Command Palette
Search for a command to run...
D'abord! Quatre Grandes Universités Ont Lancé Conjointement Y-Mol, Un Vaste Modèle Linguistique Pour La Recherche Et Le Développement De Médicaments, Dont Les Performances Globales Sont En Tête De LLaMA2

Les grands modèles de langage représentés par ChatGPT, ChatGLM et LLaMA sont devenus des outils puissants permettant aux gens d'explorer le monde inconnu. Ces modèles comportant des milliards de paramètres ont démontré de puissantes capacités à générer du texte et à comprendre le contexte grâce à une formation minutieuse de corpus de textes à grande échelle. Cependant, la plupart de ces modèles fonctionnent bien dans les tâches générales, mais sont confrontés à des défis considérables dans certains domaines spécifiques, notamment le développement de médicaments.
Contrairement au domaine du traitement du langage naturel, le domaine de la recherche et du développement de médicaments manque d’un paradigme standard unifié, et le processus de recherche et de développement est complexe et coûteux. De plus, il implique de multiples disciplines telles que la chimie computationnelle, la biologie structurale et la bioinformatique. Les données pertinentes sont difficiles à obtenir et les données d’interaction entre les entités liées aux médicaments nécessitent des connaissances de domaine sophistiquées pour être étiquetées.Ces facteurs réunis limitent l’application de grands modèles linguistiques dans la recherche et le développement de médicaments.
En réponse à cela, des équipes de recherche de l'Université du Hunan, de l'Université du Centre-Sud, de l'Université normale du Hunan et de l'Université de Xiangtan ont proposé conjointement un grand modèle de langage Y-Mol guidé par des connaissances biomédicales multi-échelles. Y-Mol est un modèle autorégressif de séquence à séquence qui peut être affiné sur différents corpus de textes et instructions, améliorant considérablement les performances et le potentiel du modèle dans le développement de médicaments. Il s’agit d’une nouvelle avancée dans le domaine du développement de médicaments utilisant de grands modèles linguistiques.
L'étude, intitulée « Y-Mol : un modèle de langage large guidé par les connaissances biomédicales à plusieurs échelles pour le développement de médicaments », a été publiée sous forme de pré-impression sur arxiv.
Points saillants de la recherche :
* Y-Mol est le premier grand modèle de langage construit pour la découverte de médicaments
* Y-Mol construit un ensemble de données d'instructions riche en informations en intégrant des connaissances biomédicales multi-échelles
* Y-Mol excelle dans les interactions médicamenteuses, les interactions médicament-cible, la prédiction des propriétés moléculaires et démontre de solides capacités de compréhension et de polyvalence dans diverses tâches de développement de médicaments

Adresse du document :
https://doi.org/10.48550/arXiv.2410.11550
Suivez le compte officiel et répondez « modèle de développement de médicaments » pour obtenir le PDF complet
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Explorer pleinement deux types d'ensembles de données pour construire un corpus biomédical complet
En termes de construction de l'ensemble de données de pré-formation pour Y-Mol, l'étude a sélectionné deux types d'ensembles de données :Un corpus de textes provenant de publications biomédicales PubMed ; instructions supervisées construites sur un graphe de connaissances biomédicales et données d'inférence extraites de modèles experts.
Afin d'explorer en profondeur les riches connaissances biomédicales contenues dans les publications,L’étude a extrait et prétraité plus de 33 millions de publications couvrant plusieurs disciplines à partir de plateformes de publication en ligne telles que PubMed.Comme le montre la figure A ci-dessous, les chercheurs ont extrait des résumés et des introductions visibles de ces publications sous forme de données textuelles biomédicales (texte reconstruit) pour garantir la qualité et la pertinence du corpus.
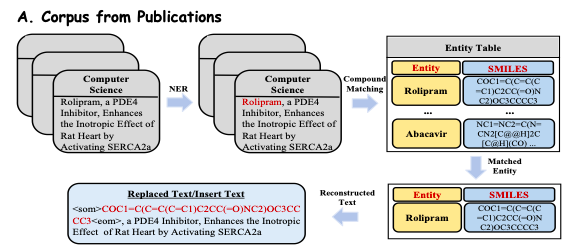
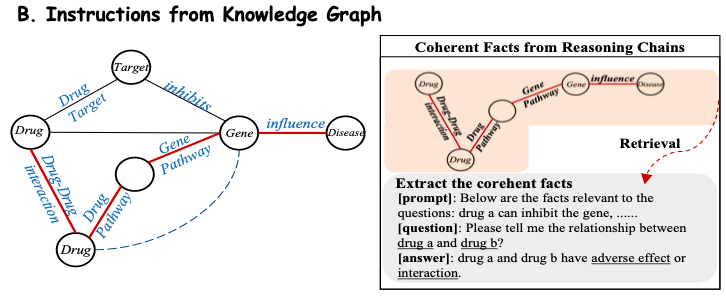
Afin d’extraire efficacement les connaissances du domaine de la base de connaissances biomédicales, cette étude convertit les faits de la base de connaissances en invites en langage naturel.Comme le montre la figure B ci-dessous, cette étude suppose que chaque chaîne de raisonnement dans le sous-graphe a une sémantique relationnelle claire, de sorte que chaque chemin cohérent est extrait et converti en une description en langage naturel à l'aide d'un modèle soigneusement conçu comme contexte d'invite. L'étude combine ensuite ces contextes construits avec les questions correspondantes et les introduit dans Y-Mol pour produire des réponses supervisées.
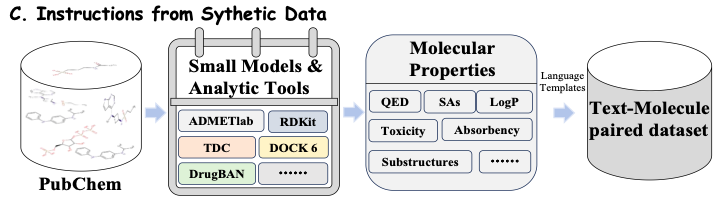
De plus, afin d'obtenir des instructions à grande échelle basées sur les attributs des médicaments et les connaissances du domaine, cette étude a utilisé des données synthétiques expertes provenant de petits modèles existants pour construire des instructions et affiné le spectre des connaissances sur les médicaments en Y-Mol.Au final, l’étude a rassemblé 11,2 millions d’entrées de corpus et 2,3 millions d’instructions soigneusement élaborées.
Comme le montre la figure C ci-dessous, pour une molécule médicamenteuse donnée, afin d'extraire des propriétés moléculaires plus complètes, cette étude a rassemblé une série d'outils moléculaires avancés et de modèles informatiques, tels qu'ADMETlab, RDKit, TDC et DrugBAN. Ces outils et modèles extraient des informations moléculaires avec différentes propriétés à partir d'ensembles de données accessibles au public, notamment QED, SA, LogP, toxicité, absorbance et sous-structures. De cette façon, la recherche peut intégrer en permanence les derniers modèles et outils et utiliser leurs données prédictives pour former les modèles, permettant à Y-Mol d'évoluer en temps réel et de maintenir sa position de leader dans le domaine du développement de médicaments.
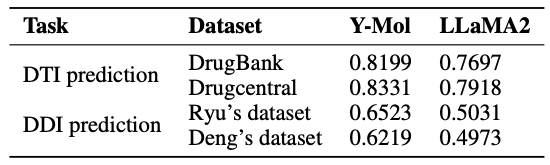
Enfin, comme le montre la figure ci-dessous, l’étude montre la distribution des données de Y-Mol pour différentes tâches pendant les étapes de pré-formation et de réglage fin supervisé. En termes d'évaluation de la capacité d'inférence, afin de tester de manière exhaustive les performances de Y-Mol dans la prédiction de l'interaction médicament-cible (DTI) et de l'interaction médicament-médicament (DDI),L'équipe de recherche a sélectionné les ensembles de données de référence largement reconnus DrugBank et DrugCentral pour la prédiction DTI.
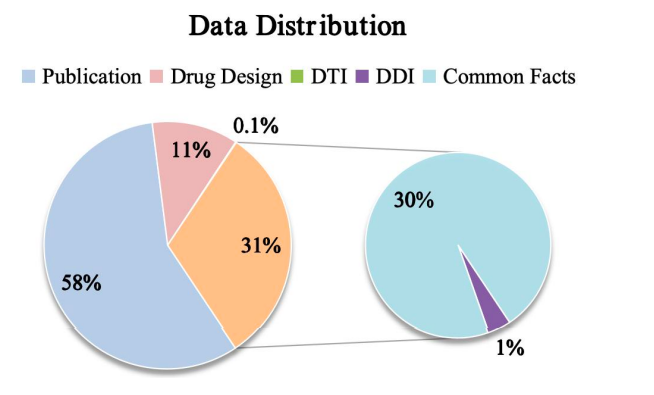
Dans le même temps, afin d’évaluer les performances de la prédiction DDI, les chercheurs ont utilisé l’ensemble de données fourni par Ryu et Deng.Ces méthodes d’évaluation ont été soigneusement sélectionnées pour garantir que Y-Mol puisse être testé de manière équitable et exhaustive selon les normes de l’industrie dans le domaine du développement de médicaments afin de prouver son efficacité.
Ensemble de données de Ryu : https://doi.org/10.1073/pnas.1803294115
Ensemble de données de Deng : https://doi.org/10.1093/bioinformatics/btaa501
Y-Mol : Basé sur LLaMA2-7b, dédié au développement de médicaments
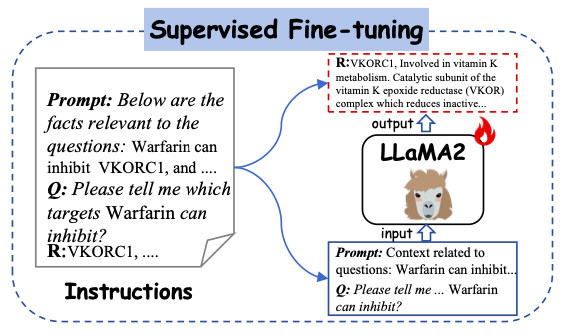
Cette étude a sélectionné LLaMA2-7b comme modèle de langage de base pour construire un cadre de formation et de raisonnement avancé spécifiquement pour le développement de médicaments - Y-Mol. Comme le montre la figure ci-dessous,Le développement de Y-Mol a été divisé en deux phases clés :
d'abord,Y-Mol est pré-formé sur un corpus à grande échelle de publications biomédicales et peaufine LLaMA2 grâce à une pré-formation auto-supervisée, permettant à Y-Mol d'avoir une compréhension de base des connaissances de base du développement de médicaments.alors,LLaMA2 est en outre supervisé et affiné à l'aide de connaissances du domaine lié aux médicaments et de données synthétiques d'experts. Ce processus introduit une grande quantité d'informations relatives aux médicaments dans Y-Mol, améliorant ainsi la compréhension du modèle des mécanismes d'interaction dans le processus de développement des médicaments.
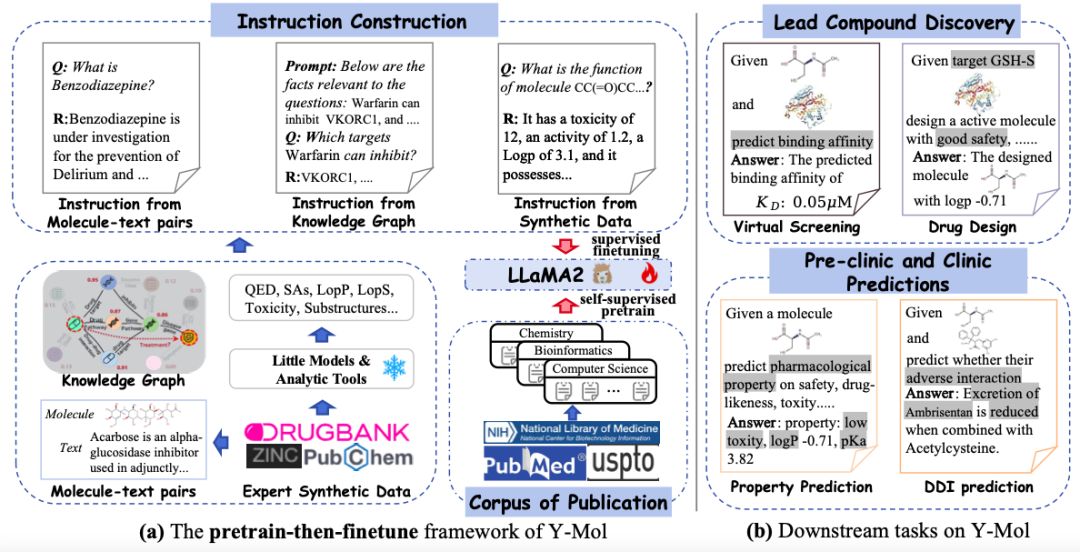
L’étude a soigneusement conçu un ensemble diversifié d’instructions et a affiné Y-Mol. Ces instructions comprenaient des instructions provenant de paires molécule-texte et des descriptions extraites de bases de données de médicaments. Ces descriptions présentent les propriétés, la structure et la fonction des médicaments en langage naturel et contiennent des informations sémantiques riches, qui contribuent à améliorer la cohérence entre les humains et les grands modèles linguistiques dans la perception des entités médicamenteuses.
Comme le montre la figure ci-dessous, cette étude utilise les instructions générées comme entrée pour l’apprentissage supervisé et les alimente dans Y-Mol. Plus précisément, des contextes et des questions d'invite construits sont entrés dans Y-Mol, et ces réponses construites sont utilisées pour superviser les sorties générées par le modèle.
Après avoir soigneusement peaufiné Y-Mol sur la base de ces instructions générées, les chercheurs l'ont appliqué à une gamme de tâches en aval, couvrant plusieurs liens allant de la découverte de composés principaux aux prédictions précliniques et cliniques. Grâce à cette méthode de réglage fin supervisé, Y-Mol peut comprendre et gérer plus précisément les problèmes complexes du développement de médicaments, fournissant ainsi un outil puissant pour le développement de médicaments assisté par ordinateur.
Résultats de recherche : Y-Mol a la meilleure performance de prédiction
Afin de vérifier pleinement l'efficacité de Y-Mol dans le domaine de la recherche et du développement de médicaments, l'étude a soigneusement conçu une série de tâches couvrant différentes étapes telles que la découverte de composés principaux, la recherche préclinique et les prévisions cliniques.Plus précisément, les différentes tâches clés sont les suivantes : (1) criblage virtuel et conception de médicaments pour la découverte de composés principaux ; (2) prédiction des propriétés physiques et chimiques des composés principaux découverts au stade préclinique ; et (3) la prédiction des effets indésirables potentiels des médicaments au stade clinique.
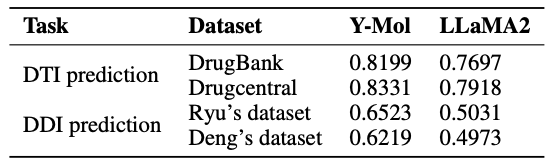
Lors du dépistage virtuel,L’identification des paires d’interactions médicament-cible inconnues est cruciale. Comme le montre le tableau ci-dessous, par rapport à LLaMA2, les scores AUC de Y-Mol sur les ensembles de données DrugBank et DrugCentral ont été améliorés respectivement de 5,02% et 4,13%. Cela indique que Y-Mol fonctionne bien dans la prédiction DTI de sources de données multi-échelles, démontrant ses performances supérieures dans le criblage virtuel.
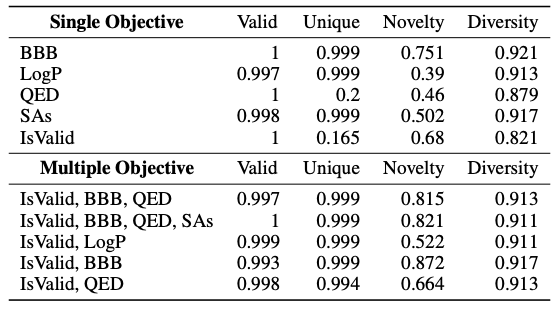
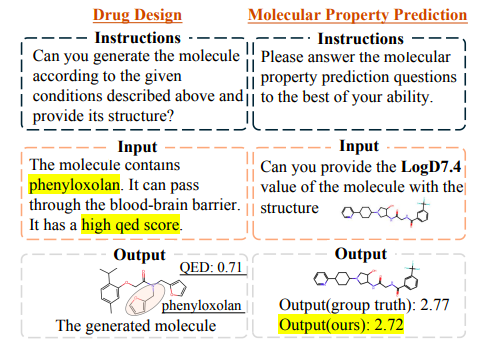
Dans la conception de médicaments,Afin de vérifier la performance de Y-Mol dans la découverte de nouveaux composés principaux, l’étude a également conçu une tâche pour produire des composés efficaces dans des conditions spécifiques. Autrement dit, étant donné une condition cible et une requête descriptive, il a été évalué si Y-Mol pouvait générer avec précision les molécules de séquence SMILES correspondantes à partir des informations contextuelles.
Comme le montre le tableau ci-dessous, cette étude a introduit des indicateurs standards tels que Valide, Unique, Nouveauté et Diversité pour prédire différents objectifs uniques tels que BBB et LogP. Les résultats ont montré que Y-Mol avait de meilleures performances globales. En comparaison, seule la capacité d’adaptation de domaine du modèle LLaMA2-7b a été peu performante et n’a pas pu générer de molécules efficaces. Dans le même temps, l’étude a également testé les performances de conception de médicaments de Y-Mol selon plusieurs objectifs. Les résultats ont montré que Y-Mol fonctionnait également bien dans ce cas.
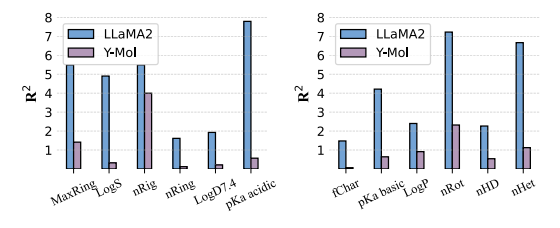
Dans la prédiction des propriétés moléculaires,Comme le montre la figure ci-dessous, Y-Mol présente des scores R² inférieurs à ceux de LLaMA2 dans toutes les tâches, ce qui indique que Y-Mol a une capacité de généralisation plus forte dans la prédiction des propriétés physico-chimiques.
Au cours de la phase clinique du développement d’un médicament, la prédiction des interactions médicamenteuses potentielles est essentielle pour garantir une utilisation sûre du médicament.Comme le montre la figure ci-dessous, Y-Mol est performant dans la tâche d’identification des interactions médicamenteuses potentielles (IDP).
Comme le montre la figure ci-dessous,Les médicaments conçus par Y-Mol répondent efficacement aux contraintes posées dans la requête. De même, Y-Mol peut prédire avec précision le LogD7.4 d’une molécule donnée, et le résultat prédit est très proche de la valeur réelle.Cela démontre l’efficacité de Y-Mol dans la résolution des tâches de développement de médicaments.
La technologie de l'IA : un nouveau moteur dans le développement de médicaments
En fait, au cours du long voyage du développement des médicaments, les scientifiques ont recherché de nouvelles technologies capables d’accélérer le processus. Ces dernières années, les technologies d’IA ont montré un grand potentiel d’application dans ce domaine. Ils peuvent non seulement comprendre en profondeur les mécanismes de la maladie, mais également jouer un rôle important dans des étapes clés telles que la découverte de médicaments et les essais cliniques.
Dans le monde des affaires,Certaines entreprises ont obtenu des résultats remarquables dans le développement de médicaments basés sur l’IA. Par exemple, la société de développement de médicaments à base d’IA Insilico Medicine a annoncé plus tôt cette année avoir découvert un nouveau médicament candidat clinique doté d’un nouveau mécanisme pour le traitement de la fibrose pulmonaire idiopathique, qui a été vérifié dans de multiples expériences sur des cellules humaines et des modèles animaux. En outre, Huawei Cloud a coopéré avec l'Institut de Materia Medica de Shanghai de l'Académie chinoise des sciences pour lancer le modèle de molécule de médicament Pangu, qui peut réaliser une conception de médicament assistée par intelligence artificielle pour l'ensemble du processus de médicaments à petites molécules et améliorer l'efficacité et la précision de la recherche et du développement de médicaments.
Dans le domaine de la recherche scientifique,L'un des auteurs de cette étude, l'équipe du professeur Zeng Xiangxiang de l'Université du Hunan, a également conçu un grand modèle de langage pour les séquences peptidiques et a formé le modèle en ajoutant progressivement des conditions de calcul et de criblage. En seulement 3 mois, le modèle a conçu et synthétisé avec succès 29 peptides antimicrobiens potentiels, dont 26 ont montré une activité antimicrobienne à large spectre. Dans des expériences sur des souris, trois peptides antimicrobiens ont montré des effets antibactériens comparables à ceux des antibiotiques approuvés par la FDA, et aucune résistance évidente aux médicaments n'a été observée pendant la culture continue et la surveillance jusqu'à 25 jours. Ce résultat a été officiellement accepté par Nature Communications.
Lien vers l'article :
https://www.nature.com/articles/s41467-024-51933-2
De plus, un autre auteur de cette étude, le professeur Cao Dongsheng de l'Université du Centre-Sud, en collaboration avec le professeur Hou Tingjun et le professeur Xie Changyu de l'Université du Zhejiang, ont récemment développé conjointement l'outil d'optimisation moléculaire Prompt-MolOpt. L'algorithme utilise une stratégie d'apprentissage rapide pour réaliser l'application de l'apprentissage à zéro coup et de l'apprentissage à quelques coups dans l'optimisation multi-propriétés.
Lien vers l'article :
https://www.nature.com/articles/s42256-024-00916-5
De la compréhension approfondie des mécanismes des maladies à l’accélération de la découverte de médicaments et à l’optimisation de la conception des essais cliniques, la technologie de l’IA devient un nouveau moteur pour la recherche et le développement de médicaments. À mesure que la technologie continue de progresser, elle jouera un rôle de plus en plus crucial dans la recherche médicale future.









