Command Palette
Search for a command to run...
Sous-titres Chinois Exclusifs ! Le Cours d'IA De Printemps d'Alfredo, Étudiant De LeCun, Commence ; Téléchargement Du Jeu De Données De Télédétection CVPR'24

Récemment, Alfredo Canziani, professeur adjoint d'informatique à l'Université de New York et étudiant de Yann LeCun, a publié son cours de printemps « AI », qui couvre des sujets tels que la probabilité discrète et Bayes naïf, les perceptrons et la régression logistique, l'optimisation, les statistiques et le traitement neuronal du langage naturel, la classification des réseaux neuronaux, les réseaux neuronaux récurrents et les réseaux neuronaux convolutifs.
Cette semaine, HyperAI diffusera le cours en direct sur B Station 24h/24 et 7j/7. Apprenons ensemble~
Lien de la montre :
http://live.bilibili.com/26483094
Du 24 au 28 juin, le site officiel hyper.ai est mis à jour :
- Ensembles de données publiques de haute qualité : 10
- Sélection de tutoriels de haute qualité : 3
- Sélection d'articles communautaires : 4 articles
- Entrées d'encyclopédie populaires : 5
- Principales conférences avec dates limites en juillet : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de suivi d'instructions multimodales de télédétection GeoChat Instruct
L'ensemble de données contient près de 318 000 instructions et vise à étendre l'adaptation des instructions multimodales au domaine de la télédétection pour la formation d'assistants conversationnels multitâches. Les résultats de l’article associé ont été acceptés par CVPR 2024.
Utilisation directe :https://go.hyper.ai/CXu0K
2. Grand ensemble de données de segmentation d'images de télédétection RRSIS-D
L'ensemble de données contient 17 402 triplets image-description-masque couvrant une variété de résolutions spatiales et d'orientations d'objets. Les résultats de l’article associé ont été acceptés par CVPR 2024.
Utilisation directe :https://go.hyper.ai/1VRQG
3. Ensemble de données de cartographie de télédétection de l'ensemble de données Earth Parser
Cet ensemble de données est utilisé pour la formation et l'évaluation des méthodes d'analyse sur de grandes analyses LiDAR aériennes non organisées. L'ensemble de données contient 7 scènes couvrant une superficie de plus de 7,7 kilomètres carrés et un total de 98 millions de points 3D. Les résultats de l’article associé ont été acceptés par CVPR 2024.
Utilisation directe :https://go.hyper.ai/3pFjm
4. Ensemble de données Harvard-GF3300 sur les maladies neurologiques rétiniennes (glaucome)
Cet ensemble de données est un ensemble de données sur les maladies neurologiques rétiniennes (glaucome) qui comprend 3 300 sujets, contenant des données d'images 2D et 3D. L'ensemble de données contient un nombre égal de sujets issus des trois principaux groupes raciaux (blancs, noirs et asiatiques), ce qui évite les problèmes de déséquilibre des données qui peuvent perturber les problèmes d'apprentissage équitable.
Utilisation directe :https://go.hyper.ai/vIhu6
Cet ensemble de données contient diverses images radiographiques de tomographie orthodontique dentaire (OPG), 70 échantillons de haute qualité. En fournissant des annotations, cet ensemble de données peut être utilisé pour former et tester des modèles d'apprentissage automatique pour les tâches d'analyse d'images dentaires telles que la classification des types de dents, la détection d'anomalies, etc.
Utilisation directe :https://go.hyper.ai/vK9zz
6. Ensemble de données radiographiques de fractures multirégionales
L'ensemble de données contient des images radiographiques fracturées et non fracturées couvrant toutes les régions anatomiques du corps, y compris les membres inférieurs, les membres supérieurs, la colonne lombaire, les hanches, les genoux, etc. L'ensemble de données est divisé en dossiers de formation, de test et de validation, avec un total de 10 580 données d'images radiologiques (rayons X).
Utilisation directe :https://go.hyper.ai/Yk1bA
7. Ensemble de données de reconnaissance d'images de fruits et légumes
L'ensemble de données contient des images de 10 types de fruits et de 26 types de légumes, et chaque catégorie est divisée en ensembles d'entraînement, de test et de validation, offrant un ensemble diversifié pour les tâches de reconnaissance d'images.
Utilisation directe :https://go.hyper.ai/FdfRK
L'ensemble de données contient des informations sur 15 939 personnages populaires issus de divers types et genres de médias. Chaque entrée comprend des détails sur le personnage, la source multimédia et une scène unique impliquant le personnage.
Utilisation directe :https://go.hyper.ai/wf1q1
9. RepLiQA est un ensemble de données de réponses aux questions possible pour l'analyse comparative
RepLiQA est un ensemble de données d'évaluation contenant des triplets « contexte-question-réponse » couvrant 17 sujets ou catégories de documents, conçus pour tester la capacité des grands modèles linguistiques (LLM) à trouver et à utiliser des informations contextuelles dans les documents fournis.
Utilisation directe :https://go.hyper.ai/ZkSYD
10. Ensemble de données d'évaluation de la sécurité du réseau à grande échelle CS-Eval
L'ensemble de données couvre 11 domaines majeurs de la sécurité des réseaux, 42 sous-domaines et 4 369 questions à choix multiples, questions vrai ou faux et questions d'extraction de connaissances. Il fournit des tâches d'évaluation complètes basées sur les connaissances et la pratique, prend en charge l'auto-évaluation des utilisateurs et fournit une référence et une inspiration pour la mise en œuvre de modèles à grande échelle dans la sécurité des réseaux.
Utilisation directe :https://go.hyper.ai/ziacf
Pour plus d'ensembles de données publics, veuillez visiter :
Tutoriels publics sélectionnés
1. Démonstration de la prédiction hiérarchique de la classification biologique Bioclip
Cette démo de tutoriel peut classer une image biologique donnée par famille, genre, espèce, etc. Il s'agit de la version Gradio du modèle du meilleur article étudiant « BioCLIP : A Vision Foundation Model for the Tree of Life » de CVPR2024.
Exécutez en ligne :https://go.hyper.ai/OEWk1
2. InstantStyle - un générateur d'images cohérent
InstantStyle est un framework de génération de texte en image développé par l'équipe InstantX de Xiaohongshu, qui permet le transfert de style tout en maintenant la contrôlabilité du texte du contenu. Ce tutoriel a créé l'environnement adapté à vos besoins et vous pouvez en faire l'expérience en un clic !
Exécutez en ligne :https://go.hyper.ai/E6GuW
Ce modèle est un modèle de chat chinois basé sur le modèle Meta-Llama-3-8b-Instruct qui est spécialement conçu pour le chinois. Par rapport au modèle original Meta-Llama-3-8b-Instruct, le nombre de « questions chinoises avec réponses en anglais » et de questions mixtes chinoises et anglaises a été considérablement réduit. Il suffit de cloner et de démarrer le conteneur, puis de copier directement l'adresse API générée pour expérimenter l'inférence sur le modèle.
Exécutez en ligne :https://go.hyper.ai/BLHcM
Articles de la communauté
Des scientifiques du Royaume-Uni et du Japon ont utilisé la technologie de l'apprentissage automatique pour concevoir un système de recherche qui combine des méthodes axées sur les chercheurs et celles basées sur les données, et ont réussi à produire l'aimant supraconducteur à base de fer le plus puissant au monde. Cet article est une interprétation détaillée et un partage de la recherche.
Afficher les détails de l'événement :https://go.hyper.ai/RxV9x
Lors de la conférence Zhiyuan de Pékin, le professeur Li Jianping, vice-président du premier hôpital de l'université de Pékin et directeur de l'Institut de médecine cardiovasculaire, a partagé la nouvelle exploration et la nouvelle pratique de l'IA dans le diagnostic des maladies coronariennes et la prédiction de l'ischémie myocardique clinique sous le thème « Méthodes et difficultés de prédiction de l'ischémie myocardique clinique ». Cela offre une nouvelle approche du diagnostic et du traitement des patients atteints de maladies coronariennes et élargit la portée du cœur aux reins, ce qui devrait permettre à l’IA de jouer un rôle plus important en médecine clinique. Cet article est un résumé détaillé du discours.
Lire l'interview complète :https://go.hyper.ai/5X9jM
Une équipe de recherche de l'Université Tsinghua a proposé un modèle de grandes cellules appelé sc-Foundation, qui est formé sur la base de données d'expression génétique provenant de 50 millions de cellules. Il possède 100 millions de paramètres et peut traiter environ 20 000 gènes simultanément. En tant que modèle de base, il montre une excellente amélioration des performances dans diverses tâches biomédicales en aval telles que l'amélioration de la profondeur du séquençage cellulaire, la prédiction de la réponse cellulaire aux médicaments et la prédiction des perturbations cellulaires. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/v5i5K
Récemment, le professeur Zhou Hao de l'Institut des industries intelligentes de l'Université Tsinghua, en tant que praticien en informatique, a partagé avec tout le monde les multiples défis auxquels sont confrontés les spécialistes de l'IA dans la conception des protéines et a décrit les dernières recherches de pointe dans le domaine des protéines sous trois aspects : la structure des données, l'algorithme de génération et le pré-entraînement des protéines. Cet article rend compte du partage approfondi du professeur Zhou Hao.
Voir le rapport complet :https://go.hyper.ai/PTyAp
Articles populaires de l'encyclopédie
1. Théorème d'échelle Loi d'échelle
2. Fusion de classement réciproque RRF
3. Champ de rayonnement neuronal (NeRF)
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Théorème de représentation de Kolmogorov-Arnold
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Aperçu de la diffusion en direct de la station B
AIfredo Canziani est professeur adjoint d'informatique à l'Université de New York et étudiant de Yann LeCun. Récemment, il a publié sa vidéo de printemps « Cours d'IA ». Les points de connaissance enseignés dans chaque chapitre comprennent : la probabilité discrète et Bayes naïf ; perceptron et régression logistique ; optimisation, statistiques et traitement neuronal du langage naturel ; classification des réseaux neuronaux, etc. Cette semaine, Super Neuro TV diffusera le cours en direct 24h/24 et 7j/7.
Le tableau suivant est un aperçu du contenu sélectionné par l'éditeur↓↓↓
| date | temps | contenu |
|---|---|---|
| Lundi 1er juillet | 18:00 | Partie 1 : Introduction à la méthode bayésienne naïve |
| Mardi 2 juillet | 18:00 | Partie 2 Classification bayésienne naïve |
| Mercredi 3 juillet | 18:00 | Partie 3 Estimation des paramètres bayésiens naïfs et lissage de Laplace |
| Jeudi 4 juillet | 18:00 | Partie 4. Évaluation des classificateurs binaires |
| Vendredi 5 juillet | 18:00 | Partie 5 Perceptrons multiclasses Régression logistique binaire et multiclasse |
| Samedi 6 juillet | 18:00 | Partie 6 Optimisation et ascension du gradient |
| Dimanche 7 juillet | 18:00 | Conférence d'Alfredo Canziani sur l'apprentissage auto-supervisé basé sur l'énergie |
Super Neuro TV diffuse en direct 24h/24 et 7j/7. Cliquez pour obtenir les « cornichons électroniques » dans le domaine de l'IA :
http://live.bilibili.com/26483094
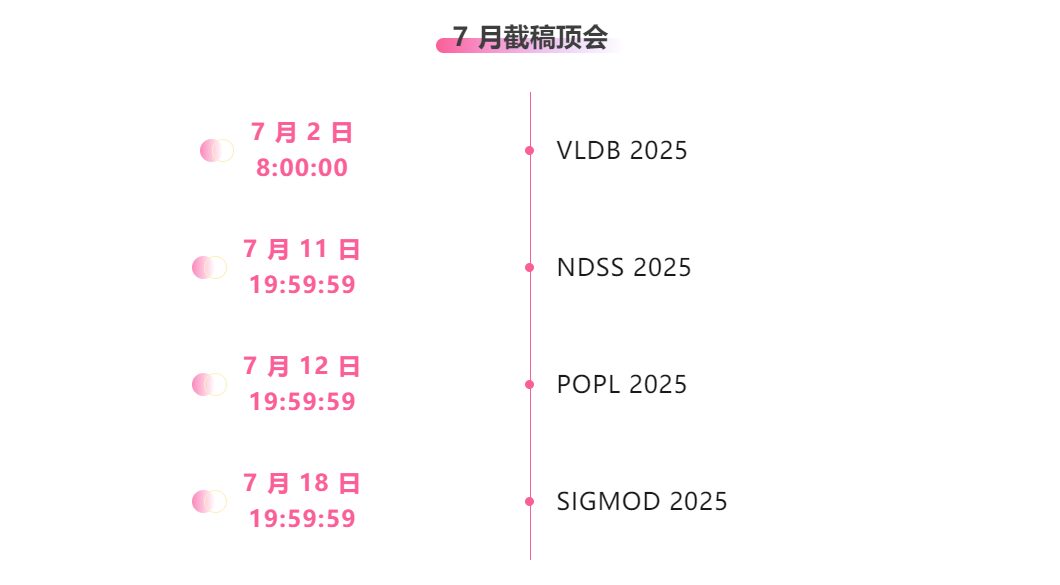
Suivi unique des principales conférences universitaires sur l'IA :https://hyper.ai/events
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine. Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
- Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 300 ensembles de données publiques
- Contient plus de 400 tutoriels en ligne classiques et populaires
- Interprétation de plus de 100 cas d'articles AI4Science
- Prend en charge la recherche de plus de 500 termes associés
- Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








