Command Palette
Search for a command to run...
Sélectionné Pour l'ECCV 2024 ! Couvrant Plus De 54 000 Images, Le MIT a Proposé Un Modèle Général De Segmentation d'images Médicales, ScribblePrompt, Qui Surpasse SAM

Le profane observe l’excitation, tandis que l’expert observe les détails. Cette phrase est une vérité absolue dans le domaine de l’imagerie médicale. De plus, même pour un expert, il n’est pas facile de voir avec précision les « astuces » dans les images médicales complexes telles que les radiographies, les scanners ou les IRM. La segmentation d'images médicales consiste à séparer certaines parties ayant des significations particulières d'images médicales complexes et à extraire les caractéristiques pertinentes, afin d'aider les médecins à fournir des diagnostics et des plans de traitement plus précis aux patients et de fournir une base plus fiable aux chercheurs scientifiques pour mener des recherches pathologiques.
Ces dernières années, grâce au développement des technologies informatiques et d’apprentissage profond,La méthode de segmentation des images médicales s’accélère progressivement de la segmentation manuelle à la segmentation automatisée, et les systèmes d’IA formés sont devenus une aide importante pour les médecins et les chercheurs.Cependant, en raison de la complexité et du professionnalisme des images médicales elles-mêmes, une grande partie du travail de formation du système repose encore sur des experts expérimentés pour segmenter et créer manuellement des données de formation, ce qui est un processus long et exigeant en main-d'œuvre. Dans le même temps, les méthodes de segmentation existantes basées sur l’apprentissage profond ont également rencontré de nombreux défis dans la pratique, tels que des problèmes d’applicabilité et des exigences d’interaction flexibles.
Afin de répondre aux limites des systèmes de segmentation interactifs existants dans les applications pratiques, une équipe du Laboratoire d'informatique et d'intelligence artificielle du Massachusetts Institute of Technology (MIT CSAIL) s'est associée à des chercheurs du Massachusetts General Hospital et de la Harvard Medical School pour développer un nouveau système de segmentation interactif qui peut être utilisé pour identifier et segmenter les visages.Nous proposons un modèle général pour la segmentation interactive d'images biomédicales, ScribblePrompt, un outil de segmentation basé sur un réseau neuronal qui prend en charge les annotateurs utilisant différentes méthodes d'annotation telles que les gribouillis, les clics et les cadres de délimitation pour effectuer de manière flexible des tâches de segmentation d'images biomédicales, même pour les étiquettes et les types d'images non formés.
La recherche, intitulée « ScribblePrompt : segmentation interactive rapide et flexible pour toute image biomédicale », a été incluse dans la plateforme académique de renommée internationale arXiv et acceptée par la principale conférence académique internationale ECCV 2024.
Points saillants de la recherche :
* Exécutez rapidement et avec précision n'importe quelle tâche de segmentation d'images biomédicales, surpassant les modèles de pointe existants, en particulier pour les étiquettes et les types d'images non formés
* Fournit des styles d'annotation flexibles et diversifiés, notamment le gribouillage, le clic et le cadre de délimitation
* Efficacité de calcul supérieure, permettant une inférence rapide même sur un seul processeur
* Dans une étude utilisateur avec des experts du domaine, l'outil a réduit le temps d'annotation de 28% par rapport à SAM

Adresse du document :
https://arxiv.org/pdf/2312.07381
Adresse de téléchargement du jeu de données MedScribble :
L'outil de segmentation d'images médicales « ScribblePrompt » a été lancé dans la section Tutoriel HyperAI Super Neural. Vous pouvez le démarrer en le clonant en un clic. L'adresse du tutoriel est :
Grands ensembles de données, couverture complète de la formation des modèles et de l'évaluation des performances
L'étude s'appuie sur de vastes efforts de collecte de données tels que MegaMedical, qui compile 77 ensembles de données d'imagerie biomédicale en libre accès pour la formation et l'évaluation, couvrant 54 000 scans, 16 types d'images et 711 étiquettes.
Ces images de jeux de données couvrent divers domaines biomédicaux, notamment des scanners des yeux, de la poitrine, de la colonne vertébrale, des cellules, de la peau, des muscles abdominaux, du cou, du cerveau, des os, des dents et des lésions ; les types d’images comprennent les microscopes, la tomodensitométrie, les rayons X, l’IRM, l’échographie et les photographies.
En ce qui concerne la division entre formation et évaluation,L’équipe de recherche a divisé les 77 ensembles de données en 65 ensembles de données de formation et 12 ensembles de données d’évaluation.Parmi les 12 ensembles de données d'évaluation, les données de 9 ensembles de données d'évaluation ont été utilisées pour le développement du modèle, la sélection du modèle et l'évaluation finale, et les données des 3 autres ensembles de données d'évaluation n'ont été utilisées que pour l'évaluation finale.
Chaque ensemble de données est divisé en un ensemble d'entraînement, un ensemble de validation et un ensemble de test dans un rapport de 6:2:2, comme indiqué dans la figure ci-dessous.

Les deux images suivantes sont des « ensembles de données de validation et de test » et des « ensembles de données d'entraînement ».Parmi eux, les « ensembles de données de validation et de test » sont invisibles pendant la formation du modèle ScribblePrompt.
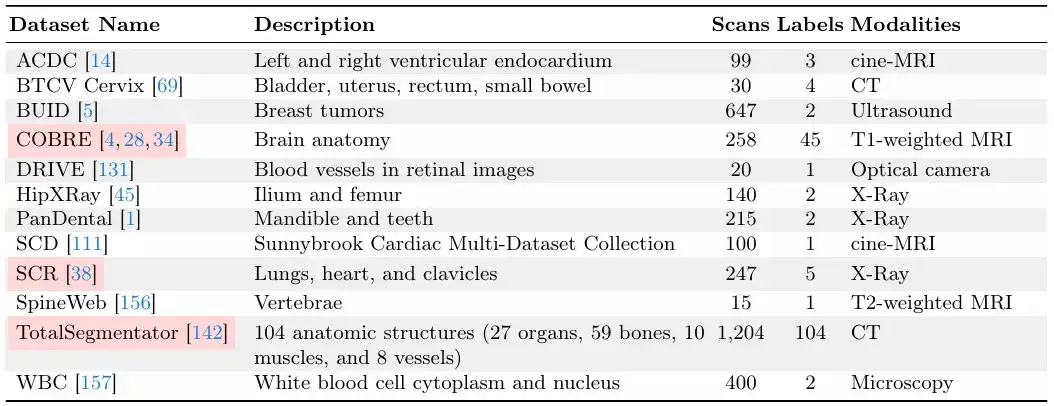
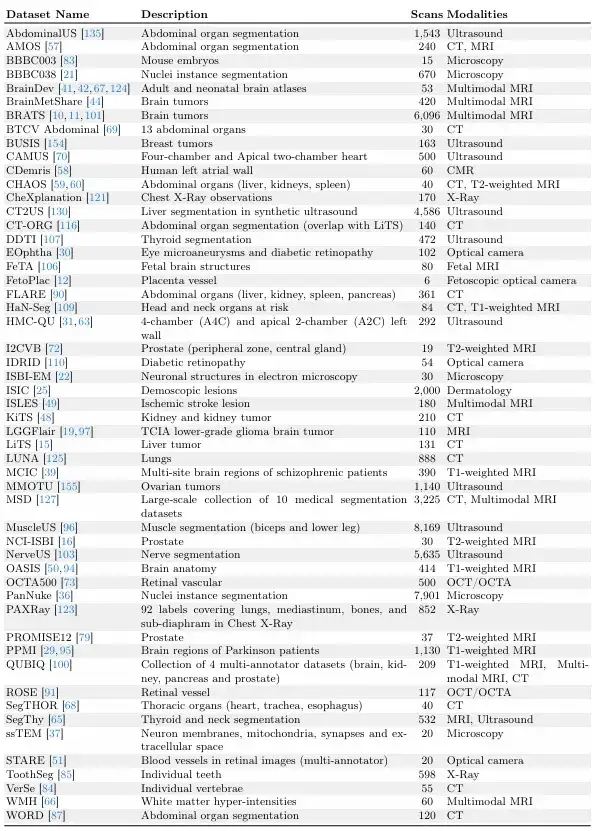
Compte tenu de la taille relative des ensembles de données, l’équipe de recherche a veillé à ce que chaque ensemble de données dispose d’un nombre unique d’analyses.
Architecture efficace pour un raisonnement rapide, création d'outils de segmentation pratiques
L’équipe de recherche a proposé une méthode de segmentation flexible et interactive avec une forte applicabilité pratique qui peut être étendue à de nouveaux domaines d’imagerie biomédicale et à des régions d’intérêt.
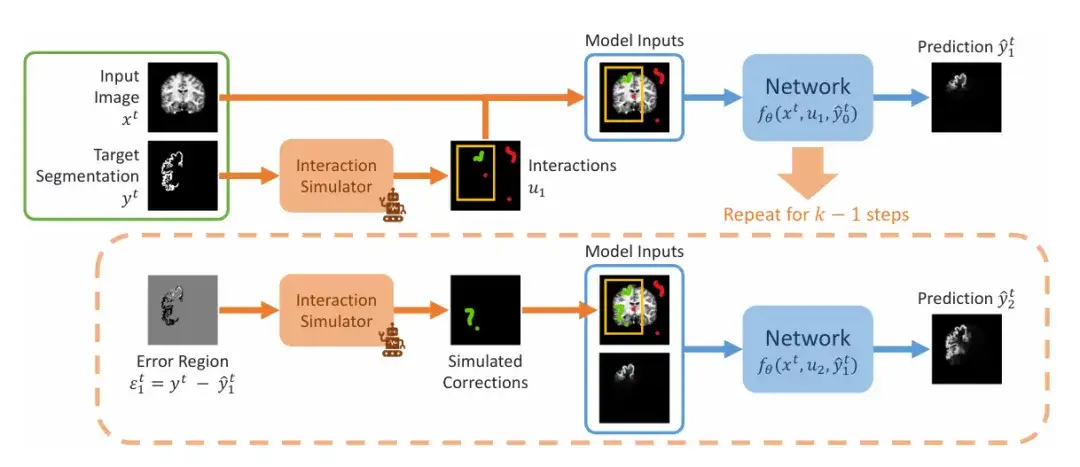
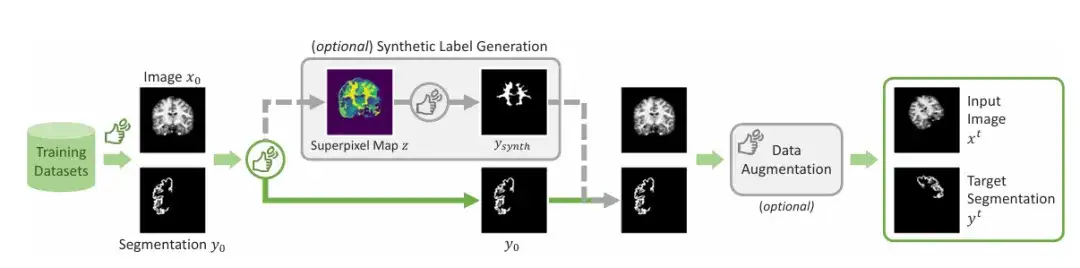
L’équipe de recherche a démontré les étapes séquentielles de la simulation de la segmentation interactive pendant la formation, comme le montre la figure ci-dessous. L'entrée reçoit une paire de segmentation d'image (xᵗ, yᵗ). L'équipe simule d'abord un ensemble initial d'interactions u₁, qui peut inclure des cadres de délimitation, des clics ou des gribouillis, puis entre dans la première étape de prédiction, en définissant la valeur initiale sur 0. Dans la deuxième étape, l'équipe a simulé les prédictions précédentes dans la zone d'erreur et les a ajoutées à l'ensemble initial d'interactions après correction de la simulation pour obtenir u₂. Ceci est répété pour produire une série de prédictions.
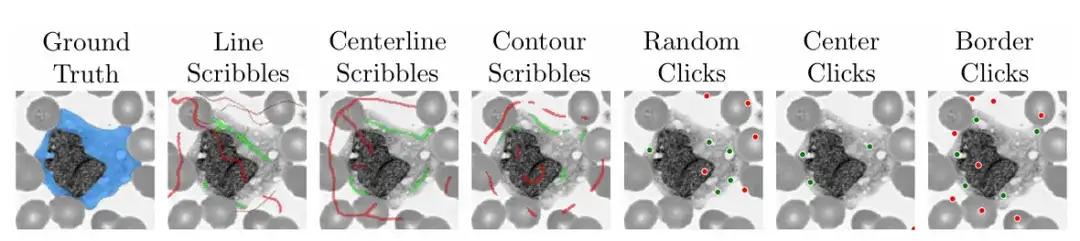
Afin de garantir la praticité et la facilité d'utilisation du modèle,L'équipe de recherche a également utilisé l'algorithme pendant la formation pour simuler des scénarios pratiques sur la manière de gribouiller, de cliquer et de saisir des cadres de délimitation sur différentes zones d'images médicales.
En plus des zones généralement signalées,L’équipe a introduit un mécanisme permettant de générer des étiquettes synthétiques.Un algorithme de superpixels est appliqué pour générer une carte d'étiquettes synthétiques potentielles, puis une étiquette est échantillonnée pour générer le « Ysynth » montré dans la figure, et enfin une augmentation aléatoire des données est appliquée pour obtenir le résultat final. Cette approche fonctionne en trouvant des parties d’une image avec des valeurs similaires, puis en identifiant de nouvelles régions susceptibles d’intéresser les chercheurs médicaux et en formant ScribblePromt à les segmenter. Comme le montre la figure ci-dessous.
Cette présentation de recherche utilise principalement deux architectures de réseau à des fins de démonstration. L’une consiste à démontrer ScribblePrompt en utilisant une architecture entièrement convolutive efficace similaire à UNet, et l’autre consiste à démontrer ScribblePrompt en utilisant une architecture de convertisseur visuel.
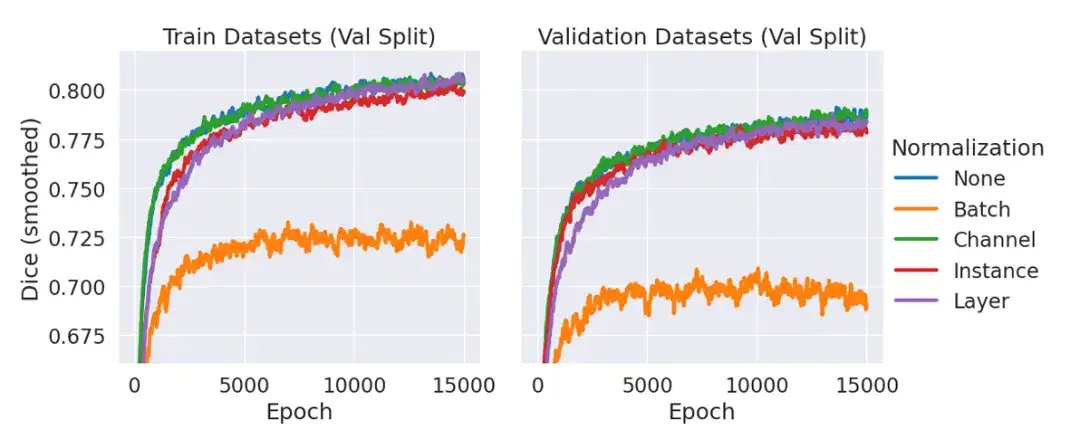
Parmi eux, ScribblePrompt-UNet utilise un CNN à 8 couches et suit une structure de décodeur similaire à l'architecture populaire UNet sans norme de lot. Chaque couche convolutive comporte 192 fonctionnalités et utilise l'activation PReLu. Il convient d'expliquer que la raison pour laquelle il n'y a pas de couche de normalisation est que dans des expériences préliminaires, l'équipe a constaté que l'inclusion de la normalisation n'améliorait pas le dé moyen sur les données de validation par rapport à l'absence d'utilisation d'une couche de normalisation, comme le montre la figure ci-dessous.
ScribblePrompt-SAM adopte le modèle SAM minimal ViT-b et peaufine son décodeur. L'architecture SAM peut effectuer des prédictions en mode masque unique ou en mode masque multiple, où le décodeur génère une seule segmentation prédite en fonction d'une image d'entrée et des interactions de l'utilisateur. En mode multi-masque, le décodeur prédit 3 segmentations possibles puis prédit la segmentation avec l'IoU la plus élevée via la sortie MLP. Pour maximiser l'expressivité de l'architecture, nous formons et évaluons ScribblePrompt-SAM en mode multi-masque.
ScribblePrompt démontre sa supériorité sur les méthodes existantes
Dans cette étude, l'équipe de recherche a comparé ScribblePrompt-UNet et ScribblePrompt-SAM avec les méthodes de pointe existantes, notamment SAM, SAM-Med2D, MedSAM et MIDeepSeg, au moyen d'expériences de gribouillage manuel, d'interactions simulées et d'études d'utilisateurs avec des annotations expérimentées.
Dans l'expérience du graffiti manuel,Les résultats montrent que ScribblePrompt-UNet et ScribblePrompt-SAM produisent la segmentation la plus précise dans l'ensemble de données de gribouillage manuel expérimental et le gribouillage manuel en une seule étape de l'ensemble de données de gribouillage ACDC, comme indiqué dans le tableau suivant.
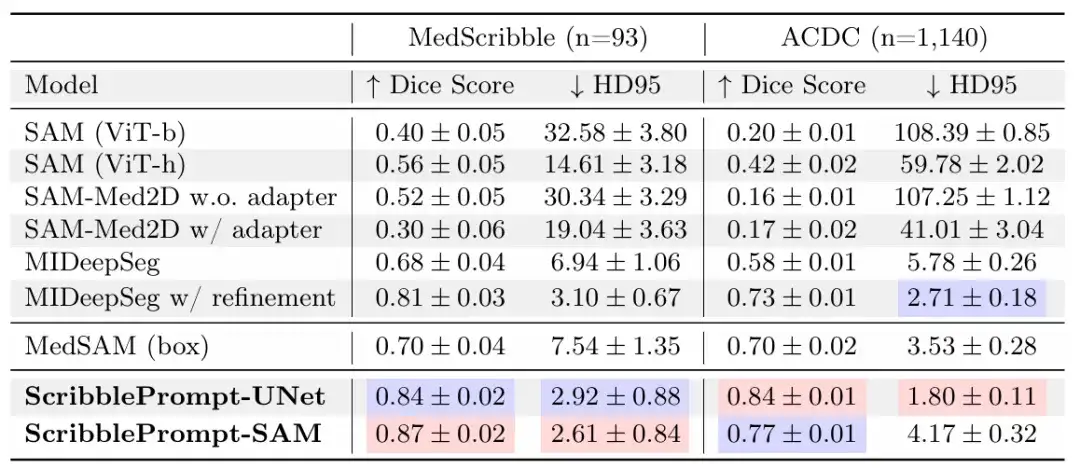
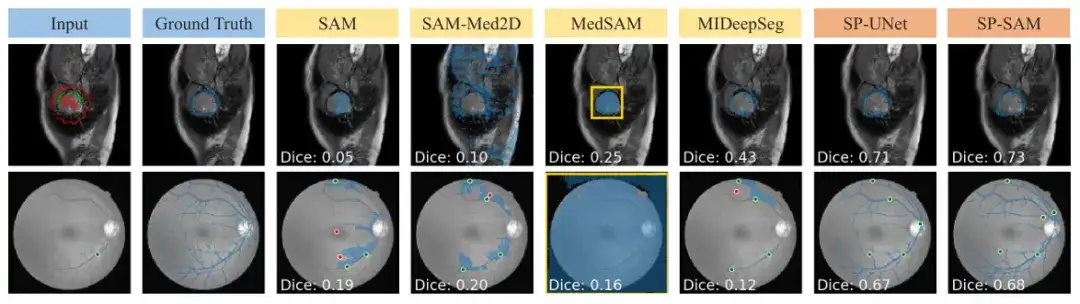
SAM et SAM-Med 2D ne peuvent pas être généralisés en douceur à une entrée griffonnée car ils n'ont pas été formés. MedSAM a de meilleures prédictions que les autres lignes de base SAM utilisant l'architecture SAM, mais il ne peut pas exploiter les gribouillis négatifs et manque donc souvent des segmentations avec des trous, comme le montre la figure ci-dessous. De plus, les prédictions initiales du réseau MIDeepSeg sont médiocres mais s’améliorent après l’application du processus de raffinement.
Dans l'expérience d'interaction simulée,Les résultats montrent que pour tous les processus d’interaction simulés pour tous les temps d’interaction, les deux versions de ScribblePrompt montrent une supériorité sur les méthodes de base. Comme le montre la figure ci-dessous.
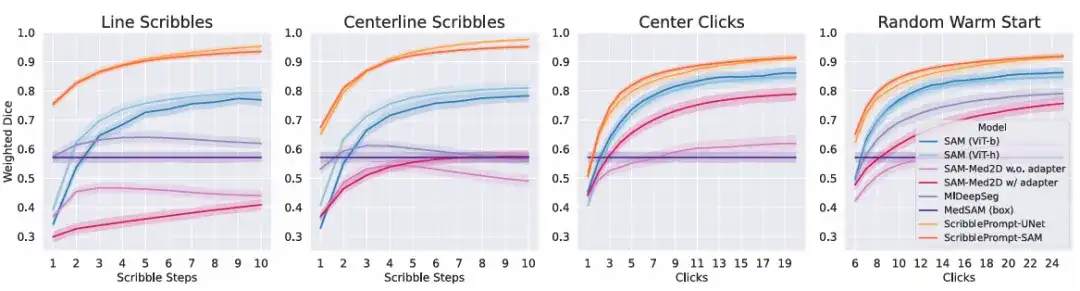
Pour évaluer davantage l’utilité réelle de ScribblePrompt,L’équipe a mené une étude utilisateur avec des annotateurs expérimentés.Cette série de comparaisons oppose ScribblePrompt-UNet et SAM (Vit-b) qui ont obtenu le score de dés le plus élevé dans l'expérience de clic ci-dessus. Les résultats ont montré que les participants ont produit des segmentations plus précises lorsqu’ils ont utilisé ScribblePrompt-UNet, comme indiqué dans le tableau ci-dessous. Pendant ce temps, chaque segmentation prenait environ 1,5 minute en moyenne avec ScribblePrompt-UNet, contre plus de 2 minutes par segmentation avec SAM.

Seize participants ont indiqué qu'il était plus facile d'obtenir une segmentation cible en utilisant ScribblePrompt qu'en utilisant SAM, dont 15 ont déclaré préférer utiliser ScribblePrompt, et le participant restant n'avait aucune préférence. De plus, 93,81 TP3T des participants ont préféré ScribblePrompt à la ligne de base SAM car il a amélioré les segments correspondants pour les corrections de gribouillis, et 87,51 TP3T des participants ont également préféré utiliser ScribblePrompt pour l'édition par clic.
Les résultats ci-dessus confirment une fois de plus les raisons les plus courantes pour lesquelles les participants préfèrent ScribblePrompt : l’autocorrection et les fonctionnalités interactives riches. Ce n’est pas possible avec d’autres méthodes. Par exemple, dans la segmentation des veines rétiniennes, le SAM a du mal à faire des prédictions précises même avec de multiples corrections.
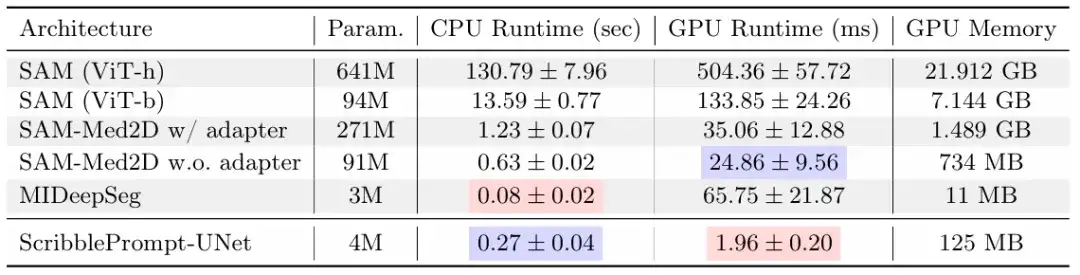
De plus, ScribblePrompt démontre également un faible coût et un déploiement facile. L’étude a révélé que sur un seul processeur, ScribblePrompt-UNet ne prend que 0,27 seconde par prédiction, avec une erreur de moins de 0,04 seconde. Comme le montre la figure ci-dessus, le GPU est le GPU Nvidia Quatro RTX8000. Alors que SAM (Vit-h) prend plus de 2 minutes par prédiction sur le CPU, SAM (Vit-b) prend environ 14 secondes par prédiction. Cela démontre sans aucun doute l’applicabilité de ce modèle dans des environnements à ressources extrêmement faibles.
Libérer le personnel médical et les chercheurs d'un travail chronophage et laborieux
L’intelligence artificielle a depuis longtemps montré un grand potentiel dans l’analyse d’images et le traitement d’autres données de grande dimension. La segmentation d'images médicales, en tant que tâche la plus courante dans l'analyse et le traitement d'images biomédicales, est naturellement devenue l'un des domaines de test importants pour l'autonomisation de l'intelligence artificielle.
En plus de cette étude,Comme mentionné dans l’article, SAM est également l’un des principaux outils qui a attiré le plus l’attention des équipes de recherche scientifique concernées ces dernières années.HyperAI a déjà mené des recherches de suivi sur des questions connexes, telles que La dernière application de SAM 2 est lancée ! L'équipe de l'Université d'Oxford a lancé Medical SAM 2, actualisant ainsi la liste SOTA de segmentation d'images médicales.Dans cet article, l’équipe de l’Université d’Oxford a partagé sa découverte du potentiel du SAM dans la segmentation des images médicales.
L’étude a présenté un modèle de segmentation d’images médicales appelé Medical SAM 2 développé par une équipe de l’Université d’Oxford. Conçu sur la base du framework SAM 2, il excelle non seulement dans les tâches de segmentation d'images médicales 3D en traitant les images médicales comme des vidéos, mais débloque également une nouvelle capacité de segmentation à invite unique. L'utilisateur n'a qu'à fournir un indice pour un nouvel objet spécifique, et la segmentation des objets similaires dans les images suivantes peut être automatiquement complétée par le modèle sans autre saisie.
certainement,Outre SAM, il existe de nombreuses autres études sur les méthodes de segmentation d’images médicales basées sur l’apprentissage profond.Par exemple, une étude intitulée « Scribformer : Transformer rend CNN plus performant pour la segmentation d’images médicales basée sur Scribble » a été publiée dans la revue et le magazine de renommée internationale IEEE Transactions on Medical Imaging.
L'étude a été publiée par une équipe de chercheurs de plusieurs institutions, dont l'Université de Xiamen, l'Université de Pékin, l'Université chinoise de Hong Kong, l'Université ShanghaiTech et l'Université de Hull au Royaume-Uni.L'étude a proposé une nouvelle solution hybride CNN-Transformer pour la segmentation d'images médicales supervisée par graffiti, appelée ScribFormer.
En bref, qu’il s’agisse des résultats des recherches du MIT, des innovations basées sur SAM ou d’autres nouvelles méthodes, l’objectif est le même. Comme le dit le proverbe, tous les chemins mènent à Rome. L’application de l’intelligence artificielle dans le domaine médical est bénéfique pour la médecine et la société.
Comme l'a déclaré Hallee E Wong, auteur principal de l'article ScribblePrompt et doctorante au MIT,« Nous souhaitons renforcer plutôt que remplacer les efforts des professionnels de santé grâce à un système interactif. »
Références :
1.https://news.mit.edu/2024/scribbleprompt-helping-doctors-annotate-medical-scans-0909
2.https://arxiv.org/pdf/2312.0738








