à améliorer la capacité du modèle à générer des séquences de raisonnement logique cohérentes. Il contient 77 685 enregistrements, qui couvrent non seulement le chinois mais aussi l'anglais, ce qui rend l'ensemble de données utile dans les environnements multilingues.
Utilisation directe :https://go.hyper.ai/KlyzY
9. Ensemble de données de réglage fin QwQ-LongCoT-130K
L'ensemble de données QwQ-LongCoT-130K est un ensemble de données SFT (Supervised Fine-Tuning) conçu pour la formation de grands modèles de langage (LLM) comme O1. Cet ensemble de données contient environ 130 000 instances, chacune étant une réponse générée à l'aide du modèle QwQ-32B-Preview.
Utilisation directe :https://go.hyper.ai/kE9aG
10. Brevet ML dans les soins de santé
L'ensemble de données a été collecté à partir de Google Patents à l'aide de la requête de recherche « apprentissage automatique et soins de santé » et comprend des brevets accordés dans des domaines allant de l'imagerie médicale, des outils de diagnostic aux recommandations de traitement basées sur l'IA.
Utilisation directe :https://go.hyper.ai/8p1M5
Tutoriels publics sélectionnés
1. Démonstration de prédiction de la protéine AlphaFold3
AlphaFold3 est un outil d'intelligence artificielle (IA) développé en 2024 par Google DeepMind. Le modèle AlphaFold 3 utilise une architecture basée sur la diffusion qui peut non seulement prédire les structures des protéines, mais également prédire avec précision les structures des complexes, notamment les acides nucléiques, les petites molécules, les ions et les résidus modifiés.
Ce tutoriel présentera comment déployer et utiliser rapidement AlphaFold3 pour prédire les protéines. Vous n’avez besoin que d’une seule carte A6000 pour exécuter l’expérience.
Exécutez en ligne :https://go.hyper.ai/KHIRR
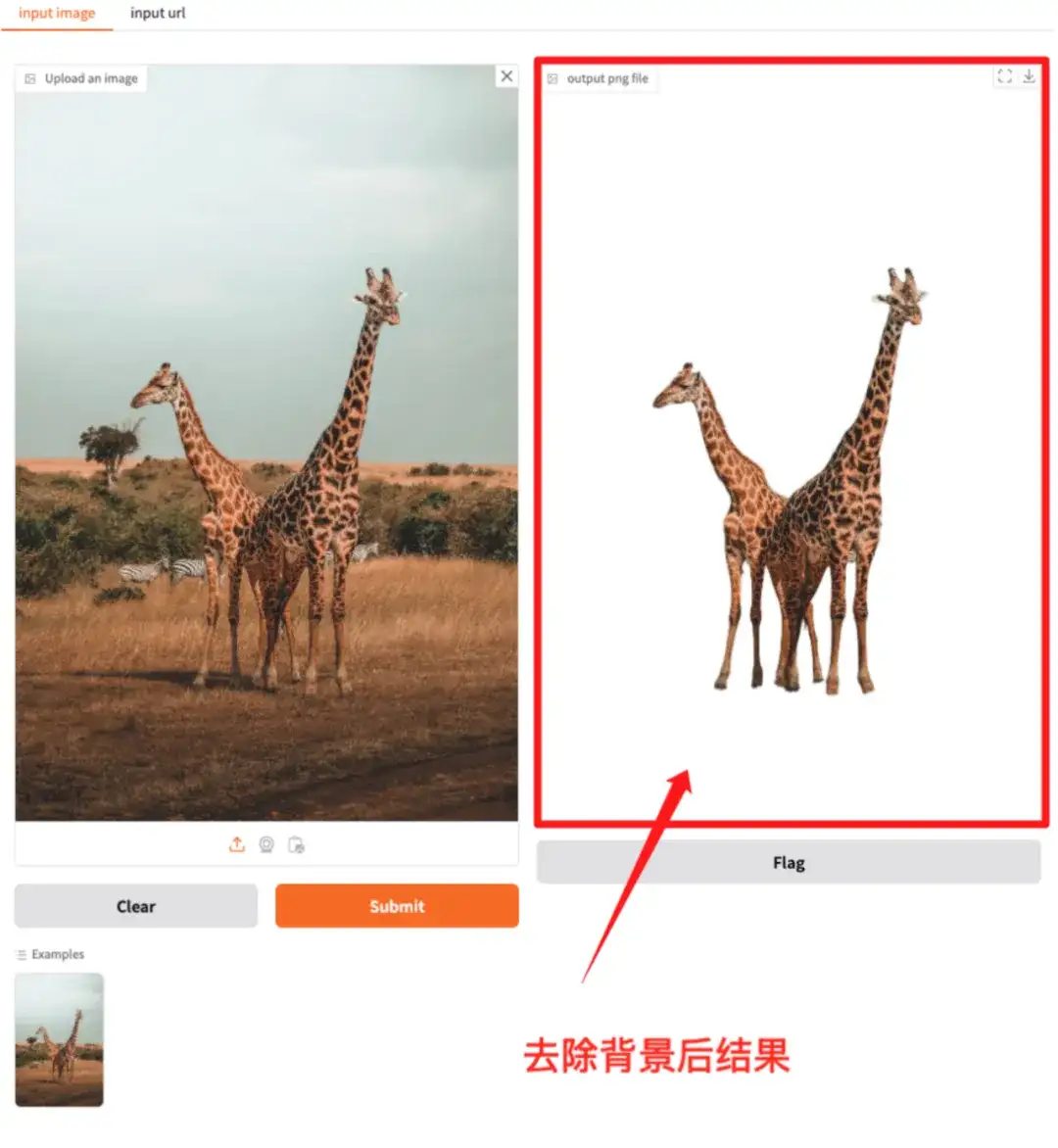
2. RMBG-2.0 : modèle de suppression d'arrière-plan open source
RMBG-2.0 est un modèle de soustraction d'arrière-plan open source conçu pour séparer efficacement le premier plan de l'arrière-plan dans une variété de catégories et de types d'images.
Le modèle a configuré l'environnement et les dépendances. Vous pouvez saisir l'adresse API pour expérimenter la découpe d'image en un clic.
Exécutez en ligne :https://go.hyper.ai/FF10L
3. DePLM : Optimisation des protéines avec des modèles de langage débruités (petits échantillons)
Le modèle de langage protéique débruité (DePLM) peut traiter les informations évolutives capturées par le modèle de langage protéique comme un mélange d'informations pertinentes et non pertinentes pour les propriétés cibles optimisées, où les informations non pertinentes sont considérées comme du « bruit » et éliminées, améliorant ainsi la précision du modèle dans la prédiction du paysage adaptatif des protéines et aidant à identifier la séquence fonctionnellement optimale pour l'optimisation.
Ce tutoriel concerne la formation et l'inférence du modèle de langage protéique de débruitage (DePLM) publié par l'Université du Zhejiang. Les résultats associés ont été sélectionnés pour « NeurIPS 24 ». La plateforme a configuré l’environnement et l’ensemble de données requis. Vous pouvez effectuer une formation et une inférence en exécutant directement les commandes données dans le didacticiel.
Exécutez en ligne :https://go.hyper.ai/ktd87
Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Articles de la communauté
Récemment, Enveda, une startup pharmaceutique spécialisée dans l'IA aux États-Unis, a annoncé avoir finalisé un financement de série C de 130 millions de dollars américains, portant le montant total du financement à 360 millions de dollars américains. De plus, fin octobre de cette année, ENV-294, le premier candidat médicament découvert à l'aide de la plateforme Enveda, a obtenu l'approbation IND de la FDA américaine et est entré dans la phase I des essais cliniques. Cet article est un rapport détaillé sur l'entreprise.
Voir le rapport complet :https://go.hyper.ai/rMk2U
En raison de la situation géographique particulière du plateau Qinghai-Tibet, les données sur le flux de chaleur de surface dans certaines zones accidentées sont très rares. Pour résoudre ce problème, l'École des sciences de la Terre de l'Université du Zhejiang a proposé un modèle de régression pondéré par réseau neuronal géographique avec une interprétabilité améliorée, qui fournit un nouveau cadre de recherche et un support technique pour une compréhension globale de la distribution du flux de chaleur et du mécanisme géodynamique du plateau Qinghai-Tibet. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/vqQDi
Lors de la cinquième diffusion en direct de Meet AI4S, Wang Zeyuan, doctorant au Knowledge Engine Laboratory de l'Université du Zhejiang, a partagé une réalisation sélectionnée pour NeurlPS 2024 et a fait une démonstration. Il a également présenté son expérience de soumission. Il regorge d'informations pratiques, alors cliquez pour le regarder rapidement.
Voir le rapport complet :https://go.hyper.ai/PLyBo
DeepMind et Google Research de Google ont publié un certain nombre de résultats dans le domaine des prévisions météorologiques, prenant en compte les prévisions à court, moyen et long terme, intégrant les méthodes traditionnelles à l'IA et construisant progressivement un « guerrier hexagonal » pour les prévisions météorologiques.
Voir le rapport complet :https://go.hyper.ai/Cvzkc
Articles populaires de l'encyclopédie
1. Fusion de tri réciproque RRF
2. Modélisation du langage masqué (MLM)
3. Norme nucléaire
4. Théorème de représentation de Kolmogorov-Arnold
5. Augmentation des données
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !








