Command Palette
Search for a command to run...
Sélectionné Pour NeurIPS 2024 ! L'équipe De l'Académie Chinoise Des Sciences a Proposé Un Nouveau Cadre Pour Le Décodage Cérébral Non Invasif, Jetant Les Bases Du Développement d'interfaces cerveau-ordinateur Et De Modèles cognitifs.
Pouvez-vous imaginer visualiser les images que vous voyez, pensez ou même dont vous rêvez ? Ce n’est pas seulement le fruit de l’imagination. Dès 2008, Jack Gallant, neuroscientifique à l’Université de Californie à Berkeley, proposait son hypothèse dans Nature. Ils ont utilisé l'imagerie par résonance magnétique fonctionnelle (IRMf) - une technologie d'imagerie fonctionnelle cérébrale non invasive pour « lire » l'activité du cortex visuel du sujet, puis ont visualisé les images vues par le sujet grâce à une reconstruction visuelle.Cela a lancé un appel clair aux scientifiques du monde entier pour qu’ils décodent le cerveau.
Comparée à la technologie de décodage cérébral invasive, la technologie de décodage cérébral non invasive représentée par l'IRMf est très appréciée car elle permet un décodage cérébral de manière plus simple et plus sûre. Il présente un grand potentiel d’application dans de nombreux domaines tels que la recherche en neurosciences cognitives, les applications d’interface cerveau-ordinateur et le diagnostic médical clinique.
Cependant, le décodage non invasif des signaux cérébraux est entravé par les différences individuelles et la complexité de la représentation des signaux neuronaux, et reste un défi majeur dans le processus de décodage cérébral.D’une part, les méthodes traditionnelles s’appuient sur des modèles personnalisés et sur un grand nombre d’expériences coûteuses ; d'autre part, en raison du manque de sémantique précise et d'interprétabilité, il est difficile pour les méthodes traditionnelles de reproduire avec précision l'expérience visuelle d'un individu dans les tâches de reconstruction visuelle.
En réponse à cela, l'équipe du professeur Zeng Yi de l'Institut d'automatisation de l'Académie chinoise des sciences a conçu de manière innovante un cadre d'intégration multimodal qui combine des extracteurs de caractéristiques IRMf avec de grands modèles de langage pour résoudre le problème de la reconstruction visuelle de l'activité cérébrale..À l'aide de Vision Transformer 3D (ViT3D), les chercheurs ont combiné la structure cérébrale 3D avec la sémantique visuelle, aligné les caractéristiques de l'IRMf avec des intégrations visuelles à plusieurs niveaux via un extracteur de caractéristiques unifié efficace et extrait des informations à partir de données expérimentales uniques sans avoir besoin d'un modèle spécifique. De plus, l'extracteur intègre des fonctionnalités visuelles à plusieurs niveaux, ce qui simplifie l'intégration avec les grands modèles de langage (LLM), et de grands modèles multimodaux peuvent être développés en augmentant les ensembles de données IRMf et les données textuelles associées aux images IRMf.
Le résultat, intitulé « Neuro-Vision to Language: Enhancing Brain Recording-based Visual Reconstruction and Language Interaction », a été accepté par NeurIPS 2024.
Points saillants de la recherche :
* Cette étude améliore considérablement la capacité à reconstruire les stimuli visuels à travers les signaux cérébraux, approfondit la compréhension des mécanismes neuronaux pertinents et ouvre de nouvelles voies pour interpréter l'activité cérébrale
* L'extracteur de caractéristiques IRMf basé sur Vision Transformer 3D combine la structure cérébrale 3D et la sémantique visuelle et les aligne à plusieurs niveaux, éliminant ainsi le besoin de modèles thématiques spécifiques et extrayant des données valides en une seule expérience, réduisant considérablement les coûts de formation et améliorant la convivialité dans des scénarios réels
* En élargissant les données textuelles liées aux images IRMf, un grand modèle multimodal capable de décoder les données IRMf a été construit, ce qui a non seulement amélioré les performances de décodage cérébral, mais a également élargi sa gamme d'applications, y compris la reconstruction visuelle, le raisonnement complexe, la localisation de concepts et d'autres tâches.
Adresse du document :
https://nips.cc/virtual/2024/poster/93607
Suivez le compte officiel et répondez « Décodage du signal cérébral » pour obtenir le PDF complet
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Ensemble de données : basé sur un ensemble de données de scènes naturelles, évaluez strictement la fiabilité du test
Les ensembles de données utilisés dans l'expérience comprennent l'ensemble de données Natural Scenes Dataset (NSD) et l'ensemble de données COCO.L'ensemble de données NSD contient des IRMf haute résolution de 7 Tesla collectées auprès de 8 participants adultes en bonne santé, mais dans l'analyse expérimentale spécifique, les chercheurs ont principalement analysé les 4 sujets qui ont terminé toute la collecte de données.
Les chercheurs ont également prétraité l'ensemble de données NSD pour effectuer un rééchantillonnage temporel afin de corriger les différences de synchronisation des tranches et une interpolation spatiale pour ajuster le mouvement de la tête et la distorsion spatiale. Par exemple, des modifications telles que le recadrage peuvent entraîner une incompatibilité entre le titre d'origine et le cadre de délimitation de l'instance, comme illustré dans la figure ci-dessous. Pour garantir la cohérence des données, les chercheurs ont réannoté les images recadrées, généré 8 légendes pour chaque image à l'aide de BLIP2 et généré des cadres de délimitation pour ces images à l'aide de DETTR.

Étant donné que certaines images sont coupées, il existe une incompatibilité entre la légende d'origine et le cadre de délimitation de l'instance.
De plus, pour assurer la compatibilité entre les données IRMf et les LLM et pour obtenir un suivi des instructions et des interactions diverses, l'équipe a élargi sept types de dialogues lors de l'annotation du NSD en langage naturel, à savoir : les descriptions brèves, les descriptions détaillées, les dialogues continus, les tâches de raisonnement complexes, la reconstruction des instructions et la localisation des concepts.
Enfin, pour assurer la standardisation des données, les chercheurs ont utilisé une interpolation trilinéaire pour ajuster les données à une dimension uniforme, ont défini la normalisation IRMf à 83 × 104 × 81 et ont divisé les données en patchs de 14 × 14 × 14 après avoir appliqué un remplissage nul aux bords pour préserver les informations locales.
Architecture du modèle : un cadre d'intégration multimodal intégrant l'extraction de caractéristiques IRMf et les LLM
Afin de résoudre la reconstruction visuelle de l'activité cérébrale et d'éliminer le problème de fusion des LLM et des données multimodales, l'équipe de recherche a conçu de manière innovante un cadre d'intégration multimodale qui intègre l'extraction de caractéristiques IRMf et un grand modèle de langage.Comme le montre la figure suivante :
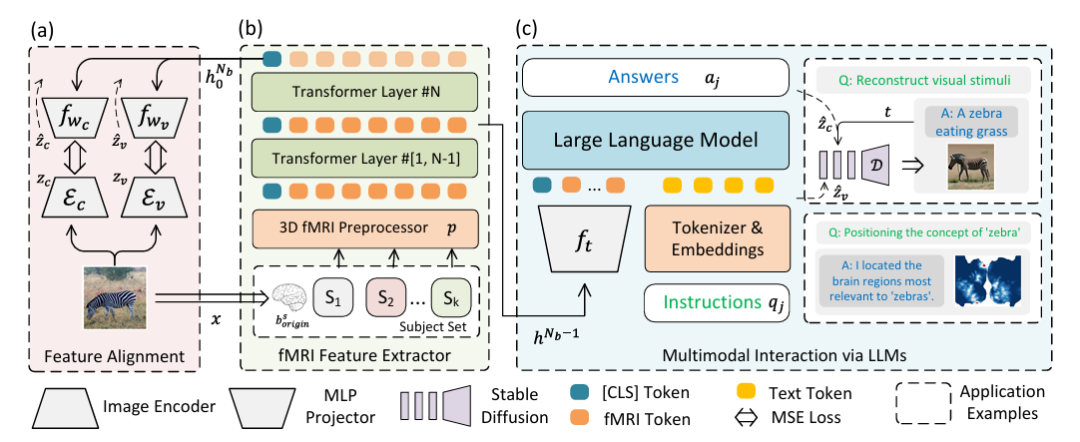
Spécifiquement,La partie (a) de la figure ci-dessus décrit le chemin à deux flux pour l'alignement des fonctionnalités à l'aide de l'autoencodeur variationnel (VAE) et de l'intégration CLIP.Dans le cadre expérimental, CLIP ViT-L/14 et AutocoderKL sont intégrés comme extracteurs de caractéristiques d'image, et deux perceptrons à deux couches fwc et fwv avec une dimension cachée de 1024 sont utilisés pour s'aligner respectivement sur les caractéristiques VAE (zv = Ev) et CLIP (zc = Ec).
La partie (b) de la figure ci-dessus décrit un préprocesseur IRMf 3D p et un extracteur de caractéristiques IRMf (extracteur de caractéristiques fMRl).Pour les données IRMf, un encodeur de transformation à 16 couches avec une taille cachée de 768 a été utilisé pour extraire les caractéristiques, et l'étiquette de classe de la dernière couche a été utilisée comme sortie. Revenez ensuite à la figure (a) pour l’alignement afin d’obtenir une reconstruction visuelle de haute qualité.
La partie (c) de la figure ci-dessus représente les LLM multimodaux intégrés à l’IRMf.C'est-à-dire que l'interaction multimodale est réalisée grâce au LLM (Multimodal Interaction via LLMs). L'objectif principal est d'entrer les fonctionnalités extraites dans les LLM pour traiter les instructions en langage naturel et générer des réponses ou une reconstruction visuelle. Cette partie utilise l'état caché avant-dernier du réseau hᴺᵇ⁻¹ comme marqueur multimodal pour les données IRMf, fₜ est un perceptron à deux couches, « Instruction » représente l'instruction en langage naturel et « Réponse » représente la réponse générée par les LLM.
Après un réglage fin basé sur les instructions, le modèle peut communiquer directement via le langage naturel et prendre en charge la reconstruction visuelle et la reconnaissance de position des concepts exprimés en langage naturel, en utilisant respectivement UnCLIP pour la reconstruction visuelle et GradCAM pour la localisation des concepts. Dans la figure, D représente UnCLIP gelé.
Résultats expérimentaux : Trois expériences majeures et de multiples comparaisons montrent que le nouveau cadre est performant dans le décodage des signaux cérébraux
Pour évaluer les performances du cadre proposé, les chercheurs ont mené divers types d’expériences telles que le sous-titrage et la réponse aux questions, la reconstruction visuelle et la localisation de concepts, et les ont comparées à d’autres méthodes différentes pour vérifier la faisabilité et l’efficacité du cadre.
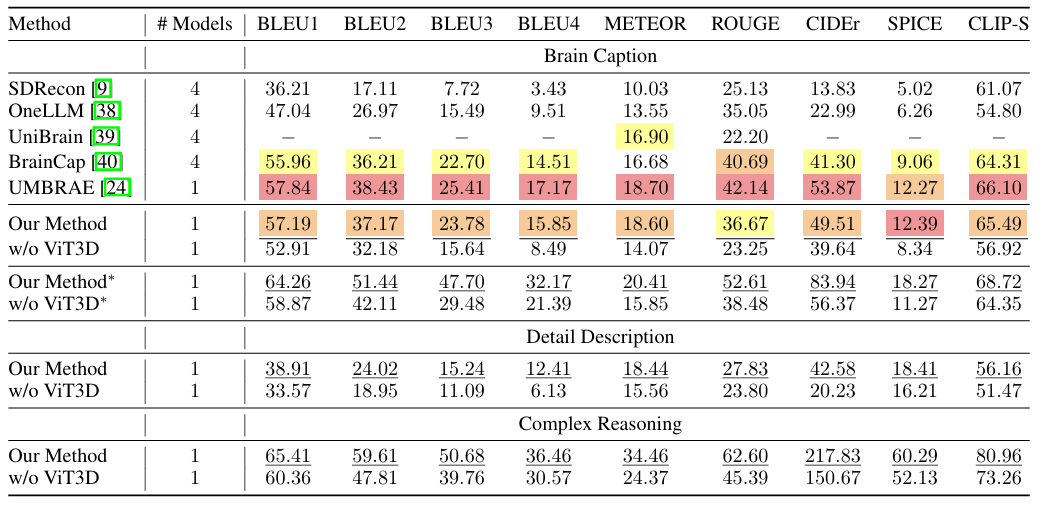
Comme le montre la figure ci-dessous, le cadre proposé montre d’excellentes performances sur la plupart des indicateurs de la tâche de capture cérébrale. De plus, le cadre présente une bonne capacité de généralisation sans avoir à former un modèle distinct pour chaque sujet ou à introduire des paramètres spécifiques au sujet.Les chercheurs ont également combiné des tâches de description détaillée et de raisonnement complexe, et le cadre a également atteint des performances de pointe sur ces deux tâches, démontrant qu'il peut non seulement générer des légendes simples, mais également réaliser des descriptions détaillées et effectuer un raisonnement complexe.
Dans l’expérience de reconstruction visuelle, comme le montre la figure ci-dessous. La méthode proposée fonctionne bien dans la correspondance de fonctionnalités de haut niveau, démontrant la capacité du modèle à utiliser efficacement les LLM pour interpréter des données visuelles complexes.La robustesse sur divers stimuli visuels confirme la compréhension globale des données IRMf par la méthode proposée. Les expériences sans ingrédients clés tels que les fonctionnalités LLM et VAE montrent une baisse des scores, soulignant l'importance de chaque élément de l'approche étudiée, qui est cruciale pour obtenir des résultats de pointe.
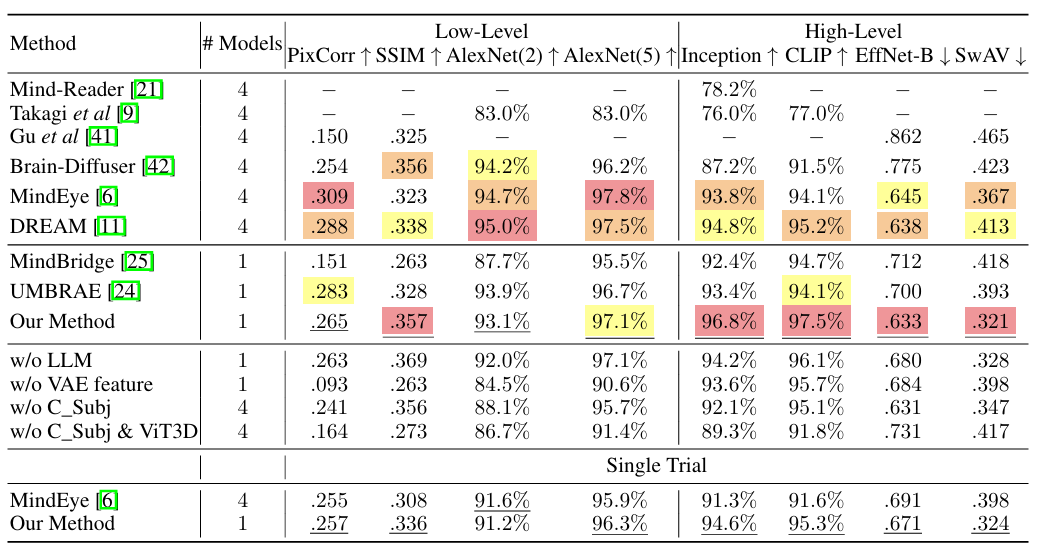
De plus, les chercheurs ont effectué une validation par essai unique, en choisissant d’utiliser uniquement le premier stimulus visuel, similaire à l’approche MindEye. Les résultats montrent que même dans des conditions plus strictes, la méthode proposée ne montre qu’une légère dégradation des performances.Il prouve sa faisabilité dans une application pratique.
Dans les expériences de localisation de concepts, les chercheurs ont d’abord affiné les LLM pour extraire les concepts cibles du langage naturel, qui, une fois codés par l’encodeur de texte CLIP, sont devenus les cibles de GradCAM. Pour améliorer la précision de la localisation, les chercheurs ont formé trois modèles avec différentes tailles de patch (14, 12 et 10) et ont utilisé l'avant-dernière couche de tous les modèles pour extraire des caractéristiques sémantiques. Comme le montre la figure ci-dessous, cela montreLa méthode proposée est capable de distinguer les emplacements de différentes sémantiques dans les signaux cérébraux du même stimulus visuel.

Pour vérifier l’efficacité de cette méthode, les chercheurs ont mené une étude d’ablation sur des concepts sémantiques. Après avoir localisé les concepts dans les signaux cérébraux d'origine, les signaux dans les voxels identifiés sont mis à zéro et les signaux cérébraux modifiés sont ensuite utilisés pour l'extraction de caractéristiques et la reconstruction visuelle. Comme le montre la figure ci-dessous, la suppression de l’activité neuronale dans des régions cérébrales spécifiques associées à certains concepts sémantiques entraînera l’ignorance de la sémantique correspondante dans la reconstruction visuelle.Cela confirme la validité de l’approche de localisation des concepts dans les signaux cérébraux et démontre la capacité de la méthode à extraire et à modifier les informations sémantiques dans l’activité cérébrale, ce qui est crucial pour comprendre le traitement des informations sémantiques dans le cerveau.

Dans l’ensemble, notre cadre exploite la puissance de Vision Transformer 3D avec des données IRMf, améliorées par l’intégration de LLM, conduisant à des améliorations significatives dans la reconstruction des stimuli visuels à partir des signaux cérébraux et offrant une compréhension plus précise et interprétable des mécanismes neuronaux sous-jacents. Cette réalisation ouvre une nouvelle voie de recherche pour le décodage et l’interprétation de l’activité cérébrale et revêt une grande importance pour les neurosciences et l’interface cerveau-ordinateur.
Décoder la vérité sur le fonctionnement du cerveau humain et explorer l'instrument le plus mystérieux de la nature
Le cerveau est l’organe biologique le plus important de l’être humain et l’instrument le plus sophistiqué de la nature. Il possède des centaines de milliards de cellules nerveuses et des milliards de synapses connectées, formant des réseaux neuronaux et des circuits neuronaux qui dominent diverses fonctions cérébrales. Et avec le développement continu des technologies des sciences de la vie et de l’intelligence artificielle, la vérité sur le fonctionnement du cerveau devient de plus en plus claire.
Il convient de mentionner que l'Institut d'automatisation de l'Académie chinoise des sciences, où cet article a été publié, est un leader dans le développement de l'intelligence artificielle dans mon pays et mène depuis longtemps des recherches dans le domaine des sciences du cerveau, en particulier dans le codage et le décodage des informations visuelles dans le cerveau humain. En plus de l'équipe du professeur Zeng Yi mentionnée ci-dessus, l'institut a publié de nombreux articles de haut niveau liés aux sciences du cerveau, qui ont été inclus dans des revues de renommée internationale.
Par exemple, fin 2008, les résultats de recherche publiés par l'équipe dirigée par le professeur He Huiguang de l'école, intitulés « Reconstructing Perceived Images from Human Brain Activities with Bayesian Deep Multiview Learning », ont été inclus dans la revue internationale faisant autorité IEEE Transactions on Neural Networks and Learning Systems dans le domaine des réseaux neuronaux et de l'apprentissage automatique.
Dans cette étude, l’équipe de recherche a établi la relation entre les images visuelles et les réponses cérébrales d’une manière scientifiquement fondée.Le problème de reconstruction d'image visuelle est transformé en un problème d'inférence bayésienne de vues manquantes dans un modèle à variables latentes multi-vues. Cette recherche fournit non seulement un outil puissant pour explorer le mécanisme de traitement de l’information visuelle du cerveau, mais joue également un certain rôle dans la promotion du développement d’interfaces cerveau-ordinateur et d’une intelligence semblable à celle du cerveau.
En plus de l'Institut d'automatisation de l'Académie chinoise des sciences, une équipe de recherche de l'Université nationale de Singapour utilise également l'IRMf pour enregistrer les images vues par les sujets, puis utilise des algorithmes d'apprentissage automatique pour les restaurer en images. Les résultats associés ont été publiés sur arXiv sous le titre « Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding ».

De plus, de nombreuses entreprises commerciales se précipitent également pour explorer le « monde du cerveau ».Il n'y a pas longtemps, Elon Musk a également partagé ses réflexions sur sa société d'interface cerveau-ordinateur Neuralink et sur la technologie d'interface cerveau-ordinateur lors de la conférence des neurochirurgiens de 2024.Certains ont même suggéré que le coût des interfaces cerveau-ordinateur ne devrait pas être trop élevé.
En bref, la technologie de décodage du cerveau peut être considérée comme un processus continu et en développement rapide. Qu’elles soient promues par des institutions de recherche scientifique ou des entreprises commerciales, elles surfent sur le vent d’est de l’intelligence artificielle et de l’apprentissage automatique pour accélérer continuellement l’arrivée de l’ère du cerveau intelligent. Il faut également croire que les progrès scientifiques se traduiront inévitablement par des applications, comme le développement d’interfaces cerveau-ordinateur, l’utilisation de machines au profit des patients dont le système nerveux est endommagé, etc.









