Command Palette
Search for a command to run...
L'outil De Traitement De Données Open Source 10k Star Est Lancé En Un Clic ! Prend En Charge La Reconnaissance De 176 Langues ; Le Premier Ensemble De Données De Détection De Chute d'objets De Grande Hauteur Est En Ligne, Comprenant Près De 2 000 Vidéos Dans 18 Scènes

Dans le domaine de l’intelligence artificielle, le traitement des données multimodales a toujours été un problème difficile. Face à des PDF complexes, des pages Web et des livres électroniques aux formats multiples, il n’est pas facile d’extraire efficacement les informations clés.
Le laboratoire d'intelligence artificielle de Shanghai et l'équipe OpenDataLab ont lancé un outil d'extraction de données intelligent open source - MinerU, qui peut convertir des documents PDF multimodaux contenant des éléments tels que des images, des formules, des tableaux, etc. au format Markdown facile à analyser. Il prend également en charge l'extraction de contenu à partir de pages Web et de livres électroniques, résolvant ainsi le besoin d'extraire automatiquement des données de haute qualité à partir de documents complexes.
Le site officiel hyper.ai a lancé la « Démo de l'outil d'extraction de données à guichet unique MinerU ».Faites défiler vers le bas pour obtenir le lien~
Du 26 au 30 août, le site officiel hyper.ai est mis à jour :
* Sélection de tutoriels de haute qualité : 3
* Ensembles de données publiques de haute qualité : 10
* Sélection d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en septembre : 7
Visitez le site officiel :hyper.ai
Tutoriels publics sélectionnés
1. MinerU, outil d'extraction de données unique
MinerU est un outil qui convertit les PDF en formats lisibles par machine (tels que Markdown, JSON), qui peuvent être facilement extraits dans n'importe quel format, prend en charge la reconnaissance précise de 176 langues et effectue une identification précise du type de langue. Le modèle et l'environnement ont été déployés. Vous pouvez utiliser le grand modèle pour la génération d'inférences conformément aux instructions du didacticiel.
Utilisation directe :https://go.hyper.ai/MIitP
2. Déploiement en un clic de LongWriter-glm4-9b
LongWriter est un projet open source développé par l'Université Tsinghua qui génère des textes très longs (plus de 10 000 mots) en utilisant un modèle de langage étendu à contexte long (LLM). Ce tutoriel est une démonstration de déploiement en un clic du modèle. Il vous suffit de cloner et de démarrer le conteneur et de copier directement l'adresse API générée pour expérimenter l'inférence du modèle.
Utilisation directe :https://go.hyper.ai/Xvktt
L’utilisation de programmes de formation humaine numérique traditionnels pour générer un humain numérique de haute qualité nécessite souvent beaucoup de temps et de ressources informatiques, et présente également des exigences élevées en matière de matériel de formation. L’émergence de MuseV et de MuseTalk a apporté de nouvelles avancées dans le domaine des humains numériques. Après avoir utilisé MuseV pour générer des vidéos humaines numériques, MuseTalk est utilisé pour synchroniser les mouvements des lèvres et l'audio, et une production humaine numérique complète peut être réalisée en quelques minutes seulement. Ils ont tous été téléchargés dans le module de didacticiel public de hyper.ai et peuvent être clonés et exécutés en ligne en un clic !
Tutoriel MuseV :https://go.hyper.ai/9fExW
Tutoriels MuseTalk :https://go.hyper.ai/wiw8g
Ensembles de données publiques sélectionnés
1. Ensemble de données de détection d'objets tombants FADE autour des bâtiments
L'ensemble de données FADE contient 1 881 vidéos couvrant 18 scènes, 8 catégories différentes d'objets en chute, 4 conditions météorologiques différentes et 4 résolutions vidéo. La diversité et la spécialisation de l'ensemble de données FADE en font une ressource précieuse pour étudier la détection d'objets tombés autour des bâtiments.
Utilisation directe :https://go.hyper.ai/8u8Sr
2. Ensemble de données d'algorithme de disposition de puces ChiPBench Al
ChiPBench est un benchmark complet spécialement conçu pour évaluer l'efficacité des algorithmes de placement de puces basés sur l'IA existants pour améliorer la métrique PPA de conception finale. L'équipe de recherche a collecté 20 circuits de différents domaines (tels que CPU, GPU et microcontrôleur). Ces conceptions permettent d’évaluer l’impact de l’algorithme de placement sur le PPA de conception final.
Utilisation directe :https://go.hyper.ai/LN4Ab
3. Ensemble de données sur les visages humains
L'ensemble de données contient environ 9,6 000 images de visages, dont 5 000 sont des images de visages réelles et 4,63 000 sont des images de visages générées par l'IA.
Utilisation directe :https://go.hyper.ai/N5nVT
4. Ensemble de données de référence pour les questions-réponses TableBench
L'ensemble de données contient 886 échantillons provenant de 18 domaines et est conçu pour faciliter la vérification des faits, le raisonnement numérique, l'analyse des données et les tâches de visualisation.
Utilisation directe :https://go.hyper.ai/Qcs2F
5. Ensemble de données de reconnaissance vidéo de détection de deepfake
L'ensemble de données contient plus de 363 clips originaux mettant en vedette 28 acteurs jouant dans 16 scènes différentes. Ces vidéos de haute qualité fournissent une base solide pour la formation des modèles sur du contenu réel. En plus des données originales, l'ensemble de données contient également plus de 3 000 vidéos traitées générées à l'aide de la méthode DeepFakes.
Utilisation directe :https://go.hyper.ai/Jw59B
6. Classification des véhicules Ensemble de données de classification d'images de véhicules
Cet ensemble de données est conçu pour la tâche de classification des véhicules et contient 5,6 000 images divisées en 7 catégories. Chaque catégorie représente un type de véhicule différent (pousse-pousse, vélo, voiture, moto, avion, bateau, train), et toutes les images sont au format JPEG avec une extension .jpg. Idéal pour créer et tester des modèles de classification d'images afin de distinguer différents types de véhicules.
Utilisation directe :https://go.hyper.ai/e9LNg
7. Détection sur les pistes Ensemble de données de détection du comportement humain sur les pistes
L'ensemble de données contient 3 766 images d'humains sur des voies ferrées avec une résolution de 1 080 × 1 080. Chaque image est annotée avec des cadres de délimitation marquant la présence humaine et leurs actions sur les voies ferrées.
Utilisation directe :https://go.hyper.ai/dsr49
8. Ensemble de données de segmentation de scènes audiovisuelles Ref-AVS
L'ensemble de données Ref-AVS est une référence pour les tâches de segmentation d'objets dans les scènes audiovisuelles. L'ensemble de données contient 48 vidéos d'objets audibles, spécifiquement classés en : 20 instruments de musique, 8 animaux, 15 machines et 5 humains.
Utilisation directe :https://go.hyper.ai/pGHwm
9. Ensemble de données de segmentation d'images médicales COSMOS 1050K
L'ensemble de données comprend 53 ensembles de données médicales publiques compilés par l'équipe de recherche, couvrant 18 modalités, 84 objets, 1050 000 images 2D et 6033 masques.
Utilisation directe :https://go.hyper.ai/nHETv
Cet ensemble de données est un ensemble de données HUST-OBC de haute qualité proposé par Wang Pengjie et d'autres membres de l'équipe de recherche du professeur Bai Xiang à l'Université des sciences et technologies de Huazhong. Il est collecté à partir de 3 sources différentes, notamment des livres, des sites Web et des ensembles de données existants. L'ensemble de données contient deux types d'images d'échantillons d'os d'oracle. L'une est constituée des images d'os d'oracle obtenues à partir des numérisations traitées des frottages d'os d'oracle originaux, et l'autre est constituée des images d'os d'oracle manuscrites basées sur les os d'oracle originaux, qui sont ensuite subdivisées en images basées sur des frottages et en images manuscrites basées sur des glyphes.
Utilisation directe :https://go.hyper.ai/46AiA
Pour plus d'ensembles de données publics, veuillez visiter :
Articles de la communauté
L'équipe de l'Université d'Oxford a développé un modèle de segmentation d'images médicales appelé Medical SAM 2. Le modèle est conçu sur la base du cadre SAM 2 et traite les images médicales comme des vidéos. Il fonctionne non seulement bien dans les tâches de segmentation d'images médicales 3D, mais débloque également une nouvelle capacité de segmentation à invite unique. Cet article est une interprétation détaillée et un partage du document de recherche.
Voir le rapport complet :https://go.hyper.ai/04VFX
Dans le deuxième épisode de la série de diffusion en direct « Meet AI4S », Li Yuzhe, chercheur postdoctoral au laboratoire de Zhang Qiangfeng à l'École des sciences de la vie de l'Université Tsinghua, a partagé les derniers résultats de recherche de l'équipe sous le titre « Exploring AI Applications in Genomics: Taking the Spatial Transcriptome Data Characterization Algorithm SPACE as an Example ». Cet article est une transcription de son discours, qui regorge d’informations pratiques.
Voir le rapport complet :https://go.hyper.ai/eRQeT
Lors de l'école d'été sur l'IA pour la bio-ingénierie, le professeur Hong Liang de l'Université Jiao Tong de Shanghai a partagé de manière facile à comprendre l'application de l'IA dans la recherche scientifique, en particulier dans la conception de protéines, avec le thème « L'IA entre dans la vie et la science », ainsi que ses perspectives sur le développement futur de l'IA pour la science. Cet article est une transcription des points saillants du discours du professeur Hong Liang.
Voir le rapport complet :https://go.hyper.ai/TWBIk
Articles populaires de l'encyclopédie
1. DALL-E
2. Intersection sur l'Union (IoU)
3. Modélisation du langage masqué (MLM)
4. Champ de rayonnement neuronal (NeRF)
5. Fusion de tri réciproque RRF
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
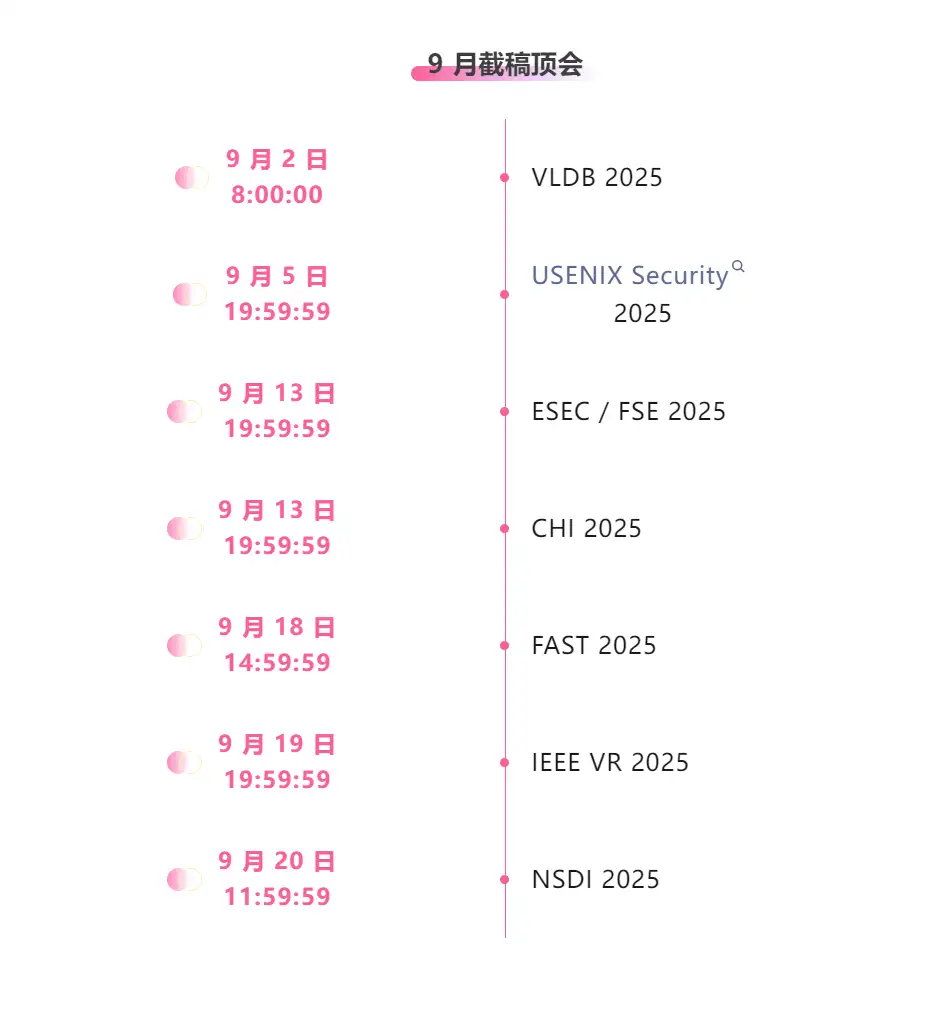
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 300 ensembles de données publiques
* Comprend plus de 400 tutoriels en ligne classiques et populaires
* Interprétation de plus de 100 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








