Command Palette
Search for a command to run...
Aperçu De La Diffusion En Direct | Nouvelle Avancée Dans L’optimisation Des Protéines ! Les Résultats De Recherche De l'Université Du Zhejiang Ont Été Sélectionnés Pour NeurIPS 2024, Et Le Premier Auteur De l'article a Expliqué En Détail Les Points Forts Techniques

Le cinquième épisode de la série de diffusion en direct « Meet AI4S » sera diffusé à l'heure prévue à 19h00 le 10 décembre. HyperAI a l'honneur d'inviter Wang Zeyuan, doctorant du Knowledge Engine Laboratory de l'Université du Zhejiang. Le thème de son partage cette fois-ci est « Utiliser le processus de débruitage par diffusion pour aider les grands modèles à optimiser les protéines ».
Le professeur Chen Huajun, le chercheur Zhang Qiang, le Dr Wang Zeyuan et d'autres de l'Université du Zhejiang ont proposé un nouveau modèle de langage protéique de débruitage (DePLM).Les informations évolutives capturées par le modèle de langage protéique peuvent être considérées comme un mélange d'informations pertinentes et non pertinentes pour la propriété cible, où les informations non pertinentes sont considérées comme du « bruit » et éliminées, prédisant ainsi le paysage adaptatif des protéines et aidant à l'optimisation des protéines.
Des recherches ont montré que DePLM surpasse les méthodes existantes pour prédire les effets des mutations protéiques et possède de fortes capacités de généralisation pour les nouvelles protéines. Cette réalisation a été sélectionnée pour la conférence phare NeurIPS 2024.
Dans cette émission en direct, le Dr Wang Zeyuan expliquera en détail les idées innovantes de cet article. HyperAI a également spécialement préparé 10 heures de ressources NVIDIA RTX A6000 pour tout le monde. Les spectateurs qui participeront au tirage au sort dans la salle de diffusion en direct auront la possibilité de les obtenir gratuitement !
Scannez le code QR et notez « AI4S » pour rejoindre le groupe de discussion⬇️

Présentation de l'invité

Partager le sujet
Utilisation du débruitage par diffusion pour aider les grands modèles à optimiser les protéines
Introduction
Notre groupe de recherche a proposé une méthode combinant un grand modèle avec un modèle de débruitage par diffusion. Grâce à un réglage précis avec une petite quantité de données expérimentales humides, la précision du grand modèle dans les tâches de prédiction du paysage adaptatif des protéines est améliorée tout en maintenant la bonne capacité de généralisation du modèle.
Avantages pour le public
1. Comprendre les méthodes, les ensembles de données et les indicateurs permettant de prédire le paysage de la condition physique des protéines
2. Comprendre comment le modèle de langage amélioré par diffusion (DePLM) peut être utilisé pour la prédiction adaptative du paysage
3. Explorer comment combiner les informations évolutives, les expériences en milieu humide et d'autres données pour la formation des modèles d'IA
Revue de presse
HyperAI a déjà interprété le document de recherche « DePLM : Denoising Protein Language Models for Property Optimization » avec le Dr Wang Zeyuan comme premier auteur.
Points saillants de la recherche
* DePLM peut filtrer efficacement les informations non pertinentes pour la propriété cible et améliorer l'optimisation des protéines en optimisant les informations évolutives contenues dans PLM
* DePLM surpasse non seulement les modèles de pointe actuels dans la prédiction des effets de mutation, mais démontre également de fortes capacités de généralisation à de nouvelles protéines
* Cette étude conçoit un processus direct basé sur le tri dans le cadre de la diffusion de débruitage, étendant le processus de diffusion à l'espace de tri des possibilités de mutation, tout en changeant l'objectif d'apprentissage de la minimisation de l'erreur numérique à la maximisation de la pertinence du tri, en favorisant l'apprentissage indépendant de l'ensemble de données et en garantissant de fortes capacités de généralisation du modèle.
Acquisition de jeux de données
L'étude a sélectionné l'ensemble de données de mutation protéique ProteinGym et, après avoir exclu les ensembles de données de protéines de type sauvage trop longs, a finalement retenu 201 ensembles de données de criblage de mutation profonde (DMS).
L'ensemble de données est utilisé directement :
https://hyper.ai/datasets/32818
Architecture du modèle
Comme le montre la figure de gauche ci-dessous, DePLM utilise la vraisemblance d’évolution dérivée de PLM comme entrée et génère une vraisemblance débruitée pour un attribut spécifique afin de prédire l’impact des mutations ; dans les parties centrale et droite de la figure ci-dessous, le module de débruitage utilise l'encodeur de caractéristiques pour générer une représentation de la protéine, en tenant compte des structures primaires et tertiaires, qui sont ensuite utilisées pour filtrer le bruit dans la vraisemblance via le module de débruitage.
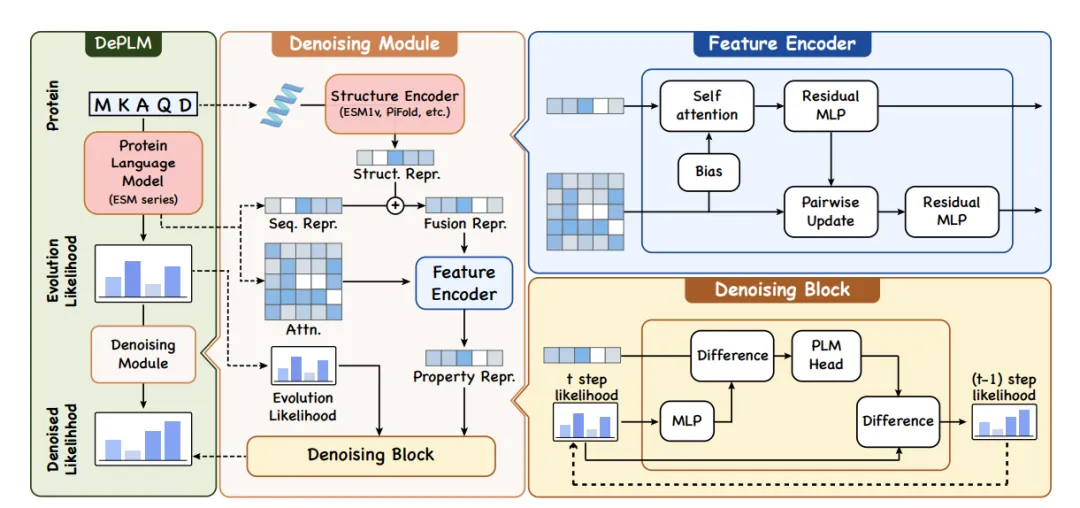
Afin de parvenir à un apprentissage indépendant de l'ensemble de données et de garantir une forte capacité de généralisation du modèle, les chercheurs ont effectué un processus de diffusion dans l'espace de classement des valeurs de caractéristiques et ont remplacé l'objectif traditionnel de minimisation de l'erreur numérique par la maximisation de la pertinence du classement.
Laboratoire du moteur de connaissances de l'Université du Zhejiang
Le laboratoire Knowledge Engine est basé sur l'École d'informatique et de technologie, l'École de logiciels, etc. de l'Université du Zhejiang.Nous sommes engagés dans la recherche universitaire, l'open source et l'innovation et l'application industrielles dans les domaines des graphes de connaissances, des grands modèles de langage et de l'IA pour la science. Les projets communs comprennent le centre conjoint de recherche et développement sur les graphes de connaissances de l'Université du Zhejiang et du groupe Ant, le laboratoire conjoint du moteur de connaissances de l'Université du Zhejiang et d'Alibaba, etc.
L'équipe recrute des chercheurs postdoctoraux exceptionnels, des centenaires, des ingénieurs R&D et d'autres chercheurs à temps plein. Bienvenue à tous ~
Page d'accueil Github du laboratoire :
Découvrez la série AI4S Live
HyperAI (hyper.ai) est le plus grand moteur de recherche de Chine dans le domaine de la science des données. Il se concentre sur les derniers résultats de recherche scientifique de l'IA pour la science et suit en temps réel les articles universitaires dans les meilleures revues telles que Nature et Science. Jusqu’à présent, il a achevé l’interprétation de près de 200 articles sur l’IA pour la science.
De plus, nous exploitons également le seul projet open source d'IA pour la science en Chine, awesome-ai4s.
* Adresse du projet :
https://github.com/hyperai/awesome-ai4s
Afin de promouvoir davantage la popularisation de l'IA4S, de réduire davantage les barrières de diffusion des résultats de la recherche scientifique des institutions universitaires et de les partager avec un plus large éventail de chercheurs de l'industrie, de passionnés de technologie et d'unités industrielles, HyperAI a planifié la colonne vidéo « Meet AI4S », invitant les chercheurs ou les unités connexes qui sont profondément engagés dans le domaine de l'IA pour la science à partager leurs résultats de recherche et leurs méthodes sous forme de vidéos, et à discuter conjointement des opportunités et des défis auxquels est confrontée l'IA pour la science dans le processus de progrès, de promotion et de mise en œuvre de la recherche scientifique, afin de promouvoir la vulgarisation et la diffusion de l'IA pour la science.
Jusqu'à présent, nous avons organisé avec succès 4 diffusions en direct de Meet AI4S, couvrant les domaines de la science de l'information géographique, des sciences de la vie et de l'ingénierie des protéines.
Nous invitons les groupes de recherche et les institutions de recherche efficaces à participer à nos événements en direct !Scannez le code QR pour ajouter « Neural Star » WeChat pour plus de détails↓









