Command Palette
Search for a command to run...
Tutoriel En Ligne : Déploiement De Grands Modèles Sans Pression ! Fonctionnement En Un Clic Du Llama 3.1 405B Et Du Mistral Large 2

Le 23 juillet, heure locale, Meta a officiellement publié Llama 3.1. La version surdimensionnée du paramètre 405B a fortement ouvert le moment fort du modèle open source. Dans de nombreux tests de référence, ses performances ont rattrapé, voire dépassé, les modèles SOTA existants GPT-4o et Claude 3.5 Sonnet.
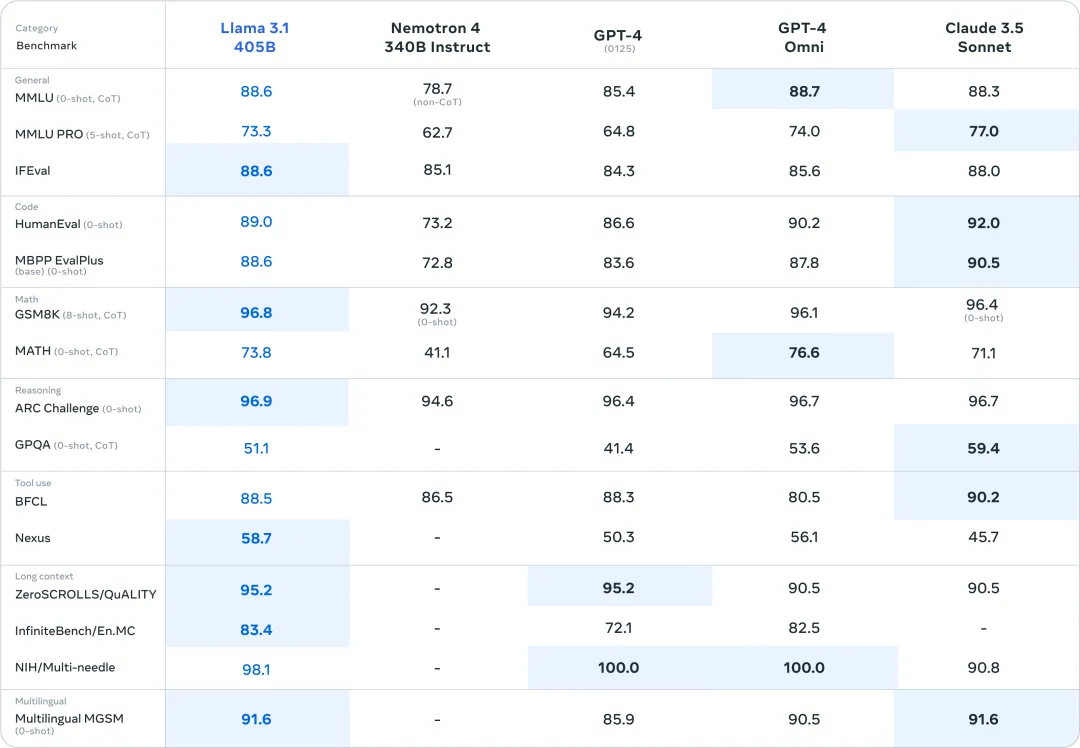
Le jour de la sortie de Llama 3.1, Zuckerberg a également écrit un long article intitulé « L'IA open source est la voie à suivre », affirmant que Llama 3.1 sera un tournant pour l'industrie. Dans le même temps, l’industrie est impatiente de tester les puissantes capacités démontrées par Llama 3.1, et d’autre part, elle attend également avec impatience la réaction des grands modèles à source fermée.
Il est intéressant de noter que, alors que Llama 3.1 se battait pour le trône, Mistral AI a lancé Mistral Large 2 pour défier directement la faiblesse du modèle 405B : la difficulté de déploiement.
Il ne fait aucun doute que les capacités matérielles requises par l'échelle de paramètres 405B ne constituent pas un seuil qui peut être facilement franchi par les développeurs individuels, et la plupart des passionnés ne peuvent que regarder avec hésitation. Le modèle Mistral Large 2 ne possède que 123B de paramètres, soit moins d'un tiers des 405B du Llama 3.1, et le seuil de déploiement est également abaissé, mais les performances peuvent rivaliser avec celles du Llama 3.1.
Par exemple, dans le test de référence de langages de programmation multiples MultiPL-E, le score moyen de Mistral Large 2 a dépassé Llama 3.1 405B et était 1% derrière GPT-4o. Il a dépassé Llama 3.1 405B en Python, C++, Java, etc. Comme le dit sa déclaration officielle, Mistral Large 2 ouvre de nouvelles frontières en termes de performance/coût de service des mesures d'évaluation.
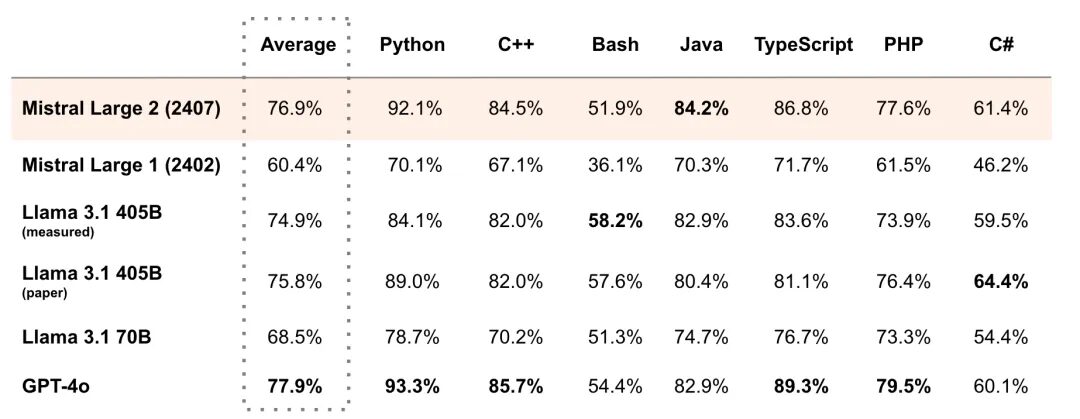
D'un côté se trouve le « plafond » actuel de l'échelle des paramètres du modèle open source, et de l'autre côté se trouve le leader de la nouvelle ère de l'open source avec une « rentabilité » extrêmement élevée. Je crois que tout le monde ne veut pas le manquer ! Ne vous inquiétez pas, HyperAI a lancé un tutoriel de déploiement en un clic pour Llama 3.1 405B et Mistral Large 2407. Vous n'avez pas besoin de saisir de commande, cliquez simplement sur « Cloner » pour en faire l'expérience.
* Utilisez Open WebUI pour déployer le modèle Llama 3.1 405B en un clic :
* Utilisez Open WebUI pour déployer Mistral Large 2407 123B en un clic :
Parallèlement, nous avons également préparé des tutoriels avancés, que vous pouvez choisir selon vos besoins :
* Déploiement en un clic du service API compatible OpenAI du modèle Llama 3.1 405B :
* Déploiement en un clic du service API compatible OpenAI du modèle Mistral Large 2407 123B :
J'ai utilisé Open WebUI pour déployer Mistral Large 2407 123B en un clic et effectué un test. Les grands modèles ne parvenaient souvent pas à répondre au problème « 9,9 ou 9,11 qui est le plus grand », et le Mistral Large 2 n'était pas à l'abri de ce problème :

Amis intéressés, venez l'expérimenter, le tutoriel détaillé est le suivant⬇️
Essai de démonstration
Ce didacticiel textuel prendra « Utiliser Open WebUI pour déployer Mistral Large 2407 123B en un clic » et « Déployer le service API compatible OpenAI du modèle Llama 3.1 405B en un clic » comme exemples pour décomposer les étapes de l'opération pour vous.
Utilisez Open WebUI pour déployer Mistral Large 2407 123B en un clic
1. Connectez-vous à hyper.ai, sur la page Tutoriel, sélectionnez Déployer Mistral Large 2407 123B avec Open WebUI, puis cliquez sur Exécuter ce tutoriel en ligne.
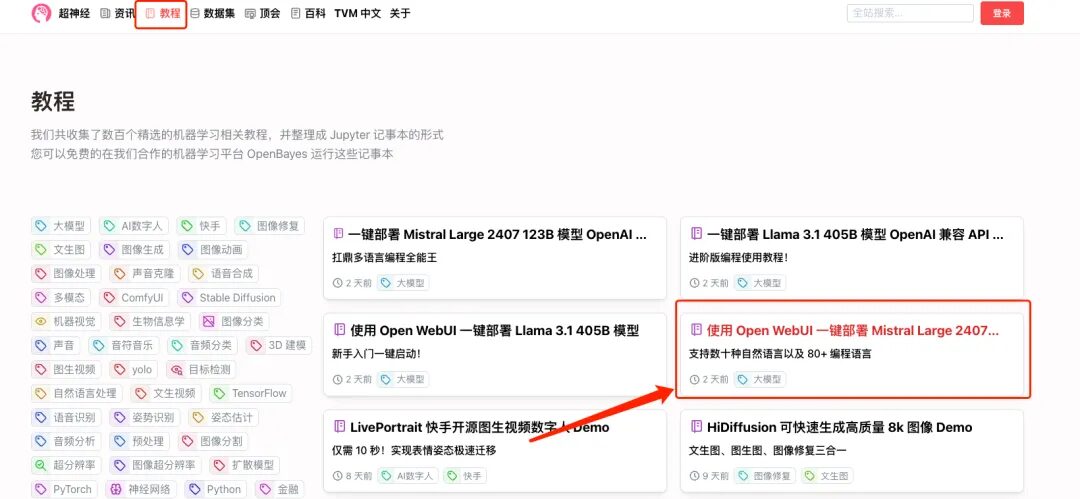
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
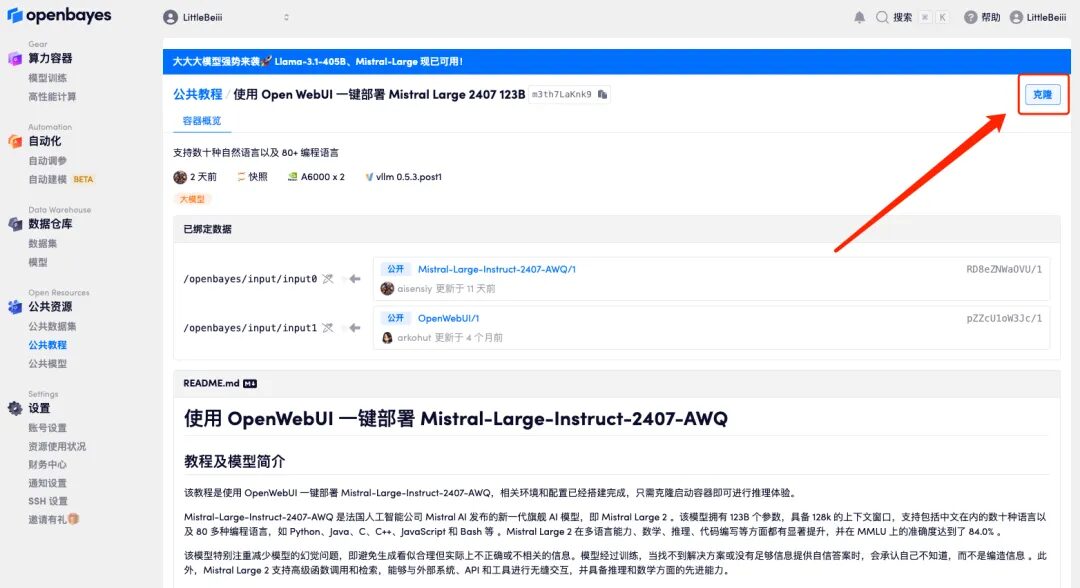
3. Cliquez sur « Suivant : sélectionner le taux de hachage » dans le coin inférieur droit.
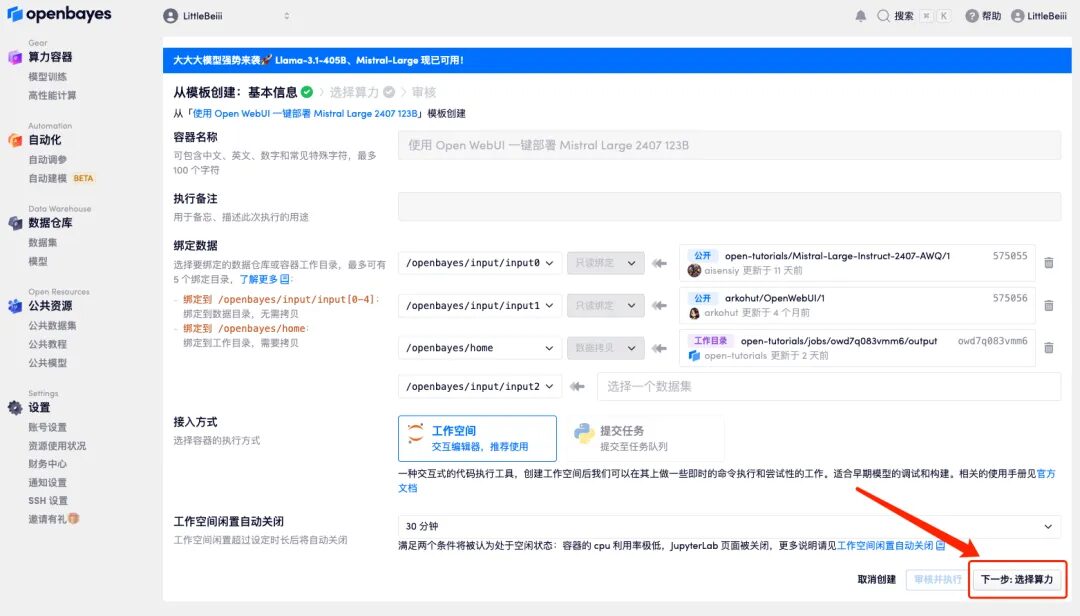
4. Une fois la page affichée, sélectionnez « NVIDIA RTX A6000-2 » et l'image « vllm », puis cliquez sur « Suivant : Réviser ».Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
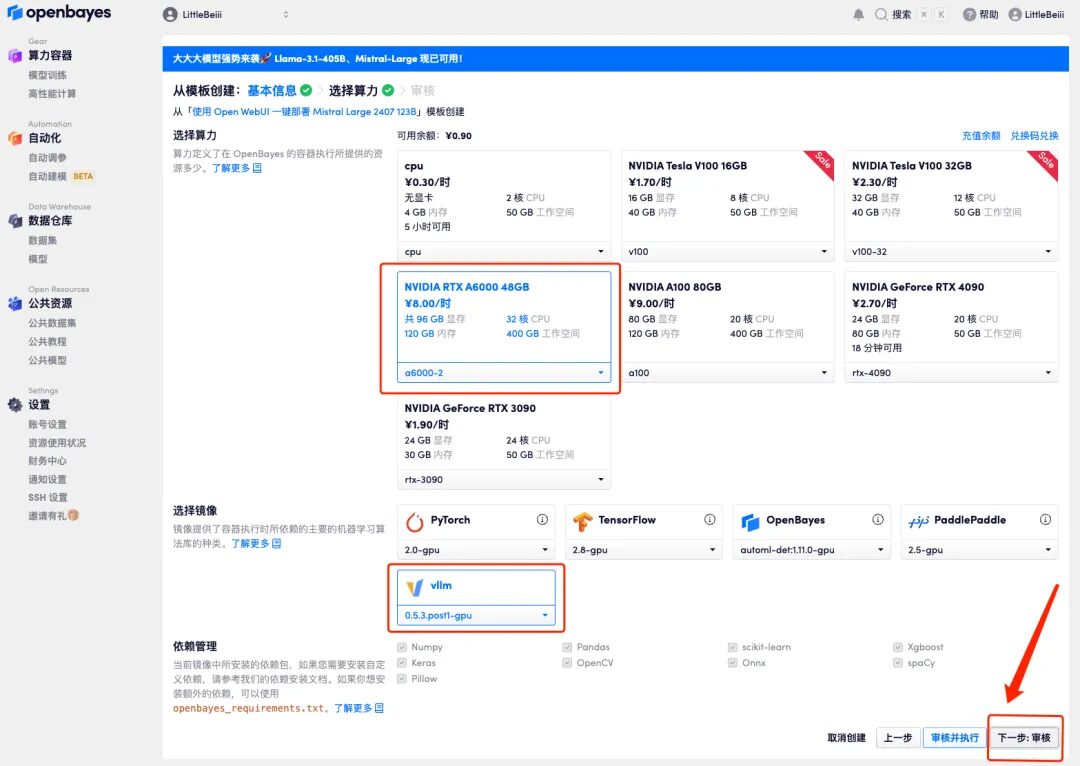
5. Après confirmation, cliquez sur « Continuer » et attendez que les ressources soient allouées. Le premier processus de clonage prendra environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration.Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
Si le problème persiste pendant plus de 10 minutes et que le système est toujours dans l’état « Allocation des ressources », essayez d’arrêter et de redémarrer le conteneur. Si le redémarrage ne résout toujours pas le problème, veuillez contacter le service client de la plateforme sur le site officiel.
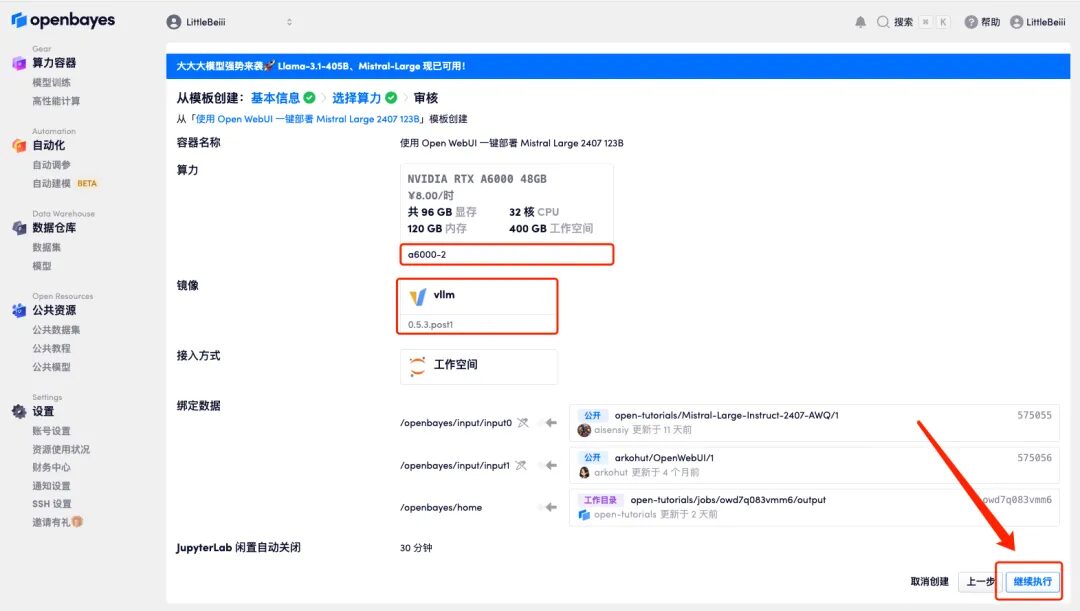
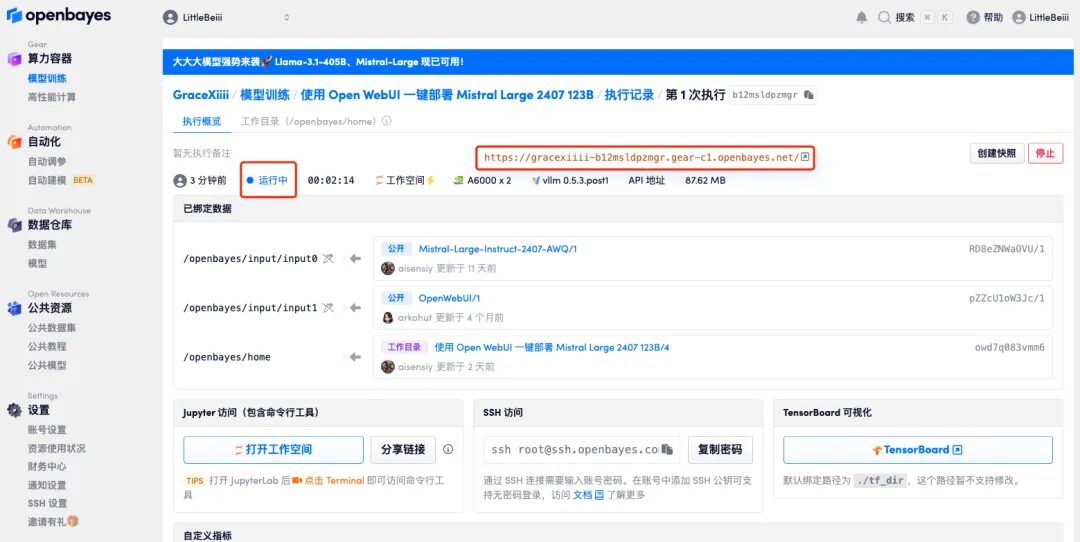
6. Après avoir ouvert la démo, vous pouvez démarrer la conversation immédiatement.
Déploiement en un clic du service API compatible OpenAI du modèle Llama 3.1 405B
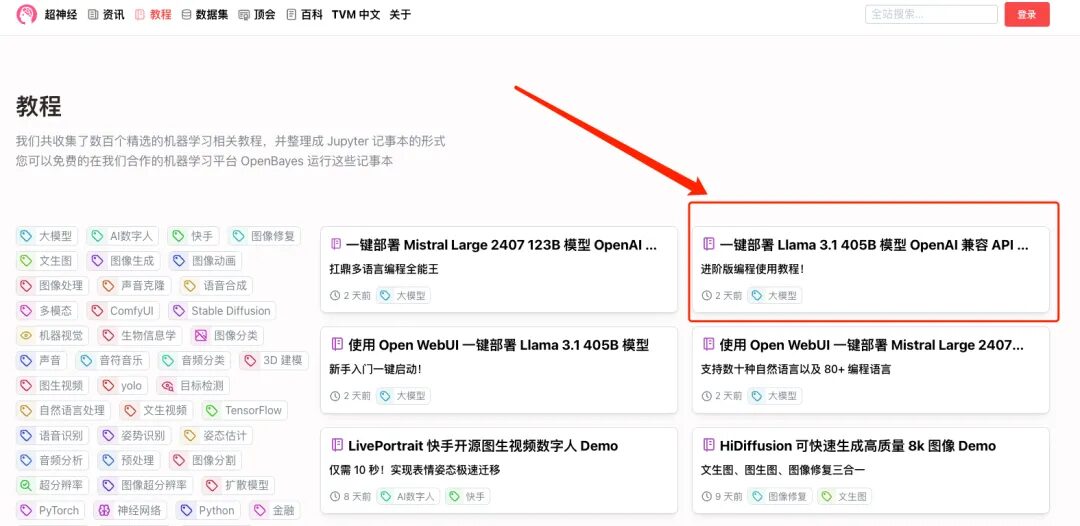
1. Si vous souhaitez déployer un service API compatible OpenAI, sélectionnez « Déploiement en un clic du service API compatible OpenAI du modèle Llama 3.1 405B » sur l'interface du didacticiel. De même, cliquez sur « Exécuter le didacticiel en ligne »
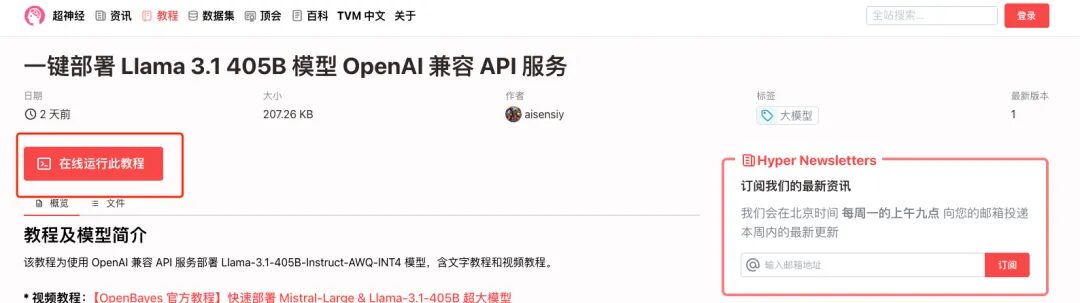
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
3. Cliquez sur « Suivant : sélectionner le taux de hachage » dans le coin inférieur droit.
4. Après le saut de page, étant donné que le modèle est volumineux, la ressource informatique doit sélectionner « NVIDIA RTX A6000-8 », et l'image sélectionne toujours « vllm ». Cliquez sur « Suivant : Réviser ».
5. Après confirmation, cliquez sur « Continuer » et attendez que les ressources soient allouées. Le premier clonage prend environ 6 minutes. Une fois que le statut est affiché comme « En cours d'exécution », le modèle commencera automatiquement à se charger.
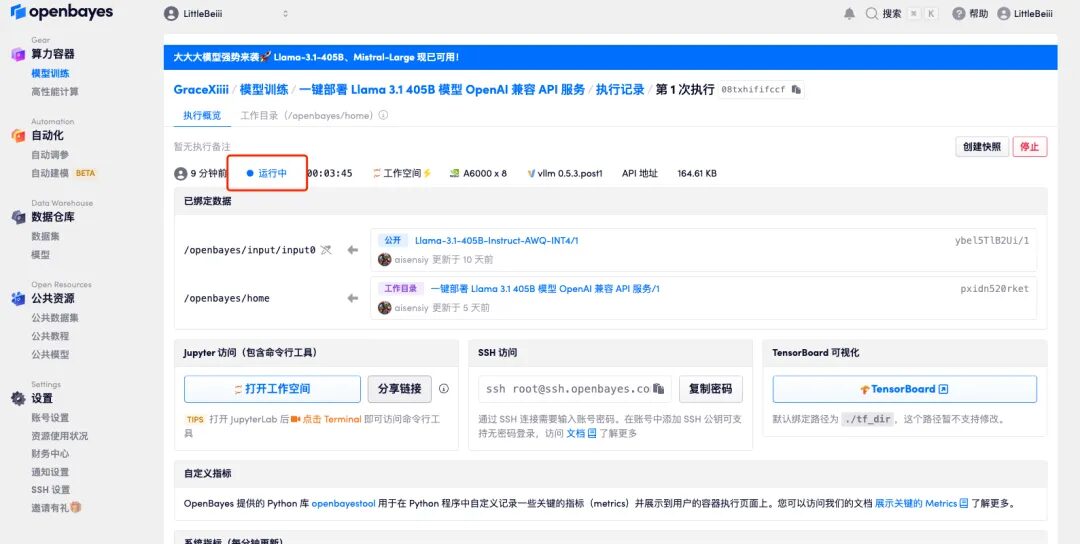
6. Faites défiler la page jusqu'en bas. Lorsque le journal affiche les informations de routage suivantes, cela signifie que le service a démarré avec succès. Ouvrez l'adresse API.
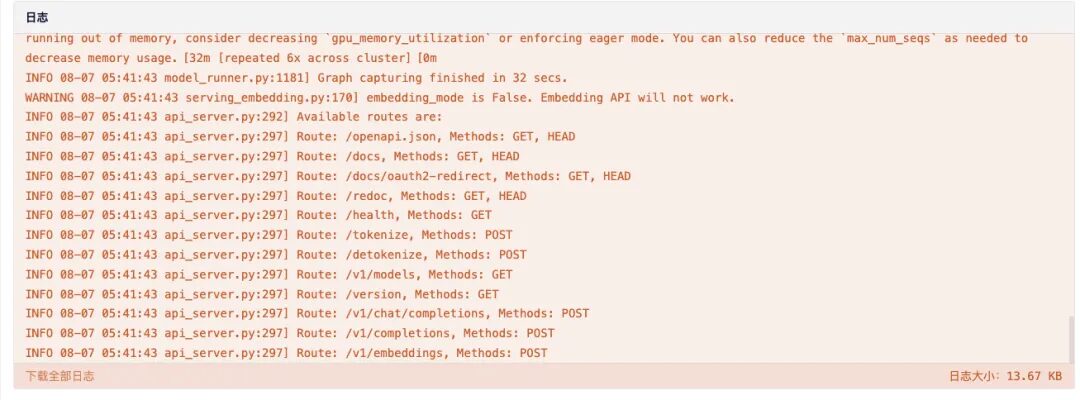
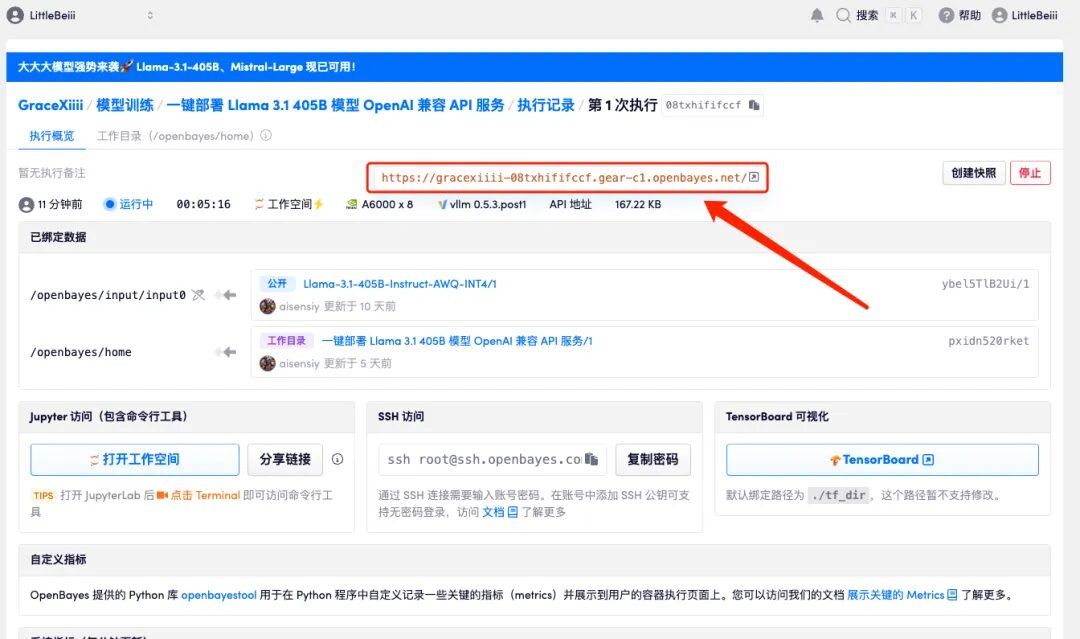
7. Après l'ouverture, les informations 404 seront affichées par défaut. L'ajout d'un paramètre supplémentaire « /v1/models » dans la case rouge affichera les informations de déploiement du modèle actuel.




8. Démarrez un service Open WebUI localement, démarrez une connexion supplémentaire dans « Connexion externe », renseignez l'adresse API précédente dans « OpenAPI » et ajoutez « /v1 ». Il n'y a pas de « clé API » définie ici, saisissez-la simplement vous-même. Cliquez sur Enregistrer dans le coin inférieur droit.
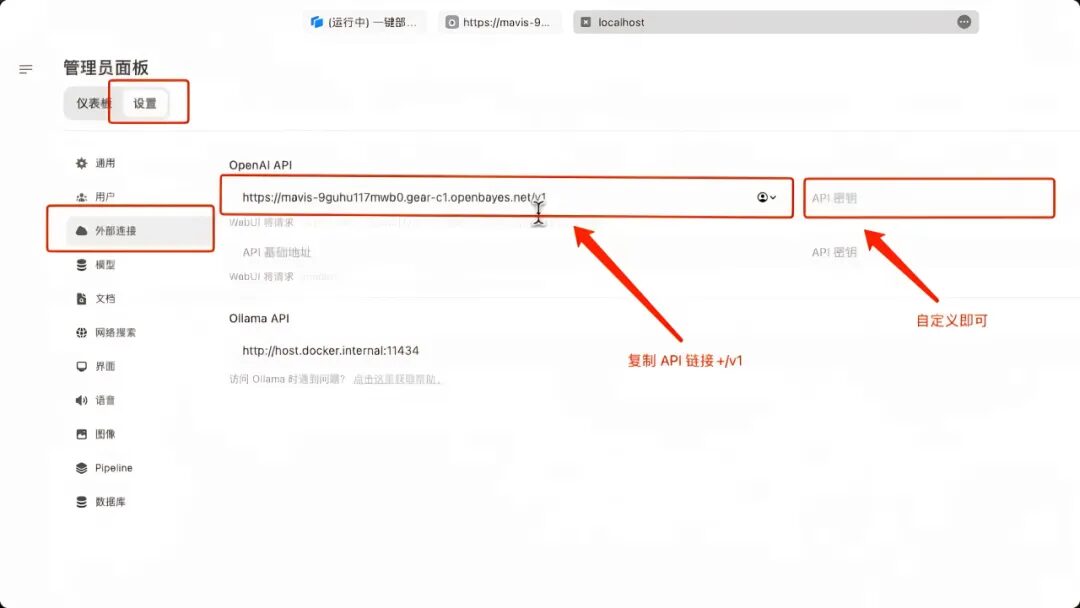
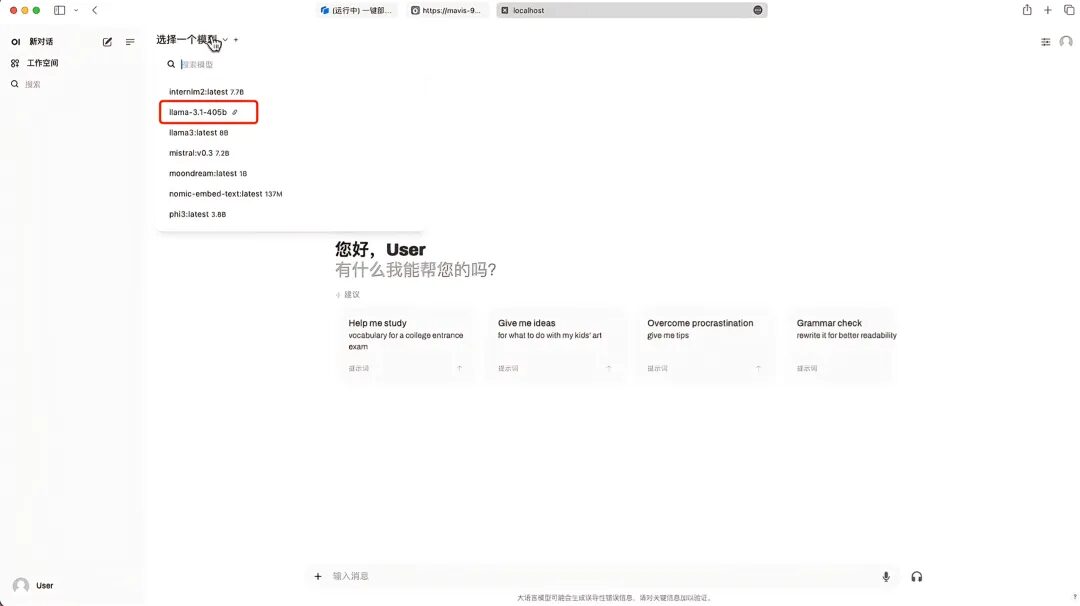
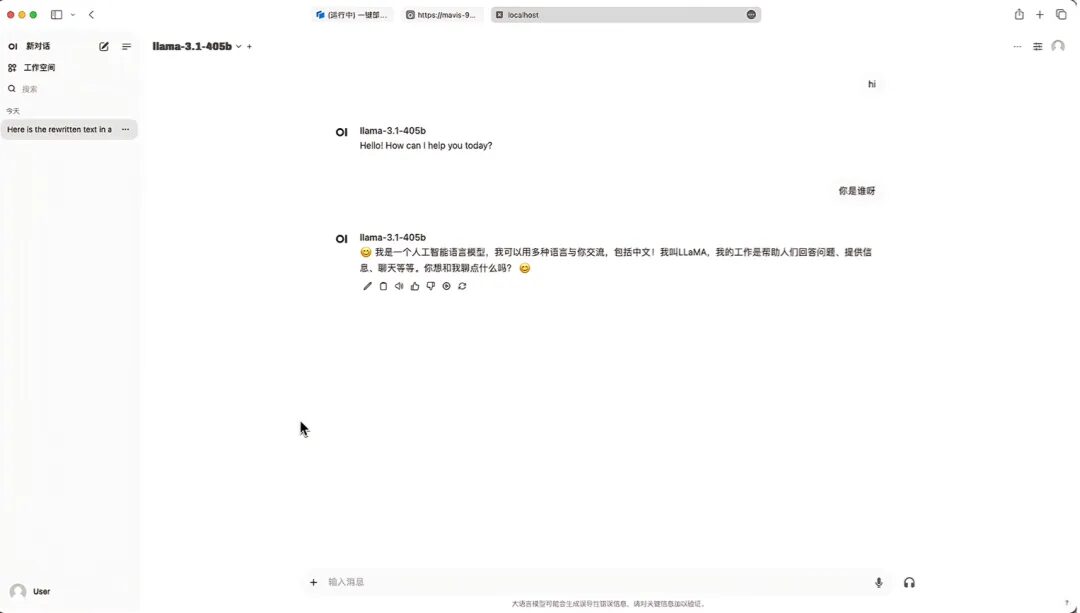
9. Après avoir enregistré, vous pouvez voir Llama-3.1-405B apparaître dans « Sélectionner le modèle ». Après avoir sélectionné le modèle, vous pouvez démarrer la conversation !
Enfin, je recommande une activité de partage académique en ligne. Les amis intéressés peuvent scanner le code QR pour participer !









