Command Palette
Search for a command to run...
Le Rassemblement Hors Ligne Meet AI Compiler Beijing 2024 Est Prévu ! InfinityInstruct, Un Ensemble De Données Permettant De Peaufiner Des Dizaines De Millions d'instructions, Est Désormais Open Source

Des données d’instruction de haute qualité constituent une ressource indispensable pour la formation et l’optimisation de grands modèles linguistiques et constituent la pierre angulaire de l’amélioration des performances du modèle. Récemment, l'Académie d'intelligence artificielle de Pékin a publié le projet open source InfinityInstruct, qui contient des dizaines de millions d'ensembles de données de réglage fin d'instructions de haute qualité, y compris des données filtrées de haute qualité basées sur des ensembles de données open source et des données d'instructions de haute qualité construites grâce à des méthodes de synthèse de données.
Le premier lot de 3 millions d'ensembles de données d'instructions chinoises et anglaises de haute qualité InfInstruct-3M, qui ont été vérifiés par modèle, a été rendu open source lors de cette conférence.Désormais disponible sur le site officiel hyper.ai. Vous pouvez utiliser cet ensemble de données et affiner le modèle de base avec vos propres données d'application pour créer rapidement un modèle de dialogue bilingue chinois-anglais exclusif de haute qualité.
Du 10 au 14 juin, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels sélectionnés de haute qualité : 2
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
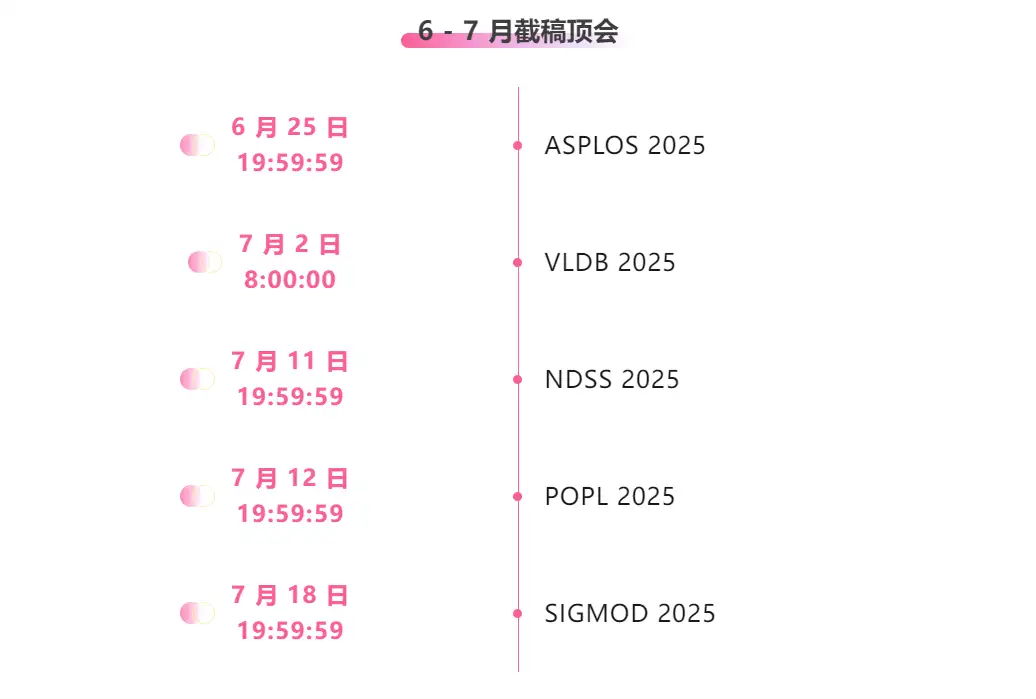
* Principales conférences avec dates limites en juin et juillet : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. InfInstruct-3M lance un ensemble de données de 10 millions d'instructions pour un réglage fin
L'ensemble de données a été lancé par l'Académie d'intelligence artificielle de Pékin. L’objectif du projet est de développer un ensemble de données contenant des millions d’instructions pour prendre en charge les capacités de suivi des instructions des grands modèles de langage et ainsi améliorer les performances du modèle. Cette version est l'ensemble de données d'instructions InfinityInstruct-3M, et la version finale devrait être publiée fin juin.
Utilisation directe :https://go.hyper.ai/iG7gN
2. Ensemble de données de référence pour la compréhension du contexte long LooGLE
Cet ensemble de données est un ensemble de données de référence conçu pour évaluer et améliorer les capacités des systèmes d'intelligence artificielle dans la compréhension du contexte à long terme. Le document de recherche associé a été accepté par ACL2024.
Utilisation directe :https://go.hyper.ai/S6dSZ
3. InternVid-Full Ensemble de données vidéo-texte à grande échelle de haute qualité
L'ensemble de données contient plus de 7 millions de vidéos avec des descriptions textuelles détaillées, couvrant 16 scènes et environ 6 000 descriptions d'actions, pour une durée totale de près de 760 000 heures. L'article connexe a été mis en avant lors de la Conférence internationale 2024 sur l'apprentissage de la représentation (ICLR 2024).
Utilisation directe :https://go.hyper.ai/AnaLl
Cet ensemble de données est un ensemble de données de couverture terrestre pour la télédétection, spécialement conçu pour la segmentation sémantique adaptative au domaine, contenant 5 987 images haute résolution et 166 768 objets sémantiques annotés.
Utilisation directe :https://go.hyper.ai/ShKyN
5. Ensemble de données d'images de bâtiments urbains CityGen
Cet ensemble de données est un ensemble de données d'images axé sur les bâtiments urbains. Il contient généralement un grand nombre d'images de bâtiments urbains. Ces images peuvent être utilisées pour former et évaluer des modèles de vision par ordinateur, en particulier dans des tâches telles que la détection de bâtiments, la segmentation sémantique et la segmentation d'instances. Les résultats pertinents ont été inclus dans le CVPR 2024.
Utilisation directe :https://go.hyper.ai/ddNqv
L'ensemble de données contient 15 000 images (256 × 256 pixels chacune) couvrant divers matériaux recyclables, déchets généraux et articles ménagers dans 30 catégories différentes, offrant une ressource riche et diversifiée pour la recherche et le développement dans le domaine du tri et du recyclage des déchets.
Utilisation directe :https://go.hyper.ai/kOiKG
7. OISEAUX 525 ESPÈCES Ensemble de données d'images de 525 oiseaux
L'ensemble de données contient 525 espèces d'oiseaux, 84 635 images d'entraînement, 2 625 images de test et 2 625 images de validation.
Utilisation directe :https://go.hyper.ai/pfw5d
L'ensemble de données comprend 2,2 millions de clips provenant de 5 000 images aériennes et satellites couvrant 97 régions dans 44 pays sur 6 continents, avec des étiquettes de couverture terrestre annotées manuellement de 8 classes à une distance d'échantillonnage au sol de 0,25 à 0,5 mètre. Les résultats pertinents des articles ont été inclus dans WACV 2023.
Utilisation directe :https://go.hyper.ai/ubxmO
9. Ensemble de données d'évaluation de la traduction automatique de bandes dessinées OpenMantra
Cet ensemble de données est un ensemble de données d'évaluation de traduction automatique pour les bandes dessinées japonaises. Il contient des bandes dessinées de cinq styles différents (fantastique, romance, combat, suspense et vie). L'ensemble de données contient un total de 1 593 phrases, 848 scènes et 214 pages de bandes dessinées. Il a été publié par l'équipe Mantra de l'Université de Tokyo.
Utilisation directe :https://go.hyper.ai/ISqUR
10. Ensemble de données de reconnaissance de texture DTD
L'ensemble de données comprend 5 640 images, divisées en 47 catégories selon la perception humaine, avec 120 images dans chaque catégorie. Pour chaque image, une liste d'attributs clés et d'attributs communs est également fournie.
Utilisation directe :https://go.hyper.ai/aUYi3
Pour plus d'ensembles de données publics, veuillez visiter :
Tutoriels publics sélectionnés
1. Exécutez la démo du modèle TripoSR en ligne
TripoSR a été développé conjointement par Stability AI et Tripo AI. Il peut générer des modèles 3D de haute qualité à partir d'une seule image en 1 seconde et nécessite peu de puissance de calcul, de sorte que les utilisateurs ordinaires peuvent facilement l'utiliser sur des appareils locaux. Ce tutoriel a configuré l'environnement pour votre commodité.
Exécutez en ligne :https://go.hyper.ai/is9qe
2. Démonstration de génération de modèles gaussiens multi-vues de grande taille LGM
LGM, ou Large Multi-View Gaussian Model, est un cadre innovant permettant de générer des modèles 3D haute résolution à partir d'invites textuelles ou d'images à vue unique. Cette méthode peut générer des objets 3D en 5 secondes et augmenter la résolution d'entraînement à 512, permettant ainsi une génération de contenu 3D haute résolution. Ce tutoriel est une implémentation de démonstration de LGM.
Exécutez en ligne :https://go.hyper.ai/pFnhg
Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~
Articles de la communauté
Le premier rassemblement Meet AI Compiler Beijing aura lieu le 6 juillet 2024 dans la salle de conférence du premier étage de l'Institut de technologie informatique de l'Académie chinoise des sciences ! Pour ce Meetup, nous avons la chance d'avoir invité de nombreux experts seniors en compilateurs d'IA de l'Université Jiao Tong de Shanghai, de l'Institut de technologie informatique de l'Académie chinoise des sciences, de Microsoft Research Asia, etc. Ils vous apporteront de merveilleux discours d'ouverture et des tables rondes, et discuteront avec vous de l'application et des avancées de la technologie des compilateurs d'IA dans des scénarios pratiques.Cliquez sur « Lire le texte original » pour vous inscrire et participer !
Voir les informations complètes sur l'événement :https://go.hyper.ai/EA1uw
La semaine dernière, Apple a publié Apple Intelligence et introduit des mises à jour majeures pour iOS 18 et Siri. La collaboration entre Apple et OpenAI, dont on parlait auparavant, a finalement été officiellement annoncée. Siri, qui intègre ChatGPT, est devenu plus naturel, plus contextuel et plus personnalisé, et peut simplifier et accélérer les tâches quotidiennes. Cet article présente les mises à jour d'Apple Intelligence, de Siri et d'iOS 18, et trie également l'historique du développement de Siri, ce qui peut démontrer davantage l'importance de la mise à niveau des capacités d'IA d'Apple vers Siri.
Voir le rapport complet :https://go.hyper.ai/kWmHC
Une équipe formée conjointement par l'École d'informatique et de logiciels de l'Université de Shenzhen et le Centre de recherche sur la santé intelligente de l'Université polytechnique de Hong Kong a proposé un nouveau modèle de segmentation vidéo d'échocardiographie MemSAM. Le modèle atteint des performances de pointe avec un petit nombre d'indices ponctuels et des performances comparables à celles des méthodes entièrement supervisées avec des annotations limitées, réduisant considérablement les exigences d'indices et d'annotations requises pour les tâches de segmentation vidéo. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/2s73Q
Le Dr Jianmin Wang et d'autres chercheurs de l'Université Yonsei ont combiné l'apprentissage profond avec l'IA générative, en utilisant un réseau neuronal génératif basé sur Transformer pour apprendre et explorer l'ensemble conformationnel des complexes protéine-protéine, et apprendre les résidus clés qui affectent la conformation et le mécanisme dynamique des complexes protéine-protéine à partir de multiples trajectoires de dynamique moléculaire, fournissant des informations mécanistes sur la liaison protéine-protéine. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/MdgoV
Articles populaires de l'encyclopédie
1. Fusion de classement réciproque RRF
2. Modélisation du langage masqué (MLM)
3. Taux d'apprentissage
4. Détection d'objets de bout en bout en temps réel YOLOv10
5. Théorème de représentation de Kolmogorov-Arnold
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Aperçu de la diffusion en direct de la station B
Jeff Dean est un chercheur senior et informaticien chez Google, connu pour son travail de pionnier dans les systèmes distribués et l'intelligence artificielle, notamment le développement de MapReduce et TensorFlow, et est l'une des figures clés du développement technologique de Google. Cette semaine, Super Neuro TV diffusera en direct les discours et interviews de Jeff Dean.
Le tableau suivant est un aperçu du contenu sélectionné par l'éditeur↓↓↓
| date | temps | contenu |
| Lundi 17 juin | 18:00 | Jeff Dean sur les cinq tendances de l'apprentissage automatique |
| Mardi 18 juin | 18:00 | Que l'IA serve tout le monde |
| Mercredi 19 juin | 18:00 | La vision positive de Jeff Dean sur l'avenir de l'IA |
| Jeudi 20 juin | 18:00 | Discours de Jeff Dean à la Stanford Medical Big Data Conference |
| Vendredi 21 juin | 18:00 | Conférence de Jeff Dean sur l'apprentissage profond |
| Samedi 22 juin | 18:00 | Résidence Google Brain & Brain |
| Dimanche 23 juin | 18:00 | Jeff Dean explique comment utiliser l'apprentissage profond pour résoudre des problèmes |
Super Neuro TV diffuse en direct 24h/24 et 7j/7. Cliquez pour obtenir les « cornichons électroniques » dans le domaine de l'IA :
http://live.bilibili.com/26483094
Suivi unique des principales conférences universitaires sur l'IA :https://hyper.ai/events
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 300 ensembles de données publiques
* Comprend plus de 400 tutoriels en ligne classiques et populaires
* Interprétation de plus de 100 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








