Command Palette
Search for a command to run...
Contenant 284 Ensembles De Données, Couvrant 18 Tâches Cliniques, Shanghai AI Lab Et d'autres Ont Publié La Référence Médicale Multimodale GMAI-MMBench

« Avec un tel dispositif médical intelligent, les patients n'ont qu'à s'allonger dessus pour terminer l'ensemble du processus, de l'analyse au diagnostic, en passant par le traitement et la réparation, et parvenir à un redémarrage sain. » Il s'agit d'une intrigue tirée du film de science-fiction de 2013 « Elysium ».

De nos jours, avec le développement rapide de la technologie de l’intelligence artificielle, les scènes médicales montrées dans les films de science-fiction deviendront, espérons-le, une réalité. Dans le domaine médical, les modèles de langage visuel à grande échelle (LVLM) peuvent traiter une variété de types de données tels que l'imagerie, le texte et même des signaux physiologiques, tels que DeepSeek-VL, GPT-4V, Claude3-Opus, LLaVA-Med, MedDr, DeepDR-LLM, etc., montrant un grand potentiel de développement dans le diagnostic et le traitement des maladies.
Cependant, avant que les LVLM puissent être mis en pratique clinique, des tests de référence doivent être établis pour évaluer l’efficacité des modèles. Cependant, les critères de référence actuels sont généralement basés sur une littérature académique spécifique et se concentrent principalement sur un seul domaine, manquant de granularités perceptuelles différentes, ce qui rend difficile l'évaluation exhaustive de l'efficacité et des performances des LVLM dans des scénarios cliniques réels.
En réponse à cela, le Laboratoire d'intelligence artificielle de Shanghai, en collaboration avec plusieurs institutions de recherche scientifique, dont l'Université de Washington, l'Université Monash et l'Université normale de Chine orientale, a proposé le benchmark GMAI-MMBench. GMAI-MMBench est construit à partir de 284 ensembles de données de tâches en aval du monde entier, couvrant 38 modalités d'imagerie médicale, 18 tâches cliniques, 18 départements et 4 granularités perceptuelles au format de réponse aux questions visuelles (VQA), avec une classification complète de la structure des données et une granularité multi-perceptuelle.
La recherche connexe, intitulée « GMAI-MMBench : un benchmark d'évaluation multimodal complet vers l'IA médicale générale », a été sélectionnée pour le benchmark du jeu de données NeurIPS 2024 et publiée sous forme de pré-impression sur arXiv.

Adresse du document :
https://arxiv.org/abs/2408.03361v7
Le « GMAI-MMBench Medical Multimodal Evaluation Benchmark Dataset » est désormais disponible sur le site officiel d'HyperAI et peut être téléchargé en un clic !
Adresse de téléchargement du jeu de données :
https://go.hyper.ai/xxy3w
GMAI-MMBench : le benchmark d'IA médicale générale le plus complet et open source à ce jour
Le processus global de construction de GMAI-MMBench peut être divisé en 3 étapes principales :
Tout d’abord, les chercheurs ont recherché des centaines d’ensembles de données provenant de bases de données publiques mondiales et de données hospitalières. Après avoir examiné, unifié les formats d’image et standardisé les expressions d’étiquettes, ils ont conservé 284 ensembles de données avec des étiquettes de haute qualité.
Il convient de mentionner que ces 284 ensembles de données couvrent une variété de tâches d'imagerie médicale telles que la détection 2D, la classification 2D et la segmentation 2D/3D, et sont annotés par des médecins professionnels, garantissant la diversité des tâches d'imagerie médicale ainsi qu'une pertinence et une précision cliniques élevées.
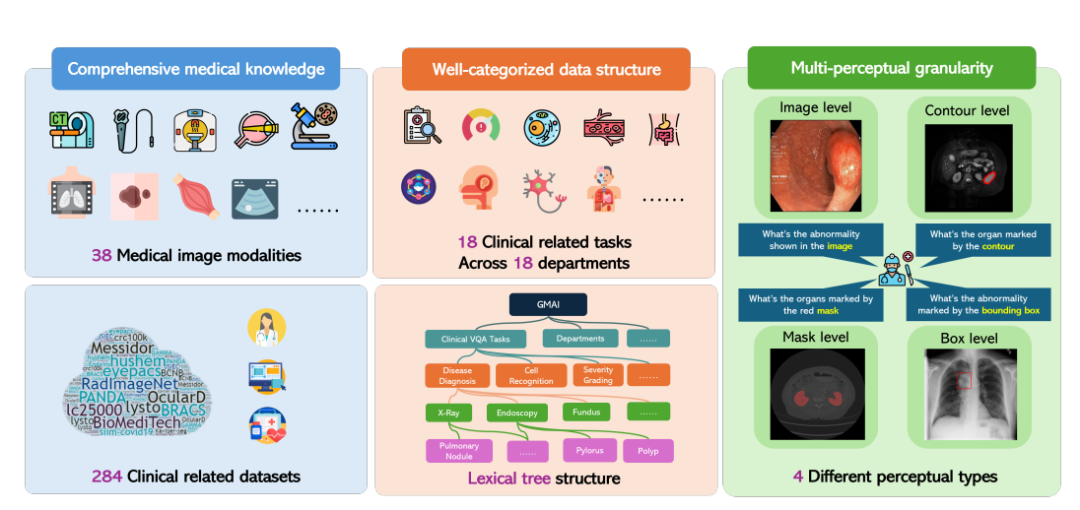
Ensuite, les chercheurs ont classé toutes les étiquettes en 18 tâches cliniques VQA et 18 départements cliniques, ce qui permet d'évaluer de manière exhaustive les avantages et les inconvénients des LVLM sous divers aspects, ce qui est pratique pour les développeurs de modèles et les utilisateurs ayant des besoins spécifiques.
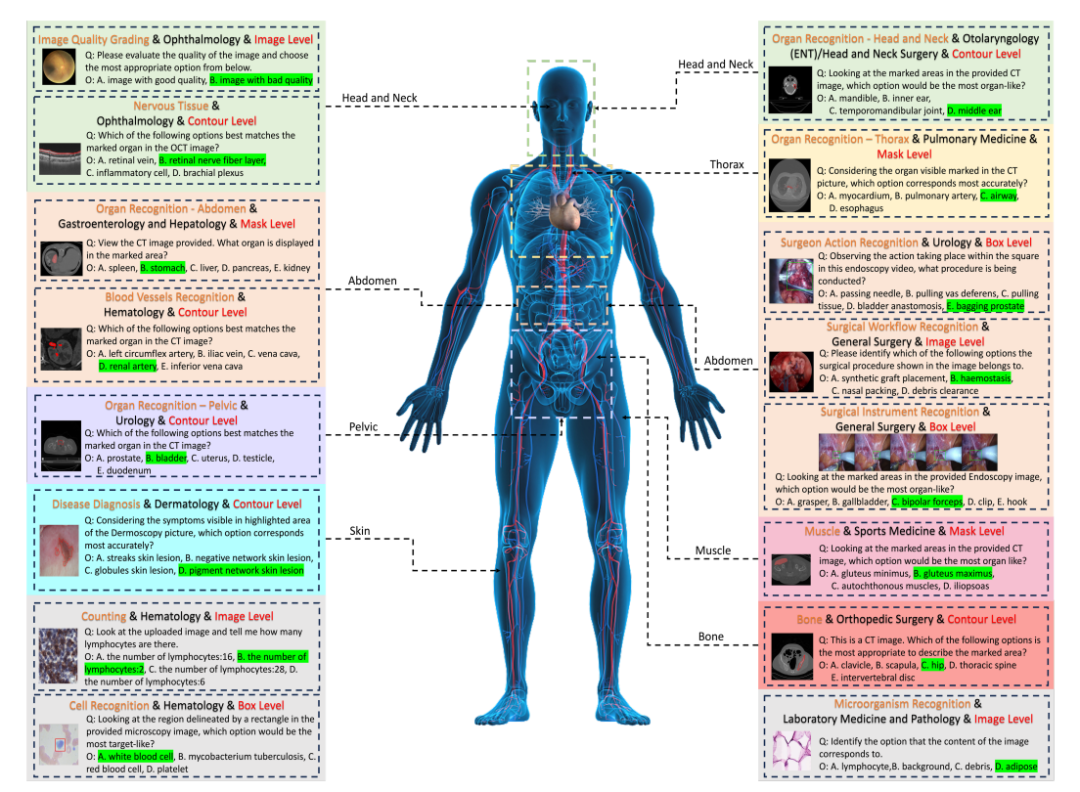
Plus précisément, les chercheurs ont conçu un système de classification appelé structure arborescente lexicale, qui divise tous les cas en 18 tâches cliniques VQA, 18 départements, 38 modalités, etc. « Tâche clinique VQA », « département » et « modalité » sont des termes qui peuvent être utilisés pour récupérer les cas d’évaluation requis. Par exemple, les services d’oncologie peuvent sélectionner des cas liés à l’oncologie pour évaluer les performances des LVLM dans les tâches d’oncologie, améliorant ainsi considérablement la flexibilité et la facilité d’utilisation pour des besoins spécifiques.
Enfin, les chercheurs ont généré des paires question-réponse en fonction de la question et du pool d’options correspondant à chaque étiquette.Chaque question doit contenir une modalité d'image, des invites de tâches et des informations de granularité d'annotation correspondantes. Le benchmark final a été obtenu grâce à une validation supplémentaire et un contrôle manuel.
50 modèles évalués, lequel arrive en tête du benchmark GMAI-MMBench
Afin de promouvoir davantage l'application clinique de l'IA dans le domaine médical,Les chercheurs ont évalué 44 LVLM open source (dont 38 modèles généraux et 6 modèles médicaux spécifiques) et des LVLM commerciaux à source fermée tels que GPT-4o, GPT-4V, Claude3-Opus, Gemini 1.0, Gemini 1.5 et Qwen-VL-Max sur GMAI-MMBench.
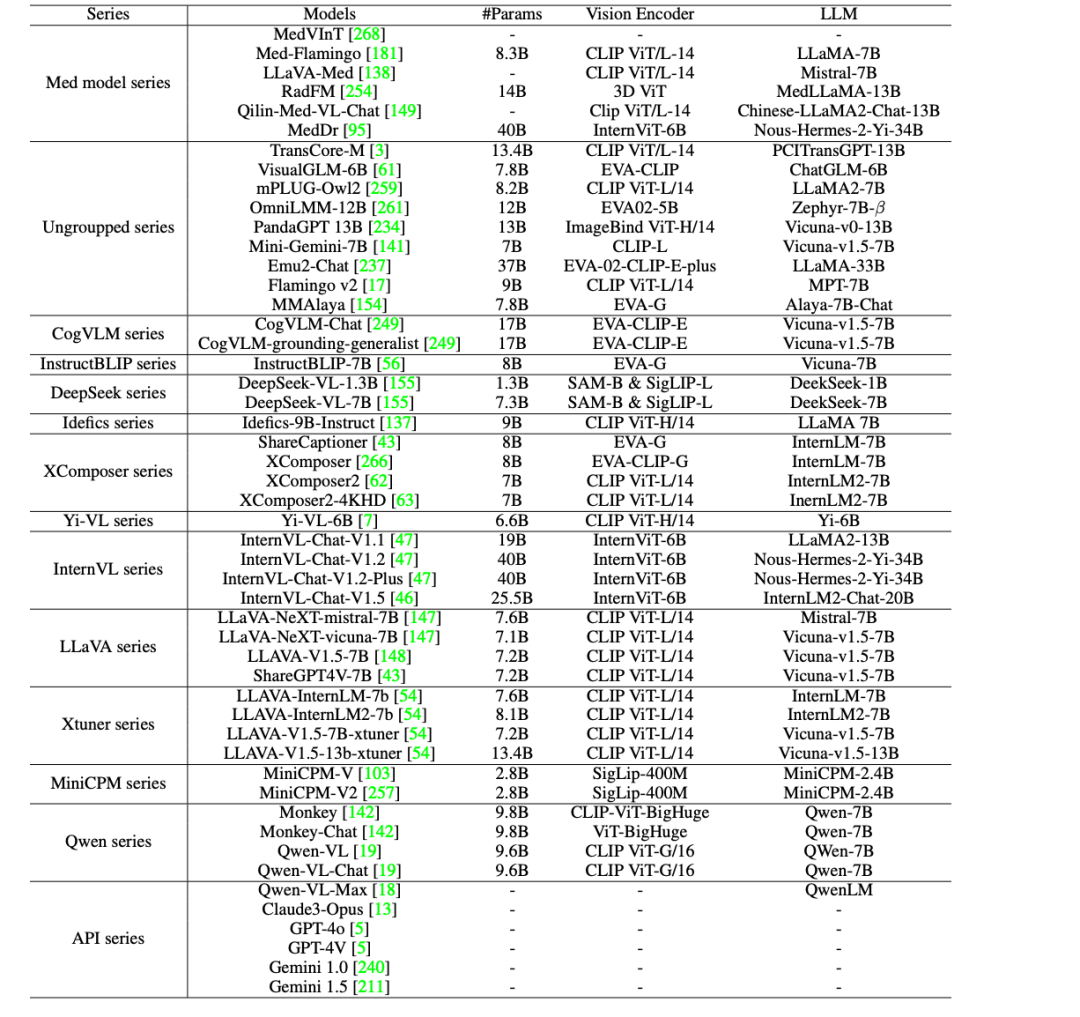
Les résultats montrent qu’il existe encore cinq lacunes majeures dans les LVLM actuels, comme suit :
* Il y a encore une marge d'amélioration dans les applications cliniques : même le modèle le plus performant, GPT-4o, a satisfait aux exigences des applications cliniques pratiques, mais sa précision n'est que de 53,96%, ce qui montre que les LVLM actuels sont insuffisants pour traiter les problèmes professionnels médicaux et qu'il y a encore une énorme marge d'amélioration.
* Comparaison des modèles open source avec les modèles commerciaux : les LVLM open source tels que MedDr et DeepSeek-VL-7B ont une précision d'environ 44%, ce qui surpasse les modèles commerciaux Claude3-Opus et Qwen-VL-Max sur certaines tâches, et sont comparables à Gemini 1.5 et GPT-4V. Cependant, il existe toujours un écart de performance important par rapport au GPT-4o le plus performant.
* La plupart des modèles spécifiques à la médecine peinent à atteindre le niveau de performance général des LVLM à usage général (précision d'environ 30%), à l'exception de MedDr, qui atteint une précision de 43,69%.
* La plupart des LVLM fonctionnent de manière inégale selon les différentes tâches cliniques VQA, les différents services et les différentes granularités perceptuelles. En particulier, dans les expériences avec différentes granularités perceptuelles, la précision des annotations au niveau de la boîte est toujours la plus faible, voire inférieure à celle des annotations au niveau de l'image.
* Les principaux facteurs conduisant à des goulots d’étranglement des performances comprennent les erreurs de perception (telles qu’une mauvaise identification du contenu de l’image), le manque de connaissances dans le domaine médical, le contenu des réponses non pertinentes et le refus de répondre aux questions en raison des protocoles de sécurité.
En résumé, ces résultats d’évaluation indiquent que les performances des LVLM actuels dans les applications médicales ont encore beaucoup de marge d’amélioration et doivent être davantage optimisées pour répondre aux besoins cliniques réels.
Rassembler des ensembles de données médicales open source pour contribuer à faire progresser les soins de santé intelligents
Dans le domaine médical, les ensembles de données open source de haute qualité sont devenus un moteur important du progrès dans la recherche médicale et la pratique clinique. À cette fin, HyperAI a sélectionné pour vous quelques ensembles de données liées à la médecine, qui sont brièvement présentés comme suit :
Ensemble de données médicales VQA à grande échelle PubMedVision
PubMedVision est un ensemble de données médicales multimodales à grande échelle et de haute qualité créé en 2024 par une équipe de recherche du Shenzhen Big Data Research Institute, de l'Université chinoise de Hong Kong et du National Health Data Institute, contenant 1,3 million d'échantillons médicaux VQA.
Afin d'améliorer l'alignement des données graphiques et textuelles, l'équipe de recherche a utilisé le grand modèle visuel (GPT-4V) pour redécrire les images et construire des dialogues dans 10 scénarios, réécrivant les données graphiques et textuelles dans un format questions-réponses, améliorant ainsi l'apprentissage des connaissances visuelles médicales.
Utilisation directe :https://go.hyper.ai/ewHNg
Corpus médical multilingue à grande échelle MMedC
MMedC est un corpus médical multilingue construit par l'équipe Smart Healthcare de l'École d'intelligence artificielle de l'Université Jiao Tong de Shanghai en 2024. Il contient environ 25,5 milliards de jetons couvrant 6 langues principales : anglais, chinois, japonais, français, russe et espagnol.
L'équipe de recherche a également ouvert le modèle de base médical multilingue MMed-Llama 3, qui a obtenu des résultats exceptionnels dans de nombreux tests de performance, surpassant considérablement les modèles open source existants et est particulièrement adapté au réglage fin personnalisé dans le secteur médical.
Utilisation directe :https://go.hyper.ai/xpgdM
Ensemble de données informatiques médicales MedCalc-Bench
MedCalc-Bench est un ensemble de données spécialement conçu pour évaluer les capacités de calcul médical des grands modèles de langage (LLM). Il a été publié conjointement en 2024 par neuf institutions, dont la Bibliothèque nationale de médecine des National Institutes of Health et l'Université de Virginie. Cet ensemble de données contient 10 055 instances de formation et 1 047 instances de test, couvrant 55 tâches informatiques différentes.
Utilisation directe :https://go.hyper.ai/XHitC
Ensemble de données d'évaluation médicale à grande échelle OmniMedVQA
OmniMedVQA est un ensemble de données d'évaluation de questions-réponses visuelles (VQA) à grande échelle axé sur le domaine médical. Cet ensemble de données a été lancé conjointement par l'Université de Hong Kong et le Laboratoire d'intelligence artificielle de Shanghai en 2024. Il contient 118 010 images différentes, couvrant 12 modalités différentes, impliquant plus de 20 organes et parties différents du corps humain, et toutes les images proviennent de scènes médicales réelles. Il vise à fournir une référence d’évaluation pour le développement de grands modèles médicaux multimodaux.
Utilisation directe :https://go.hyper.ai/1tvEH
Ensemble de données d'images médicales MedMNIST
MedMNIST a été publié par l'Université Jiao Tong de Shanghai le 28 octobre 2020. Il s'agit d'une collection de 10 ensembles de données médicales publiques, contenant un total de 450 000 données d'images médicales multimodales 28*28, couvrant différents modes de données, qui peuvent être utilisées pour résoudre des problèmes liés à l'analyse d'images médicales.
Utilisation directe :https://go.hyper.ai/aq7Lp
Les ensembles de données ci-dessus sont recommandés par HyperAI dans ce numéro. Si vous voyez des ressources de jeux de données de haute qualité, n'hésitez pas à laisser un message ou à soumettre un article pour nous le faire savoir !
Plus d'ensembles de données de haute qualité à télécharger :https://go.hyper.ai/jJTaU
Références :
https://mp.weixin.qq.com/s/vMWNQ-sIABocgScnrMW0GA









