Command Palette
Search for a command to run...
Tutoriel En Ligne | Vaincre GPT-4V ? Le Grand Modèle Multimodal Open Source Super Puissant LLaVA-OneVision Est Officiellement Lancé !

Le Grand Modèle de Langage (LLM) et le Grand Modèle Multimodal (LMM) sont deux axes de développement fondamentaux dans le domaine de l'intelligence artificielle. Alors que le LLM se concentre sur le traitement et la génération de données textuelles, le LMM va plus loin et vise à intégrer et à comprendre plusieurs types de données, notamment du texte, des images et des vidéos. Aujourd’hui, LLM est relativement mature et ChatGPT et d’autres algorithmes maîtrisent déjà parfaitement la compréhension de texte. Les gens commencent à porter leur attention sur la compréhension des données multimodales, permettant aux modèles de « lire des images et de regarder des vidéos ».
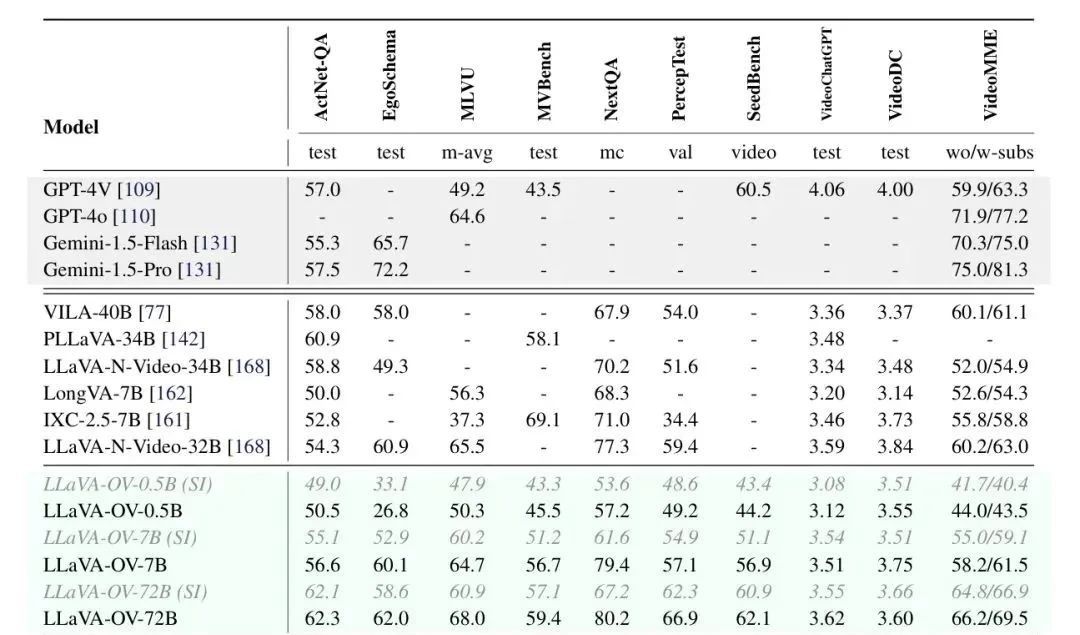
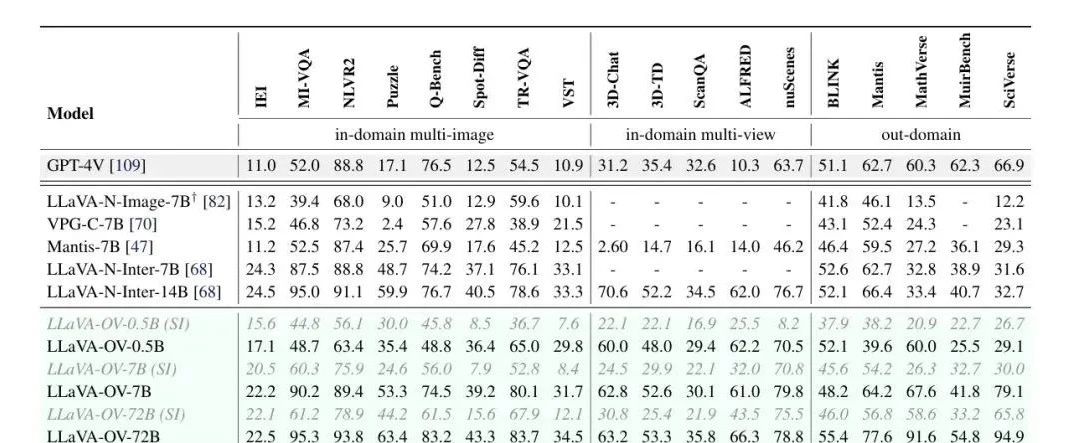
Récemment, des chercheurs de ByteDance, de l'Université technologique de Nanyang, de l'Université chinoise de Hong Kong et de l'Université des sciences et technologies de Hong Kong ont conjointement ouvert le code source du grand modèle multimodal LLaVA-OneVision, qui a démontré d'excellentes performances dans les tâches d'image unique, d'images multiples et de vidéo. LMMs-Eval, un cadre d'évaluation conçu pour les grands modèles multimodaux, montre que LLaVA-OneVision-72B surpasse GPT-4V et GPT-4o sur la plupart des benchmarks, comme le montre la figure suivante :
Le tutoriel HyperAI Hyperneuron est désormais disponible"Démonstration du modèle de vision globale multimodale LLaVA-OneVision"Les utilisateurs peuvent facilement gérer une variété de tâches visuelles en clonant simplement et en démarrant en un seul clic. Qu'il s'agisse de l'analyse d'images statiques ou de l'analyse de vidéos dynamiques, il peut fournir un résultat de haute qualité.
Adresse du tutoriel :
Essai de démonstration
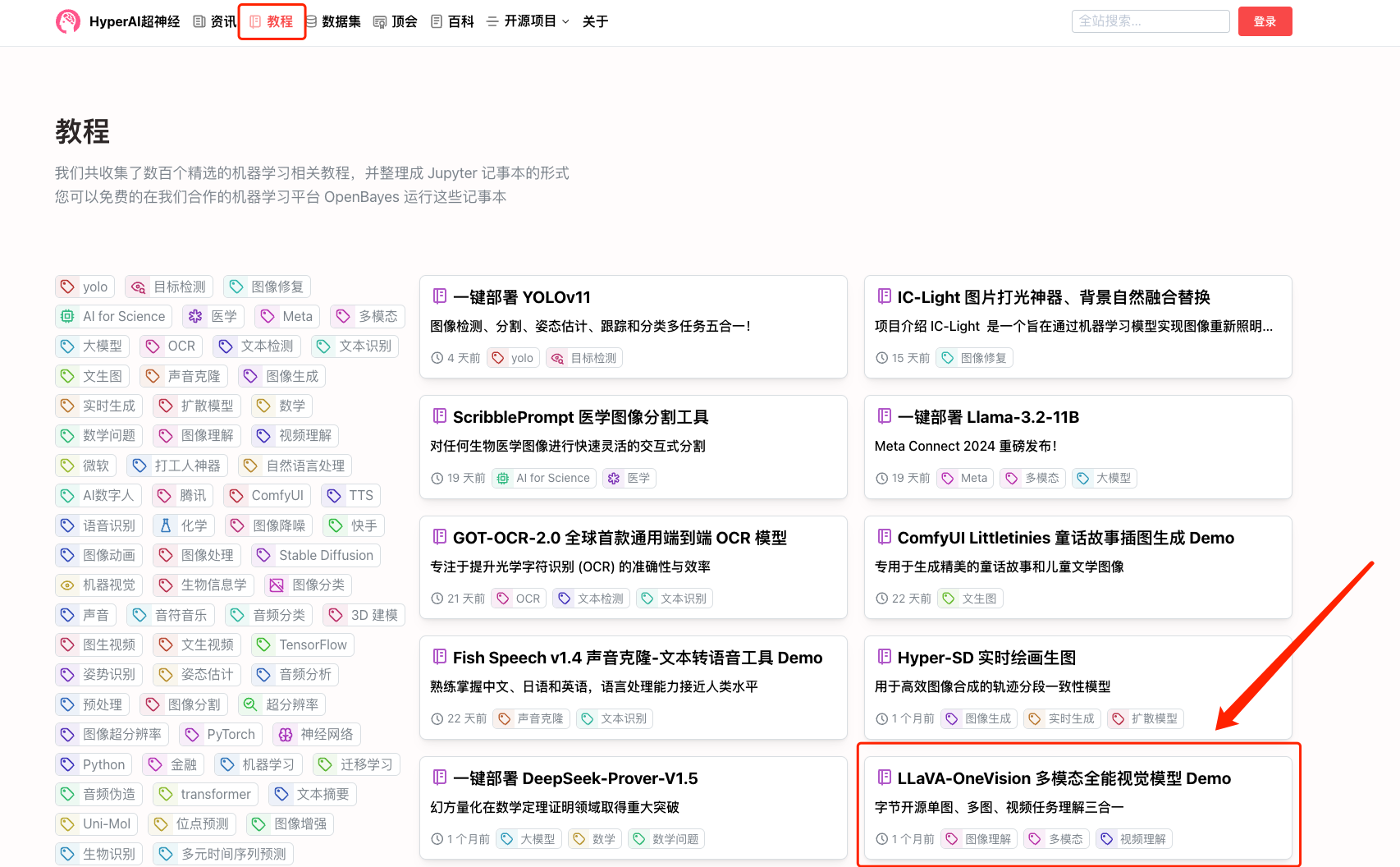
1. Connectez-vous à hyper.ai, sur la page Tutoriel, sélectionnez LLaVA-OneVision Multimodal Universal Vision Model Demo, puis cliquez sur Exécuter ce tutoriel en ligne.
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
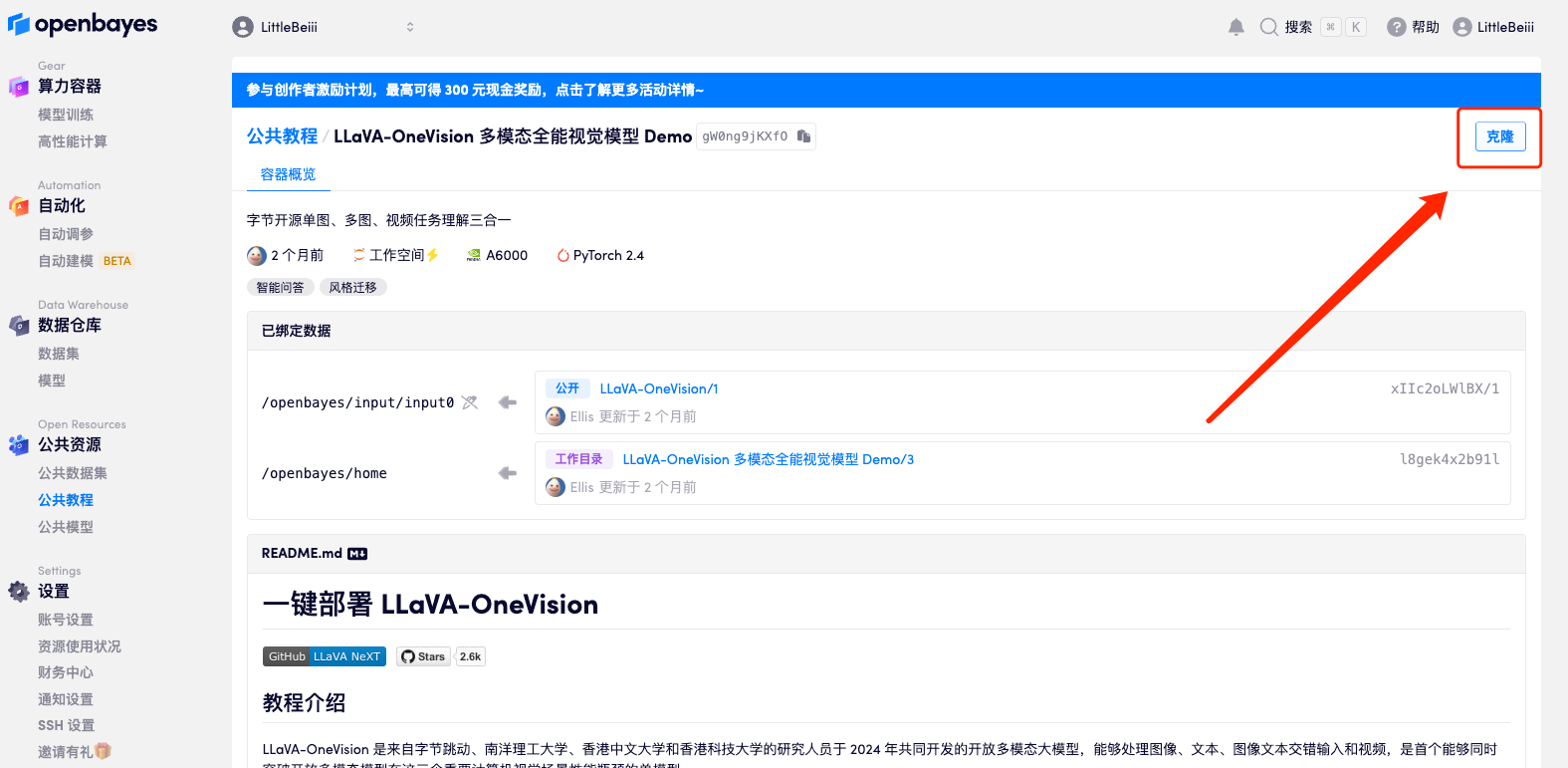
3. Cliquez sur « Suivant : sélectionner le taux de hachage » dans le coin inférieur droit.
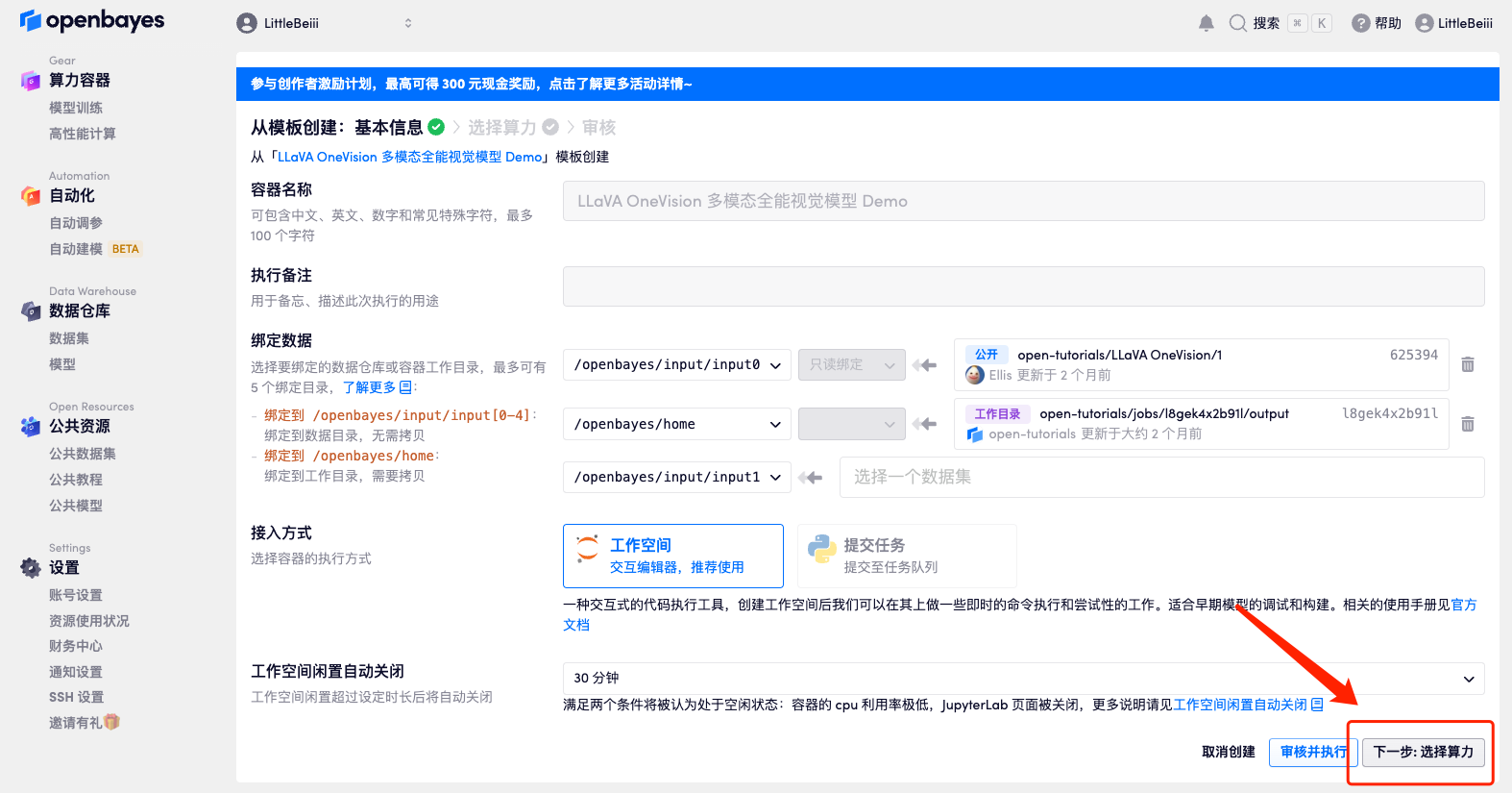
4. Une fois la page affichée, sélectionnez « NVIDIA RTX A6000 » et l'image « PyTorch », puis cliquez sur « Suivant : Réviser ».Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_QZy7
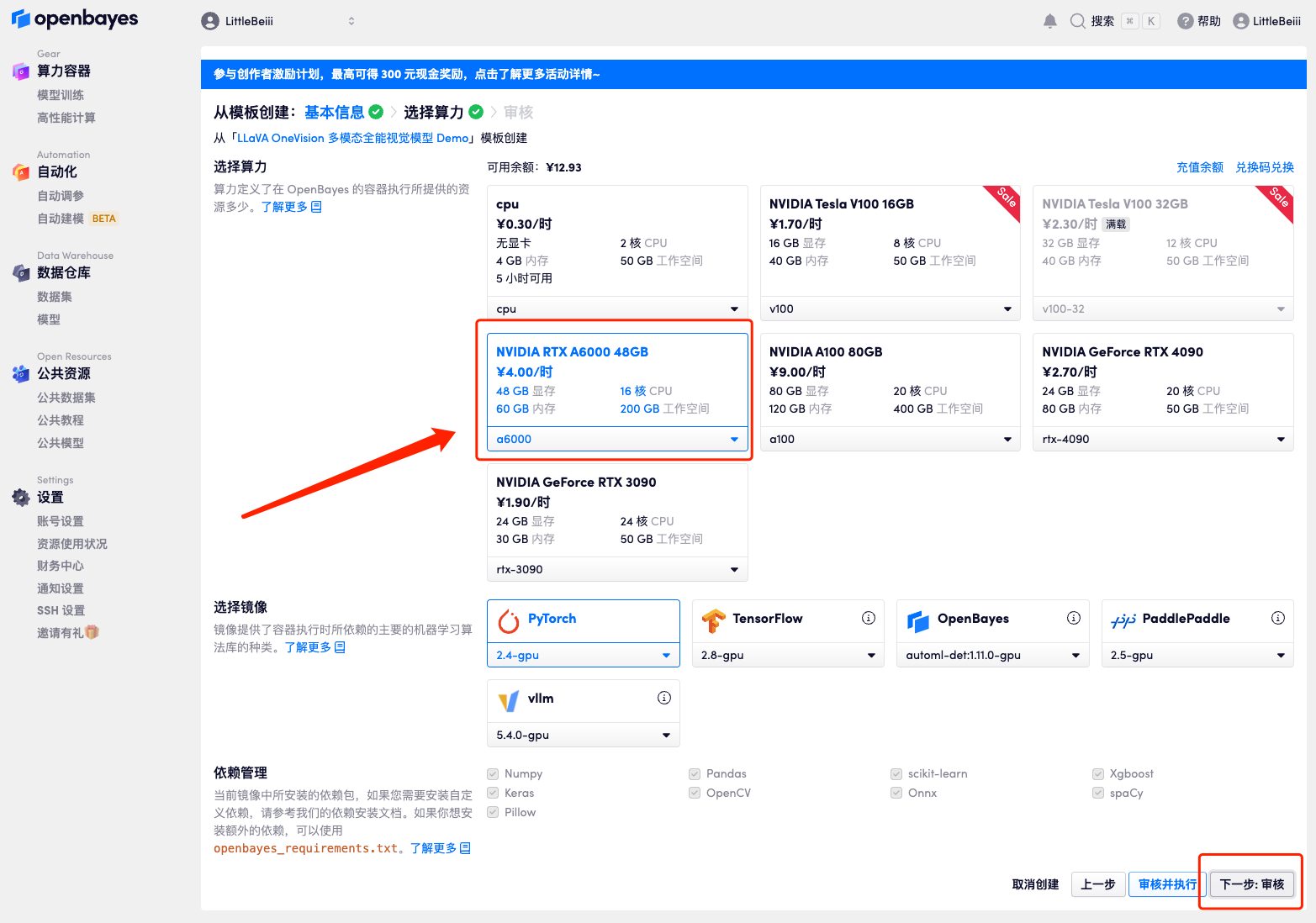
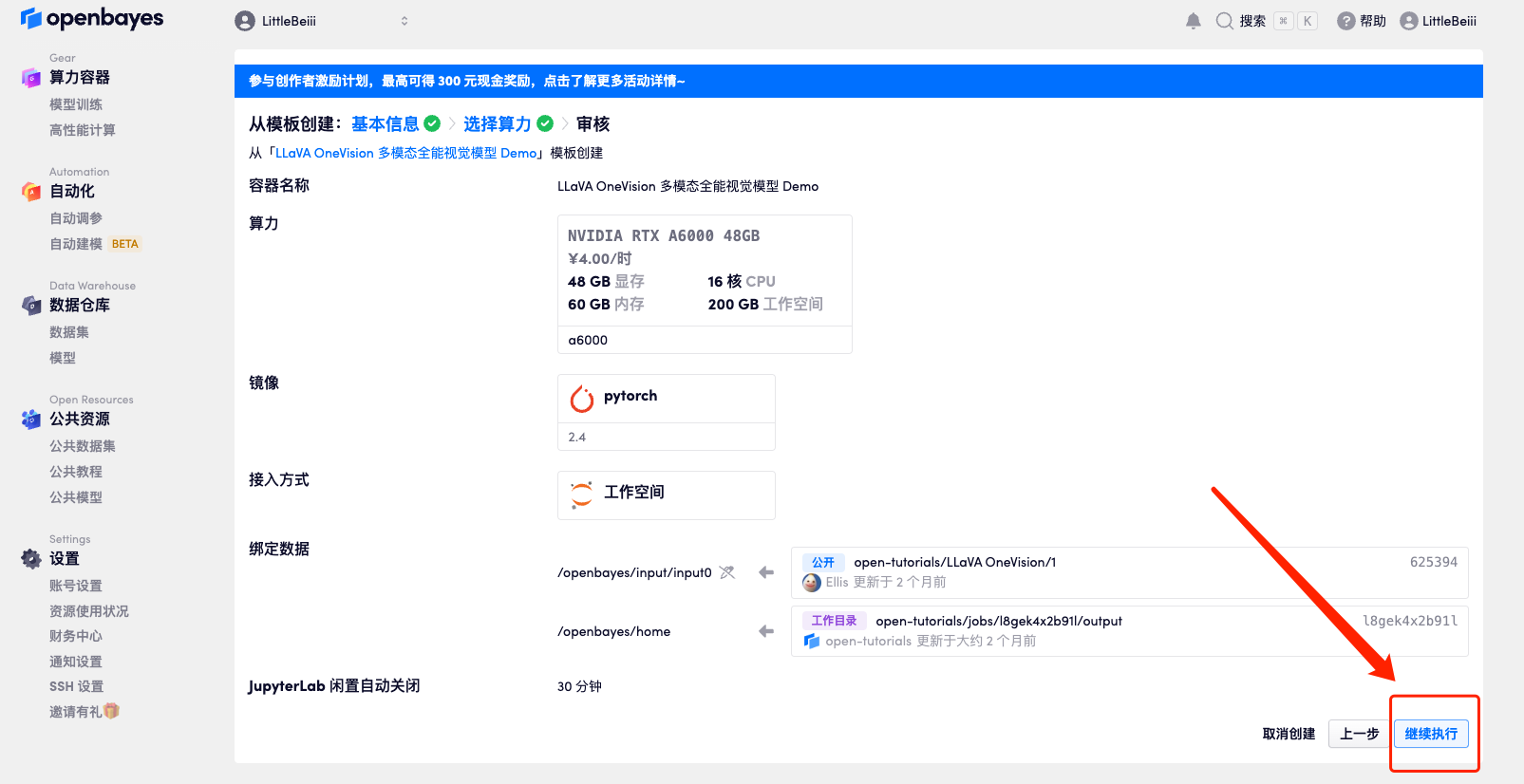
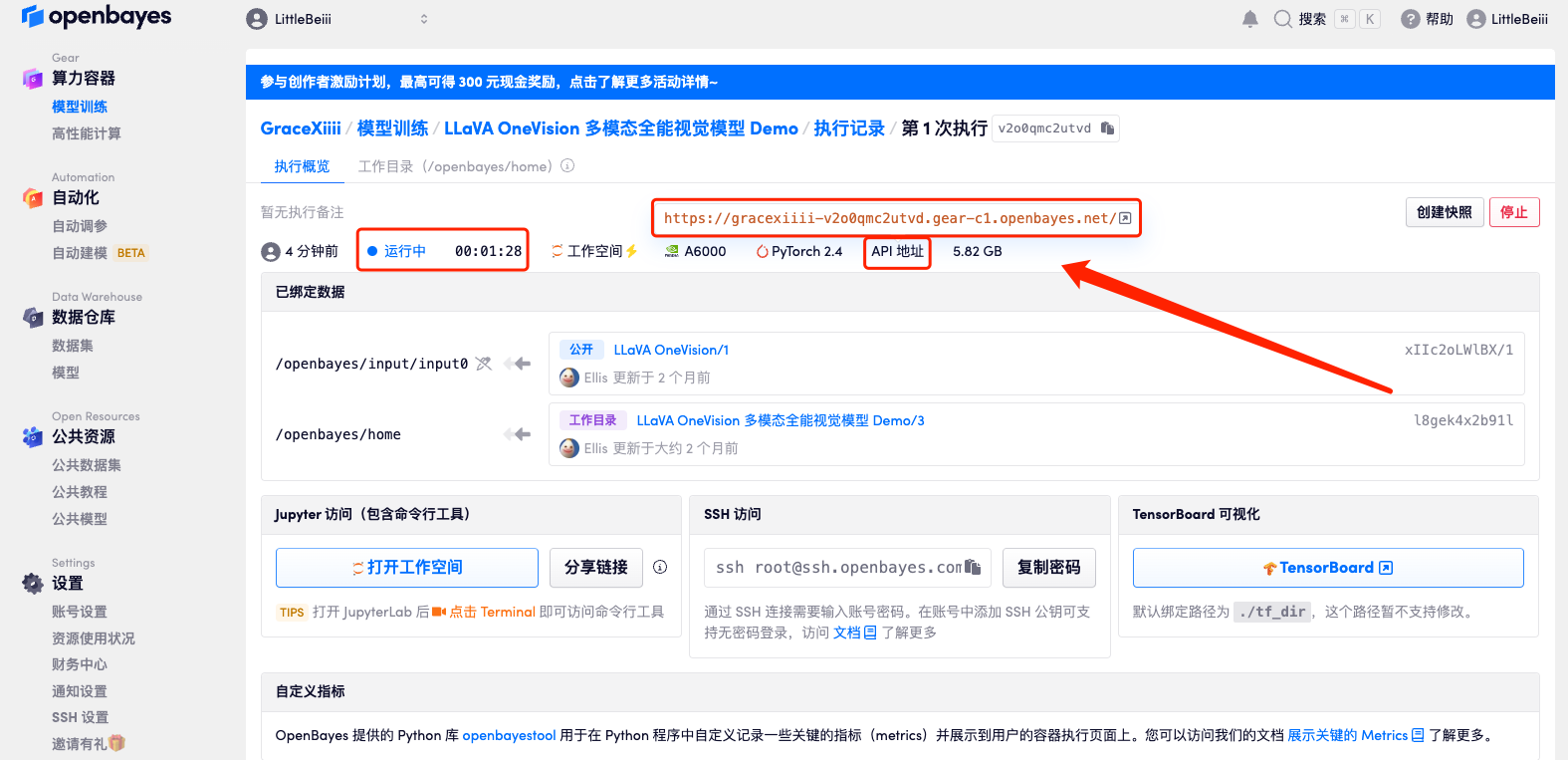
5. Après confirmation, cliquez sur « Continuer » et attendez que les ressources soient allouées. Le premier processus de clonage prendra environ 3 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration.Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.Étant donné que le modèle est trop volumineux, une fois que le conteneur indique qu'il est en cours d'exécution, vous devez attendre environ 1 minute avant d'ouvrir l'adresse API, sinon BadGateway s'affichera.
Démonstration d'effet
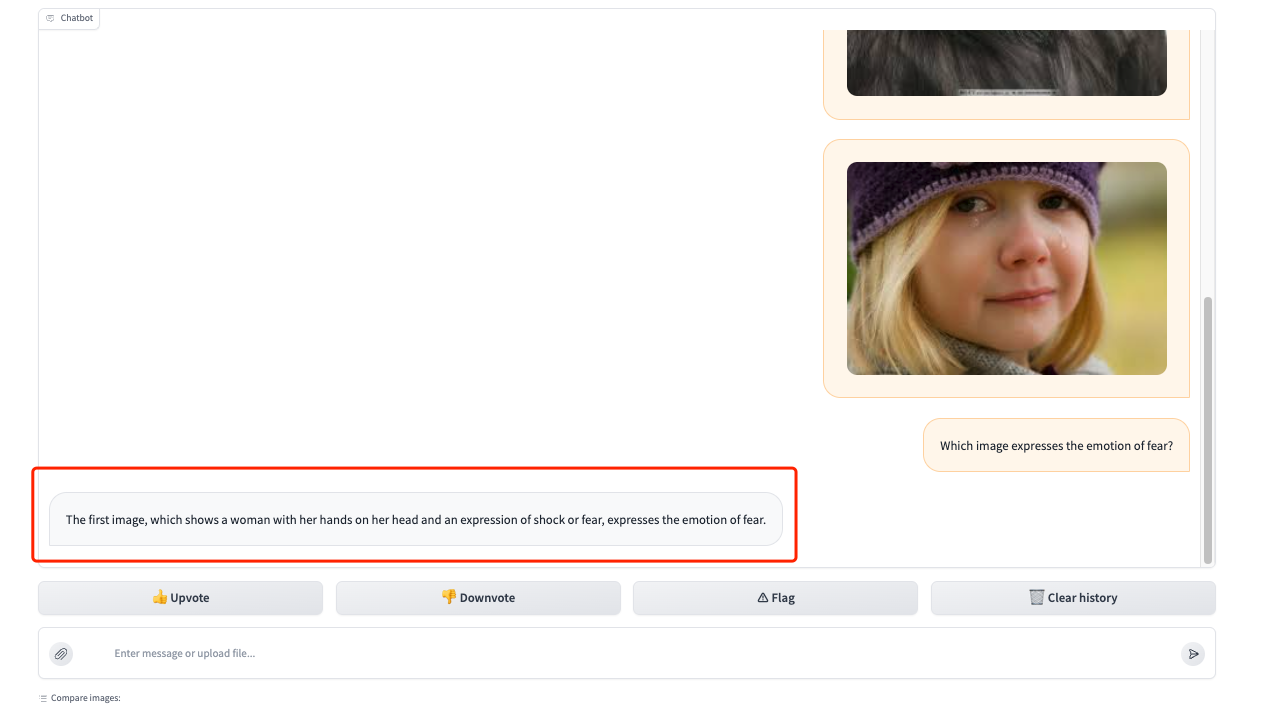
1. Après avoir ouvert l'interface de démonstration, testons d'abord sa capacité à comprendre les images. Téléchargez 3 photos d'émotions différentes dans la zone du cadre rouge et répondez à notre question « Quelle image exprime l'émotion de la peur ? » Vous pouvez voir qu'il répond avec précision à notre question et fournit une description de l'image (La première image, qui montre une femme avec les mains sur la tête et une expression de choc ou de peur, exprime l'émotion de la peur).


2. Il dispose également d’excellentes capacités de compréhension vidéo. Téléchargez une collection de vidéos des moments forts d’une compétition de course olympique et demandez « De quoi parle cette vidéo ? » Vous pouvez voir qu'il peut répondre avec précision aux événements de la compétition et décrire les scènes et les détails vidéo, tels que la couleur de peau des athlètes, les émotions et les logos des sponsors autour du stade.

Traduction de la réponse :
La vidéo semble être un extrait d'épreuves d'athlétisme, principalement le sprint de 100 mètres. On y voit des athlètes sur les starting-blocks se préparant à concourir, l'un d'eux portant une tenue jaune et verte, suggérant qu'il pourrait représenter la Jamaïque, car ce sont les couleurs du drapeau jamaïcain. La vidéo capture l’intensité et la concentration des athlètes alors qu’ils se préparent à partir, leur poussée sur les blocs de départ et leur sprint ultérieur sur la piste. Les athlètes portent des uniformes identifiant leur équipe nationale ou leurs sponsors, et les logos de divers sponsors, tels que TOYOTA et TDK, peuvent être vus autour du stade. La vidéo comprend également des gros plans des visages des athlètes, montrant leur concentration et leur détermination. La scène finale montre les athlètes en train de sprinter, avec un athlète en tête des autres, suggérant qu'une course compétitive est en cours.
Nous avons créé un « Groupe d'échange de tutoriels de diffusion stable ». Bienvenue aux amis pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats des applications~
Scannez le code QR ci-dessous pour ajouter HyperaiXingXing sur WeChat (ID WeChat : Hyperai01) et notez « SD Tutorial Exchange Group » pour rejoindre le chat de groupe.









