Command Palette
Search for a command to run...
Soyez Le Premier À Découvrir Le Filigrane Invisible SynthID ! Rendre Le Contenu Généré Par L’ia Plus Contrôlable ; Un Ensemble De Données De sous-titres Audio À Grande Échelle Est Désormais En Ligne, Contenant 6 Millions De Fichiers Audio

À une époque où le contenu généré par l’IA devient de plus en plus populaire, la manière de distinguer rapidement si le contenu est créé manuellement ou généré par l’IA est devenue un sujet brûlant. Cela implique non seulement l’authenticité des informations et la protection des droits d’auteur, mais est également étroitement lié à la sécurité du réseau.
Récemment, Google DeepMind a lancé la technologie SynthID-Text, qui peut intégrer des filigranes sans perte sans affecter la qualité du texte en optimisant le score de probabilité du jeton dans le processus de génération de texte, et présente une efficacité de détection extrêmement élevée. Par rapport aux technologies traditionnelles, il atteint une précision de classification plus élevée à un coût de latence inférieur, offrant une solution innovante pour la supervision du contenu de l'IA.
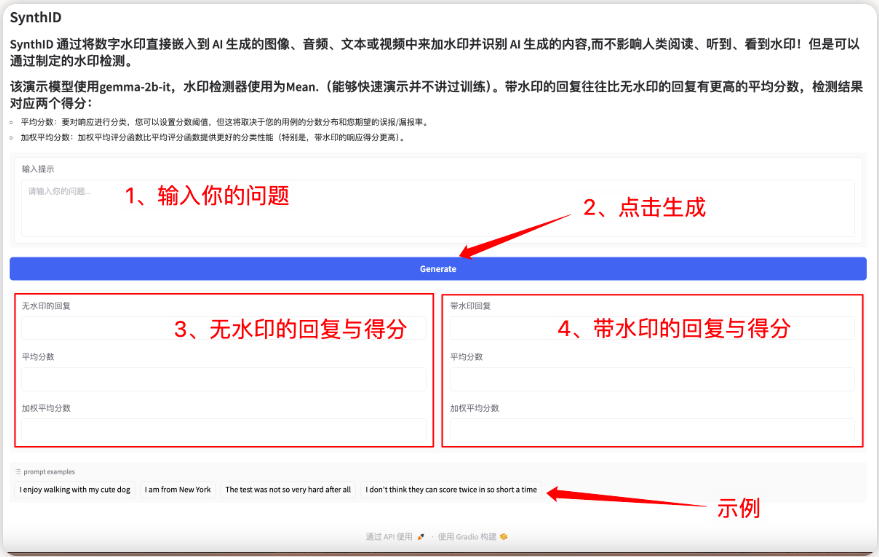
Le site officiel hyper.ai a maintenant lancé un tutoriel sur l'utilisation de SynthID-Text. Vous pouvez le cloner et le démarrer en un clic pour ajouter des filigranes numériques à la génération d'IA :
Lien de démarrage en un clic :
Du 18 au 22 novembre, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec dates limites de novembre à décembre : 3
Visitez le site officiel : hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données d'extraction de relations objet-entité multimodales PLUS
L'ensemble de données contient 21 types de relations différents et couvre plus de 20 000 faits de relations multimodales, qui sont annotés sur 3 559 paires de légendes de texte et d'images correspondantes.
Utilisation directe :https://go.hyper.ai/LlfTx

2. Ensemble de données sur les maladies des fruits de la goyave
L'ensemble de données contient 473 images de fruits de goyave étiquetées, qui ont été soumises à des étapes de prétraitement telles que le masquage flou et le CLAHE (égalisation adaptative de l'histogramme à contraste limité), portant le nombre d'images à 3 784. Chaque image est prétraitée dans un format RVB cohérent de 512 × 512 pixels.
Utilisation directe :https://go.hyper.ai/RRLEd

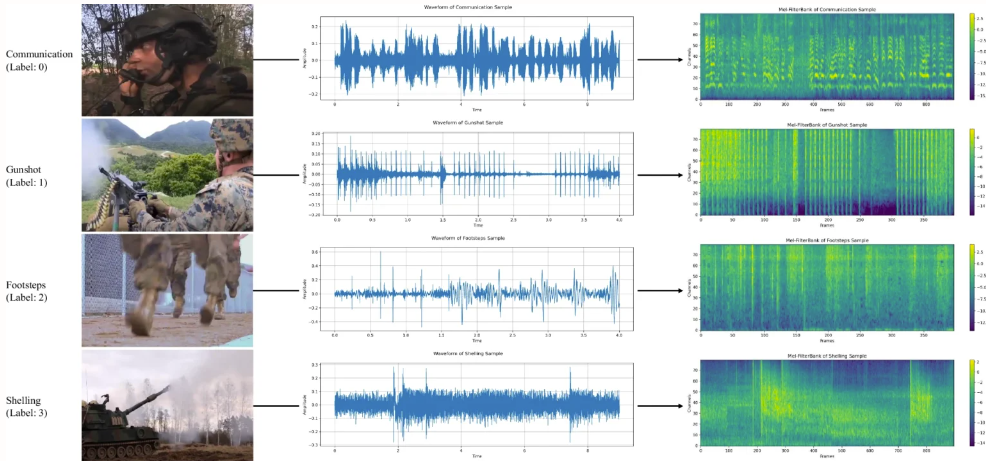
3. Ensemble de données audio militaires MAD
L'ensemble de données MAD est conçu pour soutenir la formation et l'évaluation des systèmes de classification audio, en particulier dans les tâches de classification audio liées aux activités militaires, telles que les coups de feu, les tirs d'artillerie ou les explosions. L'ensemble de données est extrait de plusieurs vidéos militaires et contient 8 075 échantillons sonores répartis en 7 catégories, totalisant environ 12 heures d'audio.
Utilisation directe :https://go.hyper.ai/kxqH3
4. Ensemble de données de préférences de raisonnement multimodal MMPR
L'ensemble de données MMPR contient 750 000 échantillons sans réponses claires et correctes et 2,5 millions d'échantillons avec des réponses claires et correctes. Les échantillons couvrent plusieurs domaines tels que VQA, Science, Graphique, Mathématiques, OCR et Documents pour assurer la diversité. L'ensemble de données vise à améliorer les performances des modèles dans les tâches de raisonnement multimodal tout en évitant les effets négatifs potentiels pendant la formation.
Utilisation directe :https://go.hyper.ai/bbHH0

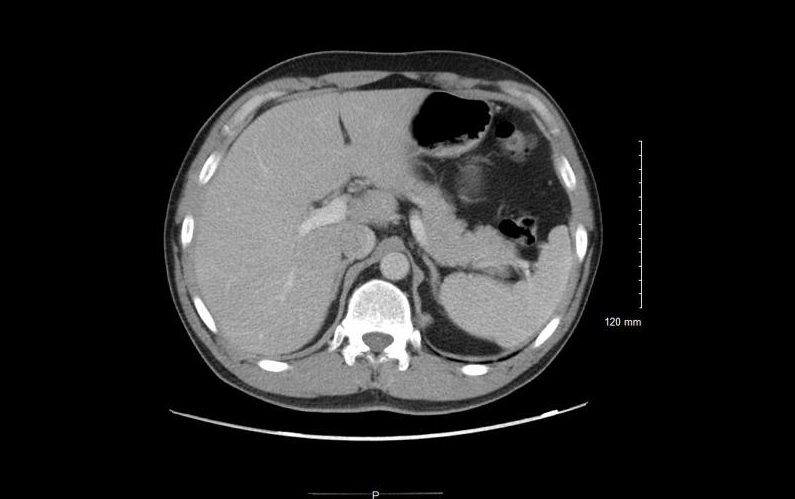
5.Ensemble de données d'images médicales multimodales de radiologie ROCOv2
L'ensemble de données ROCOv2 combine des images radiologiques avec des concepts et descriptions médicaux associés et contient plus de 70 000 images radiologiques, couvrant une variété de modèles cliniques, de régions anatomiques et de directions (pour les rayons X), et chaque image a une description de concept médical correspondante.
Utilisation directe :https://go.hyper.ai/XgqCa
6. Ensemble de données d'index géographique PDFM
L'ensemble de données PDFM Geo-Index est constitué de données réelles utilisées pour évaluer les intégrations basées sur la dynamique de population. Il contient de riches informations récapitulatives sur le comportement humain capturées à partir de cartes, de résumés de tendances de recherche et de facteurs environnementaux tels que la météo et la qualité de l'air.
Utilisation directe :https://go.hyper.ai/jpzY1
7. Ensemble de données de réglage d'instructions multi-images Mantis-Instruct
L'ensemble de données est un ensemble de données multimodal entrelacé texte-image axé sur le réglage des instructions multi-images, composé de 14 sous-ensembles contenant 721 000 exemples pour la formation de la famille de modèles Mantis. L'ensemble de données couvre une variété de compétences multi-images, notamment la coréférence, le raisonnement, la comparaison et la compréhension temporelle.
Utilisation directe :https://go.hyper.ai/dOtuR
8. Ensemble de données de flux de travail scientifique MASSW
L'ensemble de données MASSW contient plus de 152 000 publications évaluées par des pairs provenant de 17 grandes conférences en informatique, couvrant une période des 50 dernières années. L'ensemble de données définit cinq aspects clés du flux de travail scientifique : le contexte, les idées clés, les méthodes, les résultats et l'impact escompté. Ces aspects ont été utilisés pour extraire et structurer les informations de chaque publication, générant ainsi un résumé structuré.
Utilisation directe :https://go.hyper.ai/2pUy8
9. Ensemble de données de sous-titres audio AudioSetCaps
L'ensemble de données de sous-titres audio AudioSetCaps contient plus de 6,11 millions de fichiers audio de 10 secondes. Chaque fichier audio est accompagné d'un titre descriptif ainsi que de 3 paires de questions-réponses comme métadonnées pour générer le titre final.
Utilisation directe :https://go.hyper.ai/3QCQP
10. Ensemble de données de médecine traditionnelle chinoise SFT Ensemble de données de diagnostic de médecine traditionnelle chinoise
Cet ensemble de données contient environ 1 Go de contenu de haute qualité, notamment des cas cliniques dans divers domaines de la MTC, des livres célèbres, des encyclopédies médicales et des glossaires. L'ensemble de données est principalement composé de données internes provenant de sources non liées au réseau. Le 99% est en chinois simplifié avec une excellente qualité et une densité d'informations considérable, ce qui le rend adapté à des fins de pré-formation ou de pré-formation continue.
Utilisation directe :https://go.hyper.ai/zb7Uf
Tutoriels publics sélectionnés
1. Outil de génération de filigrane de texte SynthID-Text AI
Le modèle est une technique de tatouage numérique permettant d'identifier et de vérifier les textes générés par les grands modèles linguistiques (LLM), qui peuvent maintenir la qualité du texte et atteindre une précision de détection élevée tout en minimisant les coûts de latence. Son cœur réside dans l'intégration de filigranes presque imperceptibles en ajustant légèrement le score de probabilité du jeton dans le processus de génération sans compromettre la qualité du texte et l'expérience utilisateur, obtenant ainsi une précision de détection élevée.
Ce projet peut générer une interface interactive front-end via l'interface Gradio. Les modèles et dépendances pertinents ont été déployés et le texte du filigrane peut être généré en commençant par un seul clic.
Exécutez en ligne :https://go.hyper.ai/lQ1UK
2. Evo : prédiction et génération de séquences de l'échelle moléculaire à l'échelle du génome
Evo est un modèle biologiquement fondé qui se généralise aux langages fondamentaux de la biologie : l'ADN, l'ARN et les protéines. Le modèle est capable d'effectuer des tâches de prédiction et des conceptions génératives, couvrant la prédiction et la génération de séquences à des échelles allant des molécules aux génomes entiers.
Cliquez sur le lien ci-dessous et suivez le tutoriel pour prédire les séquences à l'échelle du génome.
Exécutez en ligne :https://go.hyper.ai/LgFWm
3. Tutoriel VASP : 1-1. Calcul DFT des atomes d'oxygène isolés
VASP est un progiciel permettant d'effectuer des calculs de structure électronique et des simulations de mécanique quantique-dynamique moléculaire. Il s’agit de l’un des logiciels commerciaux les plus populaires pour la simulation des matériaux et la recherche en science des matériaux computationnelle. Sa grande précision et ses fonctions puissantes en font un outil important pour les chercheurs pour prédire et concevoir les propriétés des matériaux. Il est largement utilisé en physique des solides, en science des matériaux, en chimie, en dynamique moléculaire et dans d’autres domaines.
Ce tutoriel est la première partie du tutoriel officiel VASP : calculs DFT d'atomes d'oxygène isolés. Cliquez sur le lien ci-dessous et suivez le didacticiel pour démarrer des calculs DFT hautes performances à partir de zéro.
Exécutez en ligne :https://go.hyper.ai/pa2NX
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Articles de la communauté
Le repliement inverse moléculaire joue un rôle clé dans la conception de médicaments et de matériaux, mais les recherches passées se sont rarement concentrées sur le repliement inverse de molécules générales. En réponse à cela, une équipe du Future Industries Research Center de l’Université Westlake a proposé un modèle unifié, UniIF, pour le repliement inverse de toutes les molécules. Les résultats expérimentaux montrent qu'UniIF a atteint des performances de pointe dans de multiples tâches telles que la conception de protéines, la conception d'ARN et la conception de matériaux. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/efhze
Dans l'application interdisciplinaire de la technologie de l'IA, la manière de combiner des variables discrètes et continues pour améliorer la qualité de la génération de matériaux cristallins est devenue un problème central dans le domaine de la génération de matériaux cristallins. Pour résoudre ce problème, Meta FAIR Lab a publié le modèle de génération de matériaux FlowLLM. L'efficacité de ce modèle dans la génération de matériaux stables est améliorée de plus de 300% par rapport aux modèles précédents, et l'efficacité de génération de matériaux SUN est également améliorée d'environ 50%. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/KJzjz
Récemment, l'Université Jiao Tong de Shanghai et le Laboratoire d'intelligence artificielle de Shanghai ont développé avec succès un modèle de langage protéique pré-entraîné avec des capacités de connaissance de la structure - ProSST. Le modèle est pré-entraîné sur un grand ensemble de données de 18,8 millions de structures protéiques et peut intégrer efficacement les informations sur la structure des protéines et la séquence d'acides aminés, surpassant considérablement les modèles existants dans les tâches d'apprentissage supervisé. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/qi5ei
Le laboratoire d'intelligence artificielle de Shanghai et d'autres institutions de recherche scientifique ont proposé le benchmark GMAI-MMBench, qui couvre 284 ensembles de données de tâches en aval dans le monde entier, dont 38 modalités d'imagerie médicale, 18 tâches cliniques, 18 départements et 4 granularités perceptuelles au format questions-réponses visuelles. Il s’agit de la référence médicale générale la plus complète à ce jour. De plus, cet article résume également d’autres ensembles de données médicales pour vous, y compris des liens d’utilisation en un clic.
Voir le rapport complet :https://go.hyper.ai/csr2M
Articles populaires de l'encyclopédie
1. Fonction sigmoïde
2. Norme nucléaire
3. Réseaux de neurones artificiels
4. Augmentation des données
5. Réseau neuronal quantique
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
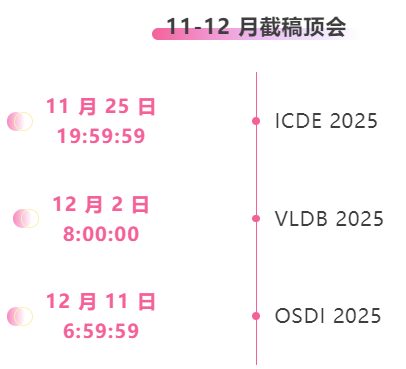
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 300 ensembles de données publiques
* Comprend plus de 400 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :
Enfin, je recommande un « Programme d’incitation aux créateurs ». Les amis intéressés peuvent scanner le code QR pour participer !









