Command Palette
Search for a command to run...
Déploiement En Un Clic De LLaMA 3 Chinese Chat, Y Compris l'ensemble De Données De Formation En Chinois ; Téléchargement De l'ensemble De Données Food2K, Comprenant 2 000 Catégories Et 1 Million d'images

La récente sortie open source de Llama 3 a enthousiasmé tout le monde dans le cercle de l'IA, mais sa prise en charge du chinois pur n'est pas très bonne et il ne peut pas passer de manière flexible à la langue correspondante pour répondre aux questions en chinois.
Cette semaine, hyper.ai a lancé le tutoriel de déploiement et de raisonnement de Llama 3 Chinese Chat, la version chinoise de Llama 3.Il résout efficacement la difficulté de « répondre aux questions chinoises en anglais » et rend la conversation plus naturelle et plus fluide.Le tutoriel a déployé le modèle et l'environnement. Il vous suffit d'ouvrir l'adresse API pour expérimenter l'inférence !
J'ai hâte, je vais l'essayer :
Le même ensemble de données de formation chinoises :
Du 27 au 31 mai, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels sélectionnés de haute qualité : 2
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juin : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de la version chinoise de Llama 3
Cet ensemble de données est une collection d'ensembles de données chinois Llama 3. Les données ont été traitées uniformément au format Firefly et peuvent être utilisées avec l'outil Firefly pour former directement le modèle chinois Llama 3.
Utilisation directe :https://go.hyper.ai/uJlfk
2. Grand corpus conversationnel chinois propre du LCCC
L'ensemble de données se compose principalement de deux parties : LCCC-base (6,8 millions de dialogues) et LCCC-large (12 millions de dialogues). L’équipe de recherche a conçu un processus rigoureux de filtrage des données pour garantir la qualité des données de conversation dans l’ensemble de données. L'ensemble de données filtré peut faciliter la recherche sur la modélisation de conversations textuelles courtes.
Utilisation directe :https://go.hyper.ai/bDzEG
3. Grand ensemble de données de reconnaissance des aliments Food2K
Food2K est un ensemble de données de reconnaissance alimentaire à grande échelle contenant 2 000 catégories d'aliments et plus d'un million d'images.
Utilisation directe : https://go.hyper.ai/TpfUJ
4. Ensemble de données de paires image-texte COYO-700M
COYO-700M contient 747 millions de paires image-texte et de nombreux autres méta-attributs, collectant de nombreux textes alternatifs informatifs et leurs paires d'images associées dans des documents HTML.
Utilisation directe : https://go.hyper.ai/fWI1i
5. Ensemble de données de détection de cibles de pont d'images de télédétection à grande échelle GLH-Bridge
L'ensemble de données contient 6 000 images de télédétection grand format à ultra haute résolution, avec près de 60 000 instances de ponts sur différents arrière-plans annotées manuellement. Le format de l'image est de 2048 × 2048-16384 × 16384 pixels et comporte deux ensembles d'étiquettes de détection de cible : boîte de rotation et boîte horizontale.
Utilisation directe : https://go.hyper.ai/cHPeb
6. Ensemble de données de dialogue multi-tours multimodal à domaine ouvert MMDialog
L'ensemble de données est un ensemble de données de dialogue multimodal à domaine ouvert à grande échelle, contenant 1,08 million de sessions de dialogue complètes, plus de 4 000 sujets de dialogue et 1,53 million d'images non répétées, avec une moyenne de 2,59 images par session de dialogue.
Utilisation directe : https://go.hyper.ai/iAbI2
7. Ensemble de données sur le diabète des Indiens Pima
L'ensemble de données provient à l'origine de l'Institut national du diabète et des maladies digestives et rénales, et son objectif est de prédire de manière diagnostique si un patient est diabétique en fonction de certaines mesures diagnostiques incluses dans l'ensemble de données.
Utilisation directe : https://go.hyper.ai/XqJXe
8. Grand échantillon de données LamaH-CE sur l'hydrologie et les sciences environnementales d'Europe centrale
LamaH-CE contient des séries chronologiques de ruissellement et de météorologie pour 859 bassins versants mesurés ainsi que divers attributs (bassins versants). Les séries chronologiques hydrométéorologiques sont disponibles avec une résolution temporelle quotidienne et horaire et incluent des marqueurs de qualité. Toutes les séries chronologiques météorologiques et la plupart des séries chronologiques d’écoulement des cours d’eau s’étendent sur plus de 35 ans.
Utilisation directe :https://go.hyper.ai/UPZvA
9. CAMELS-GB Ensemble de données sur les propriétés des bassins versants et les séries chronologiques hydrométéorologiques du Royaume-Uni
Cet ensemble de données fournit des séries chronologiques hydrométéorologiques et des attributs paysagers pour 671 bassins versants au Royaume-Uni. Il rassemble les débits fluviaux, les propriétés des bassins versants et les limites des bassins versants à partir des archives nationales des débits fluviaux du Royaume-Uni et d'un nouvel ensemble de séries chronologiques météorologiques et de propriétés des bassins versants.
Utilisation directe :https://go.hyper.ai/KA29l
10. Ensemble de données d'édition d'images basé sur les instructions HQ-Edit
HQ-Edit contient environ 200 000 exemples d'édition, chacun avec une image d'entrée, une image de sortie et des instructions d'édition détaillées.
Utilisation directe :https://go.hyper.ai/xjahh
Pour plus d'ensembles de données publics, veuillez visiter:
Tutoriels publics sélectionnés
1. Déploiement en un clic de la démo Llama 3-Chinese-Chat-8b
Le modèle utilisé dans ce tutoriel est la première version chinoise de Llama 3, qui est un modèle de langage avec des instructions affinées pour les utilisateurs chinois et anglais, et dispose de multiples fonctionnalités telles que le jeu de rôle et l'utilisation d'outils. Il suffit de cloner et de démarrer le conteneur, puis de copier directement l'adresse API générée pour expérimenter l'inférence sur le modèle.
Exécutez en ligne :https://go.hyper.ai/i3r7D
Latte est un modèle innovant de génération de vidéos qui a été rendu open source en novembre 2023. En tant que premier DiT vidéo Vincent open source au monde, Latte a obtenu des résultats prometteurs. Ce tutoriel est une démo du projet Latte.
Exécutez en ligne : https://go.hyper.ai/LFfmt
Aperçu de la diffusion en direct de la station B
Apple organisera la WWDC 2024 du 10 au 14 juin. Afin d'aider tout le monde à obtenir des informations approfondies sur Apple, la Super Neurological B Station Live Room continuera de diffuser des vidéos « Apple Special », couvrant : les conférences WWDC au fil des ans, les interviews de dirigeants, les documentaires connexes et d'autres contenus riches.À ce moment-là, Chao Shenjing le diffusera également en direct sur Video Account et Bilibili, alors prenez rendez-vous maintenant et ne le manquez pas~

Le tableau suivant est un aperçu du contenu de la diffusion en direct de la semaine prochaine sélectionné par l'éditeur↓↓↓
| date | temps | contenu |
| 1er juin Lundi | 18:00 | Steve Jobs |
| Mardi 2 juin | 18:00 | Qu'est-ce qui fait qu'une pomme est une pomme ? |
| Mercredi 3 juin | 18:00 | Entretien avec Steve Jobs contre Bill Gates |
| Jeudi 4 juin | 18:00 | Première sortie de l'iPhone |
| Vendredi 5 juin | 18:00 | Histoire de Steve Jobs |
| Samedi 6 juin | 18:00 | Comment Apple a survécu à la quasi-faillite |
| Dimanche 7 juin | 18:00 | L'histoire de Tim Cook |
Super Neuro TV diffuse en direct 24h/24 et 7j/7. Cliquez pour obtenir les « cornichons électroniques » dans le domaine de l'IA :
http://live.bilibili.com/26483094
Articles de la communauté
La semaine dernière, l'Administration météorologique chinoise a publié pour la première fois le « Catalogue de données spéciales pour la formation de grands modèles météorologiques d'intelligence artificielle », qui rassemble d'énormes quantités de données météorologiques. Le catalogue est désormais disponible en téléchargement sur le site officiel du Bureau météorologique. De plus, afin d'aider tout le monde à comprendre et à utiliser les ressources de données pertinentes, HyperAI a également compilé cette semaine 10 ensembles de données de catastrophes météorologiques de haute qualité pour mieux promouvoir les progrès de la recherche connexe et ouvrir un nouveau chapitre dans la recherche météorologique.
Obtenez des informations détaillées :https://go.hyper.ai/kK87m
L'équipe d'Ouyang Chaojun de l'Institut des risques de montagne et de l'environnement de Chengdu, Académie chinoise des sciences, a proposé un modèle de prévision du ruissellement et des inondations basé sur l'IA, ED-DLSTM. En codant les propriétés statiques du bassin versant et les facteurs météorologiques, et en utilisant les données de plus de 2 000 stations hydrologiques à travers le monde pour la formation des modèles, ils ont tenté de résoudre le problème de la prévision du ruissellement dans les bassins versants avec et sans données surveillées dans le monde entier. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/eG6H5
L'Université Tsinghua, l'Université du Zhejiang, l'Université Stanford, l'Université Brown, l'Université Johns Hopkins et d'autres universités nationales et étrangères ont mené des recherches pertinentes sur les interfaces cerveau-ordinateur. Cet article commence par le concept et présente les trois principales formes de mise en œuvre de l'interface cerveau-ordinateur, des cas de recherche spécifiques d'universités célèbres du pays et de l'étranger, l'éthique et la sécurité de l'interface cerveau-ordinateur, etc.
Voir le rapport complet :https://go.hyper.ai/W3pPf
L'équipe dirigée par Ge Jian, chercheur à l'Observatoire astronomique de Shanghai de l'Académie chinoise des sciences, a utilisé des méthodes d'apprentissage profond pour rechercher des lignes d'absorption de carbone neutre dans les données publiées par le Sloan Sky Survey III, révélant le mystère de la composition des nuages de gaz froid dans les premières galaxies et découvrant 107 exemples de lignes d'absorption de carbone neutre dans l'univers primitif. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/qirkz
Articles populaires de l'encyclopédie
1. Époque
2. Champ de rayonnement neuronal (NeRF)
3. Loi d'échelle
4. Détection d'objets de bout en bout en temps réel YOLOv10
5. Réseaux de Kolmogorov-Arnold
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
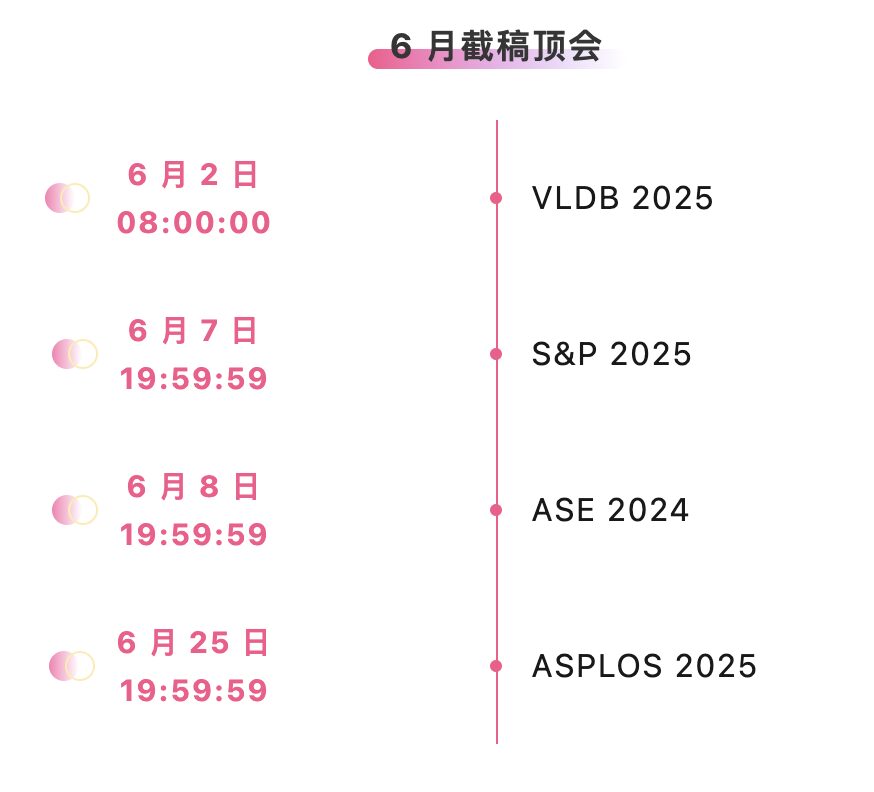
Suivi unique des principales conférences universitaires sur l'IA :
https://hyper.ai/events
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 200 ensembles de données publiques
* Comprend plus de 300 tutoriels en ligne classiques et populaires
* Interprétation de plus de 100 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








