Command Palette
Search for a command to run...
La Base De Données Dépendante d'Alphafold3 a Été Packagée Et Lancée ! Document De Partition Complet ICLR IC-Light : Identifier Avec Précision Les Caractéristiques Des Tons Clairs

AlphaFold2 a fait sensation dans le domaine de l'IA4S depuis sa sortie et a même remporté le prix Nobel de cette année. En tant que version améliorée, AlphaFold3 peut non seulement prédire la structure des protéines, mais également prédire la structure des interactions entre les protéines et diverses autres molécules biologiques, y compris la manière dont les ligands (petites molécules) et les acides nucléiques (ADN et ARN) se rassemblent et interagissent les uns avec les autres.
Le mois dernier, Google DeepMind a ouvert le code source des pondérations du modèle AlphaFold3 et de sa base de données de dépendances pour la recherche universitaire. HyperAl a maintenant lancé la base de données de dépendances AlphaFold3. Tout le monde est invité à découvrir les avancées technologiques apportées par AlphaFold3 en lisant l'article !
Utilisation en ligne :https://go.hyper.ai/wVItz
Du 9 au 13 décembre, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Sélection d'articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec dates limites en janvier : 9
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Alphafold3 dépend de la base de données
La base de données contient un grand nombre de bases de données de protéines et d'ARN sur lesquelles AlphaFold 3 s'appuie, dont 9 bases de données : BFD small, MGnify, PDB, PDB seqres, UniProt, UniRef90, NT, RFam et RNACentral.
Utilisation directe :https://go.hyper.ai/wVItz
2. Ensemble de données d'instructions de biomolécules à grande échelle Mol-Instructions
L'ensemble de données contient trois types d'instructions : des instructions orientées vers les molécules, des instructions orientées vers les protéines et des instructions textuelles sur les biomolécules. Son objectif est de fournir des données d’instructions riches pour améliorer la compréhension et les capacités de prédiction des grands modèles linguistiques dans le domaine des biomolécules.
Utilisation directe :https://go.hyper.ai/Gut1y
3. Conversion de texte conversationnel CoSQL en jeu de données SQL
CoSQL contient plus de 3 000 groupes de conversations, un total de plus de 10 000 requêtes SQL annotées, couvrant 200 bases de données, et les bases de données utilisées par différents groupes de données n'ont aucune intersection, afin d'examiner la robustesse du modèle.
Utilisation directe :https://go.hyper.ai/9Blzy

4. Ensemble de données de compréhension de lecture par raisonnement en plusieurs étapes QAngaroo
L'ensemble de données se compose de deux parties : WikiHop et MedHop, qui vise à construire une méthode de compréhension de lecture capable d'effectuer un raisonnement multi-sauts, c'est-à-dire que des faits dispersés dans différents documents nécessitent plusieurs étapes de raisonnement pour dériver de nouveaux faits.
Utilisation directe :https://go.hyper.ai/u1qRw

5. Ensemble de données sur les livres anciens de médecine traditionnelle chinoise
Cet ensemble de données contient environ 700 textes de médecine chinoise ancienne, couvrant les classiques médicaux de la dynastie pré-Qin à la fin de la dynastie Qing et à la République de Chine. Ces documents comprennent non seulement des théories médicales, des prescriptions, de la pharmacologie, etc., mais contiennent également de riches cas cliniques et des connaissances encyclopédiques médicales.
Utilisation directe :https://go.hyper.ai/8Vh6A
6. Sous-ensemble de données sur les soins de santé IndustryCorpus2
Cet ensemble de données est une bibliothèque de ressources de données de haute qualité spécifiquement destinée à la recherche et à l'application dans le domaine de la santé médicale. Il a subi un processus rigoureux de sélection et de nettoyage pour garantir l’exactitude et la fiabilité des données. Il couvre un large éventail de types de données dans le domaine de la santé, notamment les dossiers médicaux, la littérature médicale et les commentaires des patients, offrant aux chercheurs et aux développeurs une perspective complète pour explorer et innover.
Utilisation directe :https://go.hyper.ai/G9qn2
7. Ensemble de données de référence multilingue et multitâche P-MMEval
L'ensemble de données contient 3 ensembles de données de traitement du langage naturel (NLP) de base et 5 ensembles de données spécifiques aux capacités avancées, couvrant des tâches telles que la génération de code, la compréhension des connaissances, le raisonnement mathématique, le raisonnement logique et le suivi des instructions.
Utilisation directe :https://go.hyper.ai/qbzhv
8. Ensemble de données ShenNong TCM Ensemble de données ShenNong TCM
Cet ensemble de données contient plus de 110 000 données d’instructions, qui sont générées via une méthode d’auto-instruction centrée sur l’entité. Il se concentre sur les entités fondamentales et les différents scénarios d’intention dans le domaine de la médecine traditionnelle chinoise. Il peut non seulement améliorer la capacité du modèle à répondre aux questions liées à la médecine traditionnelle chinoise, mais également aider au diagnostic de la médecine traditionnelle chinoise et fournir des conseils médicaux personnalisés.
Utilisation directe :https://go.hyper.ai/Okruv
9. Ensemble de données de référence pour la génération de code DS-1000
L'ensemble de données contient 1 000 questions réelles sur la science des données provenant de StackOverflow, couvrant 7 bibliothèques de science des données largement utilisées en Python, telles que NumPy, Pandas, TensorFlow, etc.
Utilisation directe :https://go.hyper.ai/AL4h0
10. IndustryCorpus2-tourism-geography Ensemble de données géographiques touristiques
Cet ensemble de données est un sous-ensemble de l'ensemble de données de géographie touristique d'IndustryCorpus2, qui couvre un large éventail de types de données dans le domaine de la géographie touristique, y compris les introductions d'attractions, les guides de voyage, les critiques touristiques et les informations géographiques, offrant des scénarios d'application riches pour divers domaines de recherche et d'application tels que le traitement du langage naturel, l'apprentissage automatique, l'exploration de données et les systèmes de recommandation touristique.
Utilisation directe :https://go.hyper.ai/FIAM9
Tutoriels publics sélectionnés
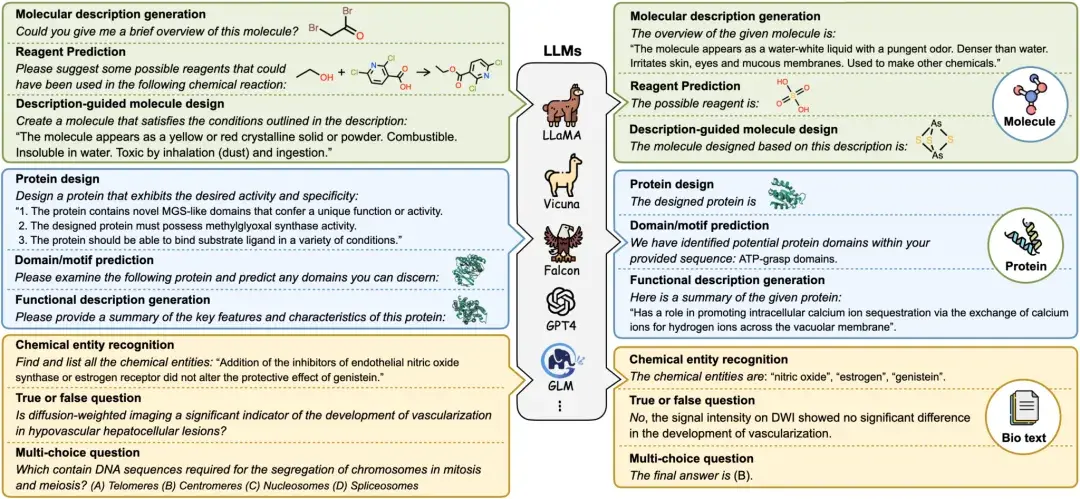
1. Démonstration de génération vidéo Allegro
Allegro a la capacité de convertir une entrée de texte de base en contenu vidéo haute définition, avec une résolution de 720p, 15 images par seconde et une durée vidéo maximale de 6 secondes. Le modèle démontre d’excellentes performances dans le domaine de la synthèse vidéo, excellant à la fois en qualité et en cohérence temporelle.
Ce tutoriel est un tutoriel d'inférence de modèle. Comme il faut beaucoup de temps au modèle pour générer une vidéo, ce tutoriel peut générer un effet vidéo de 5 secondes.
Exécutez en ligne :https://go.hyper.ai/MgUVZ
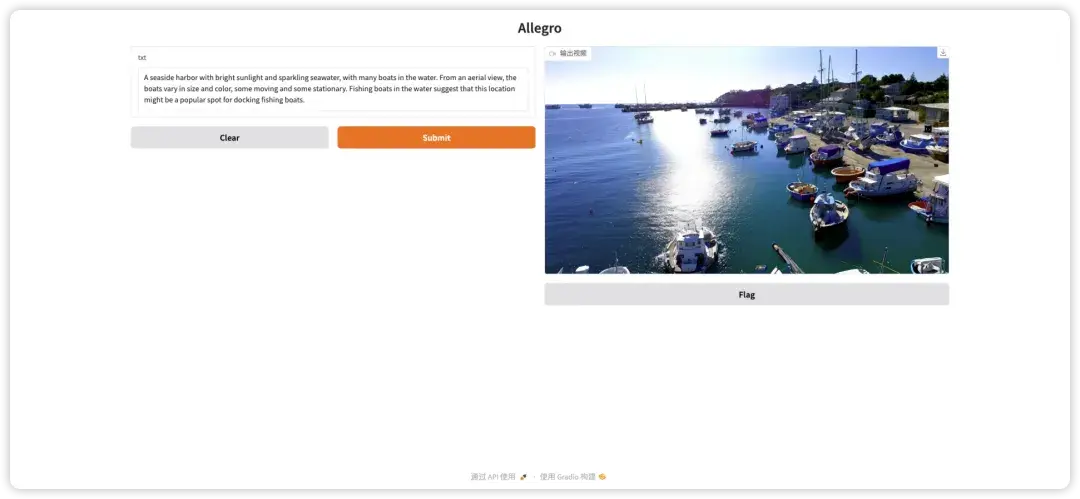
2. IC-Light v2 : démonstration de mise à niveau du contrôle d'éclairage par IA
IC-Light signifie Imposing Consistent Light, un projet qui vise à réaliser un rééclairage d'image grâce à des modèles d'apprentissage automatique. Ce tutoriel est une version améliorée d'IC-Light v2. Par rapport à l'IC-Light original, cette version est formée sur la base du modèle Flux, ce qui lui permet d'identifier plus précisément les caractéristiques d'éclairage et de tonalité de l'image et d'obtenir un effet de fusion plus détaillé et plus réaliste.
Cliquez sur le lien ci-dessous et suivez le tutoriel pour contrôler les effets d'éclairage de votre image.
Exécutez en ligne :https://go.hyper.ai/hg0cM
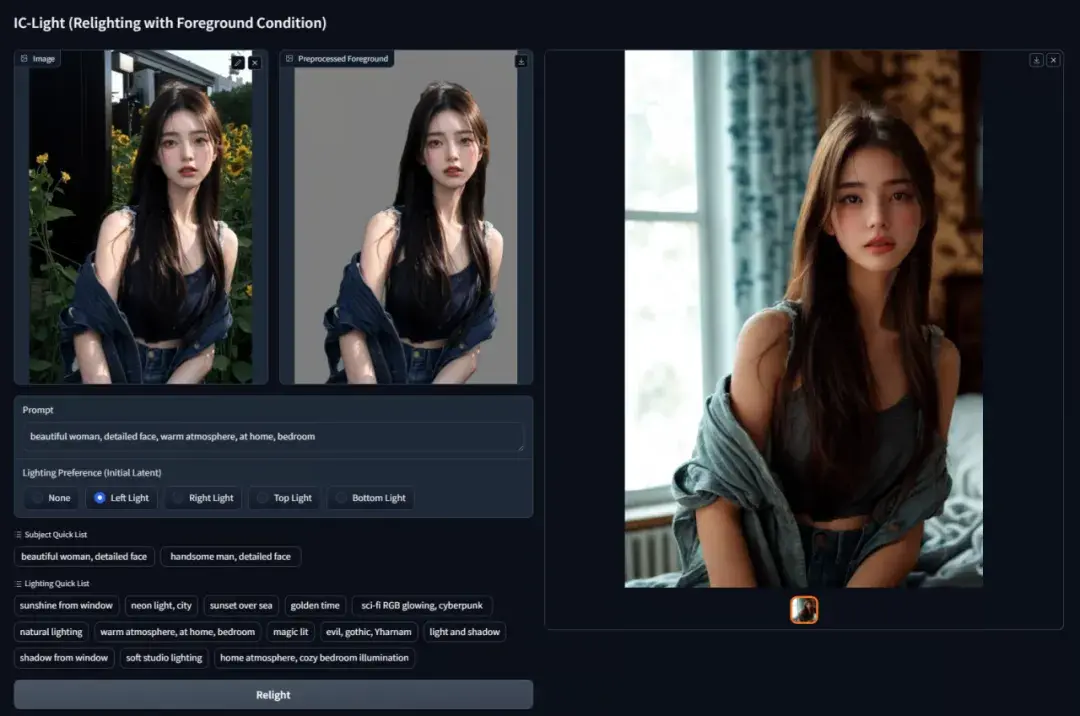
3. Hunyuan3D : générez des ressources 3D en seulement 10 secondes
Hunyuan3D est un modèle de diffusion générative 3D, comprenant une version allégée et une version standard, toutes deux prenant en charge la génération d'éléments 3D de haute qualité à partir d'entrées de texte et d'image. Après une évaluation multidimensionnelle qualitative et quantitative, Hunyuan3D-1.0 a obtenu de très bons résultats en termes de détails géométriques, de détails de texture, de cohérence texture-géométrie, de rationalité 3D et de conformité aux instructions.
Ce tutoriel est une version allégée de Hunyuan3D. Cliquez sur le lien ci-dessous et suivez les instructions du didacticiel pour découvrir la génération de modèles 3D.
Exécutez en ligne :https://go.hyper.ai/Rsrno
Articles de la communauté
En tant que startup, la force de CuspAI ne doit pas être sous-estimée. Son tour de financement d'amorçage a atteint 30 millions de dollars américains, devenant l'un des plus importants tours de financement d'amorçage en Europe cette année-là. En outre, l'expert en apprentissage automatique Max Welling est l'un des cofondateurs de l'entreprise, et Geoffrey Hinton, lauréat du prix Nobel et du prix Turing, est conseiller du conseil d'administration de son entreprise. Cet article est une introduction détaillée à CuspAI.
Voir le rapport complet :https://go.hyper.ai/3fQFG
Avec l’application généralisée de la technologie de l’IA dans notre vie quotidienne, « l’explicabilité » des modèles est progressivement devenue un problème qui doit être traité de toute urgence. Ce problème est particulièrement important dans les tâches de prévision de séries chronologiques. Afin de rendre la prédiction des séries chronologiques un processus « visible », l'équipe de Lu Feng de l'Université des sciences et technologies de Huazhong, en collaboration avec l'équipe de l'académicien Zomaya de l'Université de Sydney et de l'hôpital Tongji, a proposé une nouvelle méthode - CGS-Mask. En combinant la prédiction de séries chronologiques avec l’interprétabilité, cette méthode peut non seulement améliorer la précision de prédiction du modèle, mais également rendre les résultats de prédiction plus intuitifs et explicables. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/TFEsd
Une équipe de recherche de l'Université de Stanford et de l'Arc Institute aux États-Unis a proposé un modèle basé sur le génome, Evo, qui a été publié dans un article de couverture de Science. Il permet une prédiction zéro coup et une génération de haute précision dans les tâches multimodales d'ADN, d'ARN et de protéines. La section Tutoriel HyperAI Hyper-Neural est désormais en ligne « Evo : Prédiction et Génération de l'Échelle Moléculaire à l'Échelle Génomique », qui peut être rapidement expérimentée avec un clonage en un clic !
Voir le rapport complet :https://go.hyper.ai/5WPGm
Le parrain de l'IA, Hinton, est né dans une famille de génies, mais il était un décrocheur habituel ; sa start-up ne comptait que 3 personnes, mais a été rachetée par Google pour 44 millions de dollars ; il a passé près d'un demi-siècle à développer des réseaux neuronaux, mais a franchement exprimé des regrets... Quel genre d'expériences de vie a fait de lui ce qu'il est aujourd'hui ? Cet article est un rapport approfondi sur Hinton.
Voir le rapport complet :https://go.hyper.ai/EHWs6
vLLM est un framework conçu pour accélérer le raisonnement de grands modèles de langage, obtenant une perte quasi nulle de mémoire cache KV. La dernière version v0.6.4 introduit la planification en plusieurs étapes et le traitement de sortie asynchrone, optimisant davantage l'utilisation du GPU et améliorant l'efficacité du traitement. Afin d'aider les développeurs nationaux à en savoir plus sur les mises à jour de la version vLLM et les développements de pointe, la communauté HyperAI Super Neural a terminé la localisation de la documentation chinoise de vLLM.
Voir la documentation chinoise de vLLM :https://vllm.hyper.ai/
Articles populaires de l'encyclopédie
1. MFCC Mel Cepstrum
2. Fusion de tri réciproque RRF
3. Modélisation du langage masqué (MLM)
4. Front de Pareto
5. Augmentation des données
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








