Command Palette
Search for a command to run...
Monseigneur, Les Temps De Vincent Van Gogh Ont Encore Changé ! Les Membres Principaux De SD Ont Créé Leur Propre Entreprise, Et Le Premier Modèle FLUX.1 Est Un Combat Difficile Contre SD 3 Et Midjourney

Depuis longtemps, depuis Midjourney avec divers styles artistiques, jusqu'à DALL-E soutenu par OpenAI, en passant par la diffusion stable open source (SD en abrégé), la qualité et la vitesse de génération du modèle graphique basé sur du texte ont été continuellement améliorées, et la compréhension rapide et le traitement des détails sont également devenus de nouvelles directions pour la circulation interne des principaux modèles.
Après être entrés en 2024, Midjourney et Stable Diffusion, qui sont au stade de la « course à deux chevaux », ont multiplié les efforts. SD 3 a été publié en premier, puis Midjourney V6.1 a également été mis à jour et itéré. Cependant, lorsque les gens sont encore plongés dans la comparaison entre SD 3 et Midjourney,Une nouvelle génération de « diable » est née tranquillement – FLUX est sorti de nulle part.
Lorsque FLUX génère des personnages, en particulier des scènes de personnes réelles, l’effet est très proche des prises de vue réelles. Les détails tels que l'expression du personnage, la brillance de la peau, la coiffure et la couleur sont très réalistes.Il a été autrefois salué comme le successeur de Stable Diffusion.Il est intéressant de noter que les deux entretiennent une relation étroite.
Robin Rombach, fondateur de Black Forest Labs, l'équipe derrière FLUX, est l'un des co-développeurs de Stable Diffusion. Après avoir quitté Stability AI, Robin a fondé Black Forest Labs.Et lancé le modèle FLUX.1.
Actuellement, FLUX.1 propose 3 versions : Pro, Dev et Schnell. La version Pro est une version à code source fermé fournie via une API, qui peut être utilisée à des fins commerciales et est également la version la plus puissante ; la version Dev est une version open-source « distillée » directement de la version Pro, avec une licence non commerciale ; la version Schnell est la version simplifiée la plus rapide, qui fonctionnerait jusqu'à 10 fois plus vite. Il est open source et utilise la licence Apache 2, adapté au développement local et à l'usage personnel.
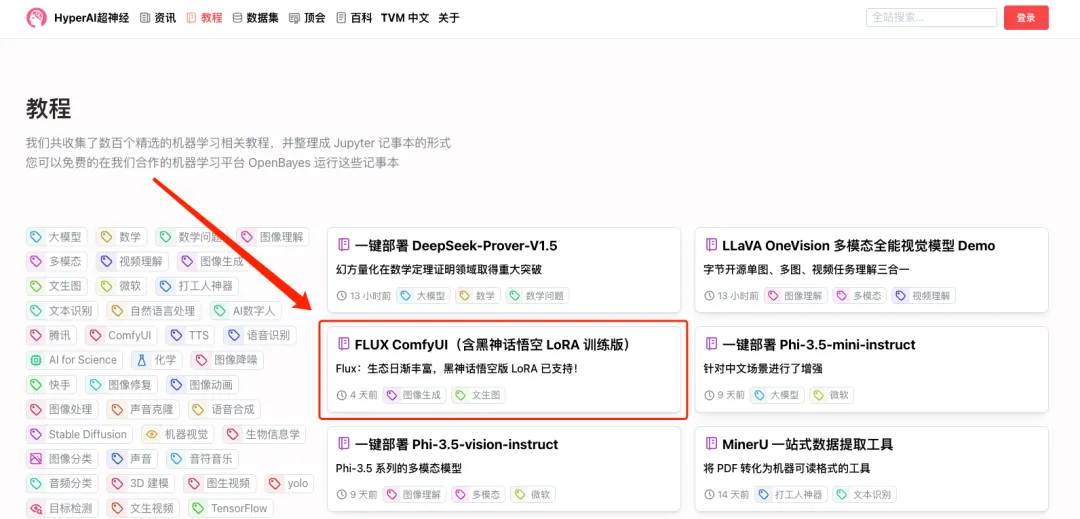
Je crois que beaucoup d’entre vous veulent réellement découvrir cette nouvelle génération d’images littéraires de premier ordre !La section tutoriel du site Web officiel d'HyperAI (hyper.ai) a maintenant lancé « FLUX ComfyUI (y compris la version de formation Black Myth Wukong LoRA) », qui est la version ComfyUI de FLUX [dev] et prend également en charge la formation LoRA.
Amis intéressés, venez vivre l'expérience ! Je l'ai essayé pour vous, et l'effet est aussi bon que SD 3 et Midjourney↓

La même invite, générée par 3 modèles
* invite : une fille tient une pancarte sur laquelle est écrit « Je suis une IA »
De plus, Jack-Cui, un Up Master populaire sur Bilibili, a également créé un didacticiel de fonctionnement détaillé pour enseigner à tout le monde étape par étape !
Adresse du tutoriel :
Vidéo de l'opération :
https://www.bilibili.com/video/BV1xSpKeVEeM
Essai de démonstration
FLUX ComfyUI Run
1. Connectez-vous à hyper.ai, sur la page Tutoriel, cliquez sur Exécuter ce tutoriel en ligne. "FLUX ComfyUI (y compris la version de formation Black Myth Wukong LoRA)", cliquez sur "Exécuter ce tutoriel en ligne".
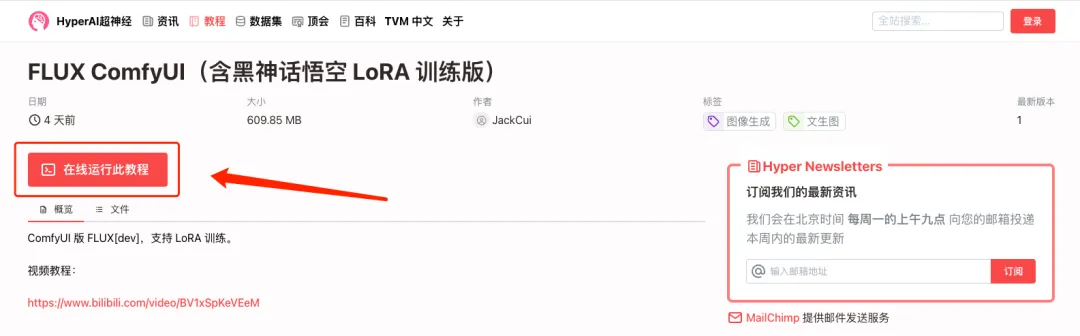
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
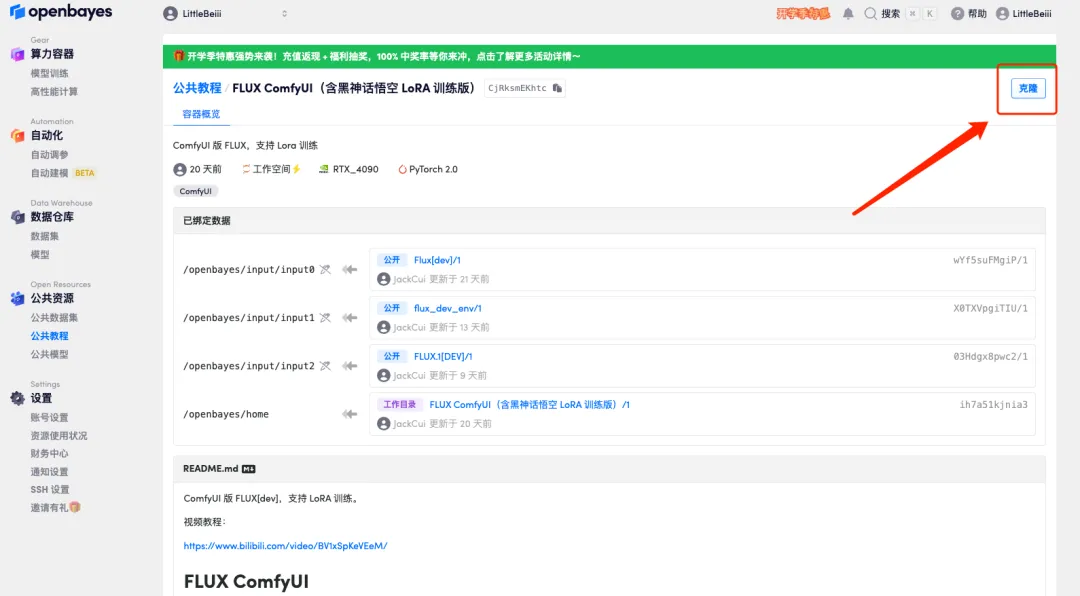
3. Cliquez sur « Suivant : sélectionner le taux de hachage » dans le coin inférieur droit.
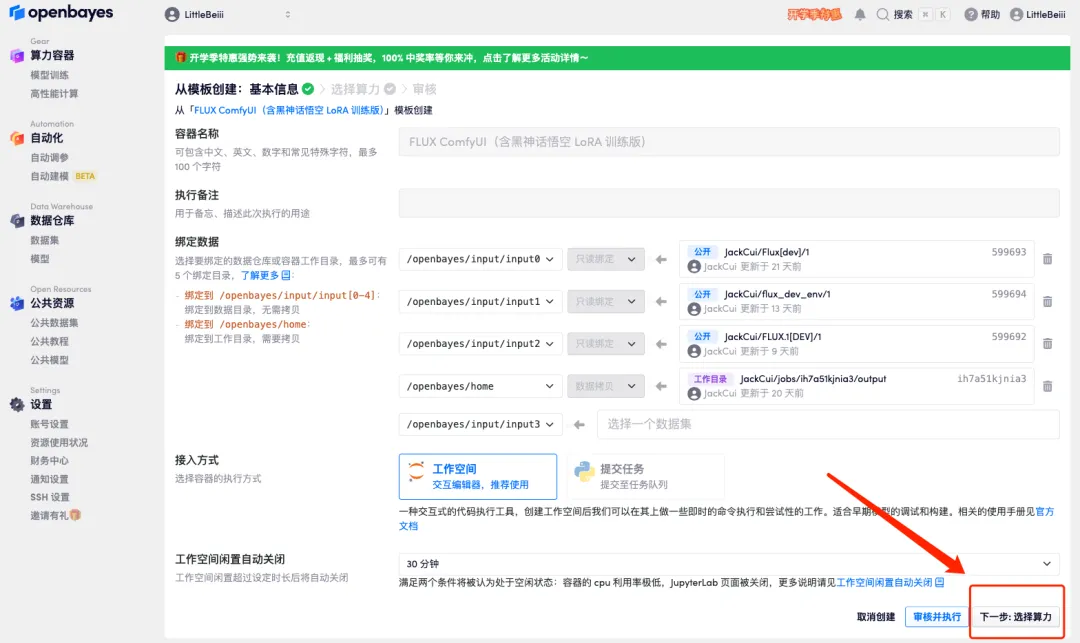
4. Une fois la page affichée, sélectionnez « NVIDIA RTX 4090 » et l'image « PyTorch », puis cliquez sur « Suivant : Réviser ».Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
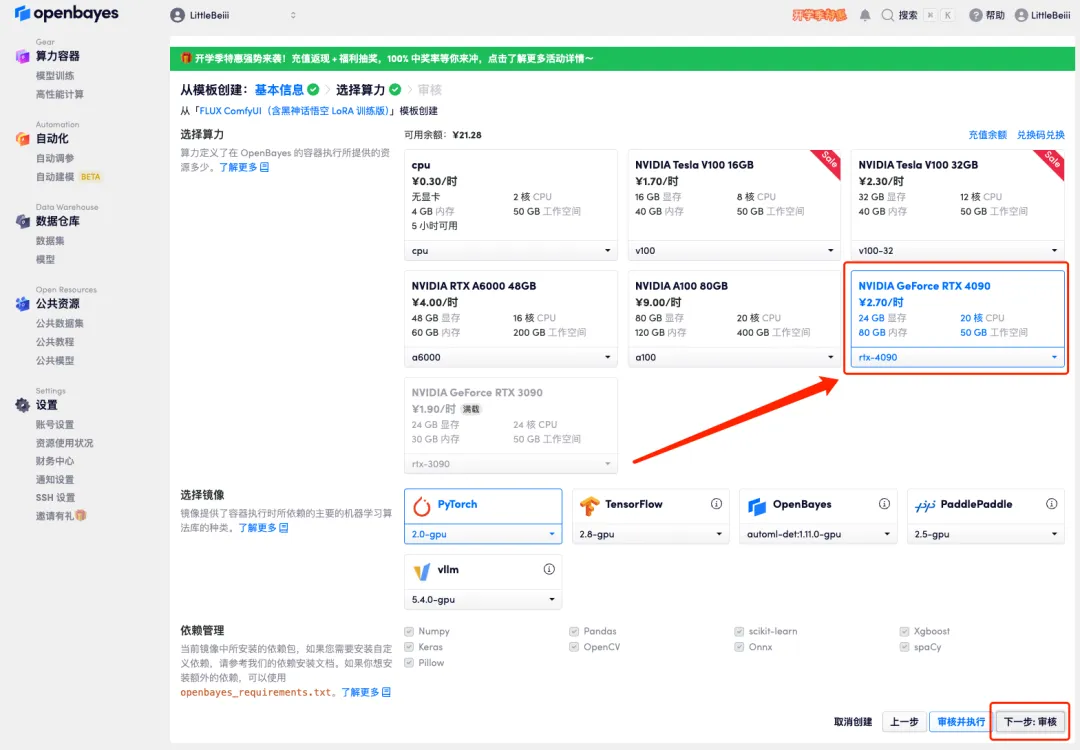
5. Après confirmation, cliquez sur « Continuer » et attendez que les ressources soient allouées. Le premier processus de clonage prendra environ 1 à 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration.Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
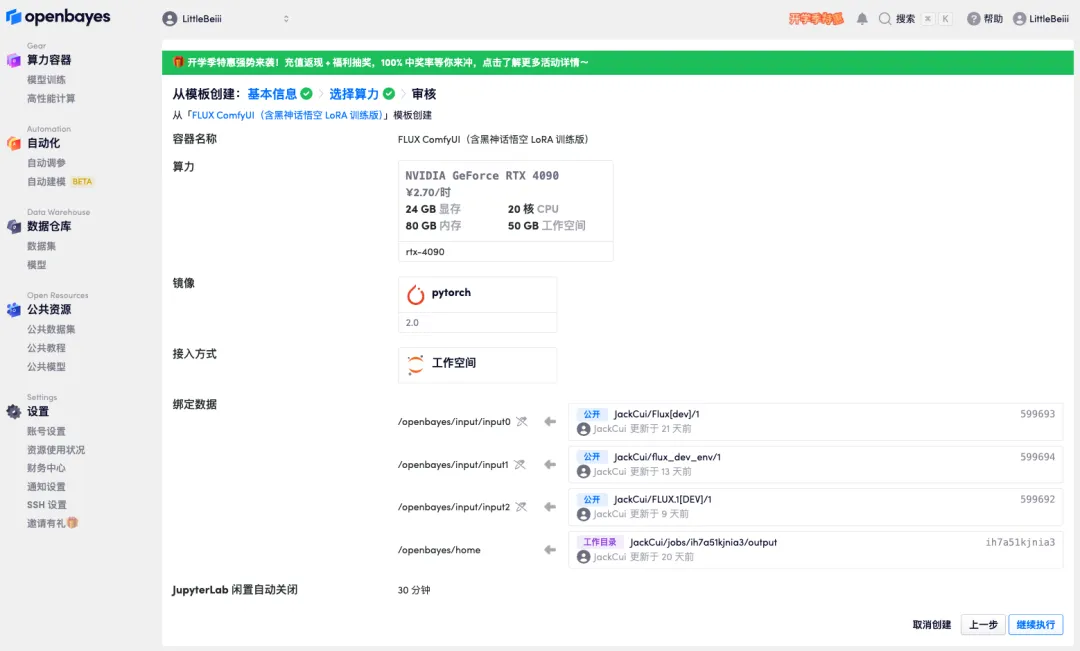
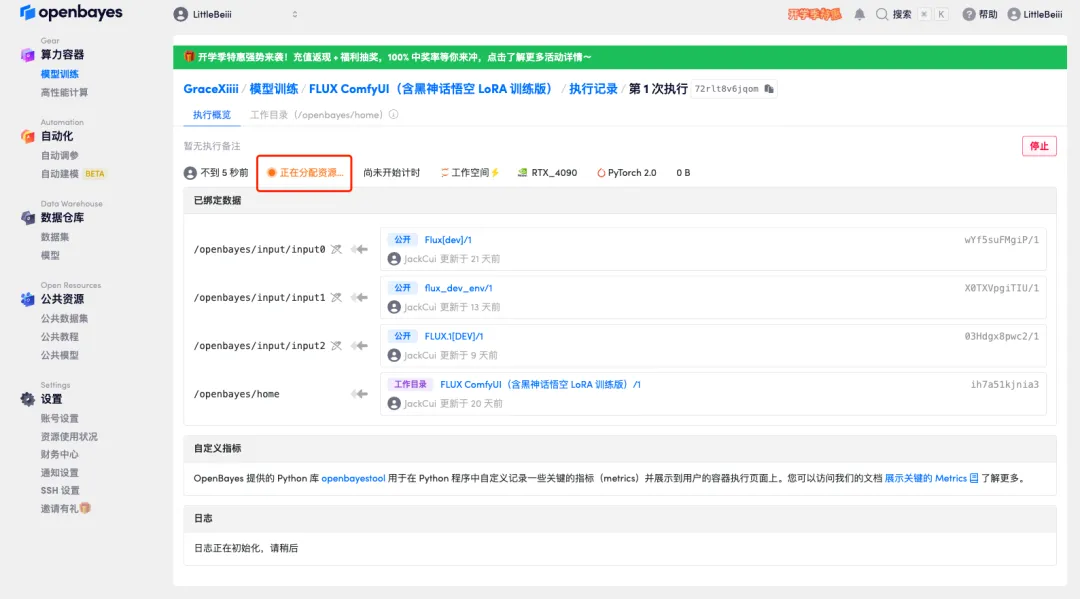
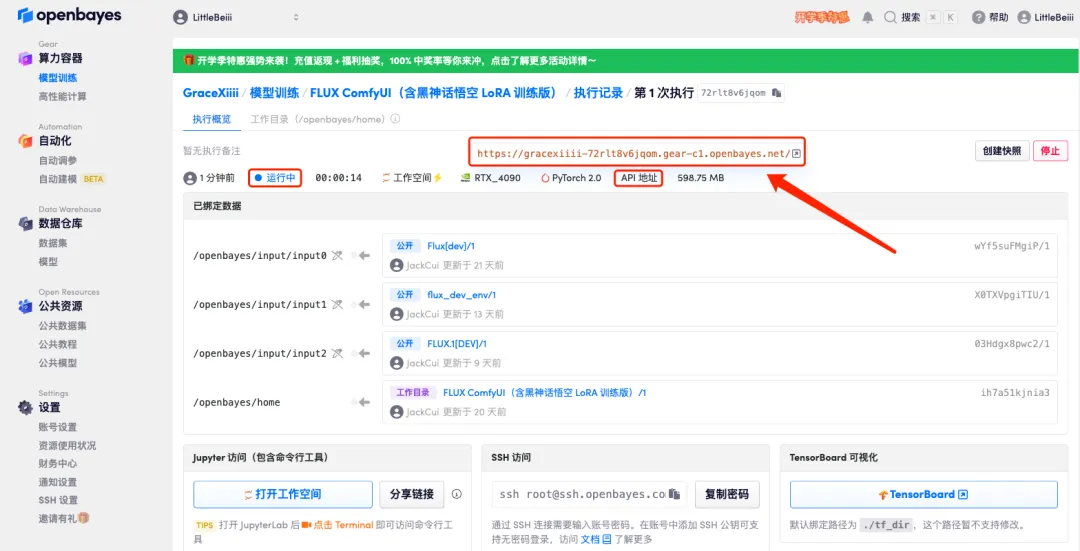
6. Après avoir ouvert la démo, cliquez sur « Changer de langue » pour changer la langue en chinois.
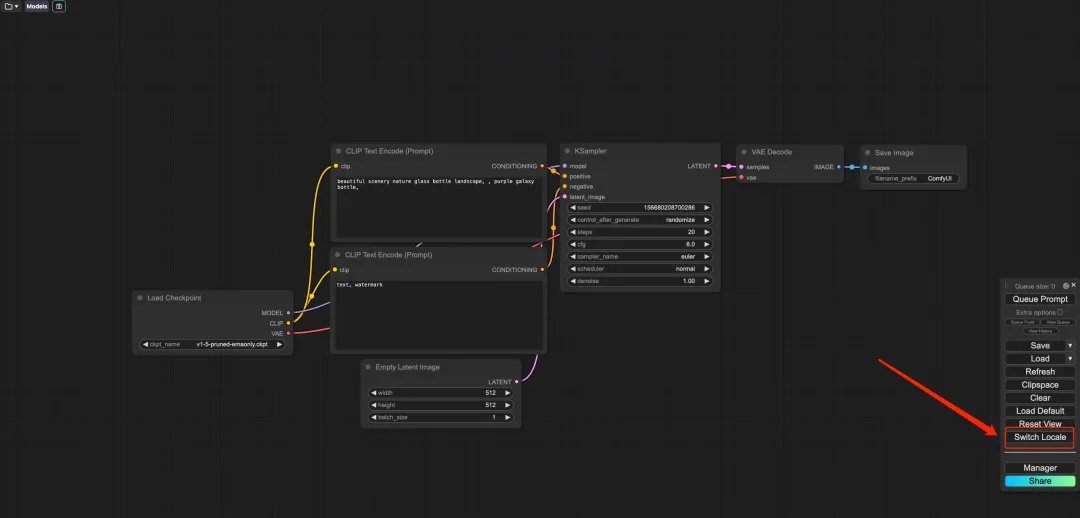
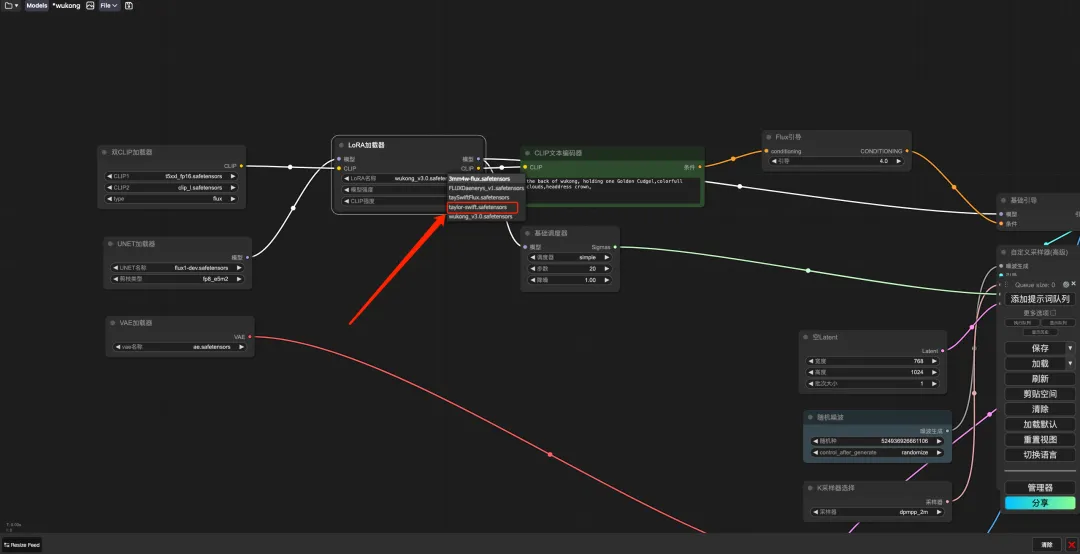
7. Après avoir changé de langue, cliquez sur l'icône du dossier dans le coin supérieur gauche pour sélectionner le flux de travail requis.
* Wukong : Démo d'image de Wukong du mythe noir
* TED : démonstration du discours TED en direct
* 3mm4w : Démonstration d'écriture de texte sur des images
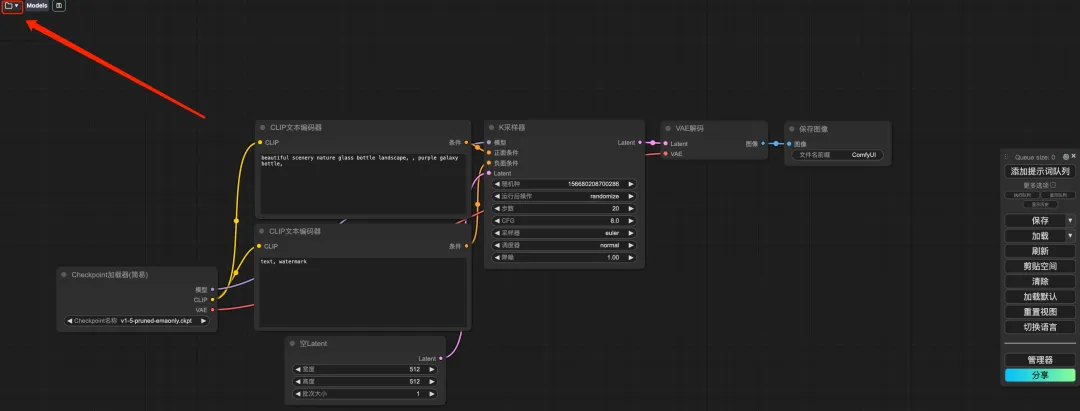
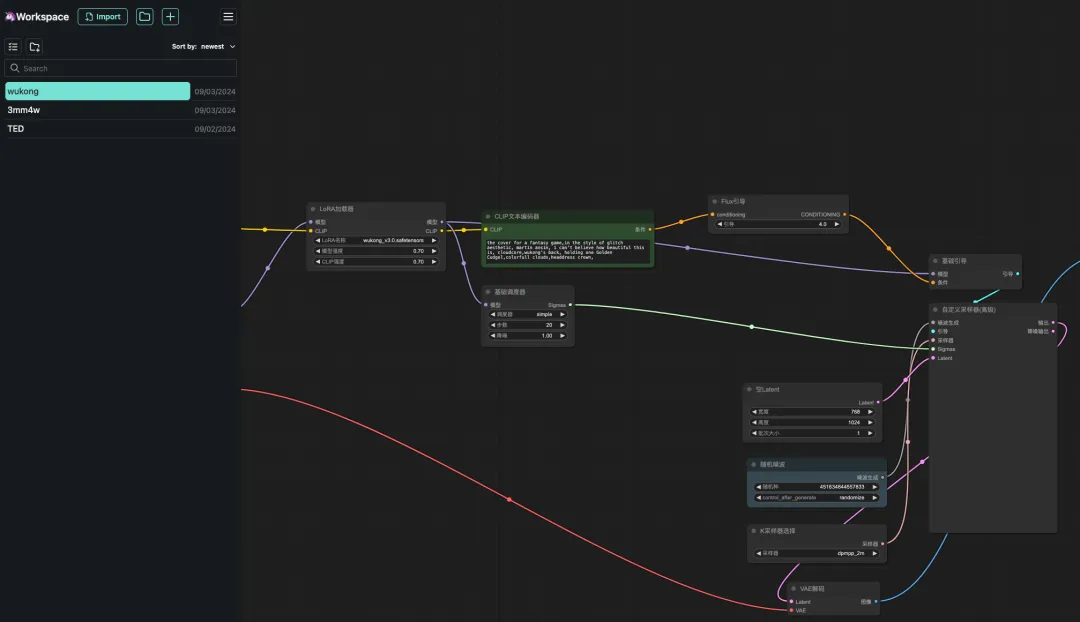
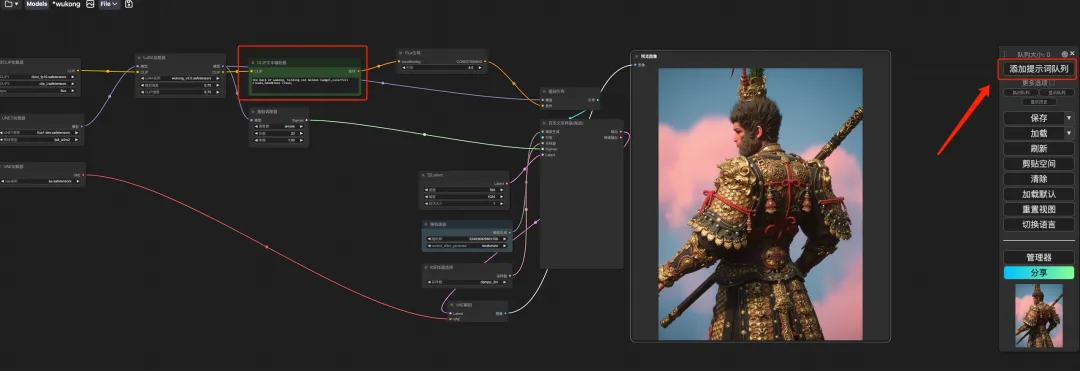
8. Sélectionnez le flux de travail « wukong », entrez Prompt dans le générateur de texte CLIP (par exemple : le dos de wukong, tenant un gourdin doré, des nuages colorés, une couronne de coiffe), cliquez sur « Ajouter une file d'attente de mots d'invite pour générer l'image », et vous pouvez voir que l'image générée est très belle.

Formation FLUX LoRA
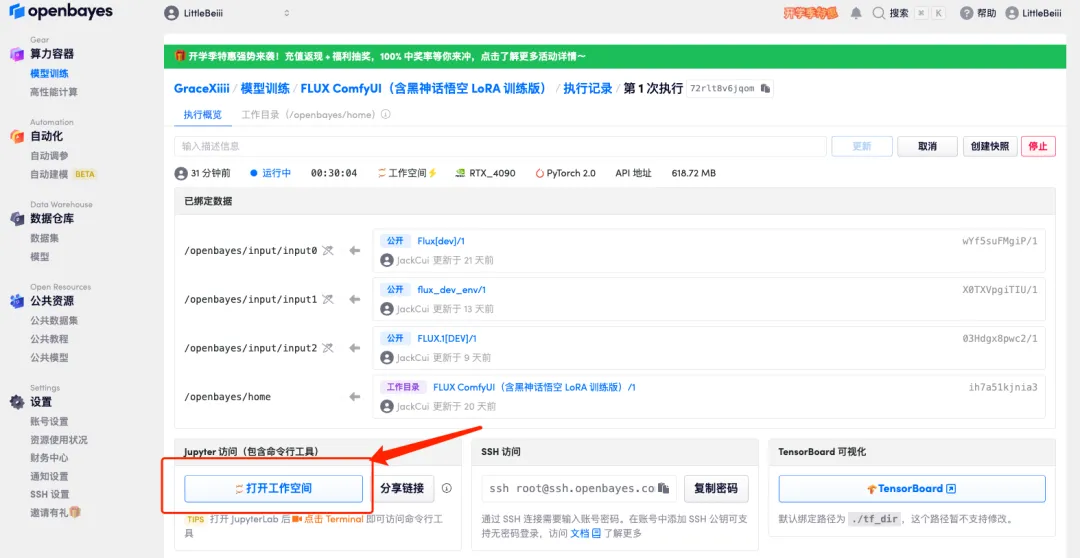
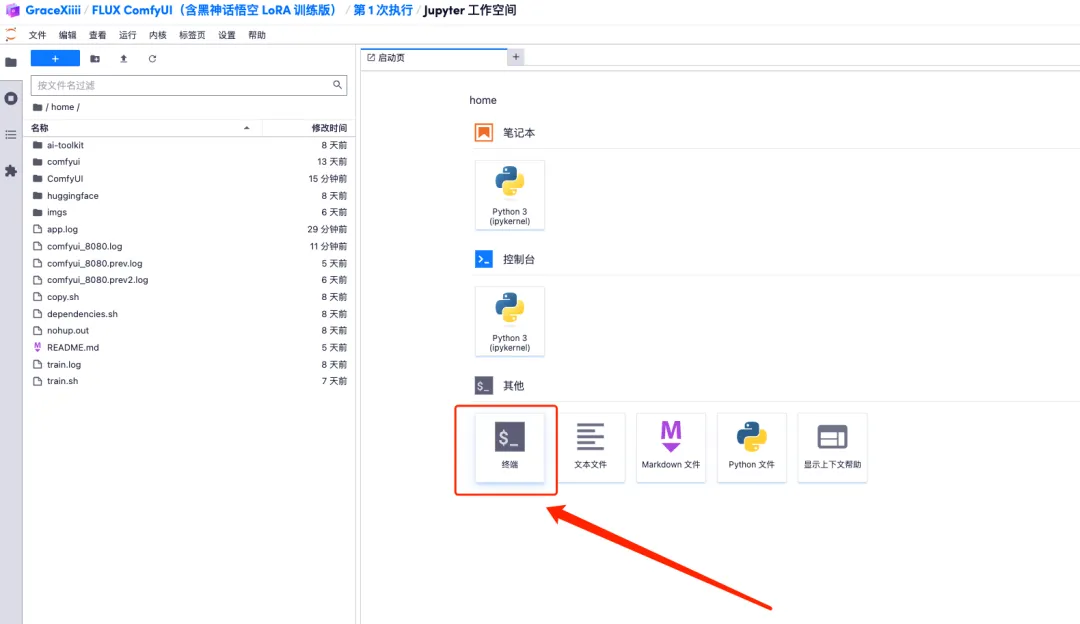
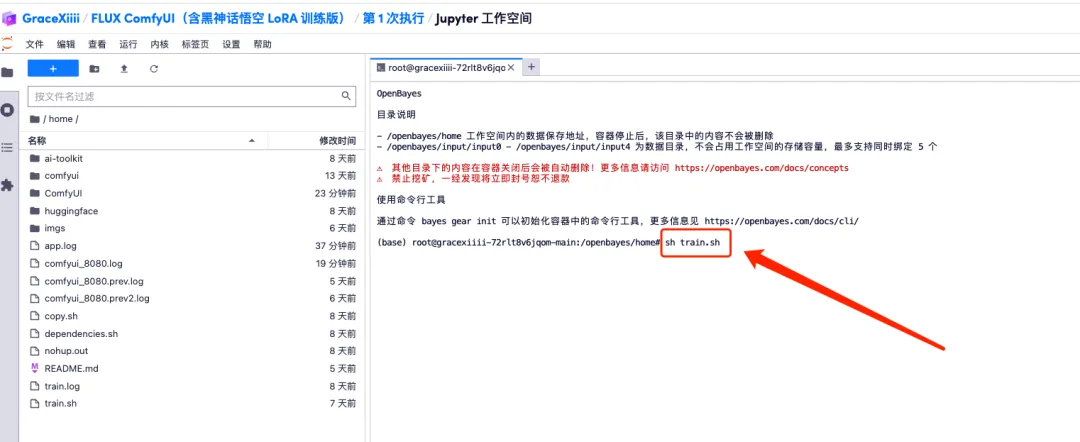
1. Pour personnaliser le flux de travail, nous devons d’abord former le modèle LoRA. Revenez maintenant à l'interface du conteneur, cliquez sur « Ouvrir l'espace de travail » et créez un nouveau terminal.
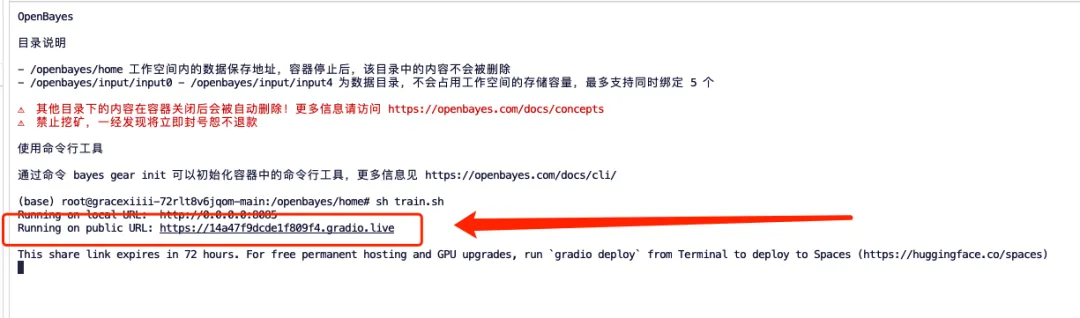
2. Entrez « sh train.sh » dans le terminal et appuyez sur Entrée pour exécuter. Lorsque « Exécution sur une URL publique » apparaît, cliquez sur le lien.
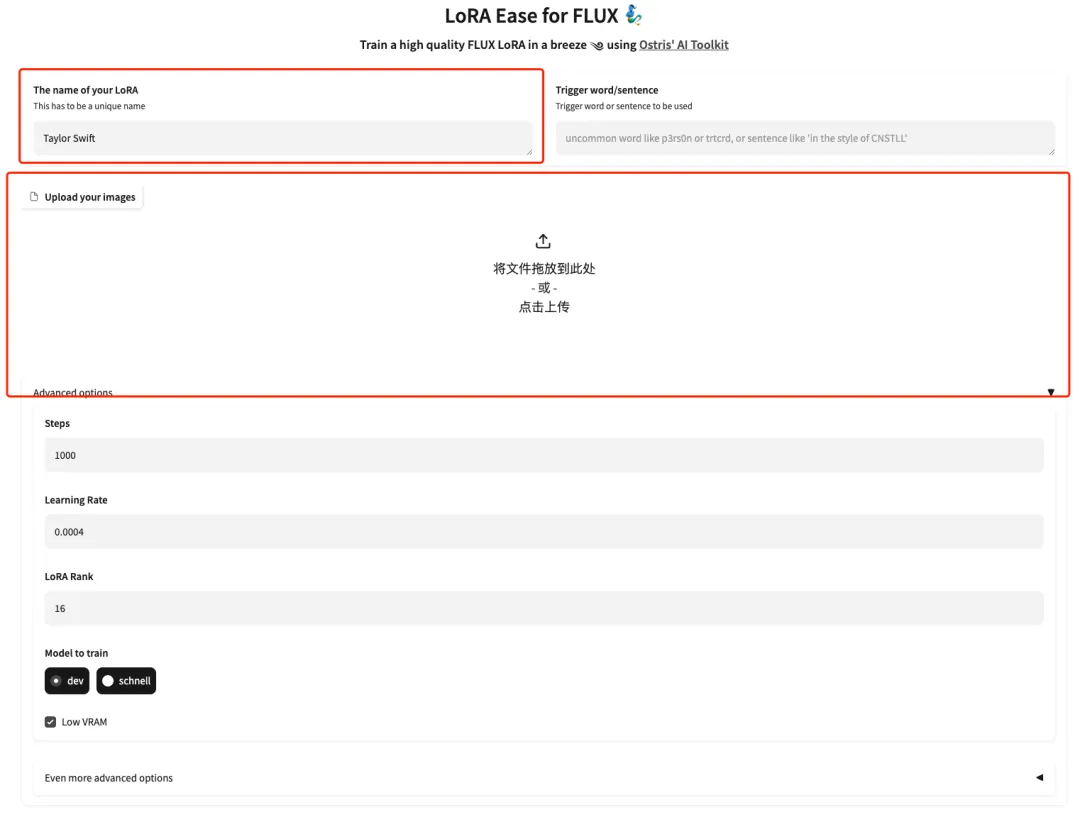
3. Une fois la page affichée, entrez le modèle du modèle et téléchargez les images. Ici, téléchargez 5 photos de Taylor Swift.Veuillez noter que l'image doit être une photo frontale haute résolution avec un rapport de visage plus grand. Plus la qualité de l’image est bonne, meilleur est l’effet d’entraînement.
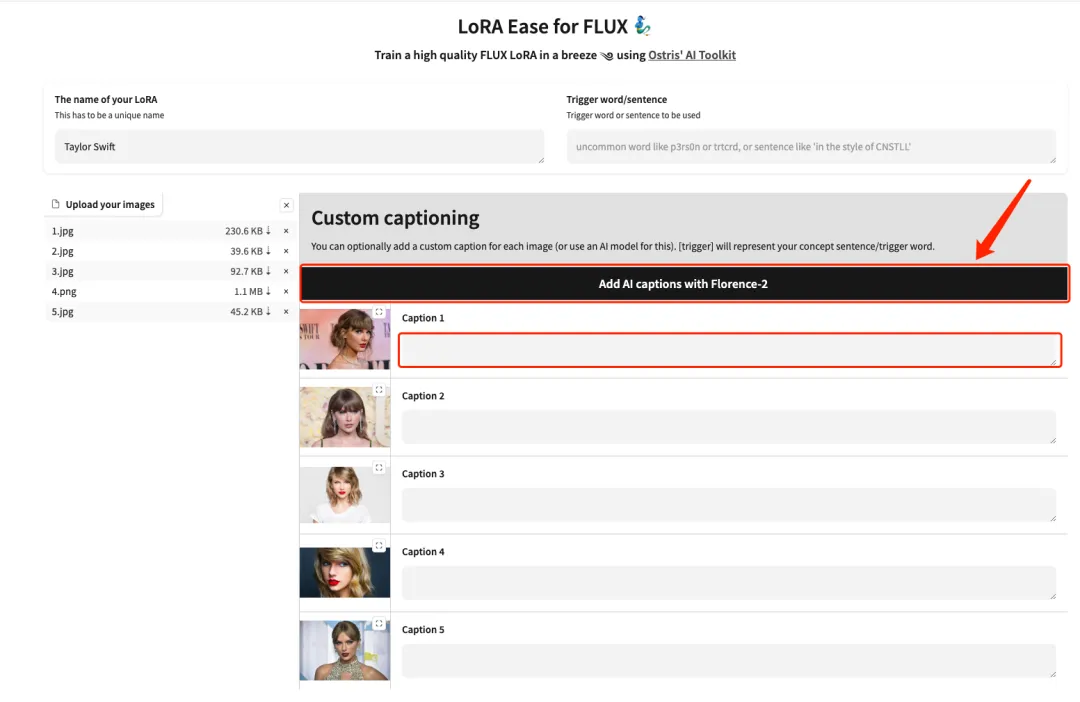
4. Une fois le téléchargement terminé, ajoutez manuellement des descriptions de texte en anglais après chaque image ou cliquez sur « Ajouter des légendes AI avec Florence-2 » pour générer automatiquement des descriptions de texte.
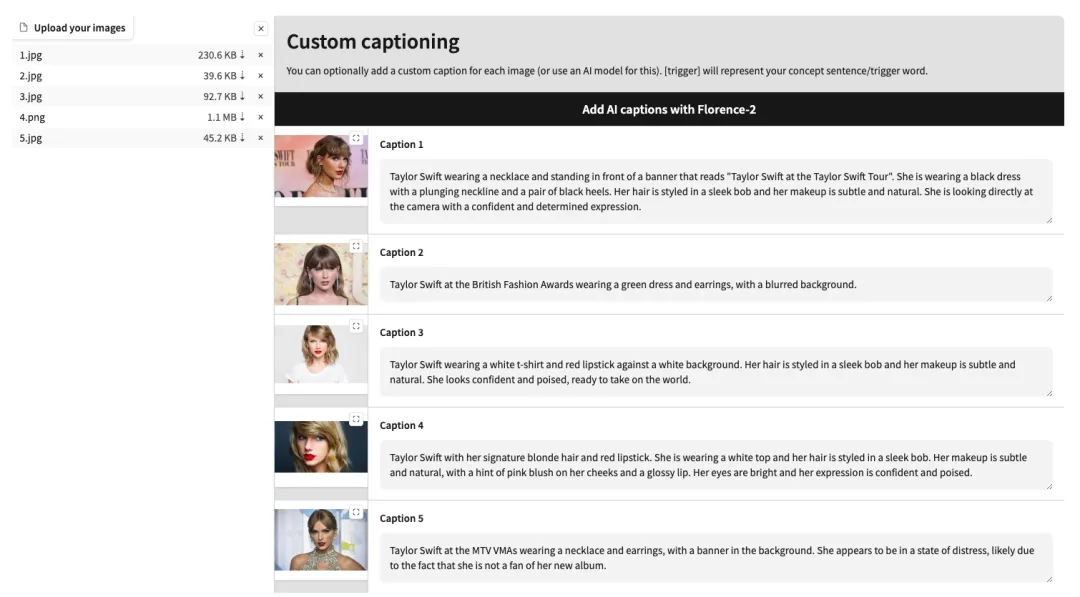
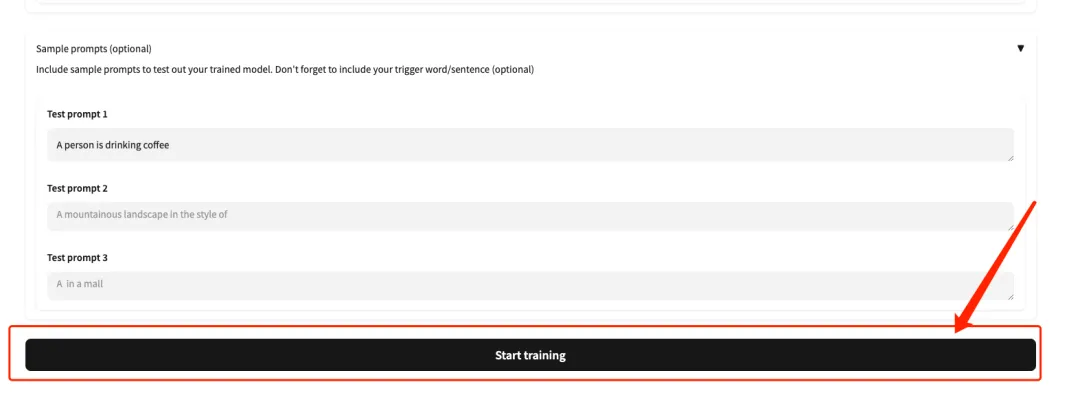
5. Faites défiler la page jusqu'en bas, saisissez une invite de test (par exemple : une personne boit du café) et cliquez sur « Démarrer l'entraînement ».
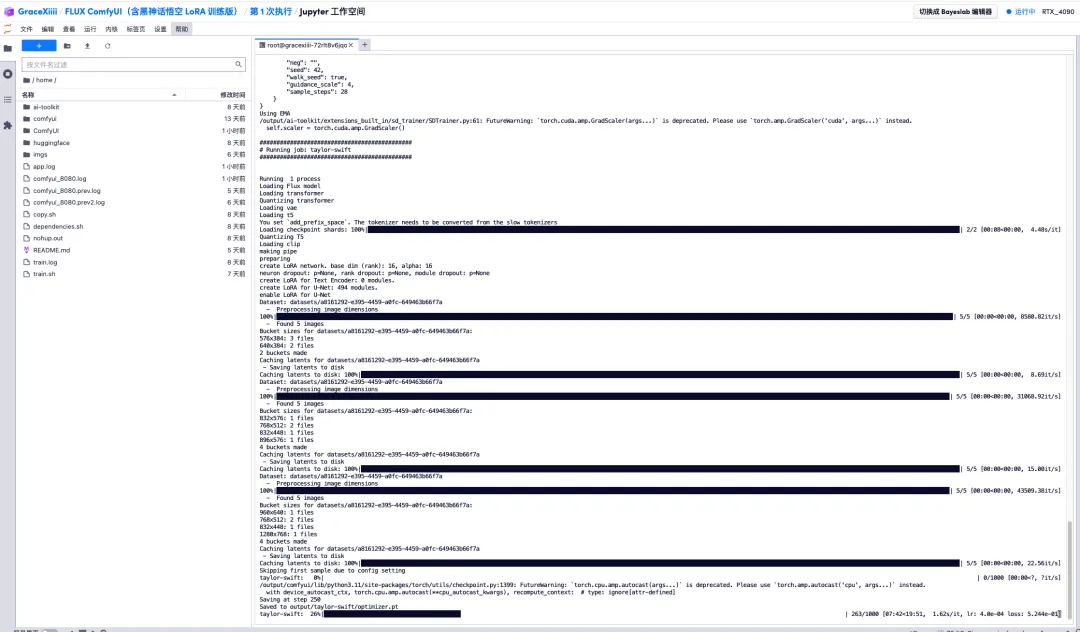
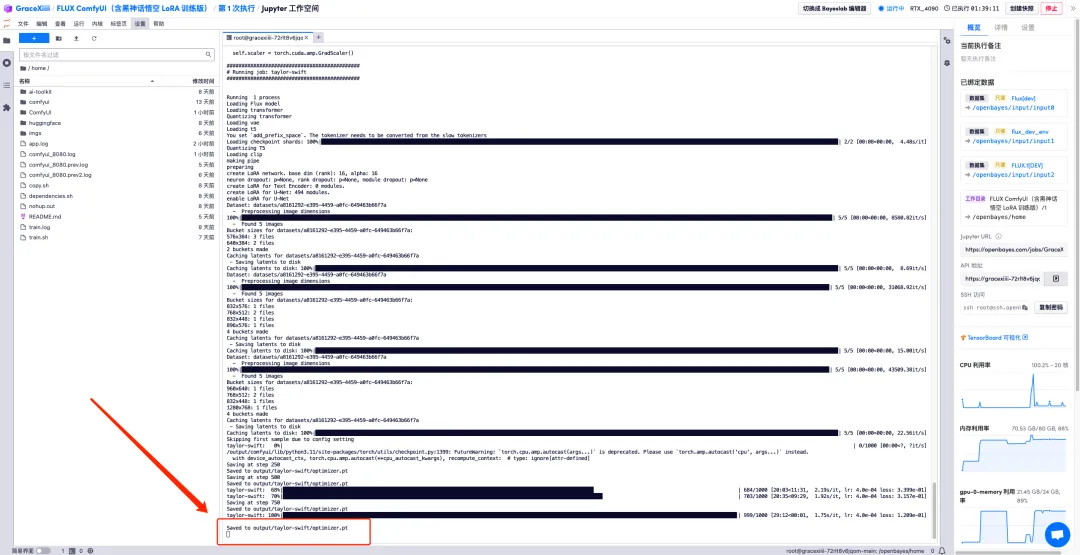
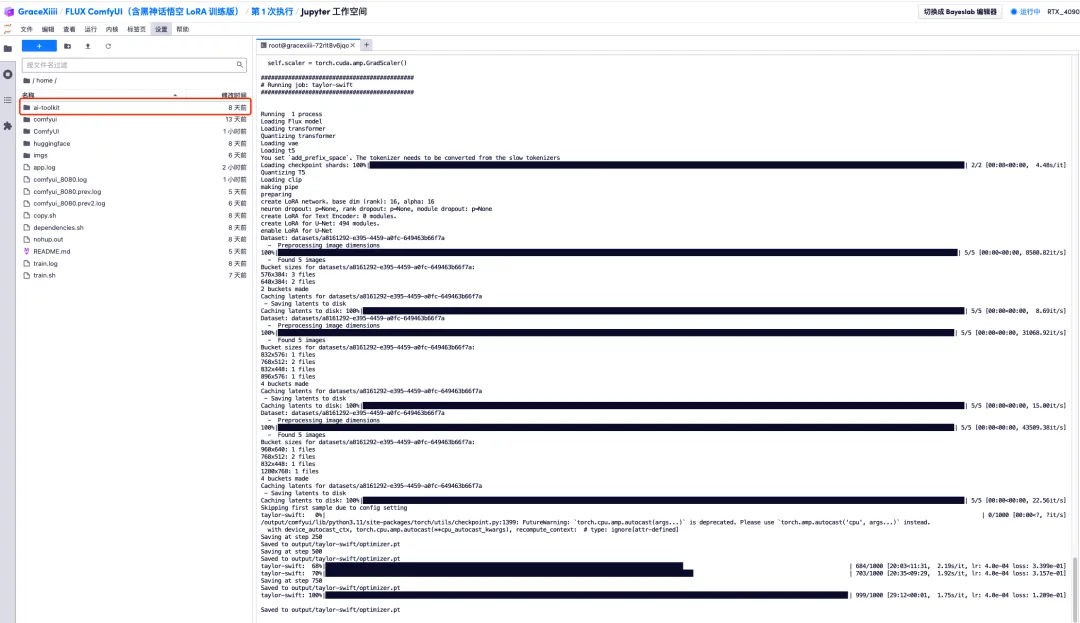
6. Après avoir attendu quelques minutes, nous revenons à l'interface du terminal et pouvons voir la barre de progression de la formation. La formation sera complétée en environ 40 minutes. Lorsque « Enregistré dans output/taylor-swift/optimizer.pt » apparaît, la formation est terminée.
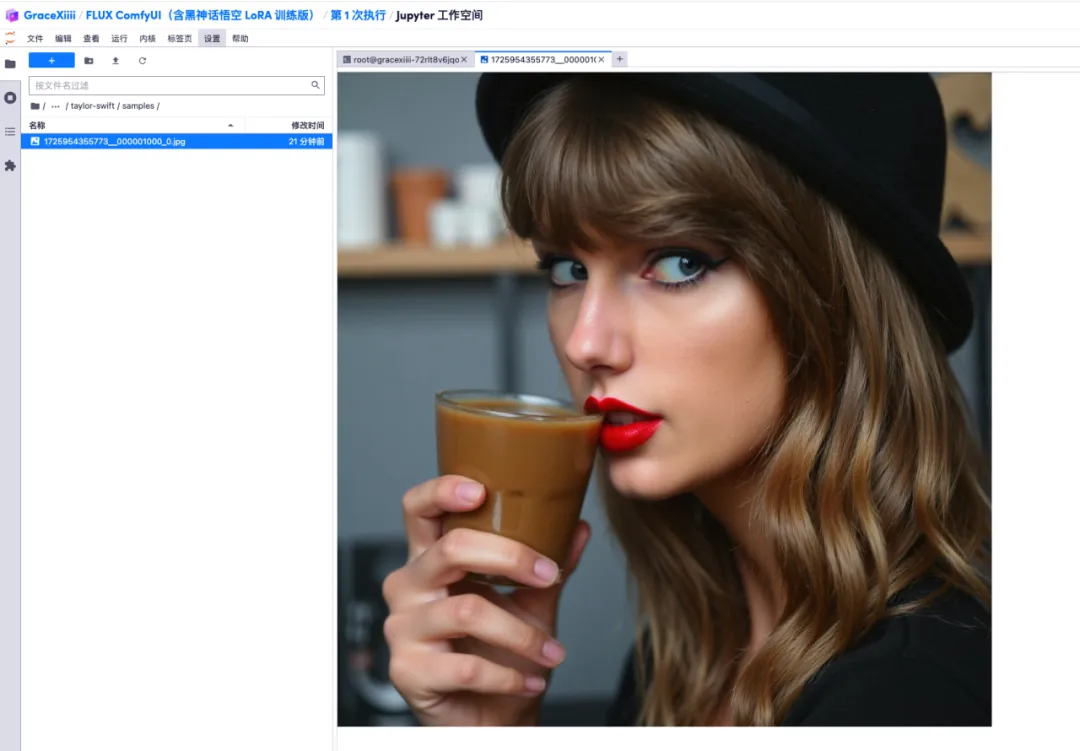
7. Dans le fichier « ai-toolkit » - « output » - « taylor swift » - « sample » sur la gauche, vous pouvez voir l’effet de notre invite de test. Si l’effet est bon, cela prouve que notre modèle a été formé avec succès.
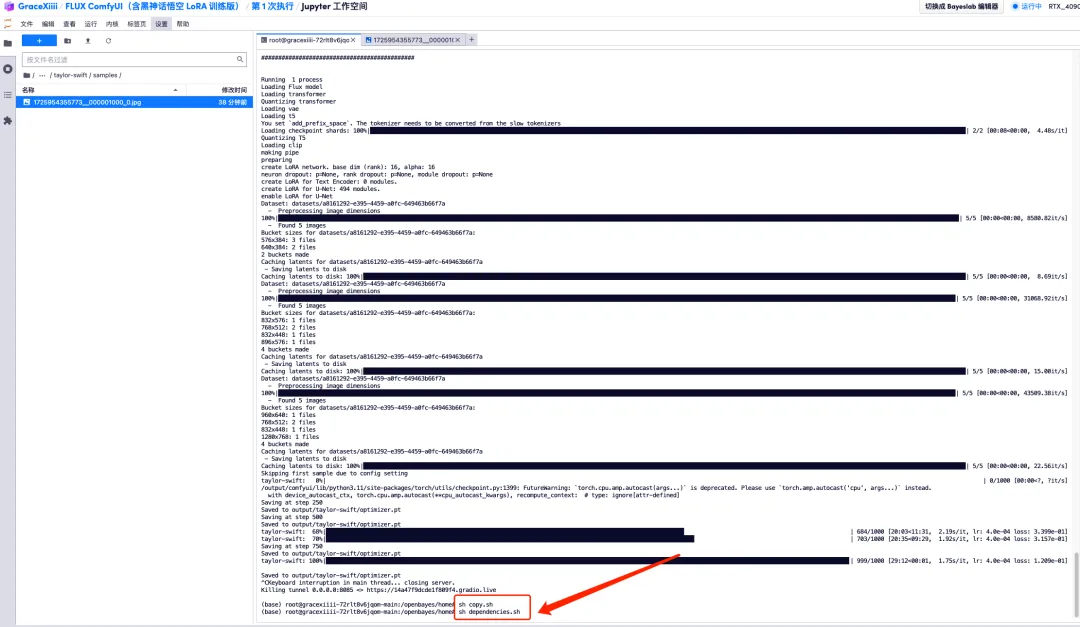
8. Une fois le modèle formé, nous devons arrêter le service de formation pour libérer les ressources GPU, revenir à l'interface clé à l'instant et appuyer sur « Ctrl+C » pour terminer la formation.
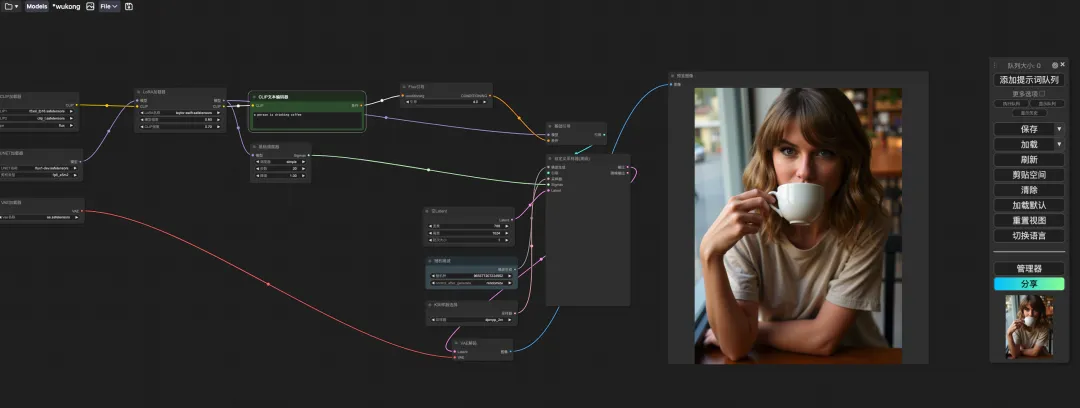
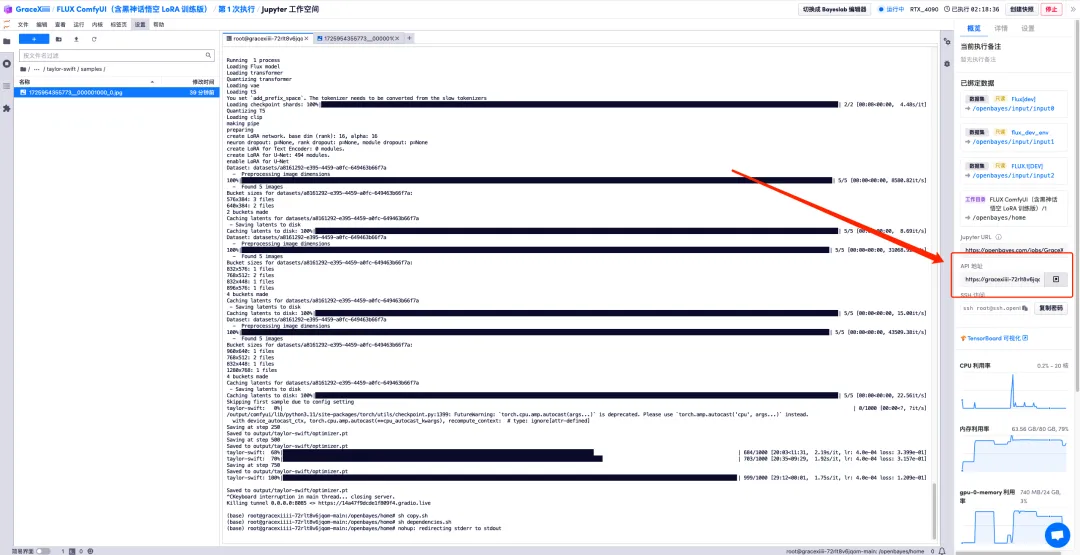
9. Exécutez « sh copy.sh », puis exécutez « sh dependencies.sh » pour démarrer ComfyUI, attendez 2 minutes et ouvrez l'adresse API sur la droite.
10. Une fois la page affichée, sélectionnez le modèle formé dans « LoRA Loader », saisissez Prompt (par exemple : une personne boit du café) dans « CLIP » et cliquez sur « Ajouter une file d'attente de mots d'invite » pour générer l'image.