Command Palette
Search for a command to run...
En Comparant 11 Algorithmes Horizontalement, l'Université De Toronto a Lancé Un Modèle d'apprentissage Automatique Pour Accélérer Le Développement De Nouveaux Médicaments Injectables À Action prolongée.
Selon le « Rapport sur l'état nutritionnel et les maladies chroniques des résidents chinois (2020) », en 2019, les décès causés par des maladies chroniques représentaient 88,51 % du total des décès dans mon pays.Les maladies chroniques sont devenues une menace majeure pour la santé humaine.Prenons l’exemple de la schizophrénie, une maladie chronique que les chercheurs appellent « la pire maladie de l’humanité ». Si les patients veulent se rétablir complètement, ils ont besoin d’une longue période de traitement d’entretien. Cependant, pendant cette période, les patients peuvent interrompre le traitement pour diverses raisons, ce qui entraîne une rechute.
Afin de résoudre le problème de la mauvaise observance du traitement médicamenteux chez les patients chroniques, des injections à action prolongée ont vu le jour. Ce médicament est fabriqué en dissolvant une dose suffisante du médicament dans une certaine préparation, qui pénètre dans le corps par injection pour former un petit « entrepôt de stockage » de médicament, puis libère lentement le médicament dans le corps pour exercer un effet thérapeutique stable. Par rapport aux médecines traditionnelles,Les injections à action prolongée présentent les avantages d’intervalles de dosage longs, d’une action rapide et d’un dosage stable du médicament.
D’autre part, la recherche et le développement de ce nouveau type de médicament sont également assez difficiles. Par exemple, pour obtenir la libération optimale du médicament dans l’organisme dans un délai spécifié, un grand nombre d’expériences approfondies sont nécessaires sur une variété de formulations candidates. Ce processus est fastidieux et prend du temps, ce qui constitue un goulot d’étranglement pour le développement ultérieur d’injections à action prolongée.
Récemment, des chercheurs de l’Université de Toronto ont développé un modèle d’apprentissage automatique. Des résultats expérimentaux pertinents montrent que le modèle peut prédire avec précision le taux de libération de médicaments injectables à action prolongée, accélérant ainsi efficacement le développement de médicaments injectables à action prolongée.La recherche a été publiée dans la revue Nature Communications.Le titre est « Modèles d’apprentissage automatique pour accélérer la conception d’injectables polymères à action prolongée ».

Les résultats ont été publiés dans Nature Communications.
Adresse du document :
https://www.nature.com/articles/s41467-022-35343-w#Abs1
Aperçu de l'expérience
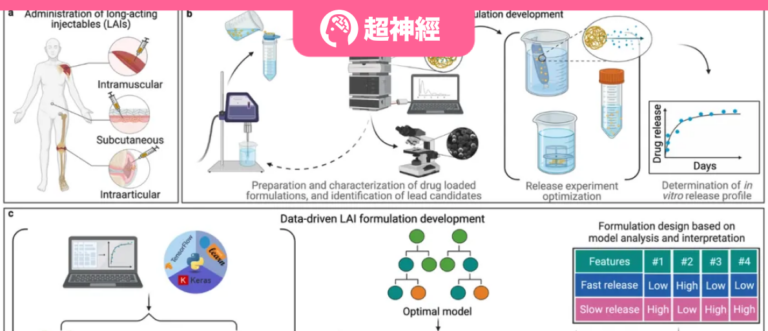
Les préparations injectables à action prolongée sont disponibles sous différents types, généralement des lipides et des polymères synthétiques.La figure ci-dessous montre une comparaison entre les approches traditionnelles et celles basées sur les données pour le développement de formulations injectables à action prolongée.

Figure 1 : Diagramme schématique des approches de R&D traditionnelles et basées sur les données pour les formulations injectables à action prolongée
a Figure : Voies d’administration des formulations injectables à action prolongée approuvées par la Food and Drug Administration des États-Unis.
Figure b : Cycle typique d’essais et d’erreurs dans le développement de formulations injectables traditionnelles à action prolongée.
Figure c : Aperçu du flux de travail de cette étude, qui utilise des modèles d’apprentissage automatique formés pour accélérer le processus de développement de formulations injectables à action prolongée.
Cet ensemble de données expérimentales est construit à partir de résultats de recherche publiés précédemment.Des données provenant de sources externes recherchées à l'aide du moteur Web of Science sont également ajoutées. Plus précisément, l’ensemble de données comprend les quantités libérées (le nombre de molécules de médicament libérées dans un temps donné) de 181 médicaments et de 43 combinaisons médicament-polymère. Dans le même temps, les chercheurs ont divisé l’ensemble de données construit en deux sous-ensembles :Ils sont utilisés respectivement pour la formation et les tests de modèles.
Ensemble de données sur les injectables à action prolongée
Agence d'édition :Université de Toronto
Quantité incluse :Lancement de 181 médicaments et de 43 combinaisons médicament-polymère
Taille estimée :394,1 Ko
Heure de sortie :2022
Adresse de téléchargement :hyper.ai/datasets/23625
Procédures expérimentales
Dans cette étude, les chercheurs ont formé un total de 11 algorithmes d’apprentissage automatique.Y compris la régression linéaire multiple (MLR), l'opérateur de sélection et de rétrécissement absolu le moins élevé (Lasso), la régression des moindres carrés partiels (PLS), l'arbre de décision (DT), la forêt aléatoire (RF), la machine de boosting de gradient léger (LGBM), le boosting de gradient extrême (XGB), le boosting de gradient naturel (NGB), la régression de vecteur de support (SVR), l'algorithme des k plus proches voisins (k-NN) et le réseau neuronal (NN).
Sélection du modèle
Pour évaluer les performances prédictives de ces modèles d’apprentissage automatique, les chercheurs ont utilisé une approche de validation croisée imbriquée composée d’une boucle interne (formation et validation) et externe (test). Le processus spécifique consiste pour les chercheurs à regrouper d’abord l’ensemble de données en fonction de la combinaison médicament-polymère.Ensuite, 10 expériences de validation croisée imbriquées ont été réalisées sur chaque modèle d’apprentissage automatique.
Enfin, les performances de prédiction de chaque modèle d’apprentissage automatique dans les boucles de validation croisée imbriquées internes et externes sont résumées dans le tableau 1 et la figure 2 ci-dessous. Le tableau 1 montre les valeurs d'erreur absolue moyenne (MAE) et d'erreur standard moyenne (σM, indiquées entre parenthèses) obtenues après avoir prédit la libération de médicament à l'aide de différents algorithmes d'apprentissage automatique dans une validation croisée imbriquée (n = 10). Comme on peut le voir dans le tableau,Les modèles de machines basés sur des arbres sont généralement plus précis que les modèles linéaires, basés sur des instances et d'apprentissage en profondeur (MAE < 0,16).

Tableau 1 : Performances de prédiction de chaque modèle d'apprentissage automatique dans la validation croisée imbriquée
La figure 2 montre les valeurs d’erreur absolue (AE) des prédictions de libération de médicament obtenues dans la validation croisée imbriquée (n = 10). En combinant les informations du tableau 1 et de la figure 1, le modèle basé sur LGBM présente la plus petite valeur MAE et la plus petite valeur AE dans les boucles interne et externe parmi les 11 modèles. donc,Les chercheurs estiment que le modèle basé sur le LGBM est celui qui présente les meilleures performances prédictives.

Figure 2 : Performances de prédiction globales de chaque modèle d'algorithme
Les cercles noirs et les lignes pointillées noires dans les cases de la figure représentent respectivement la valeur MAE et la valeur AE de chaque modèle.
Optimisation du modèle
Afin d'améliorer encore la capacité de généralisation des modèles d'apprentissage automatique,Les chercheurs ont également optimisé et amélioré le modèle LGBM avec 17 fonctionnalités grâce à l'analyse de cluster.
Ici, ils ont utilisé l’algorithme de clustering des voisins les plus éloignés, comme illustré dans la figure ci-dessous, pour organiser les fonctionnalités d’entrée dans une hiérarchie. Les chercheurs ont trouvé une redondance dans 17 caractéristiques. Après des améliorations,finalIl a été déterminé que le modèle LGBM avec 15 fonctionnalités était le plus performant.

Figure 3 : Carte thermique du coefficient de corrélation de Spearman des 17 entités d'entrée initiales
Le bleu foncé indique un coefficient de corrélation de Spearman absolu (une méthode permettant d'étudier la corrélation entre deux variables en fonction des données de rang) de 1, et le rose indique un coefficient de corrélation de Spearman absolu de 0. La carte thermique est accompagnée d'un dendrogramme montrant la hiérarchie des groupes de caractéristiques identifiés par une analyse de groupe hiérarchique agglomérative.
Résultats expérimentaux
Après avoir obtenu le modèle optimal ci-dessus, les chercheurs ont effectué deux tests. L’une consistait à utiliser le modèle pour prédire la courbe de libération du médicament d’un certain médicament injectable à action prolongée, et l’autre consistait à utiliser le modèle pour prédire la courbe de libération du médicament-polymère dans l’ensemble de test. Les résultats ont été comparés aux courbes expérimentales de libération de médicament et les résultats sont présentés dans la figure ci-dessous.
La figure 4 montre la comparaison des profils de libération de médicament prévus et expérimentaux pour une injection à action prolongée sélectionnée, et la figure 5 montre la comparaison des profils de libération de médicament pour les profils de libération de médicament-polymère et de médicament expérimental. On peut voir que dans les deux cas,Les valeurs prédites et les valeurs expérimentales sont fondamentalement cohérentes.Par conséquent, les chercheurs pensent que le modèle basé sur l’algorithme LGBM peut prédire avec précision le taux de libération du médicament lors d’injections à action prolongée.

Figure 4 : Comparaison des courbes de libération de médicament prédites et expérimentales pour les injections à action prolongée dans l'ensemble de données

Figure 5 : Comparaison des profils de libération de médicament-polymère prévus et des profils expérimentaux correspondants
Alliance d'accélération : Aider à la mise en œuvre de nouveaux paradigmes de recherche scientifique
Il convient de noter queLes auteurs de cette recherche, Christine Allen et Alán Aspuru-Guzik, sont tous deux issus du Consortium d’accélération (AC).Née en 2021, l'Accelerator Alliance est une nouvelle collaboration mondiale entre le monde universitaire, l'industrie et le gouvernement, dont le siège est à l'Université de Toronto, au Canada, avec la vision d'utiliser l'IA et la robotique pour accélérer la découverte et la conception de nouveaux matériaux et molécules.
« Notre objectif est d’accélérer la science »,« Pour atteindre cet objectif, nous avons réalisé que nous pouvions étendre la réflexion sur la conduite autonome aux laboratoires automatisés, en utilisant l'IA et l'automatisation pour expérimenter de manière plus intelligente », a déclaré Alán Aspuru-Guzik, directeur de l'Accelerator Alliance.

Figure 6 : Accelerator Alliance, un scientifique extrait des réactifs pré-distribués d'un robot de distribution de solides automatisé
Il convient de noter que le mois dernier, l'Accelerator Alliance a reçu une subvention de 200 millions de dollars américains du Fonds d'excellence en recherche Apogée Canada (FARC), qui servira à soutenir les travaux de l'alliance dans le domaine des « laboratoires autonomes ». Meric Gertler, président de l’Université de Toronto, a déclaré :« Ces investissements importants dans la recherche et l’innovation axées sur l’IA ont le potentiel d’améliorer la vie des gens au Canada et partout dans le monde. ».
L'adresse du code de cette étude :
https://github.com/aspuru-guzik-group/long-acting-injectables








