Command Palette
Search for a command to run...
Le Premier Document Chinois vLLM Est En Ligne ! La Dernière Version Augmente Le Débit De 2,7 Fois Et Réduit La Latence De 5 Fois, Ce Qui Accélère l'inférence De Grands Modèles Linguistiques !

Aujourd’hui, le développement de grands modèles de langage (LLM) s’étend des mises à niveau itératives des paramètres d’échelle à l’adaptation et à l’innovation des scénarios d’application. Ce processus révèle également une série de problèmes. Par exemple, l’efficacité du lien de raisonnement est faible et le traitement des tâches complexes prend beaucoup de temps, ce qui rend difficile de répondre aux besoins des scénarios avec des exigences élevées en temps réel. En termes d’utilisation des ressources, en raison de la grande échelle du modèle, la consommation de ressources de calcul et de stockage est énorme et il existe un certain degré de gaspillage.
Compte tenu de cela,Une équipe de recherche de l'Université de Californie à Berkeley (UC Berkeley) a ouvert le vLLM (Virtual Large Language Model) en 2023.Il s’agit d’un framework conçu spécifiquement pour accélérer le raisonnement de grands modèles de langage. Il a attiré une large attention dans le monde entier pour son excellente efficacité de raisonnement et ses capacités d’optimisation des ressources.
Afin d'aider les développeurs nationaux à se renseigner plus facilement sur les mises à jour de version de vLLM et les développements de pointe,HyperAI Super Neural Network a maintenant lancé le premier document chinois vLLM.Des connaissances techniques aux tutoriels pratiques, des tendances de pointe aux mises à jour majeures, les débutants comme les experts expérimentés peuvent trouver le contenu essentiel dont ils ont besoin.
Documentation chinoise vLLM :
Traçage de vLLM : Histoire de l'Open Source et évolution technologique
Le prototype de vLLM est né fin 2022. Lorsqu'une équipe de recherche de l'Université de Californie à Berkeley a déployé un projet de raisonnement parallèle automatisé appelé « alpa », elle a constaté qu'il fonctionnait très lentement et avait une faible utilisation du GPU. Les chercheurs sont parfaitement conscients qu’il existe une énorme marge d’optimisation dans le raisonnement basé sur des modèles de langage de grande taille. Cependant, il n'existait aucun système open source sur le marché optimisé pour l'inférence de modèles de langage à grande échelle. Ils ont donc décidé de créer eux-mêmes un cadre d'inférence de modèles de langage à grande échelle.
Après d'innombrables expériences et débogages, ils ont prêté attention à la mémoire virtuelle et à la technologie de pagination dans le système d'exploitation et, sur cette base, ils ont proposé l'algorithme d'attention pionnier PagedAttention en 2023, qui peut gérer efficacement les clés et les valeurs d'attention. Sur cette base, les chercheurs ont construit un moteur de service LLM distribué à haut débit vLLM, qui a permis d'obtenir une perte quasi nulle de mémoire cache KV.Résolution du problème de goulot d'étranglement de la gestion de la mémoire dans le raisonnement du modèle de langage volumineux.Comparé aux transformateurs Hugging Face, il atteint un débit 24 fois supérieur et cette amélioration des performances ne nécessite aucune modification de l'architecture du modèle.
Ce qui est encore plus intéressant à mentionner, c’est que vLLM ne se limite pas au matériel. Il ne se limite pas seulement au GPU Nvidia, mais ouvre également ses bras à de nombreuses architectures matérielles du marché, telles que le GPU AMD, le GPU Intel, AWS Neuron et Google TPU, ce qui favorise véritablement le raisonnement efficace et l'application de grands modèles de langage dans différents environnements matériels. Aujourd'hui, vLLM est capable de prendre en charge plus de 40 architectures de modèles et a reçu le soutien et le parrainage de plus de 20 entreprises, dont Anyscale, AMD, NVIDIA et Google Cloud.
En juin 2023, le code source open source de vLLM a été officiellement publié. En seulement un an, le nombre d'étoiles de vLLM sur Github a dépassé les 21,8 000.À ce jour, le projet compte 31 000 étoiles.
En septembre de la même année, l'équipe de recherche a publié l'article « Efficient Memory Management for Large Language Model Serving with PagedAttention », qui détaille davantage les détails techniques et les avantages de vLLM. L'équipe n'a pas arrêté ses recherches sur vLLM et continue d'effectuer des mises à niveau itératives dans des domaines tels que la compatibilité et la facilité d'utilisation. Par exemple, en termes d'adaptation matérielle, en plus du GPU Nvidia, comment vLLM peut-il fonctionner sur plus de matériel ? Par exemple, dans la recherche scientifique, comment améliorer encore l’efficacité du système et la vitesse d’inférence. Ceux-ci se reflètent également dans les mises à jour de version de vLLM.
Adresse du document :
https://dl.acm.org/doi/10.1145/3600006.3613165
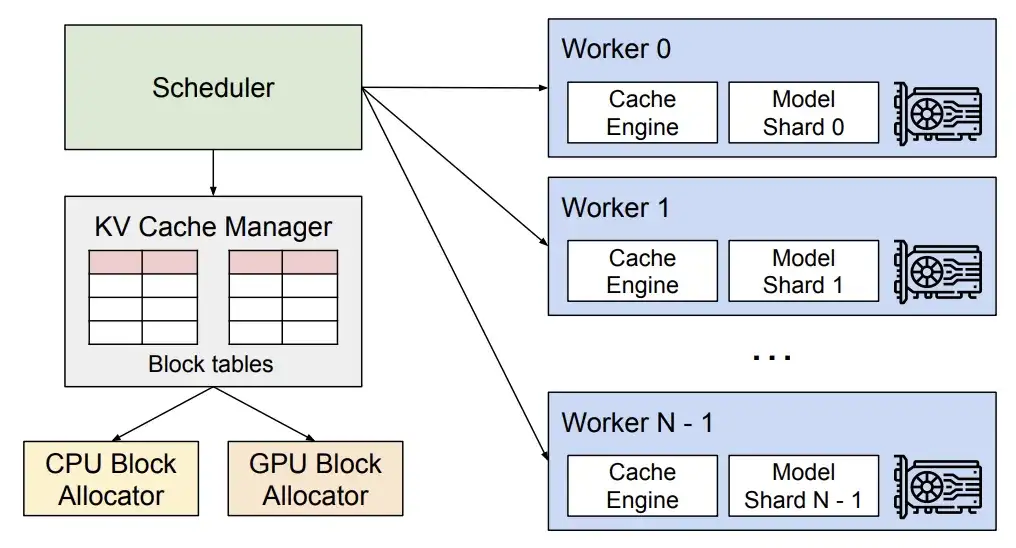
Mise à jour vLLM v0.6.4
Débit 2,7 fois supérieur et latence 5 fois inférieure
Le mois dernier, vLLM a été mis à jour vers la version 0.6.4, qui a permis des progrès importants en matière d'amélioration des performances, de prise en charge des modèles et de traitement multimodal.
En termes de performances, la nouvelle version introduit la planification en plusieurs étapes et le traitement de sortie asynchrone.Utilisation optimisée du GPU et efficacité de traitement accrue, améliorant ainsi le débit global.
Analyse technique vLLM
* La planification en plusieurs étapes permet à vLLM de terminer la planification et la préparation des entrées de plusieurs étapes à la fois, de sorte que le GPU peut traiter plusieurs étapes en continu sans avoir à attendre les instructions du CPU pour chaque étape, dispersant ainsi la charge de travail du CPU et réduisant le temps d'inactivité du GPU.
* Le traitement de sortie asynchrone permet d'effectuer le traitement de sortie en parallèle avec l'exécution du modèle. Plus précisément, vLLM ne traite plus la sortie immédiatement, mais retarde plutôt le traitement, traitant la sortie de l'étape n tout en exécutant l'étape n+1. Même si cela peut entraîner une étape supplémentaire par demande, l’amélioration significative de l’utilisation du GPU compense largement ce coût.
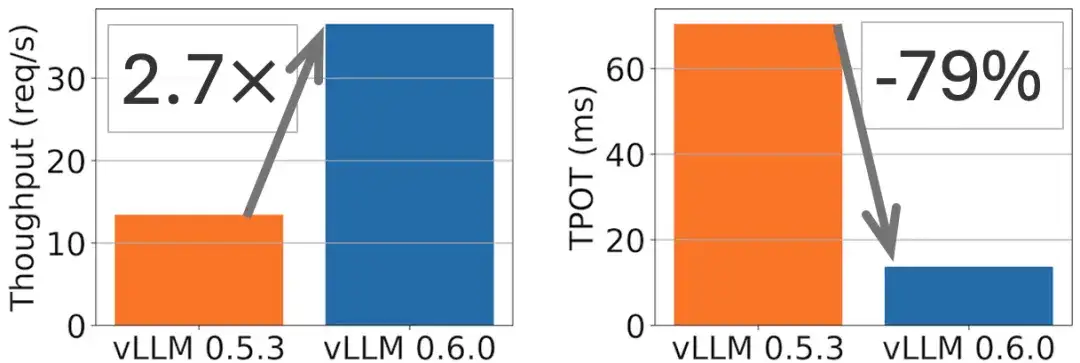
Par exemple, une amélioration du débit de 2,7x et une réduction du TPOT (Token Per Output Time) de 5x peuvent être obtenues sur le modèle Llama 8B, comme illustré dans la figure suivante.
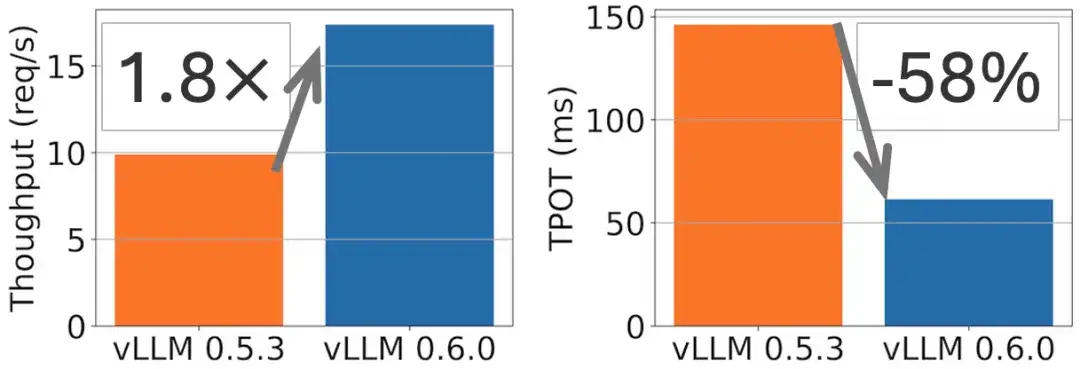
Sur le modèle Llama 70B, une amélioration du débit de 1,8 fois et une réduction du TPOT de 2 fois ont été obtenues, comme le montre la figure suivante.
En termes de support de modèle, vLLM a récemment intégré des adaptations pour les modèles de langage de pointe tels que Exaone, Granite et Phi-3.5-MoE. Dans le domaine multimodal, la fonction d'entrée multi-images a été ajoutée (le modèle Phi-3-vision est utilisé comme exemple dans la documentation officielle), ainsi que la possibilité de traiter plusieurs blocs audio d'Ultravox, élargissant encore le champ d'application de vLLM dans les tâches multimodales.
La première version complète de la documentation chinoise de vLLM est en ligne
Il ne fait aucun doute que le vLLM, en tant qu’innovation technologique importante dans le domaine des grands modèles, représente la direction actuelle du développement du raisonnement efficace. Afin de permettre aux développeurs nationaux de comprendre les principes techniques avancés qui le sous-tendent de manière plus pratique et plus précise, le vLLM sera introduit dans le développement de grands modèles nationaux, favorisant ainsi le développement de ce domaine. Les bénévoles de la communauté HyperAI ont terminé avec succès le premier document chinois vLLM grâce à une collaboration ouverte et à une double révision de la traduction et de la relecture.Désormais entièrement lancé sur hyper.ai.
Documentation chinoise vLLM :
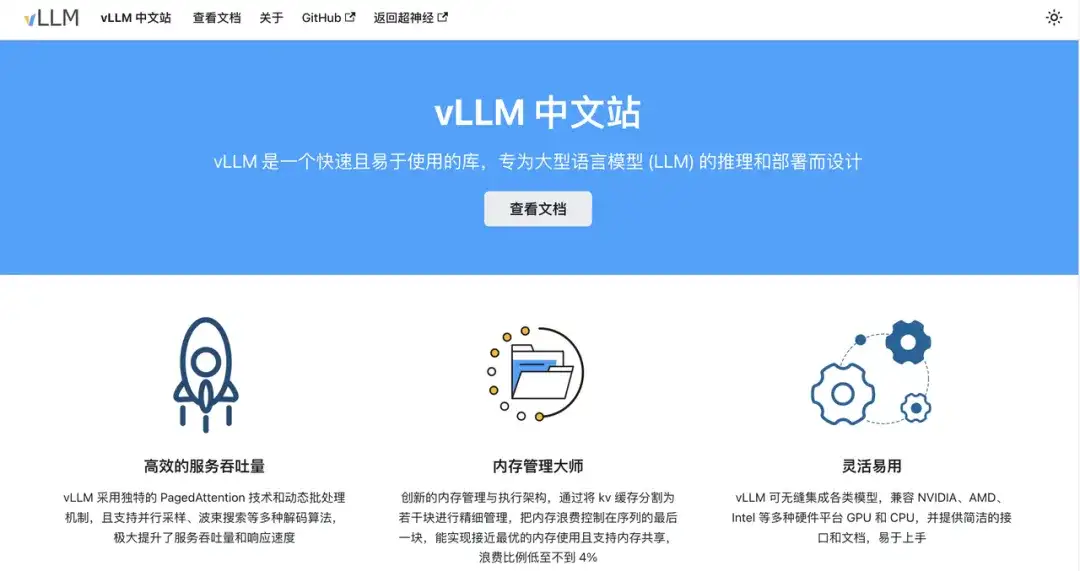
vLLM Ce document vous fournit :
* Concepts de base à partir de zéro
* Tutoriel de clonage en un clic pour un démarrage rapide
* Base de connaissances vLLM mise à jour en temps opportun
* Écologie communautaire chinoise amicale et ouverte
Construire des ponts open source :
Parcours de co-construction communautaire entre TVM, Triton et vLLM
En 2022, HyperAI a lancé la première documentation chinoise d'Apache TVM en Chine (Cliquez pour voir le texte original : Le site Web chinois de TVM est officiellement lancé ! Le « livre de référence » le plus complet sur le déploiement de modèles d'apprentissage automatique est ici)Alors que les puces nationales se développent rapidement, nous fournissons aux ingénieurs compilateurs nationaux l'infrastructure nécessaire pour comprendre et apprendre TVM.Dans le même temps, nous nous sommes également associés à Apache TVM PMC Dr. Feng Siyuan et d'autres pour former la communauté chinoise TVM la plus active de Chine.Grâce à des activités en ligne et hors ligne, nous avons attiré la participation et le soutien des principaux fabricants de puces nationaux, couvrant plus d'un millier de développeurs de puces et d'ingénieurs compilateurs.

Adresse de la documentation chinoise de TVM :
En octobre 2024, nous avons lancé le site Web chinois Triton (Cliquez pour voir le texte original : Le premier document chinois complet de Triton est en ligne ! Ouverture d'une nouvelle ère d'accélération de l'inférence GPU), élargissant encore les limites techniques et la portée du contenu de la communauté des compilateurs d'IA.
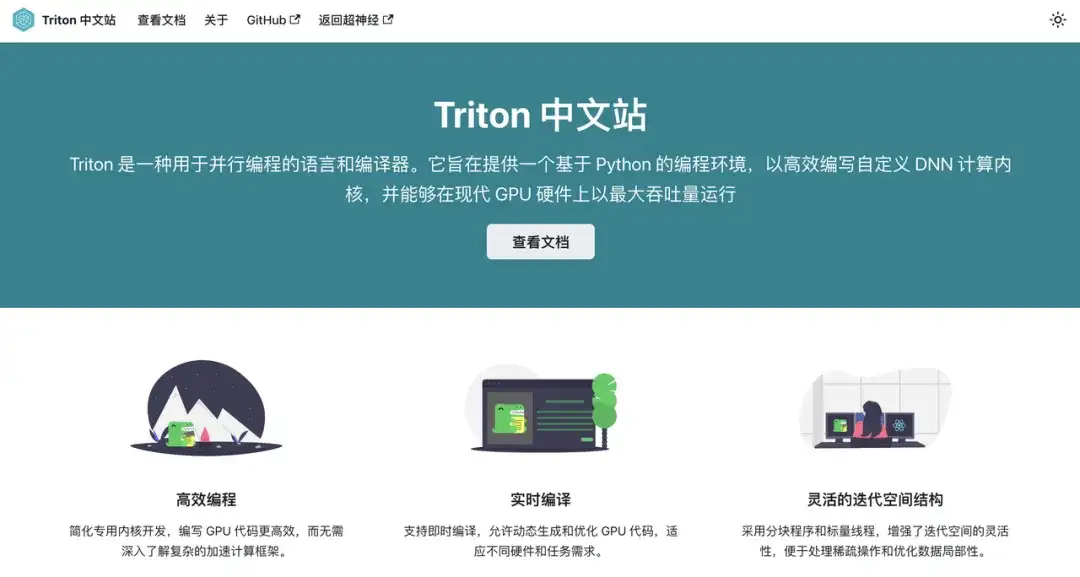
Adresse de la documentation chinoise de Triton :
Dans notre parcours pour bâtir la communauté des compilateurs d'IA, nous avons écouté la voix de chacun et gardé un œil sur les tendances du secteur. Le lancement de la documentation chinoise vLLM est dû au fait que nous avons observé qu'avec le développement rapide des grands modèles, l'attention des gens et la demande pour l'utilisation de vLLM augmentent. Nous espérons fournir une plate-forme d’apprentissage, de communication et de coopération aux développeurs et promouvoir conjointement la vulgarisation et le développement de technologies de pointe dans le contexte chinois.
La mise à jour et la maintenance des documents chinois TVM, Triton et vLLM constituent le travail de base pour nous permettre de construire la communauté chinoise. À l’avenir, nous espérons que davantage de partenaires nous rejoindront pour construire une communauté open source d’IA plus ouverte, diversifiée et inclusive !
Consultez la documentation complète de vLLM en chinois :
Sur GitHub vLLM chinois :
https://github.com/hyperai/vllm-cn
Ce mois-ci, HyperAI organisera une réunion d'échange technique hors ligne appelée Meet AI Compiler à Shanghai. Veuillez scanner le code QR et noter « AI Compiler » pour rejoindre le groupe d'événements et obtenir des informations pertinentes sur l'événement dès que possible.

Références :
1.https://blog.vllm.ai/2024/09/05/perf-update.html








