Command Palette
Search for a command to run...
Une Étape Importante Pour Universal Robots ! Le MIT Propose Un Cadre De Combinaison De Stratégies PoCo Pour Résoudre Le Problème Des Sources De Données Hétérogènes Et Permettre Une Exécution Flexible Des Robots Multitâches

18 robots humanoïdes ont joué le rôle de « saluteurs » et ont salué les invités à l'unisson. Ce fut une scène choquante lors de la Conférence mondiale sur l’intelligence artificielle 2024, permettant aux gens de ressentir intuitivement le développement rapide des robots cette année.

En 1954, le premier robot programmable au monde, « Unimate », a été officiellement mis en service sur la chaîne de montage de General Motors. Après plus d’un demi-siècle, les robots sont progressivement passés du statut de géants industriels volumineux à celui d’assistants humains plus intelligents et plus flexibles. Parmi elles, la technologie de l’intelligence artificielle, en particulier les progrès révolutionnaires dans le traitement du langage naturel et la vision par ordinateur, a ouvert la voie au développement à grande vitesse de robots, utilisant une énorme puissance de calcul et des données massives.Entraîner des stratégies robotiques générales grâce à des algorithmes simples tels que le clonage comportemental,Le potentiel illimité des robots du futur est progressivement libéré.

Cependant, la plupart des pipelines d’apprentissage robotiques actuels sont formés pour une tâche spécifique.Cela les rend incapables de faire face à de nouvelles situations ou d’effectuer des tâches différentes.De plus, les données de formation des robots proviennent principalement de scénarios de simulation, de démonstration humaine et de téléopération de robots.Il existe une grande hétérogénéité entre les différentes sources de données.Il est également difficile pour un modèle d’apprentissage automatique d’intégrer des données provenant d’autant de sources, et la formation de robots avec des stratégies générales a toujours été un défi majeur.
En réponse à cela,Les chercheurs du MIT ont proposé un cadre de composition de politique robotique PoCo (Policy Composition).Ce cadre utilise la synthèse probabiliste de modèles de diffusion pour combiner des données provenant de différents domaines et modalités, et développe des méthodes de synthèse de stratégie au niveau des tâches, du comportement et du domaine pour créer des combinaisons complexes de stratégies de robot. Il peut résoudre les problèmes d’hétérogénéité des données et de diversité des tâches dans les tâches d’utilisation des outils robotiques. La recherche connexe a été publiée sur arXiv sous le titre « PoCo : Policy Composition from and for Heterogeneous Robot Learning ».
Points saillants de la recherche :
* Pas besoin de se recycler, le framework PoCo peut combiner de manière flexible des stratégies pour former des données de différents domaines
* PoCo excelle dans les tâches d'utilisation d'outils à la fois en simulation et dans le monde réel, et montre une généralisation élevée aux tâches dans différents environnements par rapport aux méthodes entraînées sur un seul domaine

Adresse du document :
https://arxiv.org/abs/2402.02511
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Trois grands ensembles de données, couvrant les données humaines et machines, les données réelles et simulées, etc.
Les ensembles de données impliqués dans cette étude proviennent principalement de données vidéo de démonstration humaine, de données de robots réels et de données de simulation.
Ensemble de données vidéo de démonstration humaine
Des vidéos de démonstration humaine peuvent être collectées à partir de caméras non calibrées dans la nature, avec jusqu'à 200 pistes collectées au total.

Ensemble de données de robots réels
Les vues locales et globales de la scène sont obtenues grâce à la caméra de poignet installée et à la caméra aérienne, et la posture de l'outil, la forme de l'outil et les informations tactiles lorsque l'outil entre en contact avec l'objet sont collectées à l'aide de GelSight Svelte Hand. 50 à 100 démonstrations de trajectoire sont collectées pour chaque tâche.
Ensemble de données de simulation
L'ensemble de données simulées suit Fleet-Tools, où des démonstrations d'experts sont générées via l'optimisation de la trajectoire des points clés, et un total d'environ 50 000 points de données simulés sont collectés. Au cours du processus de formation ultérieur, les chercheurs ont effectué une augmentation des données sur les données du nuage de points et les données de mouvement, et ont enregistré des scènes de simulation fixes pour les tests.
De plus, les chercheurs ont ajouté des bruits ponctuels et des chutes aléatoires à 512 outils et 512 nuages de points d'objets à partir d'images de profondeur et de masques pour améliorer la robustesse du modèle.
Combinaison de stratégies par produit de distribution de probabilité
Dans la combinaison de stratégies, les chercheurs ont donné des informations de trajectoire codées par deux distributions de probabilité pDM(⋅|c,T) et pD′M′(⋅|c′,T′), et ont directement combiné les informations de ces deux distributions de probabilité par échantillonnage dans la distribution du produit pendant l'inférence.
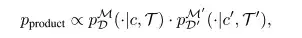
dans,pproduit Il montre une forte probabilité sur toutes les trajectoires qui satisfont les deux distributions de probabilité.Il peut encoder efficacement les informations des deux distributions.
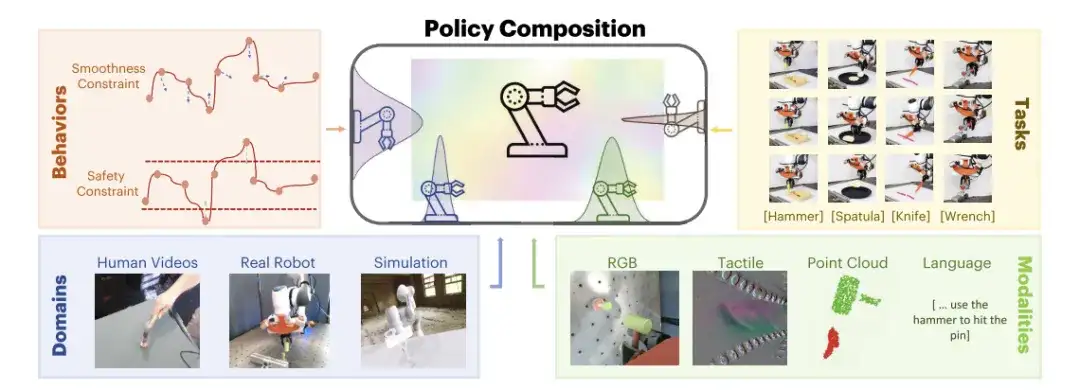
PoCo proposé par les chercheurs,Rassembler des informations sur les comportements, les tâches, les canaux et les domaines,Aucune reconversion n’est nécessaire ; les informations sont combinées de manière modulaire lors de la prédiction, et la généralisation des tâches d'utilisation des outils peut être obtenue en exploitant les informations de plusieurs domaines.
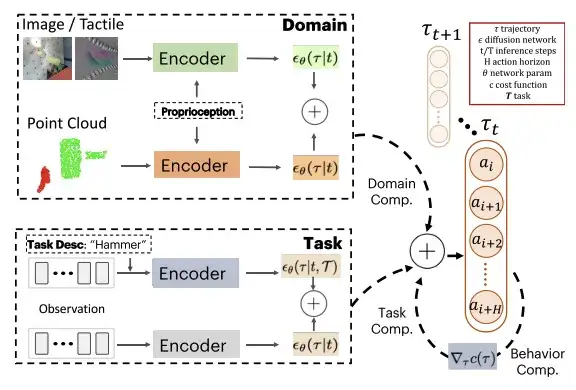
On suppose que la sortie de diffusion de chaque modèle se trouve dans le même espace, c'est-à-dire que la dimension d'action et le domaine temporel d'action sont les mêmes. Au moment du test, PoCo est combiné avec des prédictions de gradient. Cette approche peut être appliquée à la combinaison de politiques de différents domaines, comme la combinaison de politiques formées à l’aide de différentes modalités telles que des images, des nuages de points et des images tactiles. Il peut également être utilisé pour combiner des stratégies pour différentes tâches, ainsi que pour fournir des fonctions de coût supplémentaires pour les comportements souhaités grâce à la combinaison de comportements.
À cet égard, les chercheurs ont fourni trois exemples : la composition au niveau des tâches, la composition au niveau du comportement et la composition au niveau du domaine pour illustrer comment PoCo peut améliorer les performances des politiques.
Composition au niveau des tâches
La combinaison au niveau des tâches ajoute des poids supplémentaires aux trajectoires qui peuvent potentiellement terminer la tâche T, ce qui peut améliorer la qualité finale de la trajectoire synthétisée sans nécessiter de formation séparée pour chaque tâche.Au lieu de cela, une politique générale est formée qui peut atteindre des objectifs multitâches.
Composition au niveau du comportement
Cette combinaison peut combiner des informations sur la répartition des tâches et l’objectif de coût.Assurez-vous que la trajectoire synthétisée complète la tâche et optimise l’objectif de coût spécifié.
Composition au niveau du domaine
Cette combinaison peut exploiter les informations capturées à partir de différentes modalités et domaines de capteurs.Très utile pour compléter les données collectées dans des champs séparés.Par exemple, lorsque les données de robots réels sont coûteuses à collecter mais plus précises, et que les données de démonstration de simulation sont moins chères à collecter mais moins précises, la concaténation de caractéristiques peut être effectuée sur des données provenant de différents modes dans le même champ pour simplifier le traitement.
Tâche d'utilisation de l'outil de visualisation, évaluer 3 combinaisons de stratégies majeures

Au cours de la formation, les chercheurs ont utilisé une structure U-Net temporelle avec un modèle probabiliste de diffusion de débruitage (DDPM) et ont effectué 100 étapes de formation ; lors des tests, ils ont utilisé un modèle implicite de diffusion de débruitage (DDIM) et ont effectué 32 étapes de test. Afin de combiner différents modèles de diffusion entre différents domaines D et tâches T, les chercheurs ont utilisé le même espace d'action pour tous les modèles et ont effectué une normalisation fixe sur les limites d'action du robot.
Les chercheurs ont évalué le PoCo proposé à travers des tâches d’utilisation de robots pour des outils courants (clé, marteau, pelle et clé à molette). La tâche était considérée comme réussie lorsqu'un certain seuil était atteint, par exemple, la tâche de martelage était considérée comme réussie lorsqu'une goupille était enfoncée.
Les combinaisons au niveau du comportement peuvent améliorer les objectifs comportementaux souhaités
Les chercheurs ont utilisé l’inférence au moment du test pour combiner des comportements tels que la fluidité et les contraintes d’espace de travail, avec le poids de synthèse fixé à γc = 0,1.
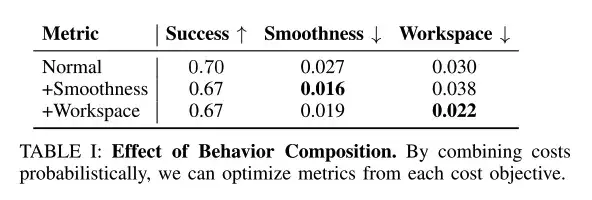
Comme le montre le tableau ci-dessus, les combinaisons de comportement au moment du test peuvent améliorer les objectifs comportementaux souhaités tels que la fluidité et les contraintes de l'espace de travail.
Les combinaisons au niveau des tâches sont optimales dans l'évaluation des politiques multitâches
Lorsque le poids de la tâche α = 0, la politique de combinaison au niveau de la tâche est mappée à la politique multitâche inconditionnelle, lorsque α = 1, elle est mappée à la politique standard conditionnée par la tâche, et lorsque 0 < α < 1, les chercheurs interpolent entre les politiques conditionnées par la tâche et les politiques inconditionnelles par la tâche. Lorsque α > 1, des trajectoires plus pertinentes pour les conditions de la tâche peuvent être obtenues.
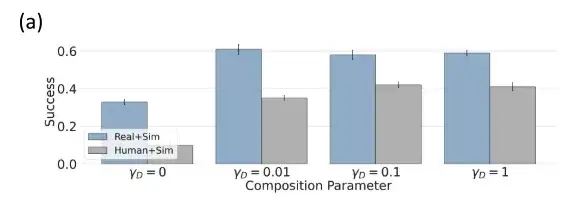
La figure ci-dessus montre que par rapport à la stratégie de diffusion de l'utilisation d'outils multitâches conditionnels inconditionnels et spécifiques à la tâche, la stratégie d'utilisation d'outils multitâches conditionnels et inconditionnels présente une meilleure combinaison de tâches.
La combinaison de données humaines et simulées au niveau du domaine offre de meilleures performances
Les chercheurs ont formé des modèles de politique distincts à l’aide d’un ensemble de données simulées θsim, d’un ensemble de données humaines θhuman et d’un ensemble de données robotiques θrobot, et ont évalué les combinaisons au niveau du domaine dans un environnement simulé.
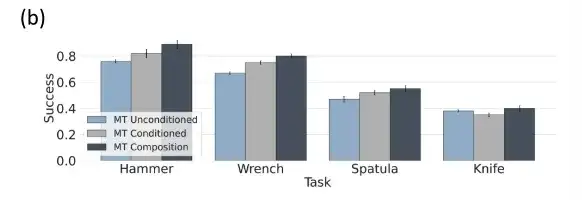
Étant donné que θsim n’a pas d’écart de domaine de formation/test, il fonctionne bien et peut atteindre un taux de réussite de 92%. Dans des domaines tels que les données humaines, les chercheurs l'ont combiné avec une politique θsim plus performante, améliorant considérablement les performances.
La performance de la combinaison de stratégies dépasse celle de ses composants individuels et est plus polyvalente
Les chercheurs ont appliqué PoCo aux tâches d’utilisation d’outils robotiques, en combinant des données provenant de différents domaines et tâches pour améliorer sa capacité de généralisation. Les 4 tâches sont : serrer les vis avec une clé, enfoncer les clous avec un marteau, retirer les crêpes de la poêle avec une pelle et couper la pâte à modeler avec un couteau.

En combinant des politiques formées en simulation, des humains et des données réelles, nous pouvons généraliser sur plusieurs distracteurs (ligne 1), différentes poses d'objets et d'outils (ligne 2) et de nouvelles instances d'objets et d'outils (ligne 3).
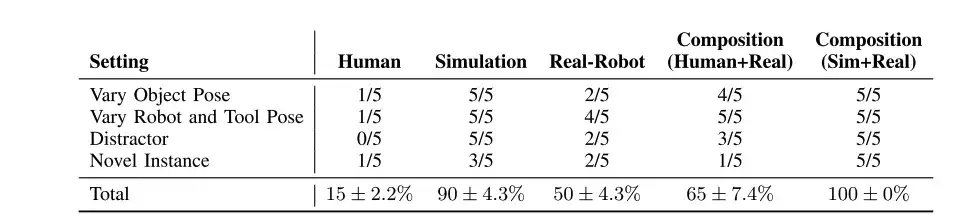
Comme le montre le tableau ci-dessus, bien que les stratégies entraînées avec des données humaines et les stratégies entraînées avec des données de robots réels aient de faibles performances dans différents scénarios (par rapport à la simulation),Mais leur combinaison (Humain+Réel) peut dépasser chaque composant individuel.
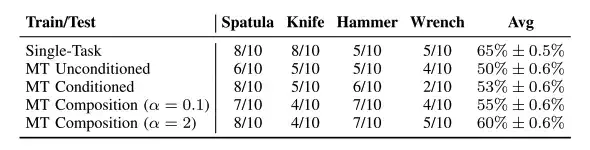
Dans le monde réel, les chercheurs ont évalué les performances stratégiques du robot sur quatre tâches différentes utilisant des outils et ont constaté que dans les tâches utilisant des outils,Les performances de la stratégie de combinaison de tâches sont mieux améliorées.Comme le montre le tableau ci-dessus, les performances de la stratégie multitâche sont presque les mêmes que celles des tâches spécifiques conditionnées par Tspatula et Thammer, et elles présentent toutes une certaine stabilité dans les actions fines. De plus, les hyperparamètres combinés doivent être maintenus dans une plage pour être efficaces et stables.
Les meilleures conditions pour l'universalité : les robots humanoïdes connaissent une forte croissance
Les robots à usage général ont prospéré au cours des deux dernières années, mais un phénomène intéressant est que l'industrie semble actuellement davantage en faveur de la promotion du développement de robots à usage général de manière humanoïde.Pourquoi les robots polyvalents doivent-ils être humanoïdes ?Chen Zhe, directeur général de 5Y Capital, a déclaré : « Parce que seuls les robots humanoïdes peuvent s'adapter à différents scénarios d'interaction dans l'environnement de vie humain ! » Étant donné que les robots vont aider les humains à travailler, il est évidemment préférable pour eux d’imiter les humains et d’apprendre avec une apparence humanoïde.
En tant que référence pour l'industrie, dès septembre 2022, Tesla a lancé le robot humanoïde polyvalent Optimus. Bien qu'il ne puisse même pas marcher de manière stable au début, il possède un prototype de robot humanoïde complet et répond aux exigences de base du travail adroit que les humains peuvent effectuer. Avec l'itération continue de la technologie logicielle et matérielle de Tesla, Optimus aura des fonctions plus intéressantes, et les faits se sont avérés vrais.

Lors de la Conférence mondiale sur l'intelligence artificielle 2024, Tesla a montré à tous les derniers progrès de la recherche de son robot humanoïde Optimus : la vitesse de marche verticale a augmenté de 30%, et les dix doigts ont également fait évoluer la perception et le toucher, de sorte qu'ils peuvent tenir doucement les œufs fragiles et transporter régulièrement des boîtes lourdes. Il semblerait qu'Optimus ait essayé des applications pratiques dans les usines Tesla, comme l'utilisation de réseaux neuronaux visuels et de puces FSD pour imiter les opérations humaines afin de mener une formation au tri des batteries. On s’attend à ce que l’année prochaine, il y ait plus de 1 000 robots humanoïdes dans les usines Tesla pour aider les humains à accomplir les tâches de production.
De même, Shanghai Fourier Intelligent Technology Co., Ltd., une société leader dans le domaine de la robotique générale fondée en 2015, a également amené son robot humanoïde GR-1 à la conférence. Depuis son lancement en 2023, GR-1 a pris la tête de la production et de la livraison de masse et a réalisé des mises à niveau avancées dans la perception de l'environnement, les modèles de simulation, l'optimisation du contrôle des mouvements et d'autres aspects.
De plus, en mars de cette année, NVIDIA a également lancé un projet de robot humanoïde appelé GR00T lors de sa conférence annuelle des développeurs GTC. En observant le comportement humain pour comprendre le langage naturel et imiter les actions, le robot peut rapidement apprendre la coordination, la flexibilité et d’autres compétences pour naviguer, s’adapter et interagir avec le monde réel.
Avec les progrès continus de la science et de la technologie, nous avons des raisons de croire que les robots humanoïdes pourraient devenir un pont reliant les humains et les machines, la réalité et l’avenir, nous conduisant vers une société plus intelligente et meilleure.
Références :
https://m.163.com/dy/article/J69LAFDR0512MLBG.html
https://36kr.com/p/1987021834257154
https://hub.baai.ac.cn/view/211








