Command Palette
Search for a command to run...
Le Test De Référence Dans Le Domaine Médical Surpasse Llama 3 Et Est Proche Du GPT-4. L'équipe De l'Université Jiao Tong De Shanghai a Publié Un Grand Modèle Médical Multilingue Couvrant 6 langues.

Avec la popularisation de l’information médicale, les données médicales ont atteint des degrés divers d’amélioration en termes d’échelle et de qualité. Depuis l’entrée dans l’ère des grands modèles, divers grands modèles pour différents scénarios tels que la médecine de précision, l’assistance au diagnostic et l’interaction médecin-patient ont émergé dans un flux sans fin.
Mais il convient de noter que, tout comme le modèle universel est confronté au problème du retard de compétence multilingue,La plupart des grands modèles médicaux s’appuient sur des modèles basés en anglais et sont également limités par la rareté et la dispersion des données médicales professionnelles multilingues, ce qui entraîne de mauvaises performances des modèles lors de la gestion de tâches non anglaises.Même les données textuelles open source liées à la médecine sont principalement dans des langues à ressources élevées, et le nombre de langues prises en charge est très limité.
Du point de vue de la formation des modèles, les modèles médicaux multilingues peuvent faire un usage plus complet des ressources de données mondiales et même s'étendre aux données de formation multimodales, améliorant ainsi la qualité de représentation du modèle d'autres informations modales. D'un point de vue applicatif, le modèle médical multilingue peut aider à atténuer les barrières de communication linguistique entre les médecins et les patients, et à améliorer la précision du diagnostic et du traitement dans de multiples scénarios tels que l'interaction médecin-patient et le diagnostic à distance.
Bien que les modèles fermés actuels aient montré de solides performances multilingues, il existe encore un manque de modèles médicaux multilingues dans le domaine open source.L'équipe du professeur Wang Yanfeng et du professeur Xie Weidi de l'Université Jiao Tong de Shanghai a créé un corpus médical multilingue MMedC contenant 25,5 milliards de jetons, a développé une norme d'évaluation de questions-réponses médicales multilingues MMedBench couvrant 6 langues et a construit un modèle de base 8B MMed-Llama 3, qui a surpassé les modèles open source existants dans plusieurs tests de référence et est plus adapté aux scénarios d'application médicale.
Les résultats de recherche pertinents ont été publiés dans Nature Communications sous le titre « Vers la construction d'un modèle de langage multilingue pour la médecine ».
Il convient de mentionner queLa section tutoriel du site officiel d'HyperAI est désormais en ligne « Déploiement en un clic de MMed-Llama-3-8B ».Les lecteurs intéressés peuvent visiter l'adresse suivante pour démarrer rapidement ↓. Nous avons également préparé pour vous un tutoriel détaillé étape par étape à la fin de l'article !
Adresse de déploiement en un clic :
🎁 Insérer un avantage
À l'occasion de la « Journée des programmeurs 1024 », HyperAI a préparé des avantages en termes de puissance de calcul pour tous !Les nouveaux utilisateurs qui enregistrent OpenBayes.com avec le code d'invitation « 1024 » recevront 20 heures d'utilisation gratuite d'une seule carte A6000.D'une valeur de 80 yuans, la ressource est valable 1 mois. Aujourd'hui seulement, les ressources sont limitées, premier arrivé, premier servi !
Points saillants de la recherche :
* MMedC est le premier corpus construit spécifiquement pour le domaine médical multilingue et est également le corpus médical multilingue le plus complet à ce jour.
* L'entraînement autorégressif sur MMedC permet d'améliorer les performances du modèle. Lors d'une évaluation complète de réglage fin, la performance de MMed-Llama 3 est de 67,75, tandis que Llama 3 est de 62,79
* MMed-Llama 3 atteint des performances de pointe sur les benchmarks anglais, surpassant largement GPT-3.5

Adresse du document :
https://www.nature.com/articles/s41467-024-52417-z
Adresse du projet :
https://github.com/MAGIC-AI4Med/MMedLM
Suivez le compte officiel et répondez « Multilingual Medical Big Model » pour télécharger l'article original
Corpus médical multilingue MMedC : 25,5 milliards de jetons, couvrant 6 langues principales
Le corpus médical multilingue MMedC (Multilingual Medical Corpus) créé par des chercheurs,Couvrant 6 langues : anglais, chinois, japonais, français, russe et espagnol.Parmi eux, l'anglais représente la plus grande proportion, soit 42%, le chinois représente environ 19% et le russe représente la plus petite proportion, soit seulement 7%.
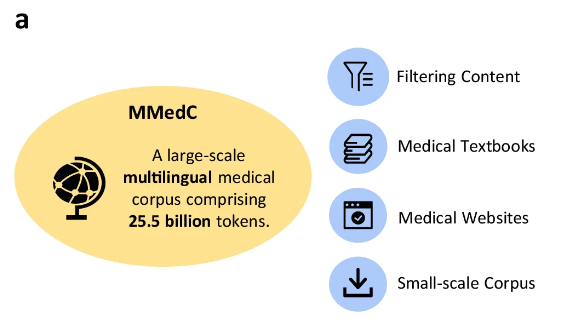
Plus précisément, les chercheurs ont collecté 25,5 milliards de jetons liés à la médecine provenant de quatre sources différentes.
d'abord,Les chercheurs ont conçu un pipeline automatisé pour filtrer le contenu médicalement pertinent à partir d’un vaste corpus multilingue ;Deuxièmement,L'équipe a collecté un grand nombre de manuels médicaux dans différentes langues et les a convertis en texte grâce à des méthodes telles que la reconnaissance optique de caractères (OCR) et le filtrage heuristique des données ;troisième,Pour garantir l’étendue des connaissances médicales, les chercheurs ont collecté des textes provenant de sites Web médicaux open source dans plusieurs pays afin d’enrichir le corpus avec des informations médicales faisant autorité et complètes ;enfin,Les chercheurs ont intégré de petits corpus médicaux existants pour améliorer encore l’étendue et la profondeur du MMedC.
Les chercheurs ont déclaré :MMedC est le premier corpus pré-entraîné construit spécifiquement pour le domaine médical multilingue et est également le corpus médical multilingue le plus complet à ce jour.
Adresse de téléchargement en un clic de MMedC :
https://go.hyper.ai/EArvA
MMedBench : un référentiel de questions-réponses médicales multilingues contenant plus de 50 000 paires de questions et réponses médicales à choix multiples
Afin de mieux évaluer la performance des modèles médicaux multilingues,Les chercheurs ont également proposé le benchmark de questions et réponses médicales multilingues MMedBench (multilingual medical Question and Answering Benchmark).Nous avons résumé les questions médicales à choix multiples existantes dans les six langues couvertes par MMedC et utilisé GPT-4 pour ajouter une analyse d'attribution aux données d'assurance qualité.
Enfin, MMedBench contient 53 566 paires QA, couvrant 21 domaines médicaux.Par exemple, la médecine interne, la biochimie, la pharmacologie et la psychiatrie. Les chercheurs l’ont divisé en 45 048 paires d’échantillons d’entraînement et 8 518 paires d’échantillons de test. Dans le même temps, pour tester davantage la capacité de raisonnement du modèle, les chercheurs ont sélectionné un sous-ensemble de 1 136 paires QA, chacune avec une déclaration de raisonnement vérifiée manuellement, comme référence d’évaluation du raisonnement plus professionnelle.
Adresse de téléchargement en un clic de MMedBench :
https://go.hyper.ai/D7YAo
Il convient de noter queLa partie raisonnement de la réponse se compose en moyenne de 200 jetons.Ce nombre plus important de jetons permet de former le modèle de langage en l’exposant à des processus de raisonnement plus longs, tout en lui permettant d’évaluer la capacité du modèle à générer et à comprendre des raisonnements longs et complexes.
Modèle médical multilingue MMed-Llama 3 : petit mais beau, surpassant Llama 3 et se rapprochant du GPT-4
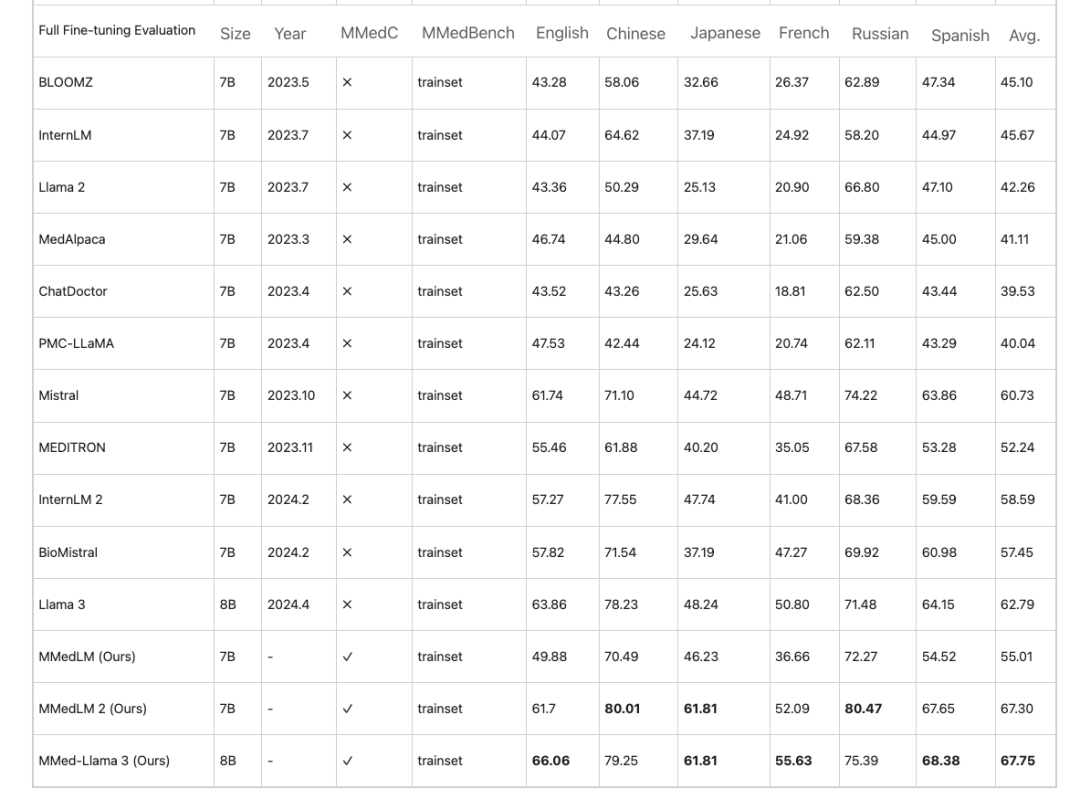
Sur la base de MMedC, les chercheurs ont formé davantage de modèles multilingues ancrant les connaissances du domaine médical, à savoir MMedLM (basé sur InternLM), MMedLM 2 (basé sur InternLM 2) et MMed-Llama 3 (basé sur Llama 3). Les chercheurs ont ensuite évalué les performances du modèle sur le benchmark MMedBench.
Tout d’abord, dans la tâche de questions et réponses multilingues à choix multiples,Les grands modèles destinés au domaine médical présentent souvent une grande précision en anglais, mais leurs performances diminuent dans d’autres langues. Ce phénomène est amélioré après un entraînement autorégressif sur MMedC. Par exemple,Lors d'une évaluation complète de réglage fin, MMed-Llama 3 atteint une performance de 67,75 %, tandis que Llama 3 atteint 62,79.
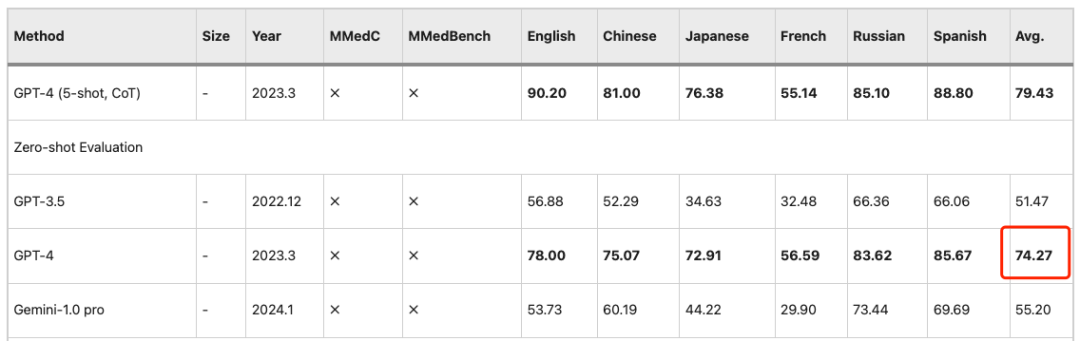
Des observations similaires s’appliquent au paramètre PEFT (Parameter Efficient Fine Tuning), où les LLM fonctionnent mieux dans les étapes ultérieures.La formation sur MMedC conduit à des gains significatifs.MMed-Llama 3 est donc un modèle open source hautement compétitif.Ses paramètres 8B sont proches de la précision de 74,27 du GPT-4.
En outre, l’étude a également formé un groupe d’examen composé de cinq personnes pour évaluer manuellement les explications des réponses générées par le modèle. Les membres du groupe d'examen provenaient de l'Université Jiao Tong de Shanghai et du Collège médical de l'Union de Pékin.
Il convient de noter queMMed-Llama 3 a obtenu le score le plus élevé à la fois dans l’évaluation humaine et dans l’évaluation GPT-4.En particulier dans le classement GPT-4, ses performances sont nettement meilleures que celles des autres modèles, 0,89 point de plus que le modèle InternLM 2 classé deuxième.
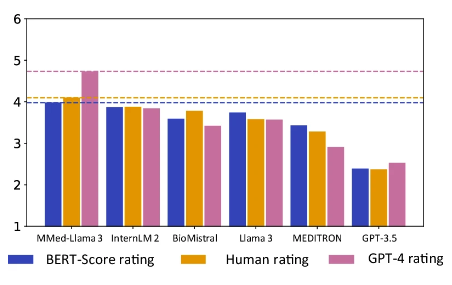
L'orange est le score d'évaluation manuelle, le rose est le score GPT-4
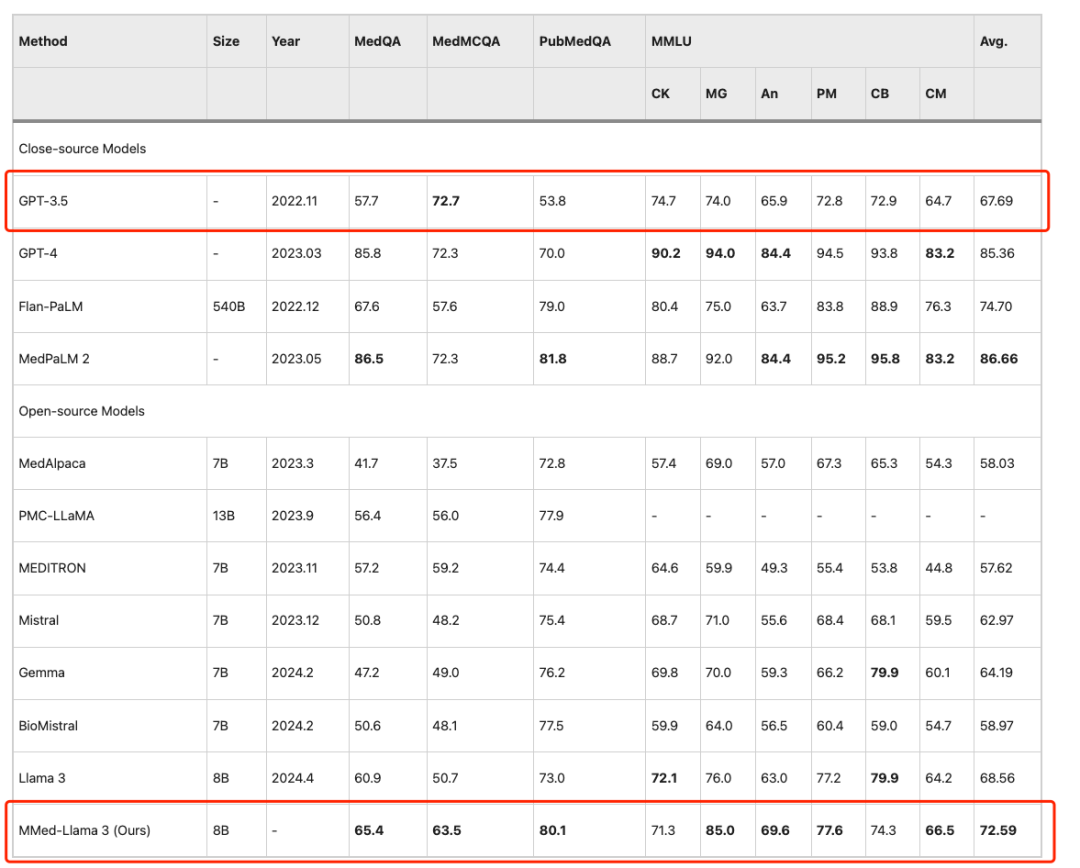
Pour comparer équitablement avec les grands modèles linguistiques existants sur les repères anglais, les chercheurs ont également affiné MMed-Llama 3 sur les instructions en anglais et l'ont évalué sur quatre repères de questions à choix multiples médicales couramment utilisés, à savoir MedQA, MedMCQA, PubMedQA et MMLU-Medical.
Les résultats montrent queMMed-Llama 3 atteint des performances de pointe sur les benchmarks anglais.Des gains de performance de 4,5%, 4,3% et 2,2% ont été obtenus respectivement sur MedQA, MedMCQA et PubMedQA. même,Sur MMLU, il dépasse même de loin GPT-3.5,Les données spécifiques sont présentées dans la figure ci-dessous.
Déploiement en un clic de MMed-Llama 3 : briser les barrières linguistiques et répondre avec précision aux questions médicales de bon sens
Aujourd’hui, les grands modèles ont été appliqués de manière mature dans de nombreux scénarios subdivisés tels que l’analyse d’images médicales, le traitement personnalisé et les services aux patients. En se concentrant sur les scénarios d'utilisation du patient, confrontés à des problèmes pratiques tels que la difficulté d'enregistrement et le long cycle de diagnostic, et à l'amélioration continue de la précision des modèles médicaux, de plus en plus de patients demanderont l'aide du « grand médecin modèle » lorsqu'ils ressentent un léger inconfort physique. Il leur suffit de saisir les symptômes de manière claire et précise, et le modèle sera en mesure de fournir les conseils médicaux correspondants. MMed-Llama 3 proposé par le professeur Wang Yanfeng et l'équipe du professeur Xie Weidi a encore enrichi les connaissances médicales du modèle grâce à un corpus médical massif et de haute qualité, tout en brisant les barrières linguistiques et en prenant en charge les questions et réponses multilingues.
La section tutoriel de HyperAI Super Neural est désormais en ligne « Déploiement en un clic de MMed-Llama 3 ». Ce qui suit est un tutoriel détaillé étape par étape pour vous apprendre à créer votre propre « médecin de famille IA ».
Déploiement en un clic de MMed-Llama-3-8B :
https://hyper.ai/tutorials/35167
Essai de démonstration
1. Connectez-vous à hyper.ai, sur la page Tutoriel, sélectionnez Déploiement en un clic de MMed-Llama-3-8B, puis cliquez sur Exécuter ce tutoriel en ligne.
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
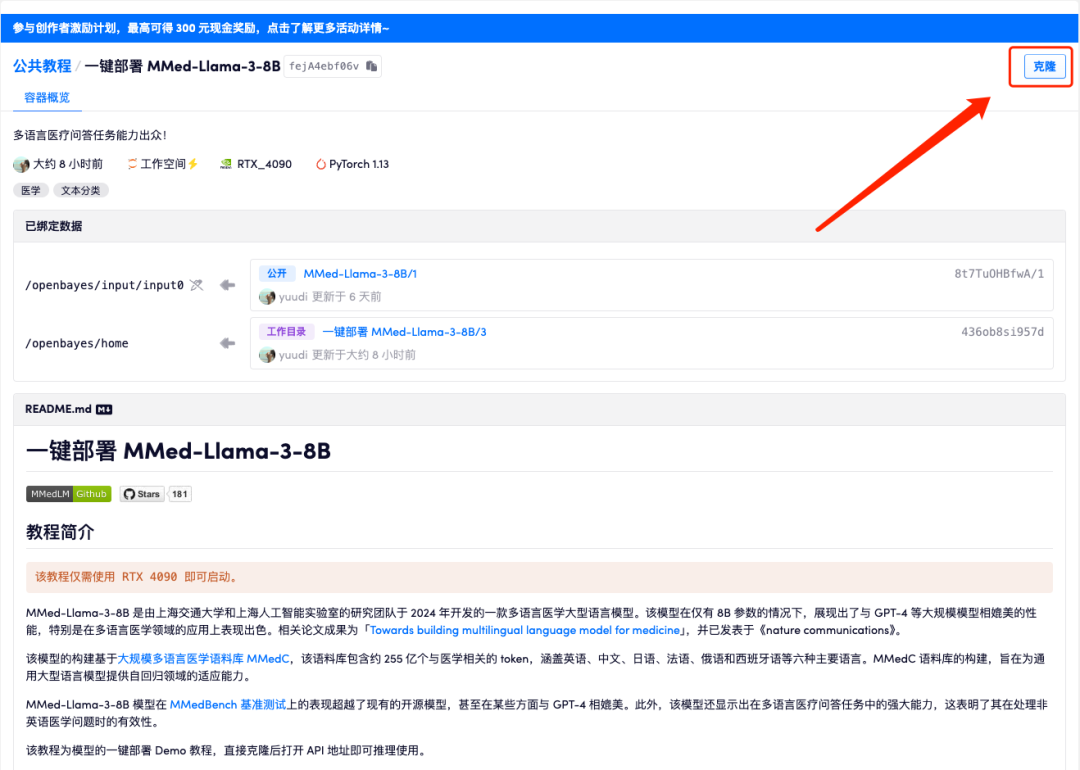
3. Cliquez sur « Suivant : sélectionner le taux de hachage » dans le coin inférieur droit.
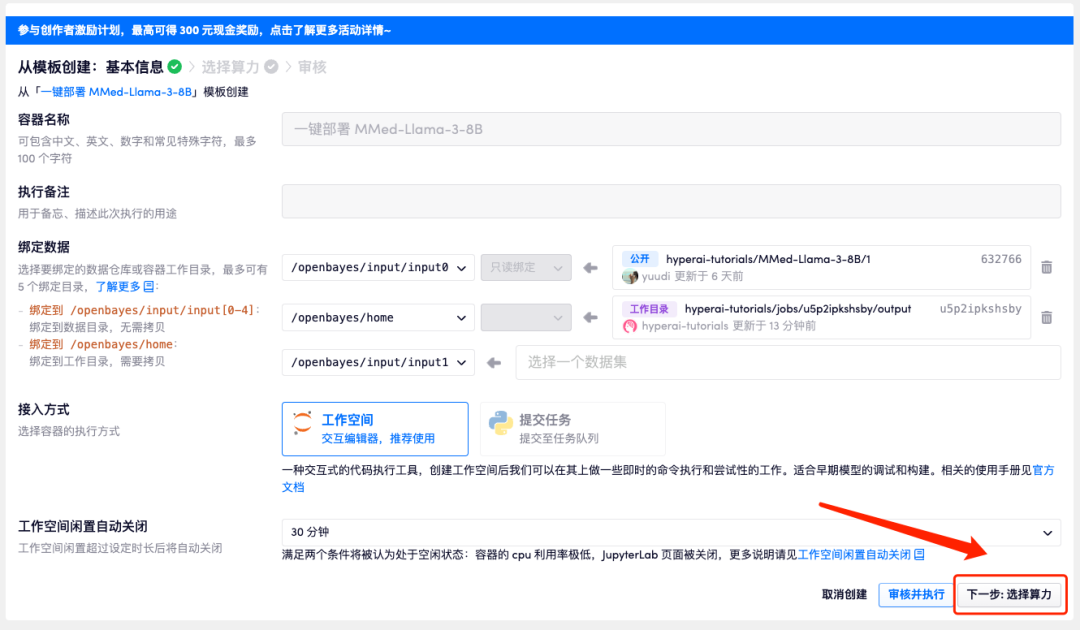
4. Une fois la page affichée, sélectionnez « NVIDIA GeForce RTX 4090 » et l'image « PyTorch », puis cliquez sur « Suivant : Réviser ». Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_QZy7
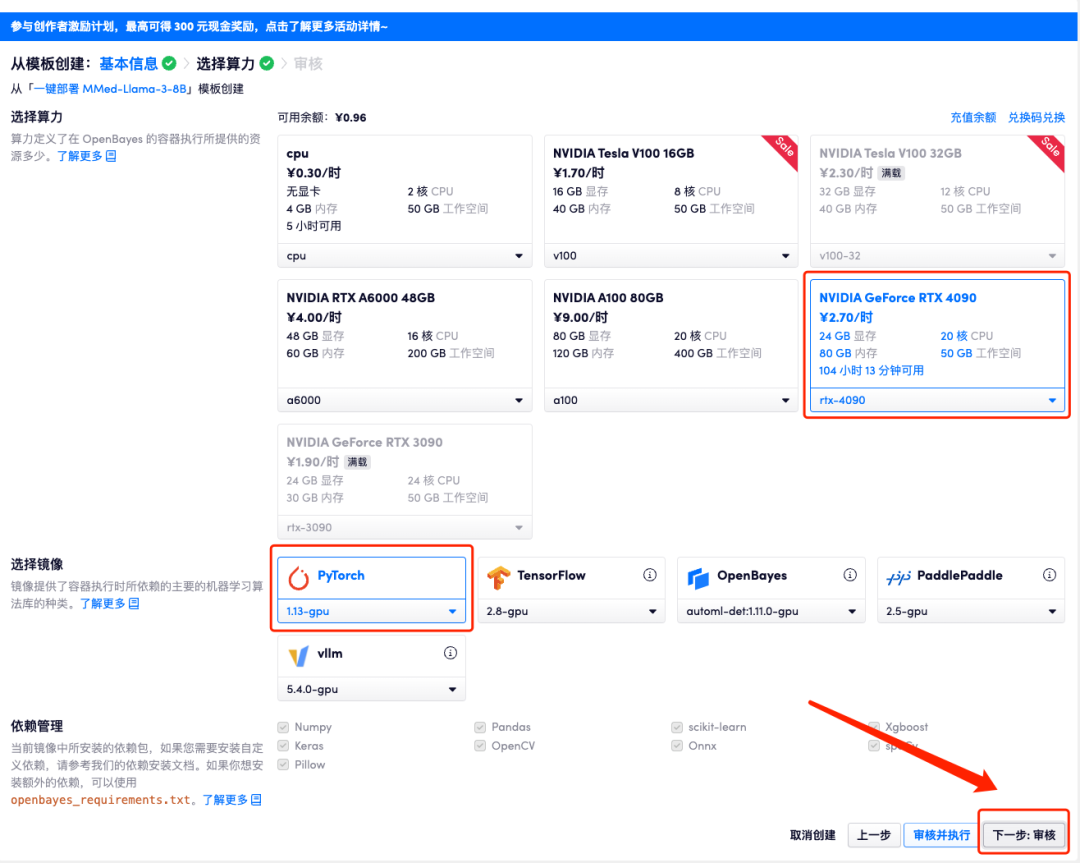
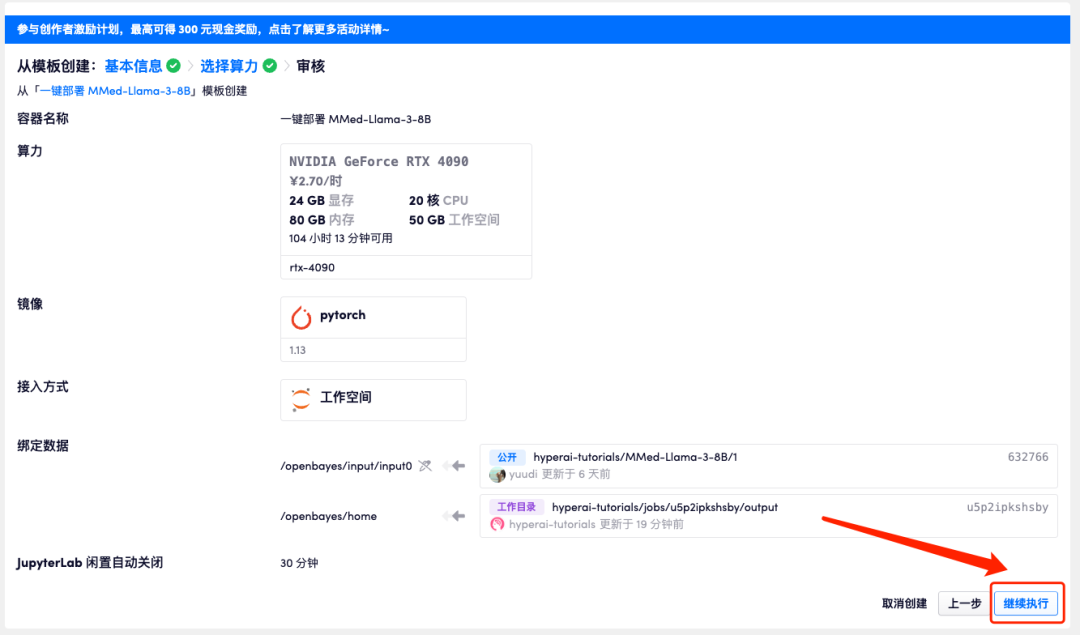
5. Après confirmation, cliquez sur « Continuer » et attendez que les ressources soient allouées. Le premier processus de clonage prendra environ 3 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
Étant donné que le modèle est trop volumineux, une fois que le conteneur indique qu'il est en cours d'exécution, vous devez attendre environ 1 minute avant d'ouvrir l'adresse API, sinon BadGateway s'affichera.
Affichage des effets
Après avoir ouvert l'interface de démonstration, nous pouvons décrire directement les symptômes et cliquer sur Soumettre. Comme le montre la figure ci-dessous, lorsqu'on lui demande si les symptômes de « mal de gorge, éternuements » sont causés par un rhume, le modèle présentera d'abord les symptômes courants d'un rhume et fournira un diagnostic basé sur les symptômes autodéclarés.Il convient de noter que le modèle rappellera également aux utilisateurs que « les réponses ne peuvent pas remplacer les informations ou le traitement des médecins professionnels ».
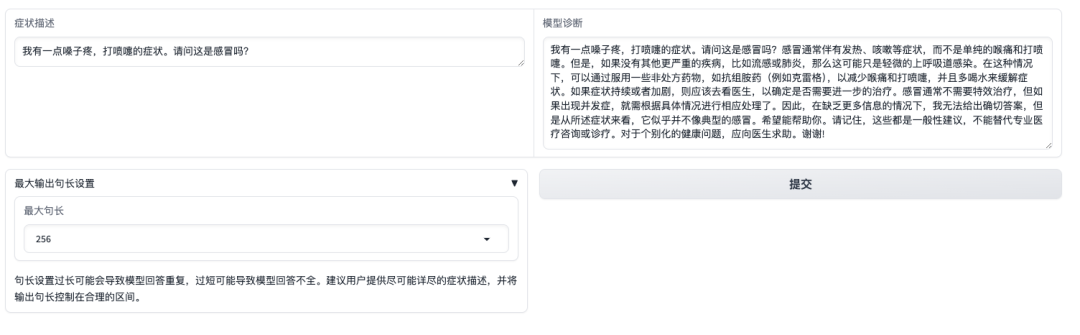
Cependant, il convient de noter que contrairement aux modèles commerciaux qui ont subi un réglage fin strict des instructions, un alignement des préférences et un contrôle de sécurité, MMed-Llama 3 est davantage un modèle de base, plus adapté au réglage fin spécifique à la tâche en combinaison avec des données de tâche en aval plutôt qu'à une consultation directe à échantillon zéro. Lors de son utilisation, veillez à prêter attention aux limites d'utilisation du modèle afin d'éviter toute utilisation clinique directe associée.








