Command Palette
Search for a command to run...
De La Vision Par Ordinateur À l'IA Médicale, Xie Weidi De l'Université Jiao Tong De Shanghai a Publié Un Certain Nombre De Résultats, Qui Ont Été Publiés Dans Les sous-journaux Nature/NeurIPS/CVPR, etc.

Ces dernières années, le développement de l’IA pour la science s’est accéléré, ce qui a non seulement apporté des idées de recherche innovantes dans le domaine de la recherche scientifique, mais a également élargi les canaux de mise en œuvre de l’IA et lui a fourni des scénarios d’application plus stimulants. Dans ce processus, de plus en plus de chercheurs en IA ont commencé à se concentrer sur les domaines de recherche scientifique traditionnels tels que la médecine, les matériaux et la biologie, en explorant les difficultés de recherche et les défis industriels qui y sont liés.
Xie Weidi, professeur associé titulaire à l'Université Jiao Tong de Shanghai, est profondément impliqué dans le domaine de la vision par ordinateur. Il revient en Chine en 2022 et se consacre à la recherche sur l’intelligence artificielle médicale.Lors du forum COSCon'24 AI for Science coproduit par HyperAI, le professeur Xie Weidi a partagé les réalisations de l'équipe sous plusieurs angles, notamment la construction d'ensembles de données open source et le développement de modèles, sous le titre « Vers le développement d'un modèle généraliste pour les soins de santé ».

HyperAI a organisé et résumé le partage approfondi sans violer l'intention initiale. Voici une transcription des points saillants du discours.
L’intelligence artificielle médicale est une tendance inévitable
La recherche médicale est d’une importance vitale car elle concerne la vie et la santé de chacun. Dans le même temps, le problème de la répartition inégale des ressources médicales n’a pas été fondamentalement résolu depuis longtemps.Nous espérons donc promouvoir les soins médicaux universels et aider chacun à obtenir un diagnostic et un traitement de qualité.
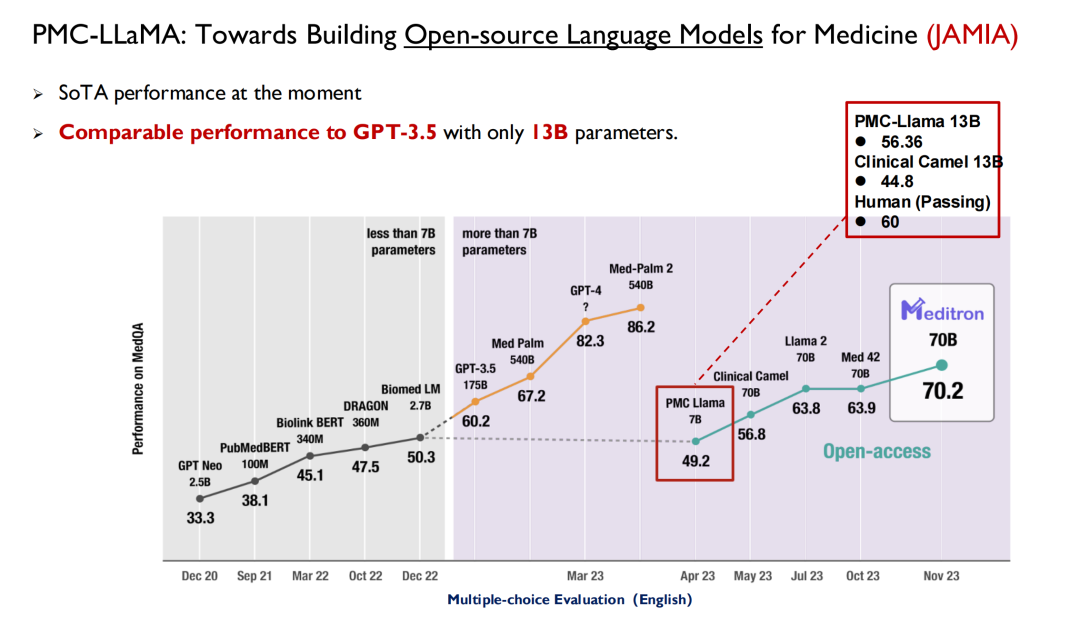
ChatGPT et d’autres grands modèles publiés ces dernières années ont tous utilisé les soins de santé comme principal champ de bataille pour les tests de performance. Comme le montre la figure ci-dessous, lors de l'examen de licence médicale aux États-Unis, avant 2022, les grands modèles pourront atteindre un score de 50, tandis que les humains pourront atteindre 70, de sorte que l'IA n'a pas attiré beaucoup d'attention de la part des médecins.
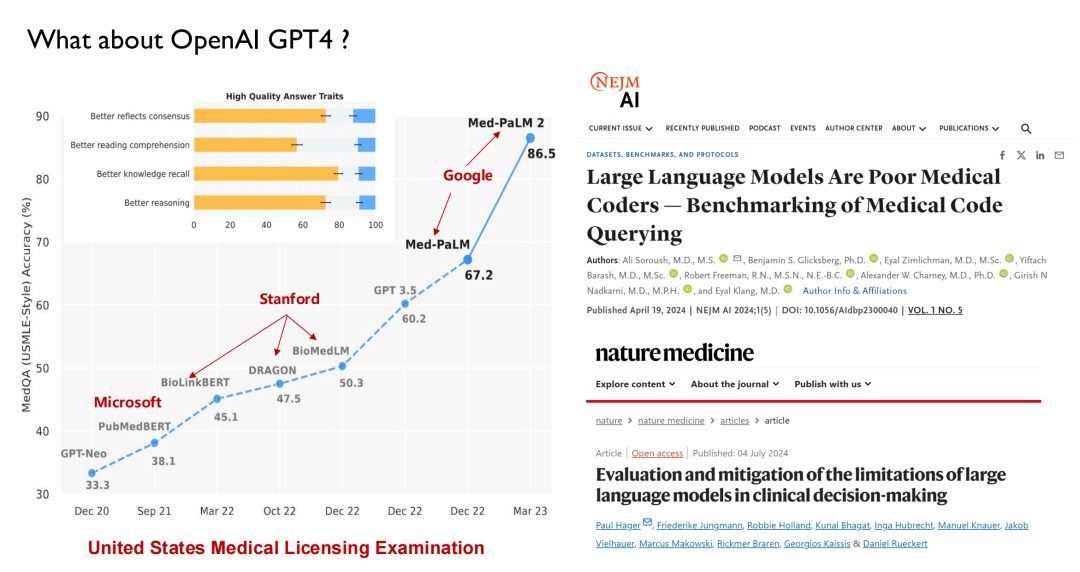
Avec la sortie de GPT 3.5, son score a atteint 60,2, une amélioration significative. Google a ensuite publié Med-PaLM et sa version mise à jour, avec un score maximal atteignant 86,5. Le GPT-4 d'aujourd'hui peut atteindre 90 points. Ces performances élevées et cette vitesse d’itération ont incité les médecins à commencer à s’intéresser à l’IA.De nombreuses écoles de médecine proposent désormais une nouvelle discipline : la médecine intelligente.
De même, les étudiants en médecine ne sont pas les seuls à devoir se renseigner sur l’intelligence artificielle ;Les étudiants en IA peuvent également acquérir des connaissances médicales au cours de leur dernière année.L’Université de Harvard et d’autres institutions ont déjà mis en place des cours pertinents dans les filières de l’IA.
Mais d’un autre côté, des études dans des revues académiques telles que Nature Medicine montrent queEn réalité, le grand modèle linguistique ne comprend pas la médecine.Par exemple, le grand modèle ne comprend pas actuellement les codes CIM (codes de diagnostic du système de classification internationale des maladies) et il lui est difficile de fournir des conseils médicaux opportuns basés sur les résultats de l'examen du patient comme un médecin. On constate que les grands modèles présentent encore de nombreuses limites dans le domaine médical.Je pense que cela ne remplacera jamais les médecins, et ce que notre équipe veut faire, c’est faire en sorte que ces modèles aident mieux les médecins.
L'objectif principal de l'équipe : construire un système d'intelligence artificielle médicale générale
Je suis retourné en Chine en 2022 et j'ai commencé à mener des recherches sur l'intelligence artificielle médicale. Ce que je vais donc partager aujourd'hui, ce sont principalement les résultats de l'équipe au cours des deux dernières années. L’industrie médicale couvre un large éventail de domaines et nous ne pouvons pas dire que le modèle que nous avons développé soit universel, mais nous espérons qu’il pourra couvrir autant de tâches importantes que possible.
Comme le montre la figure ci-dessous,Du côté des entrées, nous espérons prendre en charge plusieurs modes.Par exemple, des images, de l'audio, des dossiers médicaux des patients, etc. Après avoir été saisis dans le modèle généraliste multimodal pour la médecine, les médecins peuvent interagir avec lui.La sortie du modèle a au moins deux formes, l’une est visuelle,La localisation de la lésion est déterminée par segmentation et détection.Le deuxième est le texte (Texte),Résultats de diagnostic de sortie (Diagnosis) ou rapports (Report).
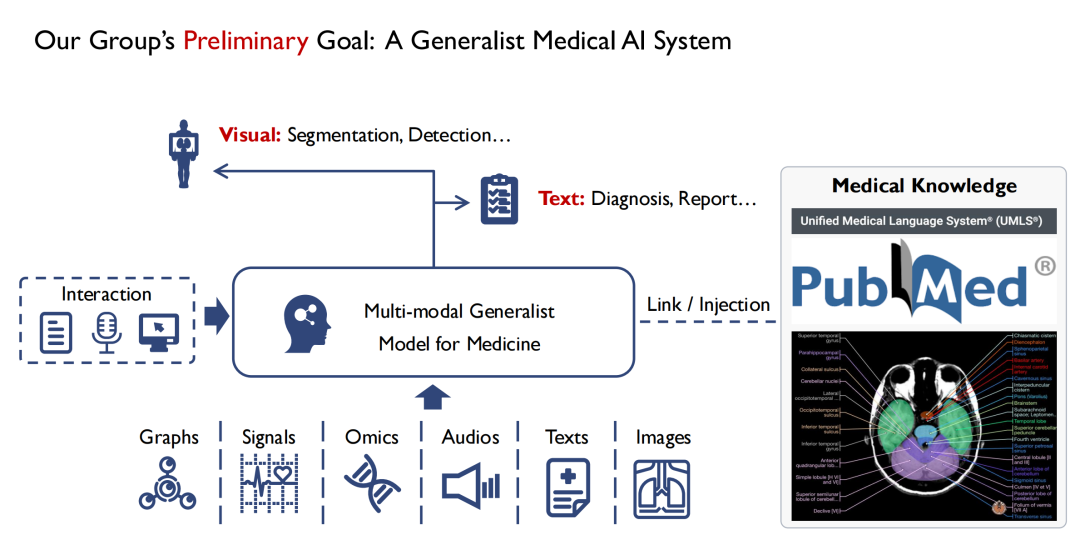
Je suis diplômé en vision par ordinateur. D’après mes observations, une grande différence entre la vision et la médecine est que la plupart des connaissances en médecine, en particulier la médecine fondée sur des preuves, sont résumées à partir de l’expérience humaine. Si un débutant peut épuiser tous les livres de médecine, il peut au moins devenir un expert médical en théorie. Donc,Au cours du processus de formation du modèle, nous espérons également y injecter toutes les connaissances médicales.Car si le modèle manque de connaissances médicales de base, il sera difficile de gagner la confiance des médecins et des patients.
Donc, en résumé,L’objectif principal de notre équipe est de construire un modèle médical universel multimodal et d’y injecter autant de connaissances médicales que possible.
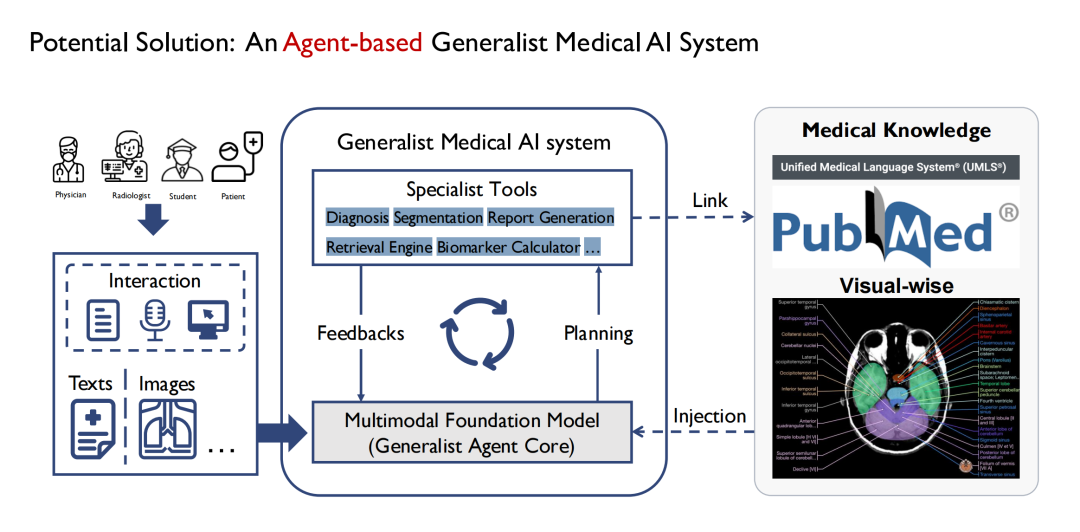
Au départ, nous avons commencé à définir des modèles généraux et avons progressivement découvert qu’il n’était pas réaliste de construire un modèle médical aussi omnipotent que GPT-4. Étant donné qu’il existe de nombreux services à l’hôpital et que chaque service a des tâches différentes, il est difficile de disposer d’un modèle général pour couvrir toutes les tâches.Nous avons donc choisi de l’implémenter via Agent.Comme le montre la figure ci-dessous, le modèle général au milieu est composé de plusieurs sous-modèles, et chaque sous-modèle est essentiellement un agent, et le modèle général est finalement construit sous la forme d'un multi-agent.
Ses avantages sont que différents agents peuvent accepter différentes entrées, de sorte que l’extrémité d’entrée du modèle peut être plus complexe et diversifiée ; plusieurs agents peuvent également former une chaîne de pensée dans le processus de gestion de différentes tâches étape par étape ; la sortie est également plus riche, par exemple, un agent peut effectuer la segmentation de plusieurs types d'images médicales telles que CT et IRM ; en même temps, il offre également une meilleure évolutivité.
Contribuer à des ensembles de données open source de haute qualité
En me concentrant sur le grand objectif de construire un modèle médical universel multimodal, je vais maintenant présenter les réalisations de l'équipe sous de multiples aspects, notamment les ensembles de données open source, les grands modèles linguistiques, les agents de diagnostic des maladies, etc.
Le premier est notre contribution aux ensembles de données open source.
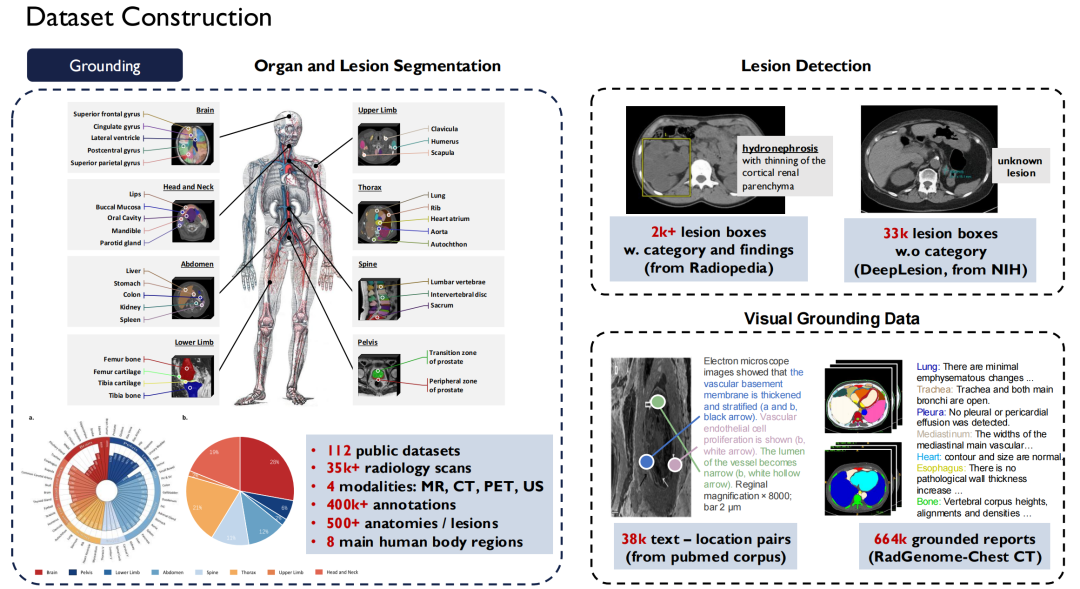
Les ensembles de données ne manquent pas dans le domaine médical, mais les données de haute qualité et librement accessibles sont relativement rares en raison de problèmes de confidentialité dès la conception. En tant qu’équipe universitaire, nous espérons contribuer à l’industrie avec davantage de données open source de haute qualité.Après mon retour en Chine, j’ai commencé à constituer un ensemble de données médicales à grande échelle.
En termes de texte, nous avons collecté plus de 30 000 livres médicaux, contenant 4 milliards de jetons ; a parcouru toute la littérature médicale dans PubMed Central (PMC), y compris 4,8 millions d'articles et 75 milliards de jetons ; et j'ai collecté des livres médicaux en huit langues, dont le chinois, l'anglais, le russe et le japonais sur Internet et les ai convertis en texte.
aussi,Nous avons également construit Super Instructions dans le domaine médical.Compte tenu de la diversité des tâches, 124 tâches médicales sont répertoriées, impliquant 13,5 millions d'échantillons.

Les données textuelles sont plus faciles à obtenir, mais les données vision-langage (paires image-texte) sont plus difficiles à obtenir. Nous avons analysé environ 200 000 cas sur le site Web Radiopaedia, collecté des images et leurs légendes à partir d'articles et plus de 30 000 volumes de rapports de radiologie de base.
Actuellement, la plupart de nos données sont open source.
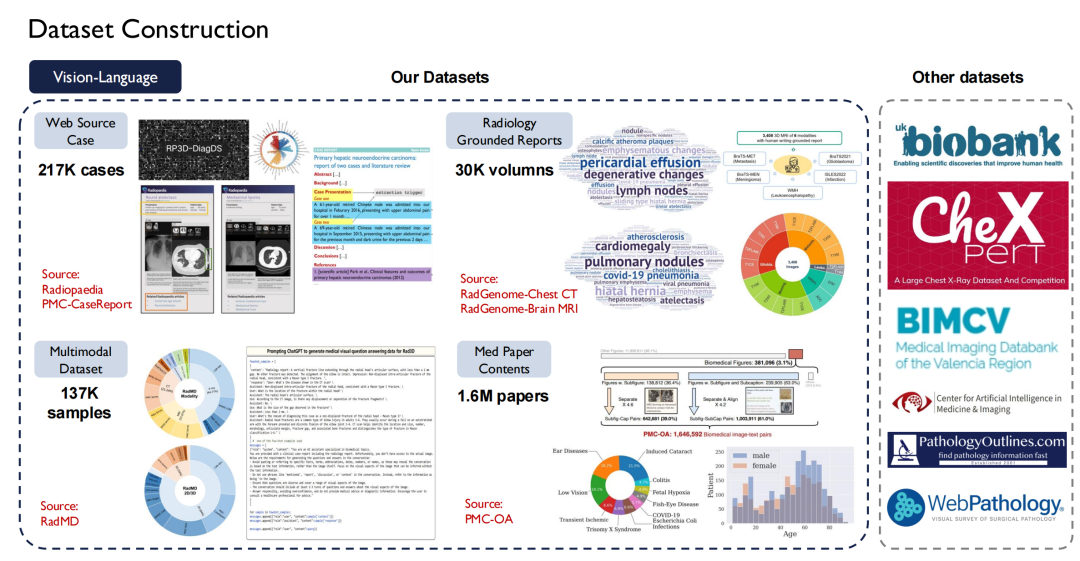
Le côté droit de la figure ci-dessus montre d’autres ensembles de données publics, tels que UK Biobank, pour lequel nous avons payé pour acheter des données sur près de 100 000 patients au Royaume-Uni pendant 10 ans ; De plus, Pathology Outlines fournit des connaissances complètes en pathologie.
En termes de données de mise à la terre,Il s’agit des données de segmentation et de détection que je viens de mentionner.Nous avons unifié près de 120 ensembles de données publiques d'images radiologiques disponibles sur le marché en une seule norme, ce qui a donné lieu à plus de 35 000 images de radiologie 2D/3D.Il couvre quatre modalités : IRM, CT, PET et US, avec 400 000 annotations à grain fin, et ces données couvrent 500 organes du corps.Parallèlement, nous avons élargi la description des lésions et rendu tous ces ensembles de données open source.
Itération continue pour créer un modèle médical professionnel
Modèle de langage
Seuls des ensembles de données open source de haute qualité peuvent aider les étudiants et les chercheurs à réaliser une meilleure formation de modèles. Ensuite, je présenterai les réalisations de l’équipe sur le modèle.
Le premier est le modèle de langage, qui est un moyen d’injecter rapidement des connaissances humaines dans le modèle. En avril dernier, nous avons lancé un modèle appelé PMC-LLaMA, et les recherches associées ont été publiées dans JAMIA sous le titre « Towards Building Open-source Language Models for Medicine ».
Adresse du document :
https://academic.oup.com/jamia/article/31/9/1833/7645318
Il s’agit du premier modèle de langage open source de grande taille que nous avons développé dans le domaine médical. Nous avons formé toutes les données médicales et les données papier mentionnées ci-dessus dans le modèle, effectué un entraînement autorégressif, puis affiné les instructions pour convertir les données en paires questions-réponses.
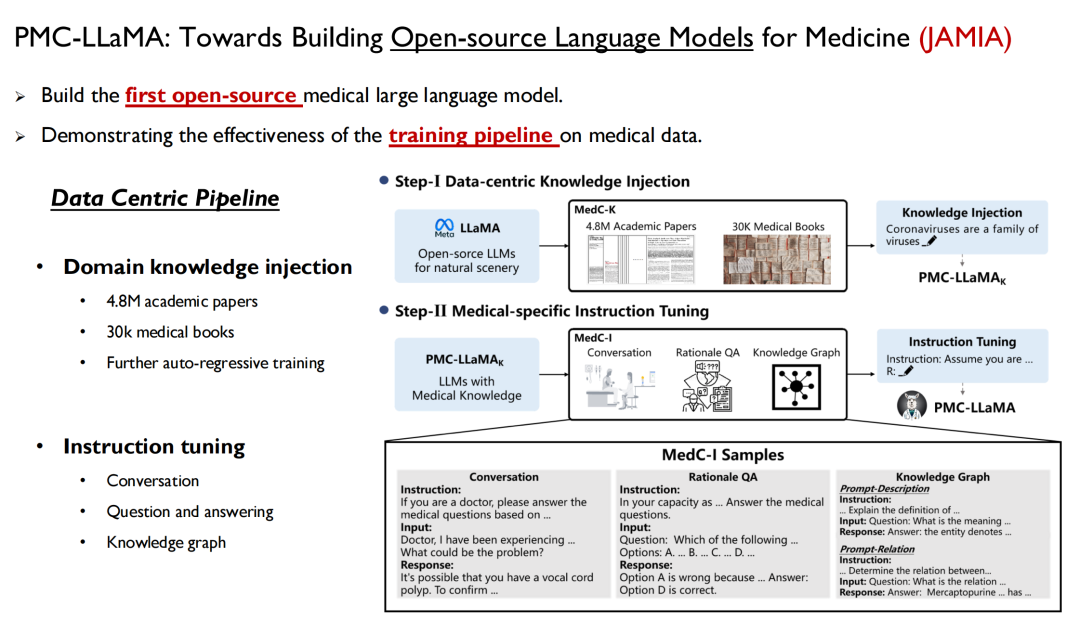
Les chercheurs de l’Université Yale ont mentionné dans leur article : PMC-LLaMA est le premier modèle médical open source dans le domaine.De nombreux chercheurs l'ont ensuite utilisé comme base de référence, mais à mon avis, il existe toujours un écart entre le PMC-LLaMA et les modèles à source fermée, nous continuerons donc à itérer et à mettre à niveau ce modèle à l'avenir.
Par la suite, nous avons publié un autre article dans Nature Communications : « Vers la construction de modèles linguistiques multilingues pour la médecine ».Un modèle médical multilingue a été lancé, couvrant six langues, dont l'anglais, le chinois, le japonais, le français, le russe et l'espagnol, et formé avec 25 milliards de jetons liés à la médecine. En raison de l'absence d'un ensemble de tests standard multilingues unifié, nous avons également créé un référentiel connexe que tout le monde peut tester.
Dans la pratique, nous avons constaté qu’à mesure que le modèle de base est mis à niveau et que des connaissances médicales y sont injectées, les performances du grand modèle médical résultant seront également améliorées.
La plupart des tâches mentionnées ci-dessus sont des « questions à choix multiples », mais nous savons tous qu'il est impossible pour les médecins de répondre uniquement à des questions à choix multiples dans leur travail réel, nous espérons donc que le grand modèle de langage pourra être intégré dans le flux de travail du médecin sous forme de texte libre. Compte tenu de cela,Dans notre nouvelle recherche, nous nous concentrerons davantage sur les tâches cliniques, collecterons des ensembles de données pertinents et améliorerons l’évolutivité clinique du modèle.
Le document concerné est toujours en cours d’examen.
Modèle de langage visuel
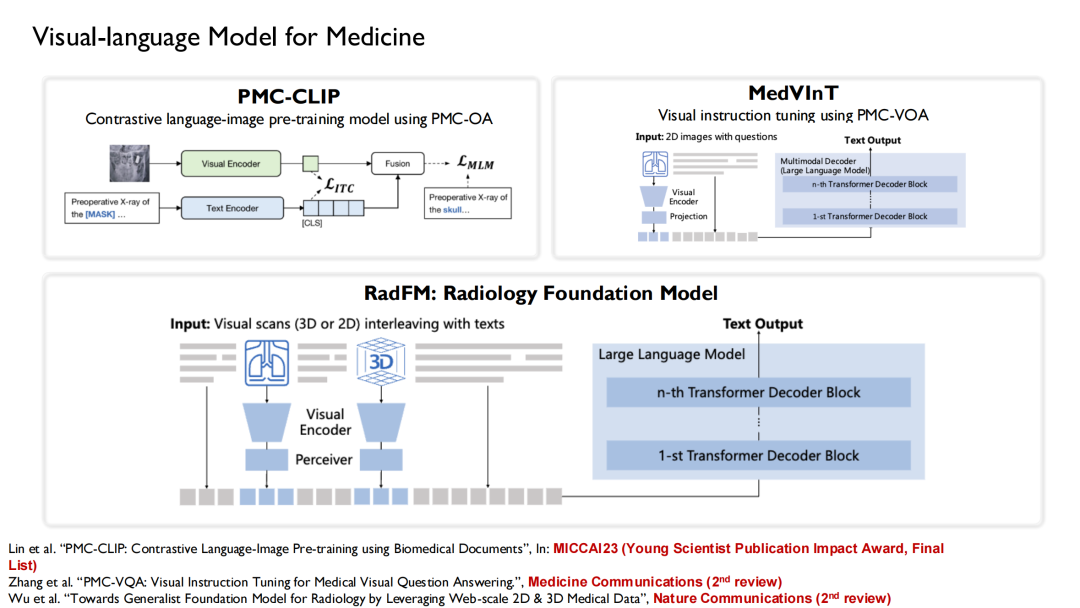
De même, nous avons été l’une des premières équipes à mener des recherches sur les modèles de langage visuel dans le domaine médical. Sur la base des données mentionnées ci-dessus,Nous avons construit 3 ensembles de données open source :
* Collecté 1,6 million de paires d'images-légendes à grande échelle à partir de PubMed Central et construit l'ensemble de données PMC-OA ;
* Génération de 227 000 paires de questions-réponses visuelles médicales à partir du PMC-OA pour former le PMC-VQA ;
* Un ensemble de données Rad3D a été construit en collectant 53 000 cas et 48 000 paires d'images-légendes multiples de l'espèce Radiopaedia.
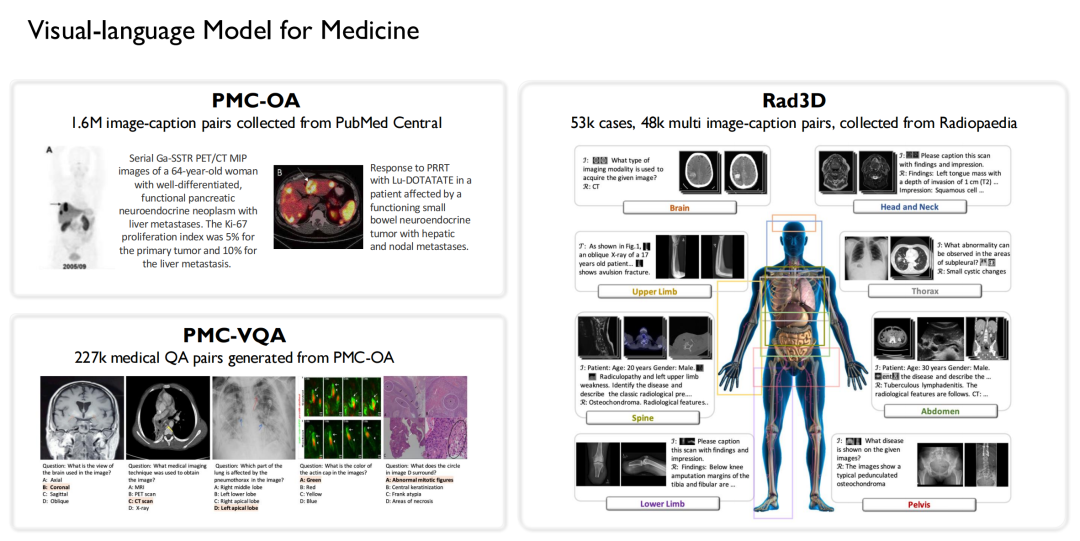
Sur la base de ces ensembles de données, nous avons combiné les modèles linguistiques qui ont été formés.Trois versions de modèles vision-langage ont été formées : PMC-CLIP, MedVInT et RadFM.
PMC-CLIP est un résultat que nous avons publié au MICCAI 2023, la principale conférence dans le domaine de l'imagerie médicale par intelligence artificielle.Finalement, il a été sélectionné comme « Young Scientist Publication Impact Award, Final List ».Le prix est décerné à 3 à 7 articles gagnants sélectionnés parmi les articles publiés au cours des cinq dernières années.
RadFM (Radiology Foundation Model) est désormais très populaire et de nombreux chercheurs l’utilisent comme référence. Au cours du processus de formation,Nous introduisons un entrelacement texte-image dans le modèle, qui peut générer directement des réponses basées sur des questions.
Améliorer les connaissances spécifiques au domaine et améliorer les performances du modèle
L'apprentissage par représentation amélioré par les connaissances (Knowledge-enhanced Representation Learning) doit résoudre le problème de la manière d'injecter des connaissances médicales dans le modèle. Nous avons également mené une série de recherches autour de ce défi.
Tout d’abord, nous devons résoudre le problème de l’origine de la « connaissance ».D’une part, il s’agit de connaissances médicales générales.Provenant d'Internet, ainsi que d'articles et de livres pertinents vendus par UMLS, le plus grand graphique de connaissances dans le domaine médical ;D’autre part, il existe des connaissances spécifiques à un domaine.Par exemple, des rapports de cas, des images radiologiques, des échographies, etc. en plus des connaissances anatomiques, elles peuvent toutes être obtenues sur certains sites Web. Bien entendu, une attention particulière doit être accordée aux questions de droits d'auteur, car le contenu de certains sites Web ne peut pas être utilisé.

Après avoir obtenu cette « connaissance », nous pouvons dessiner un graphe de connaissances.Ce document établit des relations entre maladies, médicaments et médicaments, protéines et protéines, et fournit des descriptions détaillées.
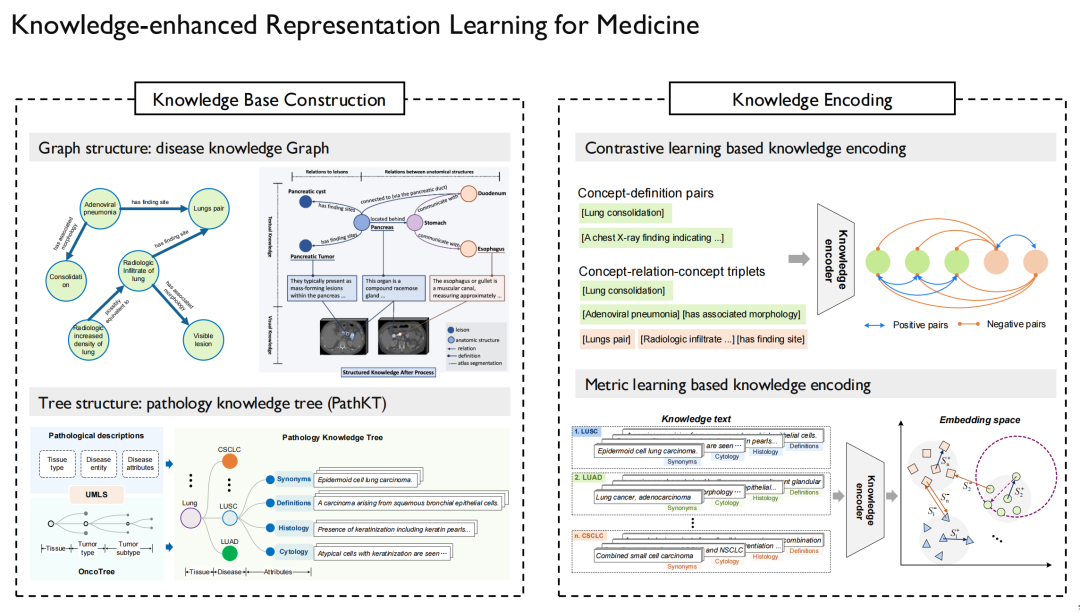
Sur le côté gauche de l’image ci-dessus se trouvent le graphique de connaissances en pathologie et l’arbre de connaissances que nous avons construit.Il est principalement utilisé pour le diagnostic du cancer, car le cancer peut survenir dans divers organes du corps humain et est divisé en différents sous-types, qui conviennent pour être transformés en une forme structurée en arbre. De même, en plus de la pathologie multimodale, nous avons également mené des recherches connexes autour de la radiologie multimodale et de la radiographie multimodale.
L’étape suivante consiste à injecter ces connaissances dans le modèle de langage afin que le modèle puisse mémoriser la relation entre le graphique et les points du graphique.Une fois le modèle de langage formé, il suffit d'aligner le modèle visuel sur le modèle de langage.
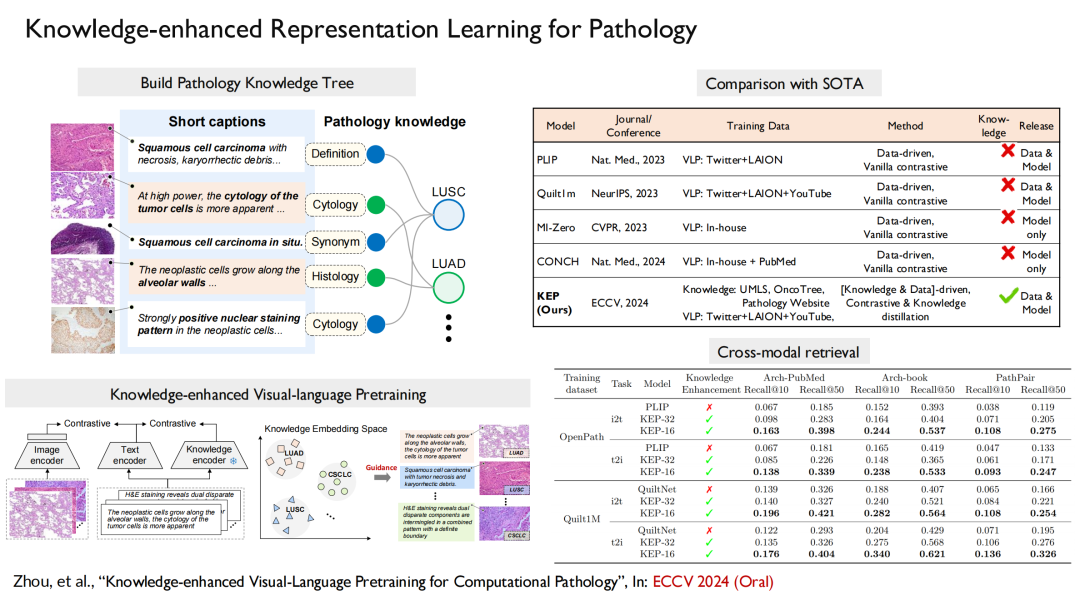
Nous avons comparé nos résultats avec ceux de Microsoft et de Stanford, et les résultats ont montré queLe modèle avec connaissance du domaine ajoutée a des performances bien supérieures à celles des autres modèles sans connaissance du domaine.
Pour la pathologie, notre article « Pré-entraînement visuel-langage amélioré par les connaissances pour la pathologie computationnelle » a été sélectionné pour la meilleure conférence sur l'apprentissage automatique ECCV 2024 (Oral). Dans ce travail, nous construisons un arbre de connaissances et l'injectons dans la formation du modèle, puis alignons la vision sur le langage.
De plus, nous avons utilisé la même méthode pour construire un modèle d'imagerie radiologique multimodale, et les résultats ont été publiés dans Nature Communications sous le titre « Diagnostic de maladie à longue queue à grande échelle sur des images radiologiques ».Le modèle peut générer directement les symptômes correspondants en fonction des images radiologiques du patient.
En résumé,Notre travail a mis en œuvre un processus complet : tout d’abord, nous avons construit le plus grand ensemble de données open source d’images radiologiques, qui contient 200 000 images, 41 000 images de patients, couvrant 930 maladies, etc. deuxièmement, nous avons construit un modèle multimodal et multilingue pour améliorer les connaissances dans des domaines spécifiques ; enfin, nous avons construit un benchmark correspondant.
À propos du professeur Xie Weidi
Il est professeur associé titulaire à l'Université Jiao Tong de Shanghai, lauréat du programme national (étranger) de jeunes talents de haut niveau, du programme de talents de haut niveau d'outre-mer de Shanghai et du programme Shanghai Morning Star. Il est également le jeune chef de projet du projet majeur « Innovation scientifique et technologique 2030 - « Intelligence artificielle de nouvelle génération » du ministère des Sciences et de la Technologie, et le chef de projet de la Fondation nationale des sciences naturelles de Chine.
Il a obtenu son doctorat. du Visual Geometry Group (VGG) de l'Université d'Oxford, où il a étudié sous la direction du professeur Andrew Zisserman et du professeur Alison Noble. Il est l'un des premiers bénéficiaires de la bourse complète Google-DeepMind, de la bourse Chine-Oxford et du prix exceptionnel du département d'ingénierie de l'université d'Oxford.
Ses principaux domaines de recherche sont la vision par ordinateur et l'intelligence artificielle médicale. Il a publié plus de 60 articles, notamment CVPR, ICCV, NeurIPS, ICML, IJCV, Nature Communications, etc., avec plus de 12 500 citations sur Google Scholar. Il a remporté à plusieurs reprises le prix du meilleur article, le prix de la meilleure affiche et le prix du meilleur article de revue lors de conférences et séminaires internationaux de premier plan, et est finaliste du prix MICCAI Young Scientist Publication Impact Award. Il est examinateur spécial pour Nature Medicine et Nature Communications, et est le président de CVPR, NeurIPS et ECCV, les conférences phares dans le domaine de la vision par ordinateur et de l'intelligence artificielle.
* Page d'accueil personnelle :










