Command Palette
Search for a command to run...
Sélectionné Pour l'ACL 2024 ! En Présentant l'apprentissage Zéro Coup, l'Université Des Sciences Et Technologies De Huazhong Publie Un Modèle De Diffusion Conditionnelle Optimisé Pour Le Déchiffrement Des Inscriptions Sur Os d'oracle

L’écriture est un symbole de civilisation et la marque la plus distinctive d’une nation. L'écriture osseuse oraculaire (OBS), en tant qu'écriture la plus ancienne et systématique connue dans mon pays, porte la culture et la civilisation de la nation chinoise. Depuis 1899, lorsqu'un érudit a découvert par hasard une carapace de tortue portant des inscriptions sur des os d'oracle dans une boutique de médecine chinoise, l'étude des inscriptions sur des os d'oracle est devenue un sujet brûlant dans la communauté universitaire.
Dans toutes les études sur les os d’oracle, l’identification et l’interprétation sont les questions les plus fondamentales. Cependant, parmi les plus de 4 500 caractères d'os d'oracle découverts jusqu'à présent, il reste encore environ 3 000 caractères qui n'ont pas été reconnus, et la recherche sur les os d'oracle est entrée dans une période de goulot d'étranglement difficile à franchir.
Avec l’essor de la technologie de l’IA, l’utilisation de la technologie moderne pour comprendre cette langue ancienne offre aux chercheurs une nouvelle façon d’explorer. Cependant, les méthodes de recherche antérieures étaient principalement basées sur la connaissance et la compréhension des os d’oracle déchiffrés.Comment utiliser l’IA pour aider à déchiffrer des mots inconnus présentant de multiples problèmes tels que du texte non numérique, des échantillons gravement endommagés, un corpus manquant, etc.C’est encore un nouveau domaine à explorer.
En réponse à cela, l'équipe de recherche de Bai Xiang et Liu Yuliang de l'Université des sciences et technologies de Huazhong, en collaboration avec l'Université d'Adélaïde, l'Université normale d'Anyang et l'Université de technologie de Chine du Sud, a utilisé un modèle génératif basé sur l'image pourUn modèle de diffusion conditionnelle Oracle Bone Script Decipher (OBSD) optimisé pour le déchiffrement de scripts Oracle Bone a été formé.Le modèle utilise des catégories invisibles d'inscriptions sur os d'oracle comme entrée conditionnelle pour générer des images de caractères chinois modernes correspondantes, offrant une nouvelle approche de la tâche de reconnaissance de caractères anciens qui est difficile à résoudre dans le traitement du langage naturel.
La recherche connexe, intitulée « Déchiffrer le langage Oracle Bone avec des modèles de diffusion », a été acceptée par la conférence principale ACL 2024.
Points saillants de la recherche :
* Fournir une nouvelle approche aux tâches de reconnaissance de textes anciens en utilisant la technologie de génération d'images
* OBSD utilise une technologie d'échantillonnage d'analyse locale pour améliorer la capacité du modèle à distinguer et à interpréter des modèles de caractères complexes
* Démontrer l'efficacité de l'OSBD dans le décodage grâce à des études d'ablation complètes et des tests de référence

Adresse du document :
https://doi.org/10.48550/arXiv.2406.00684
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Ensemble de données : Utilisation du plus grand référentiel d'Oracle, en utilisant la technologie OCR comme référence
Pour former et évaluer le modèle OSBD proposé,Cette étude a sélectionné l’ensemble de données HUST-OBS et l’ensemble de données EVOBC.Il s'agit de l'un des plus grands dépôts d'inscriptions sur os d'oracle, contenant 1 590 caractères différents représentés dans 71 698 images.
Considérant que le déchiffrement d’os d’oracle inconnus nécessite généralement une vérification professionnelle plus complète, cette étude n’a utilisé que les textes déchiffrés comme ensemble de test, simplifiant ainsi l’ensemble du processus d’évaluation. Plus important encore, l’étude a également spécifiquement exclu les catégories de caractères sélectionnées dans l’ensemble de test de l’ensemble d’entraînement pour garantir que le modèle était utilisé pour déchiffrer des caractères qui n’avaient jamais été traités. L'ensemble de données est divisé en ensembles d'entraînement et de test dans un rapport de 9:1, fournissant un cadre fiable pour l'évaluation.
De plus, bien que le modèle OSBD effectue un déchiffrement d'oracle du point de vue de la génération d'images, les mesures de génération d'images traditionnelles telles que SSIM ne conviennent pas à cette tâche. Par conséquent, cette étude a adopté la technologie OCR comme mesure plus objective pour déterminer les résultats de décryptage réussis. Plus précisément, les chercheurs ont personnalisé l'outil OBS-OCR en utilisant un classificateur simple avec un réseau dorsal ResNet-101, formé spécifiquement sur un grand ensemble de données contenant 88 899 catégories de caractères chinois modernes pour évaluer la sortie du modèle.
Les résultats montrent que L'outil OCR personnalisé a atteint une précision de reconnaissance de 99,87%.La fiabilité des résultats du déchiffrement a été prouvée. Dans le même temps, cette étude a également largement présenté l’outil OCR chinois open source PaddleOCR 1 pour une évaluation plus approfondie. Cette méthode OCR double offre une garantie solide quant à l’efficacité du modèle dans le déchiffrement des os d’oracle.
Reconstruire le modèle OBSD basé sur le modèle de diffusion conditionnelle
Cette étude représente l’ensemble d’entraînement comme S = {(si, ci) | si est une instance d'oracle, ci∈C}, c'est-à-dire faisant correspondre les instances d'oracle avec un ensemble de caractères chinois modernes dans une catégorie C connue et proposant de nouvelles formes de caractères lorsque les correspondances existantes sont manquantes. Pour y parvenir,Cette étude convertit l’image du caractère osseux d’oracle X en son équivalent chinois moderne basé sur le modèle de diffusion.
Comme le montre la figure ci-dessous, le modèle est divisé en deux étapes :
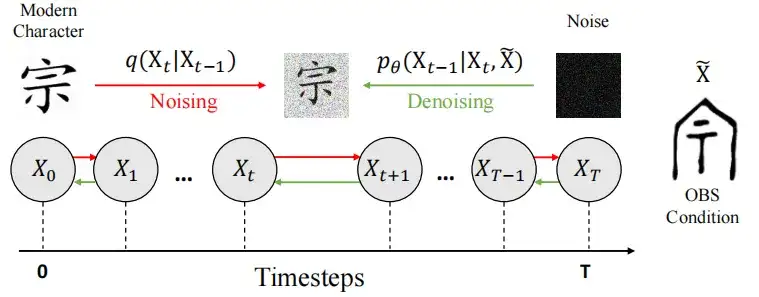
Au stade précoce (Bruit),Les chercheurs ont introduit du bruit dans l'image de caractère chinois moderne X0 et ont utilisé un processus de chaîne de Markov contrôlable pour la faire passer à un état similaire au bruit pur, formant finalement une distribution gaussienne N (0, I).
Dans la phase de débruitage,Les chercheurs ont utilisé l'architecture U-Net pour entraîner le modèle fθ à prédire le bruit e et à restaurer l'image, et ont utilisé et ∼ N(0, I) pour introduire du caractère aléatoire afin d'améliorer la diversité des résultats de génération du modèle. Le résultat final du décodage est l'image débruitée générée X0.
Sur cette base, le modèle OBSD intègre l'étape de déchiffrement initial et l'étape de raffinement à zéro coup pour améliorer la précision du déchiffrement, comme le montre la figure ci-dessous.
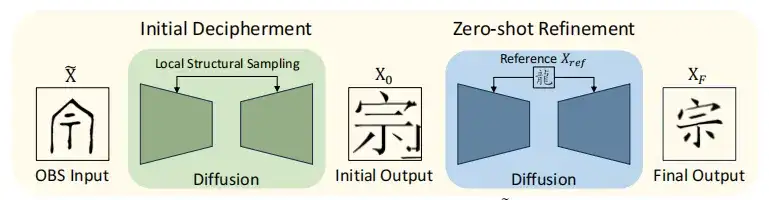
Tout d'abord, l'image oracle X est diffusée conditionnellement pour se rapprocher de l'image initiale X0, qui est ensuite améliorée par une méthode d'apprentissage à zéro coup, et Xref est utilisé comme référence pour corriger et améliorer la structure. Bénéficiant d'un aperçu de la structure du texte au cours du processus d'amélioration, le résultat du texte XF a finalement été généré, correspondant aux caractères chinois modernes.
Présentation du concept LSS pour améliorer la capacité du modèle à connecter les caractères anciens aux caractères chinois modernes
Cependant, dans les cas d'application réels, le modèle formé de cette manière ne peut pas générer avec précision les caractères chinois modernes correspondants, mais forme plutôt des absurdités basées sur un grand nombre de fragments aléatoires, comme le montre la figure ci-dessous.

Les chercheurs supposent que la raison de ce résultat est que le modèle de diffusion est principalement conçu pour générer des images naturelles, mais dans le processus de déchiffrement des inscriptions sur os d'oracle, il existe de grandes différences dans la structure entre les inscriptions sur os d'oracle et les caractères chinois modernes.Cela rend impossible pour le modèle de diffusion conditionnelle standard de reconstruire avec précision les caractères chinois modernes cibles.
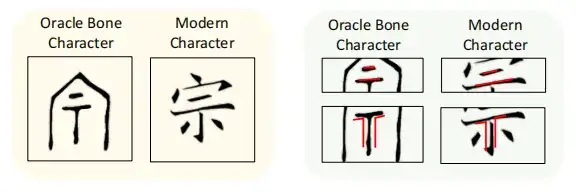
Pour relever ce défi,Cette étude a introduit le concept d’échantillonnage de structure locale (LSS).Aidez le modèle de diffusion à apprendre comment mapper la structure radicale locale des inscriptions sur os d'oracle aux caractères chinois modernes correspondants, améliorant ainsi la capacité du modèle à connecter les caractères anciens aux caractères chinois modernes. L’étude a également révélé que, bien qu’il y ait eu une évolution structurelle considérable des caractères chinois anciens aux caractères chinois modernes, certaines structures locales ont été préservées.
Afin de permettre au modèle de diffusion d'apprendre les caractéristiques de la structure locale, le module LSS utilise une méthode de fenêtre glissante pour diviser l'image cible du caractère chinois moderne X0∈RHxWx3 et l'image d'os d'oracle correspondante X∈RHxWx3 en D petits blocs de taille p×p, notés X(d) et Xt(D)∈Rp×p×3, D=1,2…D, p=64. Ici, Xt représente une image de texte moderne avec du bruit gaussien ϵt ajouté au pas de temps t.
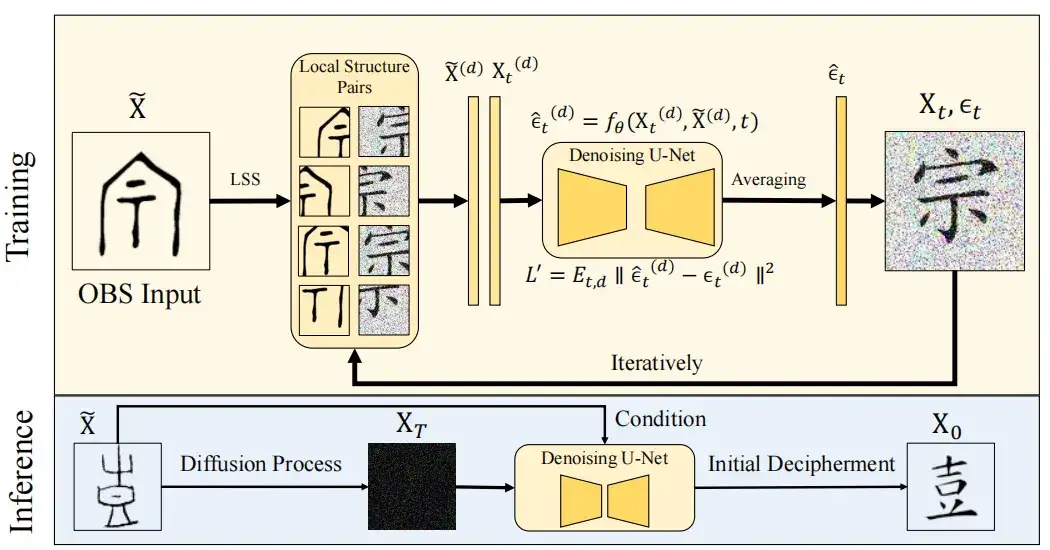
Sur la base de cette méthode,Le modèle peut itérer et optimiser les correctifs en apprenant la structure locale des inscriptions sur les os d'oracle et les différences subtiles dans la structure des caractères chinois.La particularité de notre méthode est qu'elle fait la moyenne des chevauchements entre les régions voisines à chaque pas de temps t sans terminer le débruitage pour garantir un effet uniforme sur les régions partagées. Dans le même temps, cette étude a évité les différences de bords et a maintenu la cohérence visuelle de l’image reconstruite en lissant les transitions régionales dans le processus d’échantillonnage.
Présentation de méthodes d'apprentissage sans intervention pour améliorer la capacité du modèle à comprendre la structure des personnages
Bien que certains progrès aient été réalisés dans la génération de caractères chinois modernes à l’aide d’un échantillonnage de structure locale, les efforts de déchiffrement initiaux rencontrent encore des obstacles évidents tels que la déformation structurelle et les artefacts.

Cela est dû à la méthode de formation plusieurs-à-un utilisée, qui mappe plusieurs inscriptions d'os d'oracle à une image de caractère chinois moderne.Cela conduit à une confusion et à des inexactitudes dans la capture de l’évolution des personnages.Et en raison des échantillons limités de caractères chinois modernes, une structure incomplète apparaît.
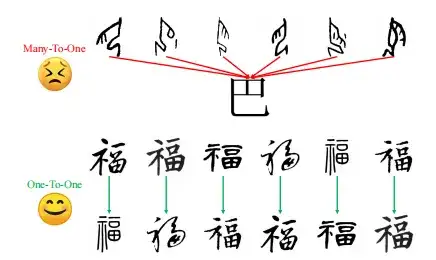
Pour surmonter ces défis,Cette étude a proposé une stratégie d’apprentissage à zéro coup pour améliorer la compréhension de la structure du modèle en utilisant différents styles d’écriture de caractères chinois modernes.En pratique, l'étude a entraîné le module de manière individuelle sur 20 polices chinoises modernes différentes, apprenant ainsi les transformations structurelles entre différents styles d'écriture chinois modernes et améliorant la capacité du modèle à comprendre la structure des caractères.
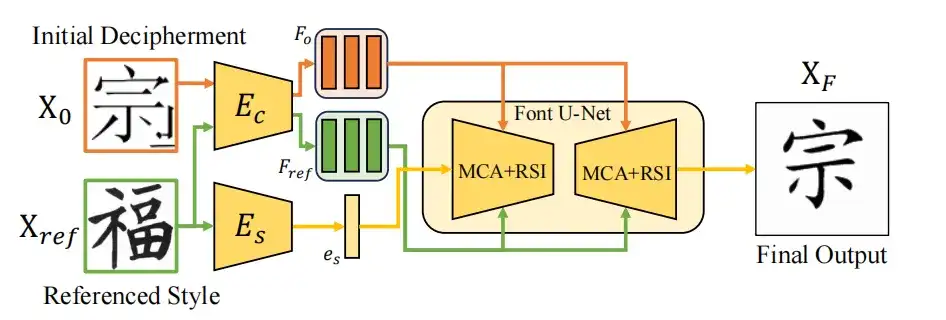
Comme le montre la figure ci-dessous, cette méthode d’apprentissage zéro coup est basée sur un cadre de transfert de style de police universel. Grâce à un système d'encodeur double, le style de l'image de police source X0 est adapté au style cible Xref tout en conservant l'intégrité du contenu. L'encodeur de style Es extrait la fonctionnalité de style es de Xref, tandis que l'encodeur de contenu Ec traite Xo et Xref pour obtenir la fonctionnalité de contenu multi-échelle Fo, qui est affinée par Font U-Net avec l'agrégation de contenu multi-échelle (MCA) et la structure de référence. Une fois la formation terminée, le module d'apprentissage zéro-shot peut être utilisé directement pour optimiser les résultats générés par le modèle de diffusion.
Évaluation des performances de l'OSBD : le taux de précision de la reconnaissance est le plus élevé selon plusieurs critères d'évaluation
Afin d’évaluer quantitativement les performances de l’OSBD, cette étude a utilisé deux critères d’évaluation différents : le décryptage à un seul tour et le décryptage à plusieurs tours. Comme il n’existe pas d’outils dédiés au déchiffrement des os d’oracle, cette étude adopte un cadre comparatif pour adapter les principales méthodes de traduction d’image à image à cette tâche.
Plus précisément, ces méthodes incluent des méthodes basées sur GAN telles que Pix2Pix, CycleGAN, DRIT++ et des modèles de diffusion tels que CDE, Palette et BBDM. Ce paramètre garantit que la méthode OBSD peut être évaluée dans le contexte d'une traduction d'images de pointe et garantit une cohérence équitable dans les conditions de formation et de test.
Au cours d'un seul cycle d'évaluation de décryptage,L'OBSD présente des avantages significatifs par rapport aux méthodes de conversion d'image en image modifiées pour déchiffrer les os d'oracle.Comme le montre la figure ci-dessous.
La précision maximale obtenue par OSBD via OBS-OCR et PaddleOCR est respectivement de 41,0% et 30,0%, ce qui est plus performant que les autres méthodes. À mesure que le classement augmente, la précision montre une nette tendance à l’amélioration. En dessous de la précision top-500, OSBD atteint une précision de reconnaissance OBS-OCR de 64,5%.
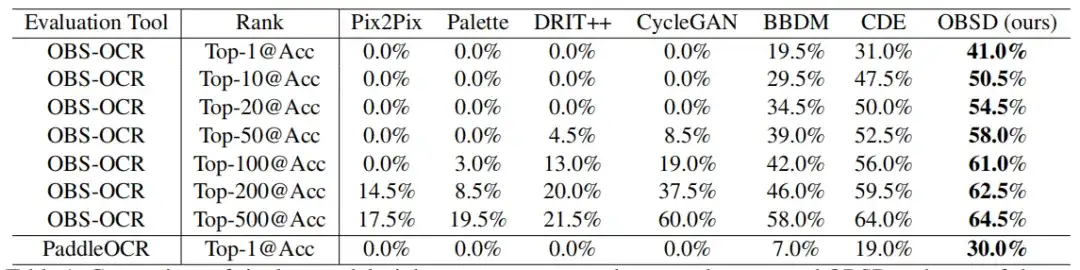
Il convient de noter que toutes les méthodes basées sur GAN (telles que Pix2Pix, Palette, DRIT++ et CycleGAN) présentent la pire efficacité dans ce cas, avec une précision top-1 de 0,%. Cela peut être dû à la difficulté du GAN lui-même à capturer les relations de cartographie complexes et subtiles nécessaires pour déchiffrer les os d'oracle.
Au cours de plusieurs cycles d’évaluation de décryptage,Le taux de réussite de l’OBS-OCR s’est progressivement amélioré au fil de plusieurs tentatives.L'indicateur s'est continuellement amélioré, passant d'un taux de réussite de 41,0% à 80,0%, comme le montre la figure ci-dessous.
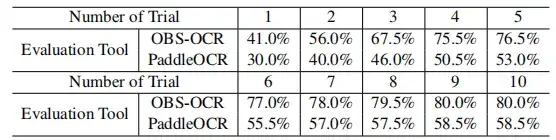
La tendance de croissance de l'indicateur PaddleOCR a également montré une tendance à la hausse, commençant à 30,0% et atteignant finalement 58,5%. Ces résultats confirment tous que des améliorations progressives peuvent être obtenues grâce à des tentatives successives.
Pour examiner plus en détail l’impact de chaque composant, cette étude a également mené une étude d’ablation, en se concentrant sur le module LSS et l’apprentissage zéro coup. Les résultats montrent que le décodage des inscriptions sur os d'oracle en utilisant uniquement le modèle de diffusion conditionnelle de base présente des limites et une précision nettement inférieure. Plus précisément, l’entraînement d’un modèle de diffusion sans aucune augmentation produit des résultats qui sont essentiellement dénués de sens.
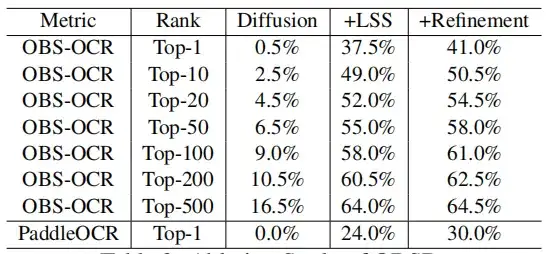
En introduisant le module LSS,La précision de reconnaissance d'OBS-OCR a été améliorée à 37,5%.PaddleOCR a été amélioré à 24%. En utilisant le module d'apprentissage zéro tir avec LSS, la précision Top-1 d'OBS-OCR et de PaddleOCR peut être encore améliorée de 3,5% et 6% supplémentaires, respectivement.
Enfin, cette étude mène également une étude qualitative sur différents modèles de traduction d’image en image.
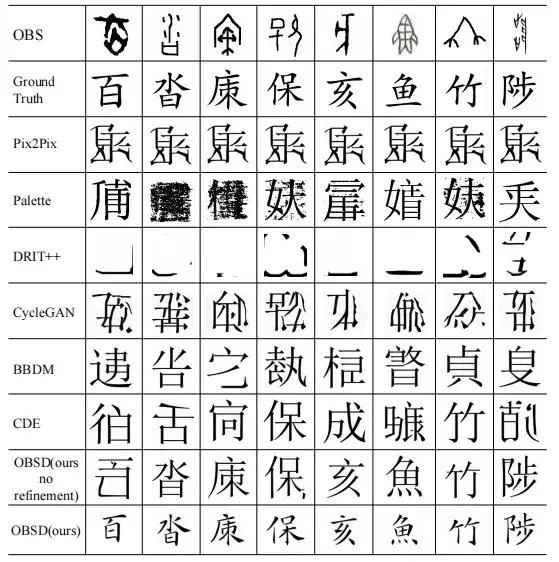
Les résultats montrent que les inscriptions sur os d'oracle saisies via la méthode OBSD peuvent produire le déchiffrement de caractères chinois modernes le plus précis et peuvent discerner les détails complexes des inscriptions sur os d'oracle. Ces résultats soulignent non seulement l’efficacité de l’OSBD, mais également son potentiel en tant qu’outil expert pour le déchiffrement du langage oracle.
Lorsque les inscriptions sur os d'oracle rencontrent l'intelligence artificielle, l'ancien système d'écriture retrouve enfin un nouveau souffle
Dans le domaine de la recherche sur les caractères chinois anciens, en particulier la recherche sur l'écriture osseuse oraculaire, l'Université des sciences et technologies de Huazhong a toujours été à l'avant-garde de son époque. C'est l'une des premières universités en Chine à avoir créé une base de données indépendante de scripts Oracle Bone. Avec le développement rapide de la technologie de l’intelligence artificielle, le traitement intelligent du texte et des images est devenu l’un des points chauds dans le domaine de la recherche en intelligence artificielle. L'Université des sciences et technologies de Huazhong, représentée par l'équipe de recherche de Bai Xiang et Liu Yuliang, est une fois de plus devenue le pionnier et le leader de l'intelligence du texte et de l'image.
Le professeur Bai Xiang est un jeune scientifique exceptionnel au niveau national et membre de l'IAPR. Il est actuellement doyen de l'École de logiciels de l'Université des sciences et technologies de Huazhong et directeur du Centre de recherche en ingénierie du Hubei pour la vision industrielle et les systèmes intelligents. Précédemment,Singe, développé par le professeur Bai Xiang Le grand modèle multimodal a remporté la première place dans la version open source OpenCompass de la liste des grands modèles faisant autorité.Les résultats ont été appliqués aux produits innovants des principales sociétés de logiciels de Wuhan.
En tant que membre principal de l'équipe de Bai Xiang, Liu Yuliang a été sélectionné pour le 9e projet de soutien aux jeunes talents de l'Association chinoise pour la science et la technologie. Il s'est concentré sur l'intelligence du texte et de l'image et a obtenu une série de résultats de travail dans l'analyse intelligente des documents, la vision et la compréhension du langage naturel et les grands modèles multimodaux.
À mesure que la technologie se développe et mûrit, afin de réaliser de plus grandes avancées dans la recherche sur les os d'oracle, Bai Xiang et le professeur Liu Yuliang ont résolument choisi de mener une coopération approfondie avec l'Université normale d'Anyang, l'une des principales institutions de recherche sur les os d'oracle en Chine. En 2018, la construction du laboratoire clé du ministère de l'Éducation pour le traitement de l'information Oracle à l'Université normale d'Anyang a été approuvée ; En 2019, le « Yinqiwenyuan », une plate-forme de big data Oracle Bone Script soigneusement construite par le laboratoire qui intègre la bibliothèque de documents Oracle Bone Script, la bibliothèque de catalogues et la bibliothèque de caractères, a été ouverte au monde.Il s’agit de la plateforme de données Oracle la plus complète, la plus standardisée et la plus fiable au monde.Son ouverture marque l’entrée de la recherche sur les os d’oracle dans l’ère intelligente.
Il convient de noter que Liu Yongge, l'un des auteurs correspondants de cet article, est le directeur du laboratoire clé de traitement de l'information Oracle du ministère de l'Éducation à l'Université normale d'Anyang.
Afin de mieux enregistrer et diffuser les recherches sur les os d'oracle, le laboratoire s'est concentré sur deux choses majeures en 2023 : d'une part, il a lancé conjointement le « Oracle Bone Global Digital Return Plan » avec Tencent SSV, la station de travail d'Anyang de l'Institut d'archéologie, l'Académie chinoise des sciences sociales et le Bureau municipal des reliques culturelles d'Anyang, en utilisant des caméras avec des centaines de millions de pixels pour réaliser une restauration et une protection haute fidélité des os d'oracle physiques dans l'espace numérique. D'autre part, le mini-programme « Amazing Oracle » lancé conjointement par le laboratoire et Tencent a rapproché Oracle du public.
Par coïncidence, afin de permettre aux chercheurs de trouver plus facilement des informations sur l'épissage des os d'oracle et de raccourcir le temps de collecte des données au début de la recherche,Début 2023, Yang Yi, Huang Bo et Cheng Minghui, doctorants du Centre de recherche sur les documents excavés et les caractères anciens de l'Université Fudan, ont créé conjointement la base de données d'informations sur l'épissage des os d'oracle « Jade et Perle ».Il rassemble plus de 6 700 ensembles de résultats d'épissage d'os oracle provenant de nombreux chercheurs depuis la publication de la « Oracle Bone Collection ». Il est non seulement devenu un outil en ligne pour la communauté universitaire pour rechercher les principaux résultats d'épissage d'os d'oracle, mais permet également à de nombreux passionnés d'os d'oracle en dehors de la « tour d'ivoire » d'avoir la possibilité de participer au travail de résolution des fragments d'os d'oracle et de fournir des corrections et de nouvelles informations sur l'épissage d'os d'oracle.
On peut constater qu’avec l’aide des technologies numériques telles que le big data, le cloud computing et l’intelligence artificielle, la recherche sur les os d’oracle est entrée dans une nouvelle ère. Alors que la recherche continue de s'approfondir, je pense que cette « compétence secrète impopulaire » finira par révéler davantage de codes dans un avenir proche et servira de référence très importante pour déchiffrer d'autres caractères anciens.








