Command Palette
Search for a command to run...
Prédire Avec Précision Le Taux De Chômage Et Le Taux De Pauvreté Aux États-Unis. Le Modèle De Base De La Dynamique De Population PDFM De Google a Été Rendu Open Source Pour Améliorer Les Modèles Géospatiaux Existants

Maladies, crises économiques, chômage, catastrophes... le monde humain est depuis longtemps « envahi » par divers problèmes.Comprendre la dynamique des populations est essentiel pour résoudre des problèmes sociaux complexes comme ceux-ci.Les responsables gouvernementaux peuvent utiliser les données de dynamique démographique pour simuler la propagation des maladies, prédire les prix des logements et les taux de chômage, et même prédire les crises économiques. Cependant, prédire avec précision la dynamique des populations a été un défi pour les chercheurs et les décideurs politiques au cours des dernières décennies.
Les approches traditionnelles de compréhension de la dynamique des populations s’appuient souvent sur des données de recensement, d’enquête ou d’imagerie satellite. Bien que ces données soient précieuses, elles présentent chacune leurs propres défauts. Par exemple, les recensements, bien que complets, sont peu fréquents et coûteux à réaliser ; les enquêtes peuvent fournir des informations locales, mais manquent souvent d’échelle et d’ubiquité ; L’imagerie satellite offre un aperçu général mais manque d’informations détaillées sur les activités humaines. Pour compenser ces lacunes, Google a constitué au fil des ans des ensembles de données massifs dans l’espoir de comprendre le comportement démographique.
Récemment, Google a proposé un nouveau modèle de base de dynamique de population (PDFM), qui utilise l’apprentissage automatique pour intégrer les riches données géospatiales disponibles dans le monde entier, élargissant considérablement les capacités des modèles géospatiaux traditionnels.Les chercheurs ont évalué le PDFM sur des problèmes d’interpolation, d’extrapolation et de super-résolution dans 27 tâches couvrant la santé, la socio-économie et l’environnement. L’étude a révélé que le PDFM a atteint des performances de pointe en matière d’interpolation pour les 27 tâches et dans 25 des tâches d’extrapolation et de super-résolution.Les chercheurs ont également démontré que le PDFM peut être combiné avec un modèle de base de prévision de pointe (TimesFM) pour prédire avec succès les taux de chômage et de pauvreté, surpassant les méthodes de prévision entièrement supervisées.
La recherche connexe a été publiée sur arXiv sous le titre « Inférence géospatiale générale avec un modèle de base de dynamique de population ». Dans le même temps, les chercheurs ont publié toutes les intégrations PDFM et les exemples de codes sur GitHub pour permettre à la communauté de recherche de les appliquer à de nouveaux cas d'utilisation et de renforcer davantage la recherche et la pratique universitaires.
Adresse open source du projet PDFM :
https://github.com/google-research/population-dynamic
Points saillants de la recherche :
* Les chercheurs ont introduit une architecture d'intégration découplée qui partitionne la dimension d'intégration par source de données, garantissant que le modèle peut prendre en charge toutes les entrées et conserver les informations pertinentes pour chaque donnée, tout en offrant une interprétabilité au niveau de la source de données pour les tâches en aval
* Les chercheurs ont démontré comment le PDFM peut être utilisé pour améliorer TimesFM, un modèle de base de prévision de pointe, afin d'améliorer les prévisions des taux de chômage au niveau du comté et des taux de pauvreté au niveau du code postal. Des approches similaires peuvent également être utilisées pour améliorer d’autres modèles de classification et de régression géospatiale existants à l’aide d’intégrations PDFM.
* Grâce à de solides performances dans les tâches d'interpolation, d'extrapolation, de super-résolution et de prédiction, les chercheurs ont démontré que le PDFM peut être facilement étendu à une variété de scénarios d'application nécessitant une modélisation géospatiale, notamment la recherche scientifique, le bien-être public, la santé publique et environnementale et les domaines commerciaux.

Adresse du document :
https://arxiv.org/abs/2411.07207
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Ensembles de données : cinq ensembles de données courants
Pour développer le PDFM, les chercheurs ont collecté et organisé cinq grands ensembles de données couvrant des zones géographiques aux niveaux du code postal et du comté :
1 Tendances de recherche agrégées :Les chercheurs ont calculé le nombre total de requêtes pour les 500 premières requêtes en juillet 2022, nécessitant au moins 20 recherches dans chaque zone de code postal, ce qui a donné lieu à plus d'un million de requêtes uniques. Ces requêtes ont ensuite été classées par popularité nationale, mesurée par le nombre total de codes postaux dans lesquels chaque requête apparaissait, à partir desquels les 1 000 requêtes les plus courantes ont été sélectionnées comme représentatives de l'activité de tendance de recherche globale au niveau du code postal à travers le pays.
2 Ensemble de données cartographiques (cartes) :Les chercheurs ont sélectionné les 1 192 catégories de points d'intérêt les plus courantes dans Google Maps en mai 2024 qui apparaissaient dans au moins le code postal de 5%. Chaque catégorie couvre un large éventail de points d’intérêt ; par exemple, la catégorie « Établissements médicaux » comprend les hôpitaux pour enfants et les hôpitaux universitaires. Il a ensuite calculé le nombre total d’établissements disponibles dans chaque limite géographique et a généré un vecteur de caractéristiques normalisé de 1 192 dimensions au niveau du code postal et du comté.
③ Ensemble de données sur l'activité :Pour chaque catégorie de points d’intérêt dans les données cartographiques, les chercheurs ont calculé la somme des visites aux lieux pertinents dans ces catégories au cours d’un mois pour résumer l’activité de ces catégories.
④ Météo et qualité de l'air :Les chercheurs ont collecté des données météorologiques et de qualité de l’air et ont résumé les données horaires pour juillet 2022, en les décrivant à l’aide de valeurs moyennes, minimales et maximales. La liste complète des variables comprend : la pression moyenne au niveau de la mer, la couverture nuageuse totale, la composante U du vent à 10 m, la composante V du vent à 10 m, la température à 2 m, la température du point de rosée à 2 m, le rayonnement solaire, le taux de précipitation total, l'indice de qualité de l'air, la concentration en monoxyde de carbone, la concentration en dioxyde d'azote, la concentration en ozone, la concentration en dioxyde de soufre, la concentration en particules respirables (<10 μm), la concentration en particules fines (<2,5 μm).
⑤ Télédétection :Les chercheurs ont combiné les données d'intégration d'images satellite générées à partir de la version ViT16-L40 du modèle SatCLIP pour obtenir des intégrations indexées par le centroïde de chaque code postal. Le modèle SatCLIP est conçu pour être un géocodeur utilisable à l'échelle mondiale et regroupe 100 000 tuiles à partir d'images satellite Sentinel-2 du 1er janvier 2021 au 17 mai 2023.
Les chercheurs ont combiné l'ensemble de données avec une architecture de réseau neuronal graphique (GNN) pour former un modèle de base qui génère des intégrations générales plutôt que spécifiques à une tâche.
Architecture du modèle : utiliser GNN pour résoudre les problèmes géospatiaux de manière efficace et intuitive
La construction du modèle PDFM est illustrée dans la figure ci-dessous : Dans la phase 1,Les chercheurs ont combiné l'ensemble de données avec l'architecture du réseau neuronal graphique (GNN) pour former un modèle de base qui génère des intégrations générales plutôt que spécifiques à une tâche.En phase 2,À l'aide de ces intégrations et de données de vérité terrain spécifiques pour la tâche à accomplir, un modèle en aval (tel qu'une régression linéaire, un perceptron multicouche simple ou un arbre de décision boosté par gradient) est appris, qui peut être appliqué à une variété de tâches, notamment l'interpolation, l'extrapolation, la super-résolution et la prévision.
* Tâche d'interpolation : consiste à déduire et à renseigner les valeurs de points de données inconnus en fonction des valeurs de points de données connus
* Tâches d'extrapolation : Extrapoler des données ou des expériences existantes pour prédire des situations, des tendances ou des résultats au-delà de la portée connue actuelle
* Tâche de super-résolution : fait référence au processus de mise à niveau d'images ou de données à basse résolution vers des images ou des données à haute résolution via des algorithmes
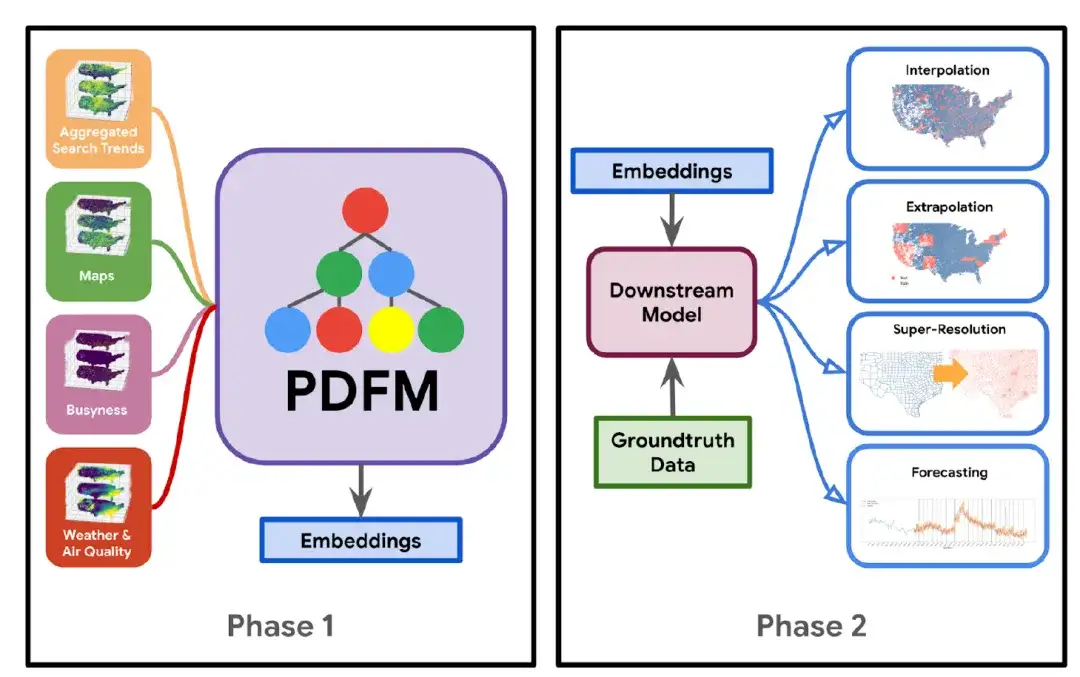
Plus précisément, le cœur du modèle PDFM est le réseau neuronal graphique (GNN), qui code les positions intégrées dans des vecteurs numériques de faible dimension riches en informations. Il se compose principalement des cinq parties suivantes :
* Construction du graphique :Les chercheurs ont construit un graphique géospatial hétérogène en utilisant les comtés et les codes postaux comme nœuds et en établissant des limites grâce à des relations de voisinage. Le graphique géospatial construit comporte un ensemble homogène de nœuds, traitant les nœuds de niveau code postal et comté comme le même type d'ensemble de nœuds, et un ensemble hétérogène d'arêtes, avec différents types d'arêtes reliant les nœuds.
* Échantillonnage de sous-images :L'échantillonnage de sous-graphes est effectué pour créer des sous-graphes pour la formation de GNN à grande échelle et ajouter du caractère aléatoire au modèle. Il démarre à partir d'un nœud d'amorçage, traverse chaque ensemble d'arêtes de manière privilégiant la largeur, échantillonne un nombre fixe de nœuds de manière pondérée et se termine lorsqu'il atteint quatre sauts.
Plus précisément, les chercheurs sont partis d'un nœud d'amorçage, ont parcouru chaque ensemble de bords en largeur, ont échantillonné un nombre fixe de nœuds de manière pondérée et ont terminé lorsque la distance de quatre sauts a été atteinte. Cette approche génère un nombre de sous-graphes égal au nombre total de nœuds au niveau du code postal et du comté.
* Prétraitement :La normalisation par colonne est appliquée à toutes les fonctionnalités et les extrémités de la plage de valeurs des fonctionnalités sont compressées par découpage.
* Détails de modélisation et de formation :GraphSAGE (une méthode inductive) est adopté pour apprendre les intégrations de nœuds en exploitant les informations sur les caractéristiques des nœuds. GraphSAGE apprend une fonction pour générer des intégrations à partir d'informations d'agrégation de voisinage local. Pour l'architecture d'agrégation, l'architecture de pooling proposée dans GraphSAGE est utilisée, dans laquelle les états des nœuds des nœuds voisins sont transmis via une couche entièrement connectée avec transformation ReLU, et les anciens états transformés et les états des nœuds voisins sont ensuite agrégés par sommation élément par élément. Les chercheurs ont utilisé l'architecture GraphSAGE pour faciliter le passage de messages en une seule fois, en ajoutant une couche linéaire de taille 330 après la couche GNN pour encoder la représentation au niveau du nœud dans une intégration compressée.
* Réglage des hyperparamètres :L'ensemble de validation est échantillonné uniformément à partir des nœuds de départ de 20% (y compris les comtés et les codes postaux) pour former les hyperparamètres de réglage, y compris le taux d'abandon, la taille des intégrations de nœuds, le nombre d'unités et de couches cachées GraphSAGE, la taille d'intégration, la régularisation et le taux d'apprentissage.
Résultats de recherche : Excellentes performances dans les tâches d'interpolation, d'extrapolation, de super-résolution et de prédiction
PDFM est un cadre de modélisation fondamental flexible qui peut répondre à une variété de défis géospatiaux aux États-Unis continentaux. En intégrant divers ensembles de données, le PDFM est intégré dans 27 tâches sanitaires, socioéconomiques et environnementales, surpassant les méthodes d'encodage de localisation de pointe (SoTA) existantes telles que SatCLIP et GeoCLIP.
Dans les tâches d’interpolation, PDFM fonctionne bien sur les 27 tâches ; dans les tâches d'extrapolation et de super-résolution, il est en tête dans 25 tâches. De plus, les chercheurs ont démontré comment les intégrations PDFM peuvent améliorer les performances des modèles de prévision tels que TimesFM, améliorant ainsi les prévisions d'indicateurs socio-économiques importants tels que les taux de chômage au niveau du comté et les taux de pauvreté au niveau du code postal.Cela met en évidence son large potentiel d’application dans la recherche, le bien-être social, la santé publique et environnementale et les entreprises.
Les résultats expérimentaux spécifiques sont les suivants :
1 Expérience d'interpolation
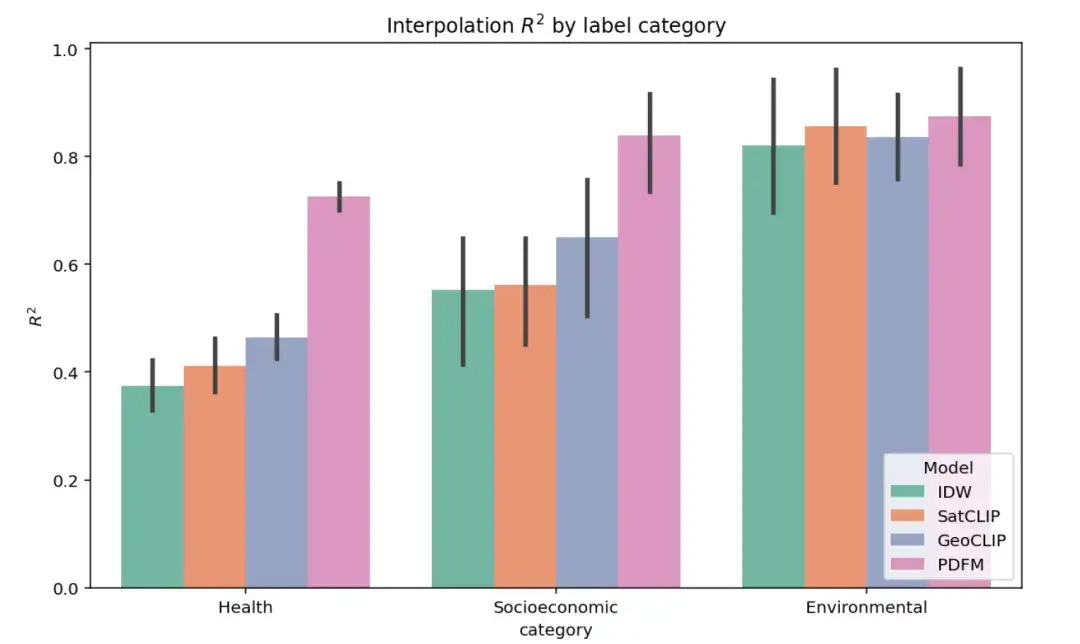
La figure ci-dessous montre les résultats de l’expérience d’interpolation complète sur 27 tâches dans trois catégories : Santé, Catégorie socio-économique et Environnement. La performance des différents modèles est évaluée à l’aide de l’indicateur ² (une valeur plus élevée indique que le modèle explique mieux la variance de l’étiquette de la variable cible). Comme le montre la figure, PDFM surpasse considérablement SatCLIP et GeoCLIP dans les catégories de tâches socioéconomiques et de santé.
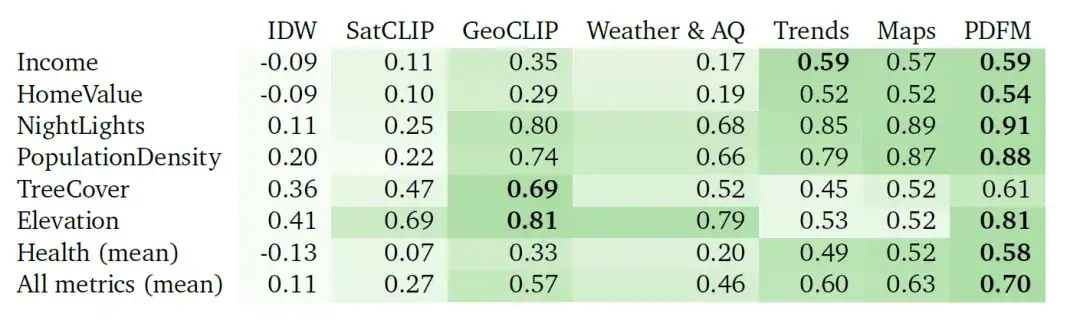
Le tableau ci-dessous montre dans quelle mesure le PDFM interpole sur 27 tâches de santé, socioéconomiques et environnementales, telles que le revenu, la valeur du logement, les lumières nocturnes, la densité de population, la couverture arborée, l'altitude et la santé (moyenne). Le PDFM surpasse systématiquement les autres, avec une moyenne de 0,83 au carré sur les 27 tâches, dont une moyenne de 0,73 au carré pour 21 tâches liées à la santé.
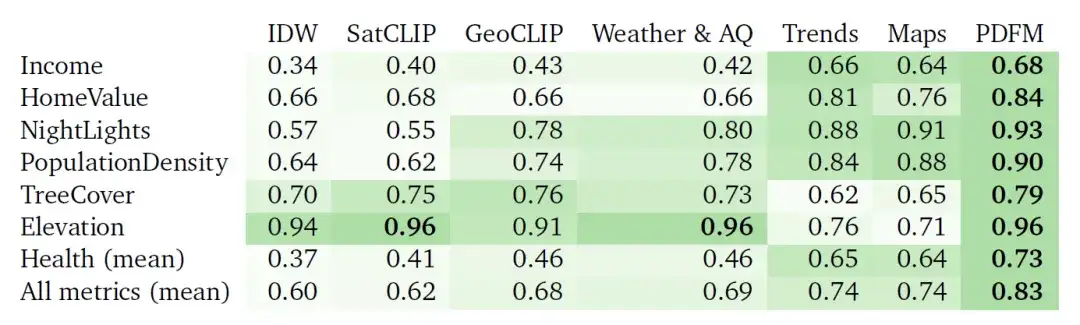
Tableau : Résultats d'interpolation² (les valeurs les plus élevées sont meilleures). Les expériences comparent les performances de l'interpolation basée sur la pondération inverse de la distance (IDW), l'intégration SatCLIP, l'intégration GeoCLIP, l'intégration PDFM et leurs sous-composants (météo et qualité de l'air, tendances de recherche agrégées, cartes et activité), en utilisant GBDT comme modèle en aval.
2 Expérience d'extrapolation
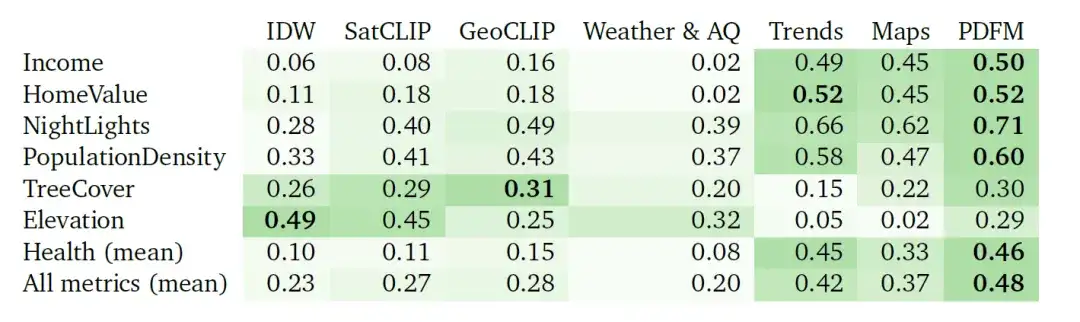
La figure ci-dessous montre les résultats complets de l’expérience d’extrapolation sur 27 tâches dans trois catégories : Santé, Catégorie socio-économique et Environnement. La performance du modèle est toujours évaluée à l’aide de l’indicateur ². Comme le montre la figure, bien que GeoCLIP ait un léger avantage dans la gestion de la tâche environnementale, PDFM surpasse considérablement tous les autres modèles de base dans la prédiction des variables sanitaires et socio-économiques.
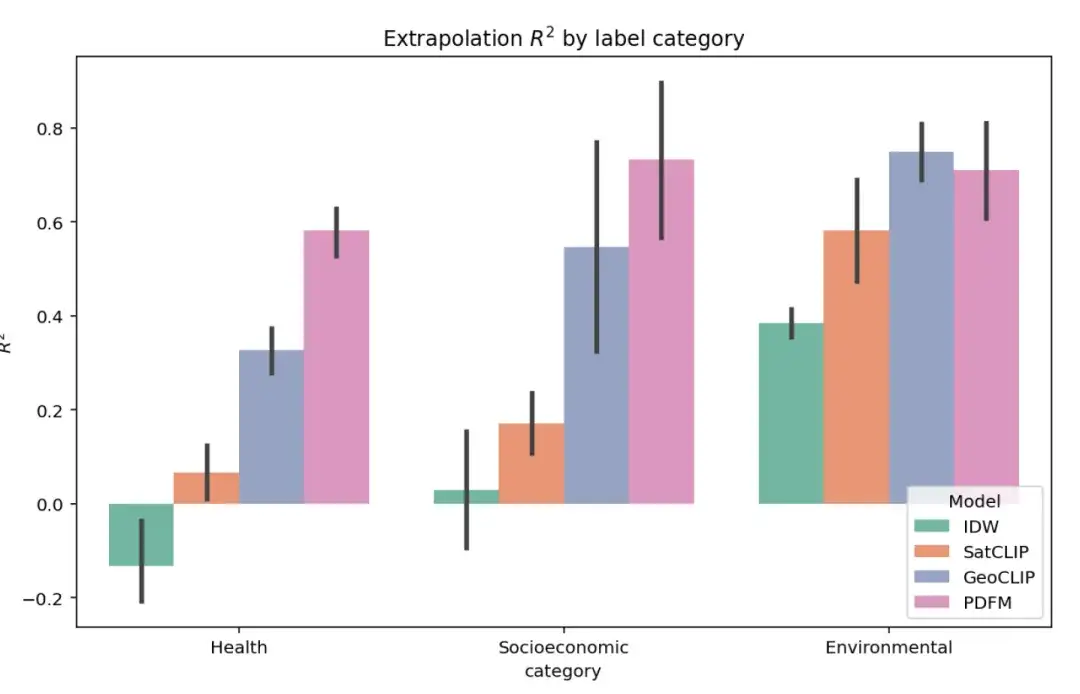
La tâche d’extrapolation est difficile en raison du manque important de données étiquetées. Dans ce cas, PDFM démontre d’excellentes performances, comme le montre le tableau ci-dessous, avec un carré moyen de 0,70 sur toutes les mesures et de 0,58 sur les mesures liées à la santé. En utilisant des images géolocalisées, GeoCLIP fonctionne bien dans la prédiction de la couverture arborée (TreeCover), atteignant ² = 0,69, surpassant le PDFM et toute modalité unique. Cependant, dans l’ensemble, le PDFM surpasse le modèle de base sur 25 tâches sur 27, soulignant son efficacité dans les scénarios d’extrapolation.
③ Expérience de super-résolution
La figure ci-dessous montre les résultats complets de l’expérience de super-résolution pour 27 tâches, regroupées par santé, catégorie socio-économique et environnement, en utilisant le coefficient de corrélation de Pearson moyen (r) au sein du comté comme métrique (des valeurs plus élevées indiquent que les prédictions du modèle sont plus corrélées avec les vraies étiquettes au niveau du code postal).
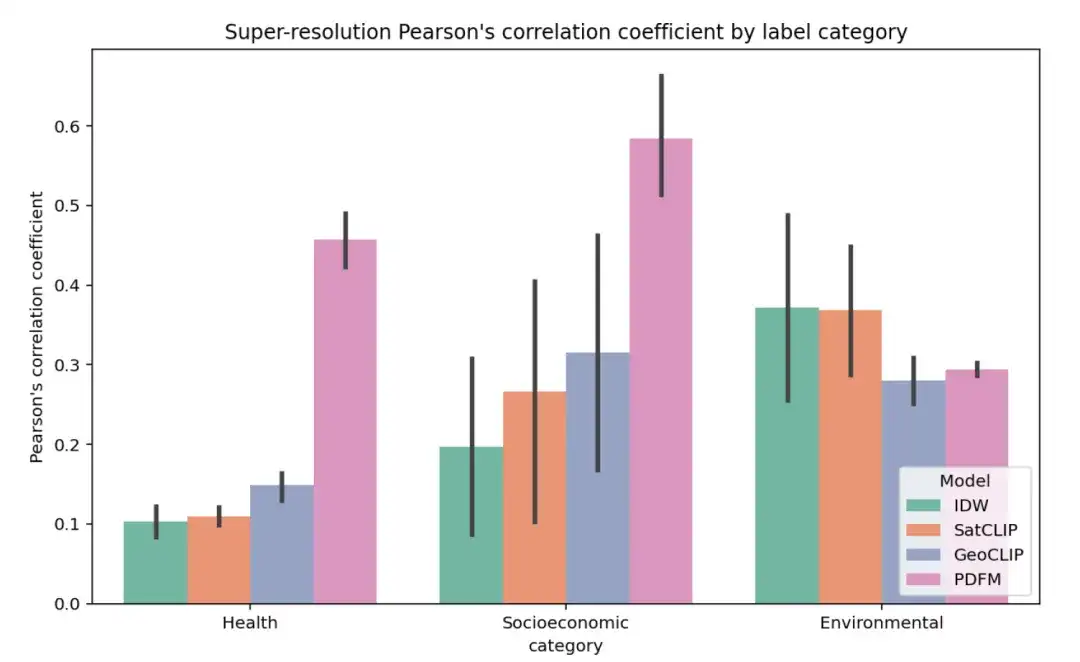
La tâche de super-résolution est plus difficile. Les résultats sont résumés dans le tableau ci-dessous. IDW est plus performant dans la tâche d'élévation, tandis que GeoCLIP est plus performant dans la tâche de couverture arborée. Dans l’ensemble, le PDFM a obtenu de meilleurs résultats sur 25 tâches sur 27, avec un coefficient de corrélation de Pearson moyen de 0,48.
④ Tâche de prédiction
Les chercheurs ont également évalué l'efficacité de l'utilisation des intégrations PDFM pour corriger les erreurs de prévision de TimesFM (un modèle de base de prévision univarié général), avec pour objectif principal d'évaluer l'amélioration de ces intégrations dans les horizons temporels futurs (prévisions du taux de chômage sur 6 mois et prévisions du taux de pauvreté sur deux ans). Les résultats du tableau ci-dessous montrent que le modèle combiné à l'intégration PDFM surpasse les performances de base de TimesFM en termes de métrique MAPE et est également meilleur qu'ARIMA - cela montre que l'intégration PDFM peut améliorer considérablement l'effet de prévision de TimesFM.
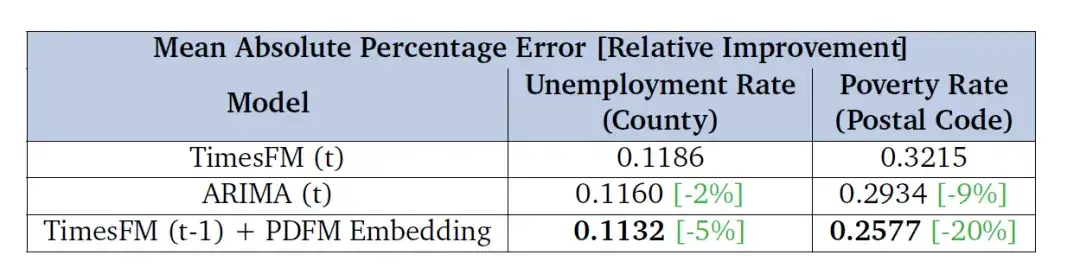
Les chercheurs ont évalué les performances en fonction des taux de chômage au niveau du comté et des taux de pauvreté au niveau du code postal aux États-Unis et ont présenté l'erreur absolue moyenne en pourcentage (MAPE) dans le tableau, les valeurs inférieures indiquant de meilleures performances.
L'intelligence artificielle géospatiale (GeoAI) est en plein essor
La naissance du modèle PDFM peut être considérée comme une autre exploration et utilisation approfondie des données géospatiales. Les données géospatiales font référence à de grandes quantités de données spatio-temporelles collectées à partir de nombreuses sources différentes dans différents formats. Il peut s’agir de données de recensement, d’images satellite, de données météorologiques, de données de téléphonie mobile, d’images cartographiées et de données de médias sociaux. Le partage, l’analyse et l’utilisation des données géospatiales de manière scientifique peuvent fournir de nombreuses informations utiles sur le développement de la société humaine, comme la prévision des taux de chômage, des prix de l’immobilier, la simulation de l’impact d’un certain médicament ou de la migration de population après une catastrophe.
Cependant, traiter efficacement des quantités massives de données géospatiales constitue un défi.Avec l’émergence des modèles de réseaux neuronaux artificiels, le concept d’intelligence artificielle géospatiale (GeoAI) a vu le jour et l’industrie a également fait de nombreuses explorations à cet égard.
Par exemple, en avril 2024, afin d'améliorer l'interprétabilité des modèles de prédiction de la minéralisation et la non-stationnarité spatiale causée par des facteurs géologiques dans le processus de minéralisation, une équipe de recherche de l'Université du Zhejiang a proposé une nouvelle méthode d'intelligence artificielle géospatiale - la régression logistique pondérée par le réseau neuronal géographique (GNNWLR). Le modèle intègre des modèles spatiaux et des réseaux neuronaux et, combiné à la théorie d'interprétation additive de Shapley, il peut non seulement améliorer considérablement la précision des prédictions, mais également améliorer l'interprétabilité des prédictions minérales dans des scénarios spatiaux complexes.
En juin 2024, des chercheurs du laboratoire SIG de l'université du Zhejiang ont publié un article de recherche intitulé « Un modèle de réseau neuronal pour optimiser la mesure de la proximité spatiale dans l'approche de régression pondérée géographiquement : une étude de cas sur le prix de l'immobilier à Wuhan » dans l'International Journal of Geographical Information Science, une revue bien connue dans le domaine des sciences de l'information géographique. Ils ont introduit de manière innovante une méthode de réseau neuronal pour coupler de manière non linéaire plusieurs mesures de proximité spatiale (telles que la distance euclidienne, le temps de trajet, etc.) entre les points d'observation pour obtenir une mesure de proximité spatiale optimisée (OSP), améliorant ainsi la précision des prédictions du modèle sur les prix des logements. Grâce à l’étude d’ensembles de données simulées et de cas empiriques de prix de l’immobilier à Wuhan, le modèle proposé dans l’article s’avère avoir de meilleures performances globales et peut décrire plus précisément des processus spatiaux complexes et des phénomènes géographiques.
Cliquez pour voir le rapport détaillé : Prévision précise des prix de l'immobilier à Wuhan ! Le laboratoire SIG de l'Université du Zhejiang a proposé le modèle osp-GNNWR : décrivant avec précision les processus spatiaux complexes et les phénomènes géographiques
À l’avenir, avec le développement continu de la technologie de l’IA, l’industrie de l’information géographique disposera d’une base technique plus solide et d’outils de développement plus pratiques, promouvant ainsi l’humanité dans l’ère de l’intelligence spatiale géographique.
Références :
1.https://arxiv.org/abs/2411.07207
2.https://research.google/blog/insights-into-population-dynamics-a-foundation-model-for-geospatial-inference/
3.https://www.ibm.com/cn-zh/topics/geospatial-data
4.https://mp.weixin.qq.com/s/eQz5N-cFTtGIkDk7IqMZxA
5.https://www.xinhuanet.com/science/2








