Command Palette
Search for a command to run...
Stanford, Apple Et 23 Autres Institutions Ont Publié Des Benchmarks DCLM. Les Ensembles De Données De Haute Qualité peuvent-ils Bouleverser Les Lois D’échelle ? Le Modèle De Base Fonctionne À Égalité Avec Le Llama3 8B

Alors que les gens continuent de prêter une attention particulière aux modèles d’IA, le débat sur les lois d’échelle devient également de plus en plus vif.
OpenAI a proposé pour la première fois des lois d'échelle dans l'article « Lois d'échelle pour les modèles de langage neuronal » en 2020. Elle est considérée comme la loi de Moore pour les grands modèles de langage. Sa signification peut être brièvement résumée comme suit :À mesure que la taille du modèle, la taille de l'ensemble de données et le nombre de calculs à virgule flottante (utilisés pour la formation) augmentent, les performances du modèle s'améliorent.
Sous l'influence des lois d'échelle, de nombreux adeptes croient encore que « grand » est toujours le premier principe pour améliorer les performances du modèle. Les grandes entreprises, en particulier celles disposant de moyens importants, s’appuient davantage sur des ensembles de données volumineux et diversifiés.
À cet égard, Qin Yujia, titulaire d'un doctorat, Un professeur du département d'informatique de l'université Tsinghua a souligné : « LLaMA 3 nous révèle une réalité pessimiste : l'architecture du modèle n'a pas besoin d'être modifiée, et l'augmentation du volume de données de 2 à 15 T peut produire des miracles. D'un côté, cela nous indique que le modèle de base représente une opportunité pour les grandes entreprises à long terme ; de l'autre, compte tenu de l'effet marginal des lois d'échelle, si nous voulons que la prochaine génération de modèles continue d'être améliorée par rapport à GPT3 et GPT4, nous devrons peut-être éliminer au moins dix ordres de grandeur de données supplémentaires (par exemple, 150 T). »

En réponse à l'augmentation continue de la quantité de données nécessaires à la formation des modèles linguistiques et à des problèmes tels que la qualité des données, 23 institutions, dont l'Université de Washington, l'Université de Stanford et Apple, ont proposé conjointement une plate-forme de test expérimentale DataComp for Language Models (DCLM). Le cœur de cette plateforme est le nouveau vocabulaire candidat 240T de Common Crawl. En corrigeant le code de formation, cela encourage les chercheurs à proposer de nouveaux ensembles de formation pour l'innovation, ce qui est d'une grande importance pour améliorer les ensembles de formation des modèles de langage.
Des recherches connexes ont été publiées sur la plateforme académique sous le titre « DataComp-LM : À la recherche de la prochaine génération d'ensembles d'entraînement pour les modèles de langage » http://arXiv.org supérieur.
Points saillants de la recherche
* Les participants au benchmark DCLM peuvent expérimenter des stratégies de gestion des données sur des modèles allant de 412M à 7B paramètres
* Le filtrage basé sur un modèle est la clé pour créer des ensembles de formation de haute qualité. L'ensemble de données généré DCLM-BASELINE prend en charge la formation d'un modèle de langage à 7 B paramètres à partir de zéro sur MMLU en utilisant 2,6 T de jetons de formation, atteignant une précision de 5 coups de 641 TP3T
* Le modèle de base DCLM fonctionne de manière comparable à Mistral-7B-v0.3 et Llama3 8B sur MMLU

Adresse du document :
https://arxiv.org/pdf/2406.11794v3
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Test de référence DCLM : conception multi-échelle de 400 M à 7 B pour répondre aux différentes exigences d'échelle de calcul
DCLM est une plateforme d'expérimentation d'ensembles de données pour l'amélioration des modèles linguistiques et la première référence pour la gestion des données de formation des modèles linguistiques.
Comme le montre la figure ci-dessous,Le flux de travail DCLM se compose principalement de quatre étapes : sélectionner une échelle, créer un ensemble de données, former un modèle et évaluer le modèle sur la base de 53 tâches en aval.
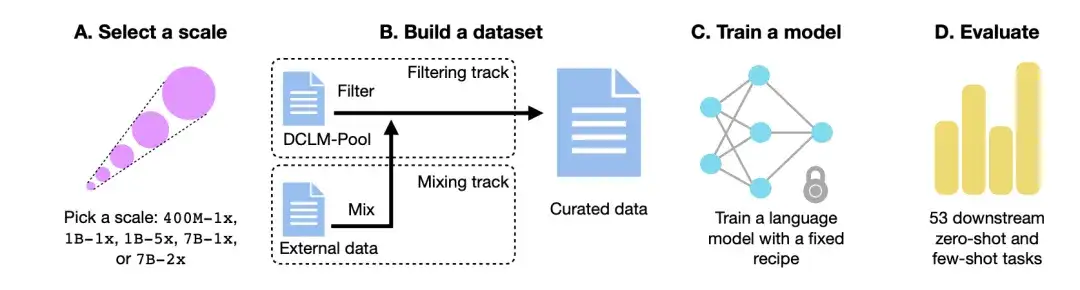
Choisissez l'échelle de calcul
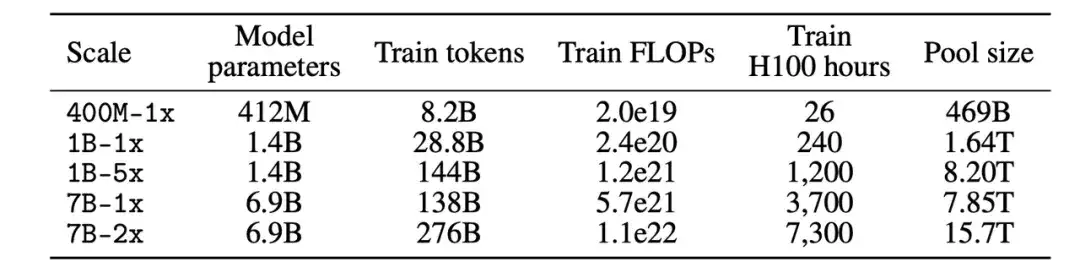
Tout d’abord, en termes d’échelle de calcul, les chercheurs ont créé cinq niveaux de compétition différents couvrant trois ordres de grandeur d’échelle de calcul. Chaque niveau (c'est-à-dire 400M-1x, 1B-1x, 1B-5x, 7B-1x et 7B-2x) spécifie le montant du paramètre du modèle (par exemple, 7B) et un multiplicateur Chinchilla (par exemple, 1x). Le nombre de jetons d'entraînement pour chaque taille est 20 fois le nombre de paramètres multiplié par le multiplicateur Chinchilla.
Construire un ensemble de données
Deuxièmement, après avoir déterminé l'échelle des paramètres, dans le processus de création d'un ensemble de données, les participants peuvent créer un ensemble de données en filtrant (Filtre) ou en mélangeant (Mix) les données.
Dans la piste Filtrage,Les chercheurs ont extrait un corpus standardisé de 240T jetons du site Web d'exploration non filtré Common Crawl, ont construit le DCLM-Pool et l'ont divisé en 5 pools de données en fonction de l'échelle de calcul. Les participants proposent des algorithmes et sélectionnent des données de formation à partir d’un pool de données.
Dans la piste Mix,Les participants sont libres de combiner des données provenant de plusieurs sources. Par exemple, synthétisez des documents de données provenant de DCLM-Pool, de données explorées personnalisées, de Stack Overflow et de Wikipédia.
Entraîner le modèle
OpenLM est une bibliothèque de code basée sur PyTorch qui se concentre sur le module FSDP pour la formation distribuée. Pour éliminer l’impact de l’interférence des ensembles de données, les chercheurs ont utilisé une méthode fixe pour la formation du modèle à chaque échelle de données.
Sur la base d'études d'ablation antérieures sur l'architecture et la formation des modèles, les chercheurs ont adopté une architecture Transformer uniquement décodeur comme GPT-2 et Llama, et ont finalement formé le modèle dans OpenLM.
Évaluation du modèle
enfin,Les chercheurs ont évalué le modèle à l’aide du flux de travail LLM-Foundry, en utilisant 53 tâches en aval adaptées à l’évaluation du modèle de base.Ces tâches en aval comprennent la réponse aux questions, la génération de réponses ouvertes et couvrent une variété de domaines tels que l'encodage, la connaissance des manuels et le raisonnement de bon sens.
Pour évaluer l'algorithme de traitement des données, les chercheurs se sont concentrés sur trois indicateurs de performance : la précision MMLU à 5 coups, la précision du centre CORE et la précision du centre EXTENDED.
Ensemble de données : utilisez DCLM pour créer des ensembles de données de formation de haute qualité
Comment DCLM construit-il l'ensemble de données de haute qualité DCLM-BASELINE et quantifie-t-il l'efficacité des méthodes de gestion des données ?
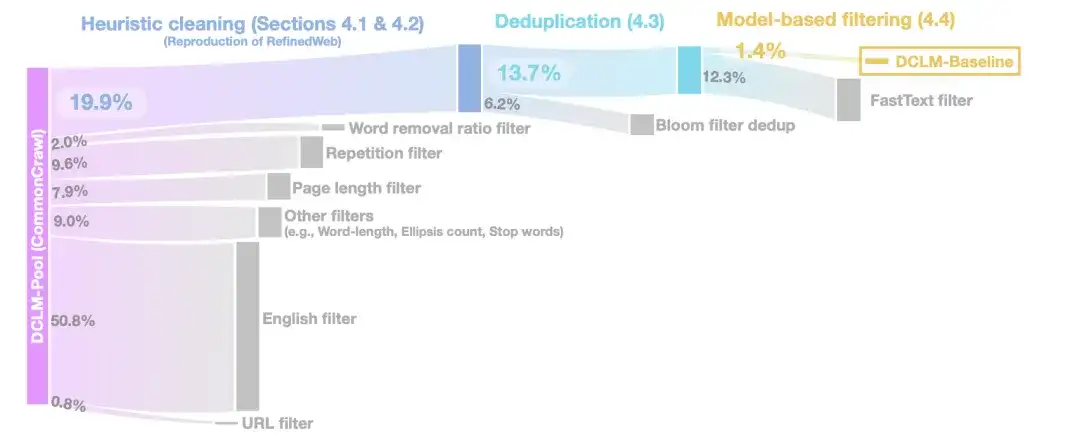
Dans l'étape de nettoyage heuristique,Les chercheurs ont utilisé la méthode de RefinedWeb pour nettoyer les données, notamment en supprimant les URL (filtre URL), les filtres anglais (filtre anglais), les filtres de longueur de page (filtre de longueur de page) et les filtres de contenu en double (filtre de répétition).
Dans la phase de déduplication,Les chercheurs ont utilisé des filtres Bloom pour dédupliquer les données textuelles extraites et ont constaté que les filtres Bloom modifiés étaient plus facilement évolutifs vers des ensembles de données de 10 To.
Pour améliorer encore la qualité des données,Dans l’étape de filtrage basé sur un modèle, les chercheurs ont comparé sept méthodes de filtrage basées sur un modèle.En incluant le filtrage à l'aide des scores PageRank, la déduplication sémantique (SemDedup), le classificateur binaire fastText, etc., il a été constaté que le filtrage basé sur fastText surpassait toutes les autres méthodes.
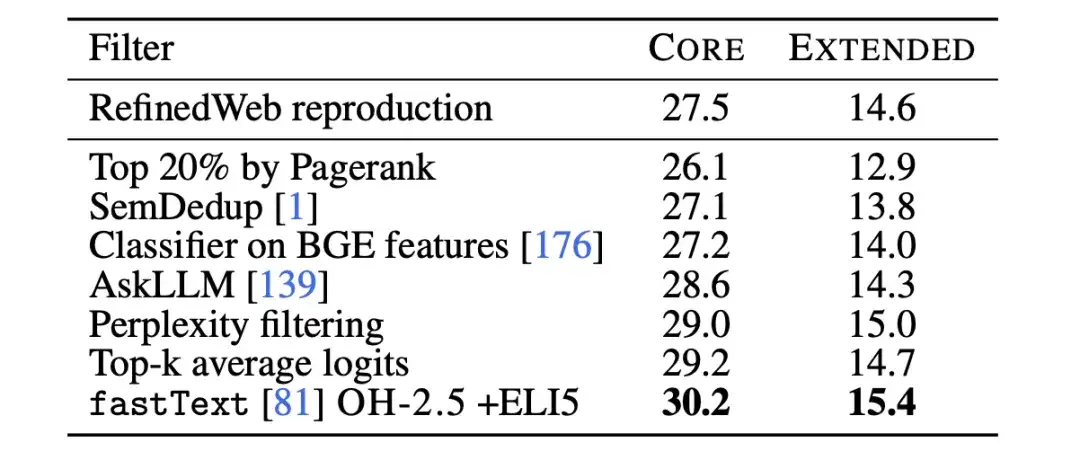
Par la suite, les chercheurs ont utilisé des ablations de classificateurs de texte pour étudier plus en détail les limites du filtrage des données basé sur fastText. Les chercheurs ont formé plusieurs variantes différentes, en explorant différents choix de données de référence, d’espace de fonctionnalités et de seuils de filtrage, comme le montre la figure ci-dessous. Pour les données de référence, les chercheurs ont sélectionné les bases de données couramment utilisées Wikipedia, OpenWebText2 et RedPajama-books, qui sont toutes des données de référence utilisées par GPT-3.
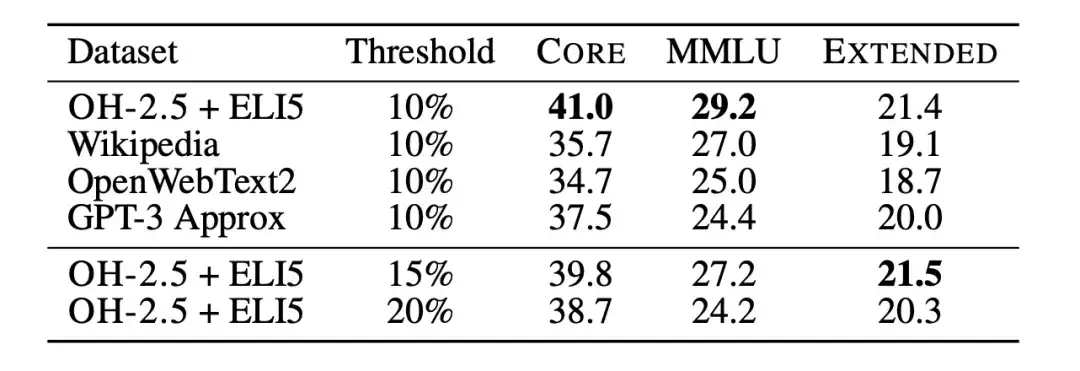
en même temps,Les chercheurs ont également fait un usage innovant des données au format d'instruction, en extrayant des exemples de publications à haut score dans les subreddits OpenHermes 2.5 (OH-2.5) et r/ExplainLikeImFive (ELI5).Les résultats montrent que la méthode OH-2,5 + ELI5 améliore 3,5% sur CORE par rapport aux données de référence couramment utilisées.
De plus, les chercheurs ont découvert qu’un seuil strict (c’est-à-dire le seuil de 10%) peut permettre d’obtenir de meilleures performances. donc,Les chercheurs ont utilisé les scores du classificateur fastText OH-2.5 + ELI5 pour filtrer les données, en conservant les 101 premiers documents TP3T pour obtenir DCLM-BASELINE.
Résultats de la recherche : le filtrage basé sur des modèles est essentiel pour générer des ensembles de données de haute qualité
Dans un premier temps, les chercheurs ont analysé si la contamination des données de pré-formation non évaluées pouvait affecter les résultats.
MMLU est une référence pour mesurer les performances des grands modèles linguistiques et vise à examiner de manière plus complète la capacité du modèle à comprendre différentes langues. Par conséquent, les chercheurs ont utilisé MMLU comme ensemble d'évaluation et ont détecté et supprimé les problèmes existants dans DCLM-BASELINE de MMLU. Les chercheurs ont ensuite formé un modèle 7B-2x basé sur DCLM-BASELINE sans utiliser le chevauchement MMLU détecté.
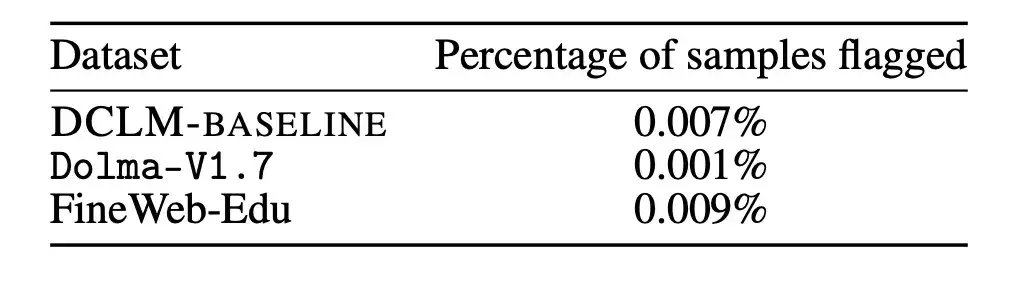
Les résultats sont présentés dans la figure ci-dessous. Le retrait des échantillons contaminés n’entraîne pas de diminution des performances du modèle. On peut voir à partir de là queL’amélioration des performances de DCLM-BASELINE sur le benchmark MMLU n’est pas due à l’inclusion de données MMLU dans son ensemble de données.

De plus, les chercheurs ont également appliqué la stratégie de suppression ci-dessus sur Dolma-V1.7 et FineWeb-Edu pour mesurer les différences de contamination entre DCLM-BASELINE et ces ensembles de données. Il s’avère que les statistiques de pollution de DLCM-BASELINE sont à peu près similaires à celles d’autres ensembles de données hautes performances.
Deuxièmement, les chercheurs ont également comparé le nouveau modèle formé avec d’autres modèles avec une échelle de paramètres 7B-8B. Les résultats montrent que le modèle généré sur la base de l'ensemble de données DCLM-BASELINE surpasse les modèles formés sur des ensembles de données open source et est compétitif avec les modèles formés sur des ensembles de données fermés.
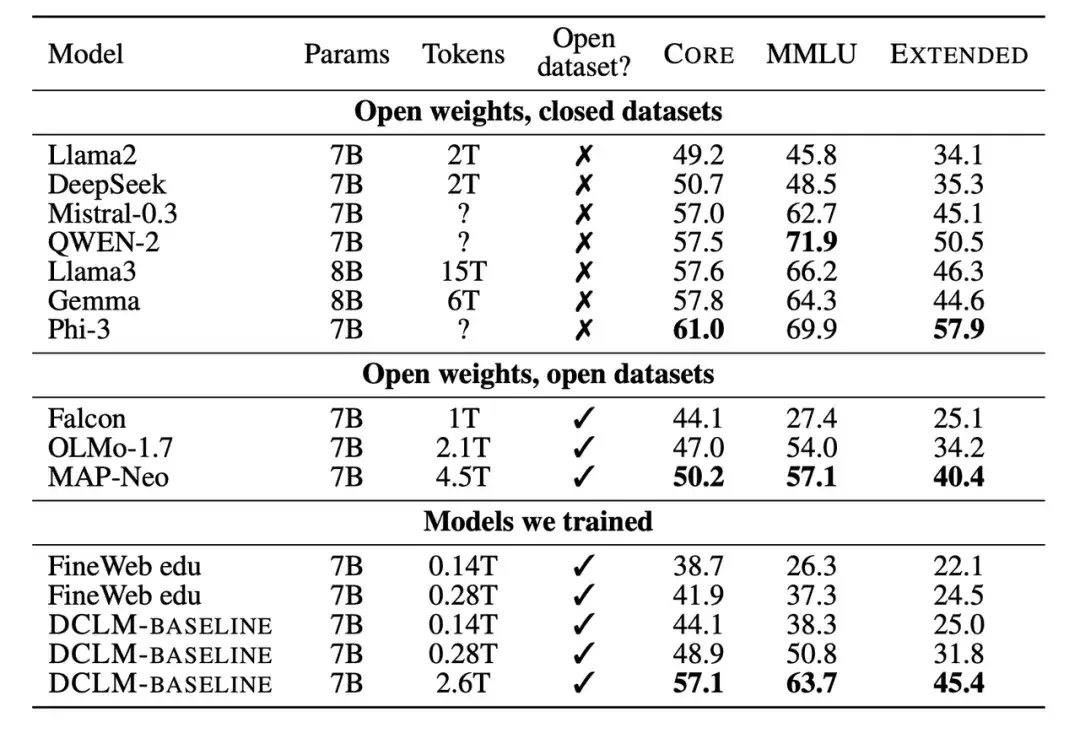
Un grand nombre de résultats expérimentaux montrent queLe filtrage basé sur un modèle est la clé pour former un ensemble de données de haute qualité, et la conception de l'ensemble de données est très importante pour la formation des modèles linguistiques.L'ensemble de données généré DCLM-BASELINE prend en charge la formation d'un modèle de langage à 7 B paramètres à partir de zéro sur MMLU à l'aide de 2,6 T de jetons de formation, atteignant une précision de 5 coups de 641 TP3T.
Comparé au modèle de langage de données ouvertes le plus avancé précédent, MAP-Neo,L'ensemble de données généré DCLM-BASELINE améliore MMLU de 6,6 %, tout en réduisant la quantité de calcul requise pour la formation de 40%.
Le modèle de base de DCLM est comparable à Mistral-7B-v0.3 et Llama3 8B sur MMLU (63% et 66%), et fonctionne de manière similaire sur 53 tâches de compréhension du langage naturel, mais nécessite 6,6 fois moins de calculs pour s'entraîner que Llama3 8B.
Lois d'échelle : l'orientation future n'est pas claire, à la recherche de la prochaine génération d'ensembles d'entraînement pour les modèles de langage
En résumé, le cœur du DCLM est d’encourager les chercheurs à créer des ensembles de formation de haute qualité grâce au filtrage basé sur le modèle, améliorant ainsi les performances du modèle. Cela fournit également une nouvelle approche pour résoudre les problèmes dans le cadre de la tendance de formation de modèle « big is beautiful ».
Comme l'a déclaré Qin Yujia, titulaire d'un doctorat. du département d'informatique de l'université Tsinghua, a déclaré : « Il est temps de réduire la taille des données. » En analysant et en résumant plusieurs articles, il a découvert que « des données propres après nettoyage + un modèle plus petit peuvent être plus proches de l'effet de données sales + un grand modèle ».
Début juillet, Bill Gates a évoqué le sujet du changement de paradigme dans la technologie de l'IA dans le dernier épisode du podcast Next Big Idea, et il pensait que les lois de mise à l'échelle touchaient à leur fin. La révolution de l’IA dans l’interaction informatique n’est pas encore arrivée, mais son véritable progrès réside dans l’obtention de capacités métacognitives plus proches de celles des humains, plutôt que dans la simple augmentation de la taille du modèle.

Avant cela, de nombreux dirigeants de l'industrie nationale ont également eu des discussions approfondies sur l'orientation future des lois de mise à l'échelle lors de la conférence Zhiyuan de Pékin en 2024.
Kai-Fu Lee, PDG de Zero One Everything, a déclaré que la loi de mise à l'échelle s'est avérée efficace et n'a pas encore atteint son apogée, mais la loi de mise à l'échelle ne peut pas être utilisée pour accumuler aveuglément des GPU. Se contenter d’accumuler davantage de puissance de calcul pour améliorer les effets du modèle ne fera que faire gagner les entreprises ou les pays disposant de suffisamment de GPU.
Zhang Yaqin, doyen de l'Institut des industries intelligentes de l'Université Tsinghua, a déclaré que la réalisation de la loi d'échelle est principalement due à l'utilisation de données massives et à l'amélioration significative de la puissance de calcul. Elle restera la principale orientation du développement industriel au cours des cinq prochaines années.

Yang Zhilin, PDG de Dark Side of the Moon, estime qu'il n'y a pas de problème essentiel avec la loi de mise à l'échelle. Tant qu’il y a plus de puissance de calcul et de données, et que les paramètres du modèle deviennent plus grands, le modèle peut continuer à générer plus d’intelligence. Il estime que la loi d’échelle continuera d’évoluer, mais les méthodes de la loi d’échelle peuvent changer considérablement au cours de ce processus.
Wang Xiaochuan, PDG de Baichuan Intelligence, estime qu'en plus de la loi de mise à l'échelle, nous devons rechercher de nouvelles transformations dans la puissance de calcul, les algorithmes, les données et d'autres paradigmes, plutôt que de simplement les transformer en compression de connaissances. Ce n’est qu’en sortant de ce système que nous pourrons avoir une chance d’évoluer vers l’AGI.
Le succès des grands modèles est en grande partie dû à l’existence de lois d’échelle, qui fournissent des conseils précieux pour le développement de modèles, l’allocation des ressources et la sélection de données de formation appropriées. Nous ne savons peut-être pas encore quelle est la fin des lois d’échelle, mais le benchmark DCLM fournit un nouveau paradigme de réflexion et une possibilité d’améliorer les performances du modèle.
Références :
https://arxiv.org/pdf/2406.11794v3
https://arxiv.org/abs/2001.08361








