Command Palette
Search for a command to run...
Candidat Au Meilleur Article CVPR 2024 ! L'Université De Shenzhen Et l'Université Polytechnique De Hong Kong Ont Publié Conjointement MemSAM : Application Du Modèle « Segment Everything » À La Segmentation Vidéo Médicale

Selon les statistiques de l’Organisation mondiale de la santé (OMS), les maladies cardiovasculaires sont la principale cause de décès dans le monde, faisant environ 17,9 millions de victimes chaque année, soit 321 % des décès dans le monde. L'échocardiographie est une technique de diagnostic par ultrasons pour les maladies cardiovasculaires et est largement utilisée dans la pratique clinique en raison de sa portabilité, de son faible coût et de sa nature en temps réel. Cependant,L'échocardiographie nécessite une évaluation manuelle par des médecins expérimentés, et la qualité de l'évaluation dépend en grande partie des connaissances professionnelles et de l'expérience clinique du médecin.Cela entraîne souvent de grandes différences inter- et intra-observateurs dans les résultats d’évaluation. Par conséquent, des méthodes d’évaluation automatisées sont nécessaires de toute urgence dans la pratique clinique.
Ces dernières années, de nombreuses méthodes d’apprentissage profond ont été proposées pour la segmentation de vidéos échocardiographiques. Cependant, ces méthodes ne peuvent toujours pas donner de résultats satisfaisants en raison de la faible qualité et des annotations limitées des vidéos échographiques. Récemment, un modèle visuel à grande échelle, Segment Anything Model (SAM), a reçu une grande attention et a obtenu un succès remarquable dans de nombreuses tâches de segmentation d'images naturelles.Cependant, la manière d’appliquer SAM à la segmentation vidéo médicale reste une tâche difficile.
Sur cette base, une équipe formée conjointement par l'École d'informatique et de logiciels de l'Université de Shenzhen et le Centre de recherche sur la santé intelligente de l'Université polytechnique de Hong Kong a publié un article intitulé « MemSAM : Taming Segment Anything Model for Echocardiography Video Segmentation » lors de la conférence de vision par ordinateur CVPR 2024. Dans l'article,Les chercheurs ont proposé un nouveau modèle de segmentation vidéo d'échocardiographie, MemSAM, qui applique le SAM aux vidéos médicales.

Le modèle utilise des mémoires contenant des informations spatio-temporelles comme indices pour la segmentation de l'image actuelle et utilise un mécanisme d'amélioration de la mémoire pour améliorer la qualité de la mémoire avant de la stocker. Des expériences sur des ensembles de données publics montrent que le modèle atteint des performances de pointe avec un petit nombre d'invites ponctuelles et atteint des performances comparables à celles des méthodes entièrement supervisées avec des annotations limitées, réduisant considérablement les exigences d'invite et d'annotation pour les tâches de segmentation vidéo.
Points saillants de la recherche :
- Cette étude utilise une mémoire contenant des informations spatio-temporelles comme signal pour la segmentation de l’image actuelle afin d’améliorer la cohérence de la représentation et la précision de la segmentation.
- Les chercheurs ont également proposé un module d’amélioration de la mémoire pour améliorer les souvenirs avant de les stocker, atténuant ainsi les effets néfastes du bruit de tache et des artefacts de mouvement pendant le repérage de la mémoire.
- Le nouveau modèle démontre des performances de pointe par rapport aux modèles existants, en particulier il atteint des performances comparables aux méthodes entièrement supervisées avec des annotations limitées.

Adresse du document :
https://github.com/dengxl0520/MemSAM
Ensembles de données : 2 ensembles de données d'échocardiographie accessibles au public
Les chercheurs ont utilisé deux ensembles de données d’échocardiographie largement utilisés et accessibles au public pour CAMUS La méthode est évaluée sur EchoNet-Dynamic :
- L'ensemble de données CAMUS contient 500 cas, y compris des vidéos de vue apicale 2D à deux chambres et à quatre chambres, et fournit également des annotations pour toutes les images.
- L'ensemble de données EchoNet-Dynamic contient 10 030 vidéos de vue apicale 2D à deux chambres. Chaque vidéo fournit la zone du ventricule gauche sous forme d'intégrale, avec uniquement les phases télédiastoliques (ED) et télésystoliques (ES) annotées.
Pour évaluer de manière exhaustive l’efficacité de la nouvelle méthode de segmentation vidéo semi-supervisée, les chercheurs ont adapté l’ensemble de données CAMUS en deux variantes : CAMUS-Full et CAMUS-Semi. CAMUS-Full utilise des annotations de toutes les images pendant la formation, tandis que CAMUS-Semi utilise uniquement des annotations des images de fin de diastole (ED) et de fin de systole (ES). Lors des tests, les deux ensembles de données sont évalués à l’aide d’annotations complètes.
Les chercheurs ont échantillonné uniformément des vidéos à partir de l’ensemble de données et les ont recadrées à 10 images chacune. Le recadrage garantit que l'image ED est la première image et l'image ES est la dernière image, et la résolution est ajustée à 256 × 256. L'ensemble de données CAMUS est divisé en un ensemble d'entraînement, un ensemble de validation et un ensemble de test dans un rapport de 7:1:2.
Architecture du modèle : les composants SAM et les composants de mémoire constituent le cadre global de MemSAM
Le cadre général du modèle MemSAM est illustré dans la figure ci-dessous.Il se compose de deux parties : le composant SAM et le composant Mémoire.
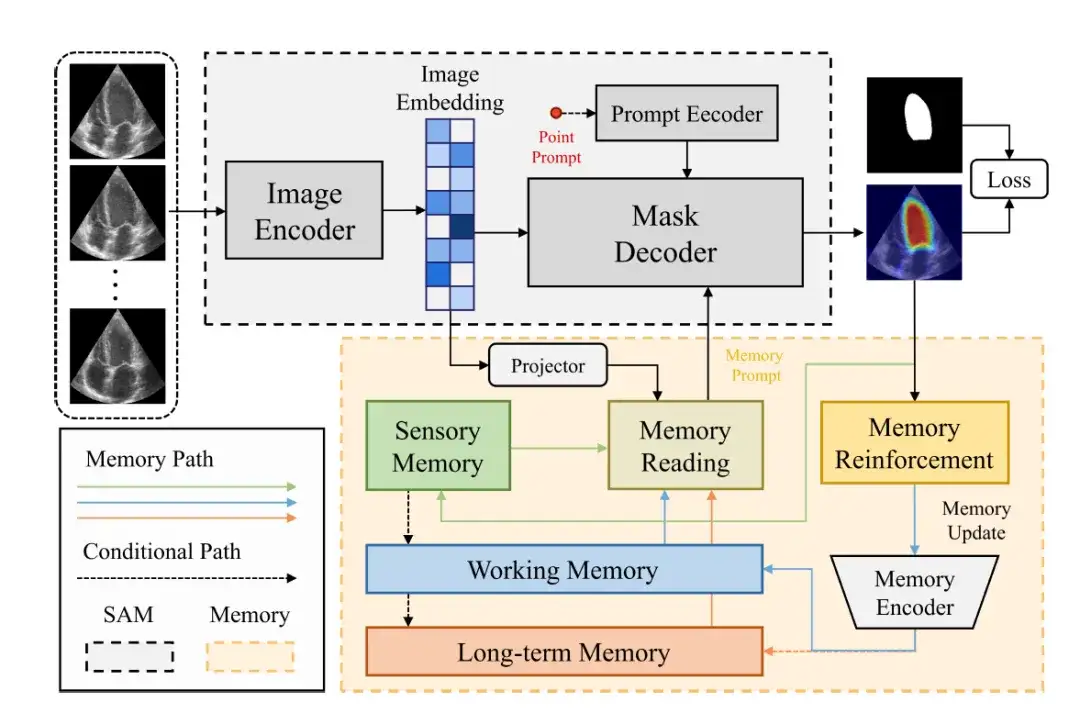
Le composant SAM utilise la même architecture que le SAM d'origine.Il se compose d'un encodeur d'image (Image Encoder), d'un encodeur d'invite (Prompt Encoder) et d'un décodeur de masque (Mask Decoder).
L'encodeur d'image utilise Vision Transformer (ViT) comme épine dorsale pour encoder l'image d'entrée dans un vecteur d'image (Image Embedding).
L'encodeur d'invite reçoit des invites externes, telles que des invites de points, et les encode dans une incorporation c-dimensionnelle. Par la suite, le décodeur de masque combine l'image et le vecteur d'indice pour prédire le masque de segmentation.
Dans ces composants, le vecteur d'image est mappé à l'espace des caractéristiques de la mémoire via une couche de projection, puis les chercheurs effectuent une lecture de la mémoire pour obtenir des invites de mémoire à partir de plusieurs mémoires de caractéristiques (telles que la mémoire sensorielle, la mémoire de travail et la mémoire à long terme) et les fournissent au décodeur de masque. Enfin, après avoir traversé le renforcement de la mémoire et l'encodeur de mémoire, la mémoire sera mise à jour.
La figure suivante montre plus de détails sur le processus de lecture de la mémoire, d'amélioration de la mémoire et de mise à jour de la mémoire :
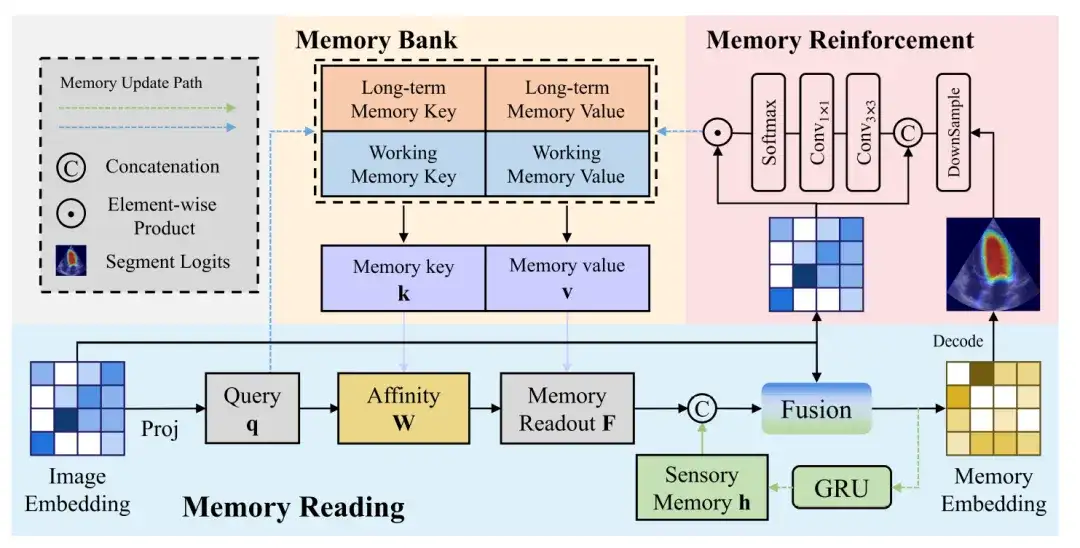
Lecture de mémoire
Le bloc de lecture de mémoire illustre le processus de génération d'un vecteur de mémoire à partir d'un vecteur d'image. Le vecteur d'image est projeté pour générer une requête, qui est ensuite interrogée par rapport à l'affinité de la valeur de mémoire pour obtenir la lecture de la mémoire. Enfin, la lecture de la mémoire est fusionnée avec la mémoire sensorielle et le vecteur d'image pour obtenir le vecteur de mémoire.
Amélioration de la mémoire
Par rapport aux images naturelles, les images ultrasonores contiennent des bruits plus complexes, ce qui signifie que les vecteurs d'image générés par l'encodeur d'image comportent inévitablement du bruit. Si ces fonctionnalités bruyantes sont mises à jour en mémoire sans aucun traitement, cela peut conduire à l’accumulation et à la propagation d’erreurs.
Afin d’atténuer l’impact du bruit sur la mise à jour de la mémoire, un module d’amélioration de la mémoire est nécessaire pour améliorer la discriminabilité des représentations de fonctionnalités en mémoire. Le bloc d’amélioration de la mémoire concatène d’abord le vecteur d’image et la carte de probabilité prédite, puis limite le champ récepteur de chaque pixel via une convolution 3 × 3 pour générer une fonction de pondération d’attention locale.
Mise à jour de la mémoire
Enfin, les caractéristiques de sortie à mettre à jour dans la banque de mémoire sont obtenues via le produit scalaire de la fonction Softmax et du vecteur image.
Résultats de recherche : MemSAM atteint des performances de pointe avec des annotations limitées
Pour valider les performances de MemSAM, les chercheurs ont largement sélectionné différents types de méthodes de comparaison, notamment des modèles de segmentation d’images traditionnels et des modèles médicaux. Les trois modèles de segmentation d'images traditionnels sont UNet basé sur CNN, SwinUNet basé sur Transformer et H2Former hybride CNN-Transformer. Les modèles SAM applicables au domaine médical incluent MedSAM, MSA, SAMed, SonoSAM et SAMUS. Parmi eux, SonoSAM et SAMUS se concentrent sur les images échographiques.
Tout d’abord, les résultats de la comparaison quantitative sont présentés dans le tableau suivant :
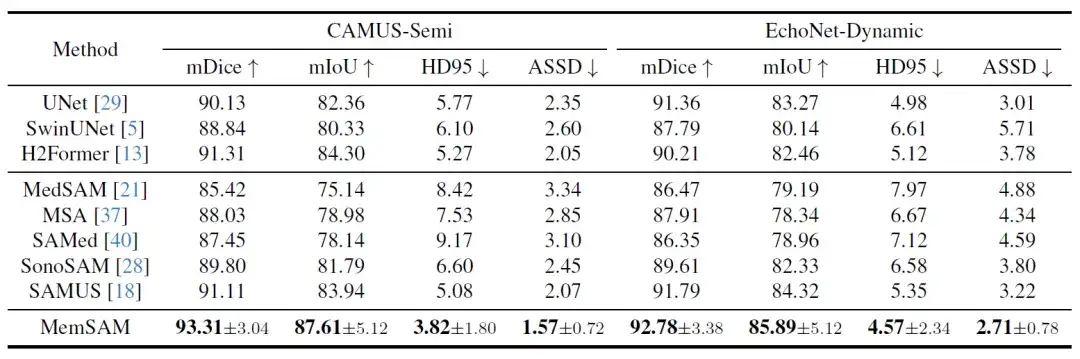
Parmi ces dernières méthodes, H2Former et SAMUS fonctionnent relativement bien sur les deux ensembles de données, grâce à l'architecture CNN-Transformer et à l'optimisation des images ultrasonores. Cependant, dans le cas d’annotations rares et sans exploiter les propriétés temporelles des vidéos, les modèles ci-dessus sont en retard par rapport à la méthode proposée dans cette étude.Les expériences vérifient que MemSAM atteint les meilleures performances avec des annotations limitées.
Pour évaluer davantage MemSAM, les chercheurs ont également comparé les ensembles de données CAMUS-Semi et CAMUS-Full dans le même contexte. Le résultat est montré dans la figure ci-dessous :
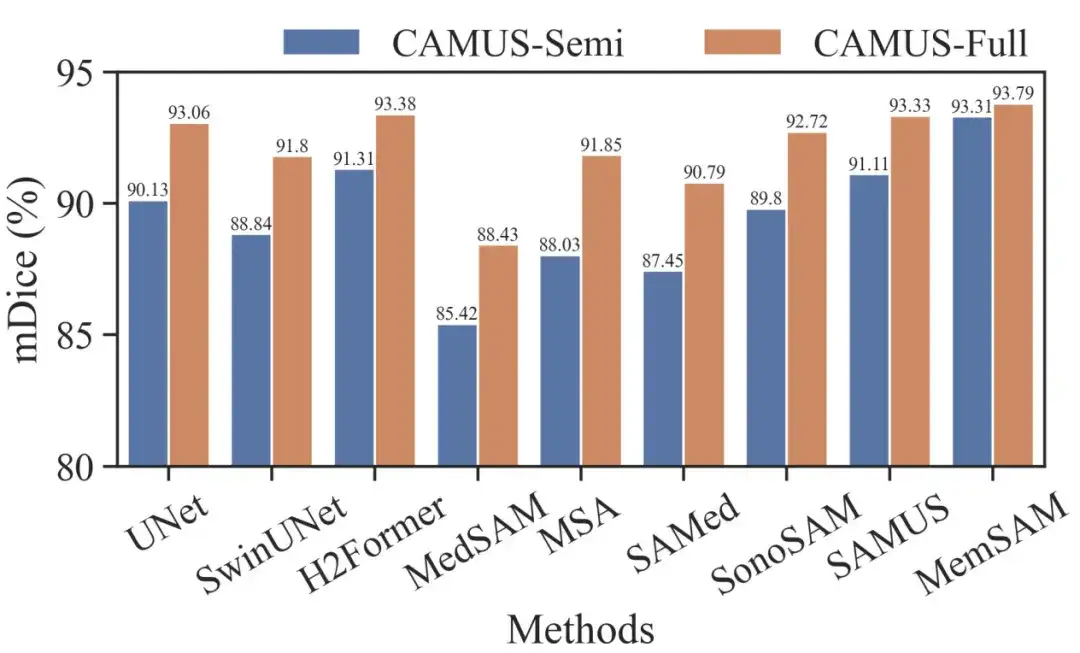
On peut constater que les méthodes traditionnelles comme UNet et H2Former, ainsi que les méthodes spécialisées en échographie comme SonoSAM et SAMUS, peuvent récupérer des résultats de segmentation décents lorsqu'elles reçoivent des annotations complètes. Bien que notre approche permette d’obtenir des gains plus faibles dans les environnements semi-supervisés et entièrement supervisés, elle surpasse néanmoins les autres concurrents dans les deux cas.
Il convient de noter que le modèle de base médical nécessite des repères par image sous supervision complète, tandis que MemSAM ne nécessite qu'un seul repère ponctuel.Les expériences vérifient que la méthode proposée atteint des performances comparables à celles des annotations complètes avec des étiquettes clairsemées et beaucoup moins d’indices externes.
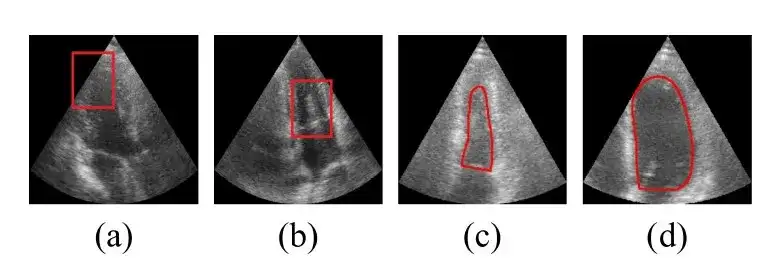
Vient ensuite le résultat de la comparaison qualitative. Les chercheurs fournissent des résultats de visualisation pour certains cas difficiles, comme le montre la figure ci-dessous :

Les images des lignes 1 et 2 ci-dessus contiennent du bruit de tache autour du ventricule gauche, ce qui induit en erreur certains modèles traditionnels et médicaux en l'identifiant à tort comme le bord du ventricule. Les lignes 3 et 4 contiennent des exemples avec des limites très floues, où presque tous les modèles comparés donnent des résultats qui vont au-delà des véritables limites ventriculaires, tandis que la méthode proposée décrit avec précision les limites.Ces résultats de visualisation démontrent que la méthode proposée est robuste pour gérer une mauvaise qualité d’image.
L'IA apporte de nouvelles idées à la prévention et au traitement des maladies cardiovasculaires
Les maladies cardiovasculaires sont une catégorie de maladies du cœur et des vaisseaux sanguins, notamment les maladies coronariennes, les maladies cérébrovasculaires, les maladies cardiaques rhumatismales et d’autres maladies. Dans la société moderne, la mauvaise alimentation, le manque d’activité physique, le tabagisme et la consommation d’alcool augmentent encore davantage le risque de maladies cardiovasculaires.
Ces dernières années, avec le développement de technologies telles que l’intelligence artificielle et le big data, « l’IA + les soins médicaux » sont entrés dans la voie rapide du développement. L’IA a fait d’énormes progrès dans le diagnostic et la prédiction des maladies cardiovasculaires. Par exemple, l’IA combinée à des données d’électrocardiogramme et d’imagerie cardiovasculaire peut permettre d’établir un diagnostic précis. L’IA combinée aux données d’imagerie cardiovasculaire et à d’autres données cliniques peut permettre un dépistage précoce et une prédiction des risques de maladies cardiovasculaires telles que les maladies coronariennes, les maladies cardiaques congénitales et l’insuffisance cardiaque.
Par exemple : une classification précise des bruits cardiaques est essentielle au diagnostic et à l’intervention précoces en cas de maladie cardiovasculaire. L'efficacité de l'auscultation artificielle du son cardiaque dépend toujours des connaissances professionnelles du médecin, mais cette situation évolue tranquillement. En novembre 2023, l'équipe de Pan Xiangbin de l'hôpital Fuwai de l'Académie chinoise des sciences médicales (hôpital Fuwai) a publié un article de recherche intitulé « Classification des bruits cardiaques basée sur les caractéristiques du bispectre et le mode Vision Transformer » en ligne dans l'Alexandria Engineering Journal.Cette étude a permis une classification binaire des bruits cardiaques basée sur l’extraction de caractéristiques inspirées du bispectre et sur un modèle de transformateur visuel.
Le modèle a démontré d’excellents résultats de classification dans l’ensemble de la population (y compris les patientes enceintes et non enceintes), avec des performances diagnostiques supérieures à celles des experts humains, démontrant un grand potentiel d’application.
En octobre 2023, de nouvelles données de recherche publiées dans la revue Clinical Medicine ont montré qu'en identifiant les signes de maladie coronarienne, tels que la calcification et les blocages, ainsi que les preuves de crises cardiaques antérieures, l'ECG-AI peut signaler certains risques des années plus tôt que les équations actuelles du calculateur de risques.
Tout récemment, une société britannique appelée Caristo Diagnostics a publié les résultats d’une étude clinique historique dans The Lancet.Leur technologie d’IA CaRi-Heart quantifie la gravité de l’inflammation des artères coronaires et prédit avec précision les maladies cardiaques.
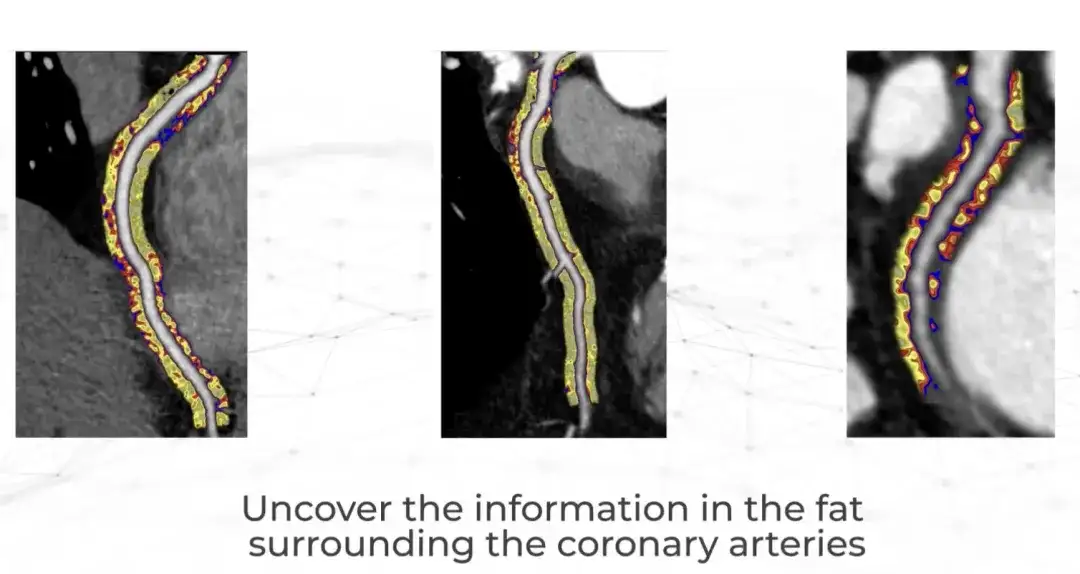
Caristo a été fondée en 2018 par des cardiologues de l'Université d'Oxford. Il y a plus de 50 ans, l'entreprise a fait une découverte majeure en matière de recherche : les crises cardiaques sont causées par une inflammation des artères coronaires, mais les cliniciens n'ont pas été en mesure d'observer et de mesurer l'inflammation lors d'examens cardiaques de routine.Désormais, la technologie CaRi-Heart peut être utilisée pour CTTA Extrayez ces informations de l'analyse.Il s’agit d’une avancée scientifique qui modifie fondamentalement l’approche traditionnelle de la prédiction, de la prévention et de la gestion des maladies cardiaques. Il est rapporté que CaRi-Heart a été mis en service clinique au Royaume-Uni, en Europe et en Australie.
En regardant vers l’avenir, l’intelligence artificielle a un énorme potentiel de développement dans le diagnostic et le traitement cliniques, en particulier dans la prévention et le traitement des maladies cardiovasculaires. Cela aidera les médecins à fournir aux patients un diagnostic précis et des conseils plus efficaces et plus fiables.
Références :
1.https://m.chinacdc.cn/jkzt/mxfcrjbhsh/jcysj/201909/t20190906_205347.html
2.https://mp.weixin.qq.com/s/daqoXwnxeZxw7xC6iw1h3A
3.https://www.drvoice.cn/v2/article/12166
4.https://36kr.com/p/280080595174








