Command Palette
Search for a command to run...
En Analysant Et En Formant Les Données De Plus De 2 000 Stations Hydrologiques À Travers Le Monde, l'équipe De l'Académie Chinoise Des Sciences a Publié ED-DLSTM Pour Réaliser La Prévision Des Inondations Dans Les Zones Sans Données De surveillance.

Alors que le changement climatique mondial se poursuit, les inondations deviennent de plus en plus fréquentes. Un rapport publié conjointement par le Bureau des Nations Unies pour la réduction des risques de catastrophe et le Centre de recherche sur l'épidémiologie des catastrophes de l'Université de Louvain en Belgique a souligné :Au cours des 20 dernières années, le nombre de catastrophes liées aux inondations dans le monde a plus que triplé, passant de 1 389 à 3 254, représentant 401 % de toutes les catastrophes et affectant 1,65 million de personnes.
Les inondations peuvent causer d’énormes pertes humaines et matérielles. En avril de cette année, les inondations et les catastrophes géologiques ont causé des dommages à divers degrés à 1,598 million de personnes dans 17 provinces (régions et villes), dont le Jiangxi et le Guangdong. 24 personnes sont mortes ou ont disparu, 140 300 hectares de cultures ont été touchés et les pertes économiques directes se sont élevées à 11,98 milliards de yuans. Les pertes dues aux catastrophes ont été les plus lourdes au cours de la même période au cours des dix dernières années.
Il est essentiel de savoir prévoir efficacement le débit des crues pour réduire le risque de catastrophes liées aux inondations. Au cours des dernières décennies, la prévision des débits de crue basée sur les processus hydrologiques a fait des progrès significatifs, mais les résultats de prévision des méthodes actuelles dépendent encore largement des données de surveillance et de l’étalonnage des paramètres. En fait, il n’existe pas de données de surveillance pour les bassins situés au-dessus de 95% dans le monde.La résolution des problèmes de prévision du ruissellement et des inondations dans les zones où les données de surveillance sont inexistantes ou insuffisantes a toujours été un problème de longue date auquel le domaine de l’hydrologie est confronté.
En avril 2024, l'équipe d'Ouyang Chaojun de l'Institut des risques de montagne et de l'environnement de Chengdu, Académie chinoise des sciences, a publié un article intitulé « Apprentissage approfondi pour la prévision des débits et des inondations interrégionaux à l'échelle mondiale » dans The Innovation.Un modèle de prévision des crues basé sur l'IA ED-DLSTM est proposé. En codant les propriétés statiques du bassin versant et les facteurs météorologiques, le modèle est formé à l'aide de données provenant de plus de 2 000 stations hydrologiques à travers le monde, tentant de résoudre le problème de prévision du ruissellement dans les bassins versants avec et sans données surveillées dans le monde entier.
Points saillants de la recherche :
- Le modèle ED-DLSTM fonctionne bien dans la prévision des inondations dans les deux bassins avec et sans données de surveillance.
- Pour la première fois, plusieurs modèles d'IA hydrologiques ont été formés et comparés dans le monde entier
- L’encodage des attributs spatiaux améliore considérablement le pouvoir prédictif des séries temporelles et explique bien la transférabilité.
Adresse du document :
https://doi.org/10.1016/j.xinn.2024.100617
Ensemble de données : Données de bassin présentant des différences de distribution significatives
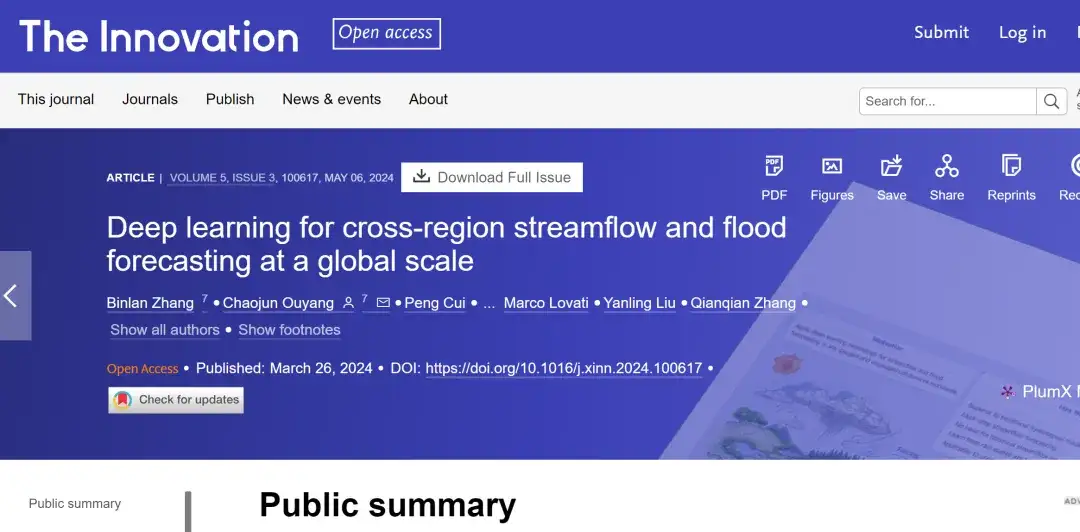
L'ensemble de données de formation utilisé dans cette étude provient de 2 089 bassins fluviaux aux États-Unis (482 bassins fluviaux), au Royaume-Uni (406 bassins fluviaux), en Europe centrale (461 bassins fluviaux), au Canada (740 bassins fluviaux), etc., comme le montre la figure suivante :
Adresse de téléchargement du jeu de données :
- Chameaux américains :https://go.hyper.ai/nCkDT
- Chameaux-GB :https://go.hyper.ai/DdUEf
- Europe centrale LamaH-CE :https://go.hyper.ai/rMHSO
- CAMELS-CL, CHILI :https://camels.cr2.cl/
- HYSETs canadiens :https://go.hyper.ai/l4etG
En général, les précipitations globales et la teneur en humidité du sol dans la région de l’Est sont généralement plus élevées que celles de l’Ouest des États-Unis et du Canada ; l’ouest du Royaume-Uni et le nord des Highlands écossais présentent généralement une humidité moyenne annuelle du sol et des précipitations plus élevées, tandis que la variabilité des autres variables est relativement faible ; en Europe centrale, la plupart des bassins fluviaux de la région autrichienne sont situés en altitude, avec de fortes précipitations et de basses températures ; Les montagnes Rocheuses traversent les États-Unis et le Canada, et les bassins voisins sont élevés en terrain, avec des précipitations et une teneur en humidité du sol élevées et des températures basses. Les effets complexes de l’évaporation et de la fonte des neiges rendent le coefficient de variation du ruissellement encore plus important.
Selon les chercheurs,Les différences de distribution des bassins versants régionaux mentionnés ci-dessus sont importantes et la variabilité spatiale est suffisamment importante pour garantir la diversité des données, ce qui est suffisant pour vérifier la capacité de prévision du débit interrégional (CSF) de l'ED-DLSTM.
Architecture du modèle : nouveau modèle intégré spatio-temporel interrégional ED-DLSTM
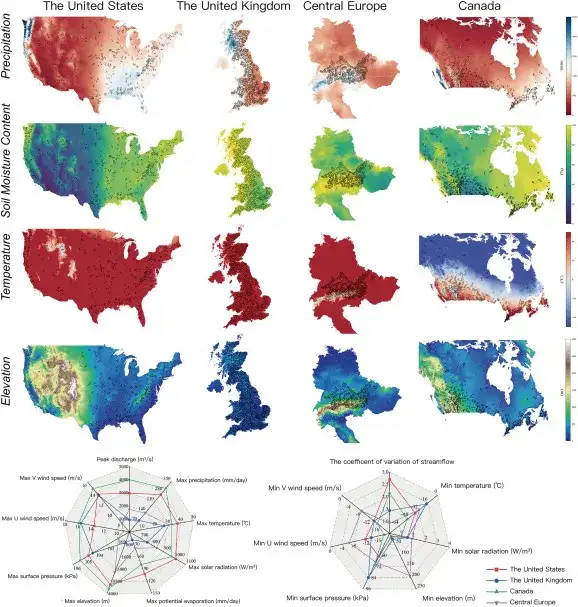
Dans cet article, les chercheurs ont proposé un nouveau modèle d’intégration spatio-temporelle interrégionale ED-DLSTM.Le modèle combine des attributs spatiaux statiques et des attributs de forçage temporel.Pour réaliser une prévision du trafic interrégional, la figure suivante montre l'architecture globale du modèle ED-DLSTM :
Le modèle ED-DLSTM utilise une structure encodeur-décodeur.Il comprend deux sous-modèles fonctionnant de manière symbiotique et est plus adapté à la capture des relations entre les bassins globaux et locaux grâce à une modélisation conjointe. Comme le montre la figure ci-dessus, l’entrée du modèle est constituée de données multimodales et les données d’attribut de grille statique spatiale d’entrée forment une matrice relativement clairsemée.
dans,L'encodeur combine des attributs statiques avec des données de forçage.Les données statiques comprennent les modèles numériques d’élévation (MNE), l’étendue de la couverture neigeuse, la teneur en humidité du sol, la profondeur des eaux souterraines, l’évapotranspiration potentielle, l’indice de sécheresse et la géométrie du lit des rivières. Ces attributs guident le modèle pour distinguer le comportement hydrologique de différentes régions. Les données forcées comprennent les précipitations, le rayonnement solaire, la température de l’air, la température du point de rosée, la pression de surface, les vitesses du vent d’est et du nord. Ces données ont une résolution temporelle de 24 heures.
Les informations statiques utilisent la convolution ordinaire pour intégrer les canaux, et la convolution résiduelle est utilisée pour extraire les propriétés statiques spatiales. Ensuite, le regroupement pyramidal spatial (SPP) est utilisé pour mapper les informations matricielles de différentes régions dans un espace fixe de haute dimension, codant ainsi spatialement des régions spécifiques. Par la suite, le vecteur codé est utilisé comme couche d’état initiale de l’unité LSTM.
Le décodeur est chargé de mapper les fonctionnalités de haut niveau aux valeurs de trafic prédites à l'aide d'une couche LSTM inversée.Les chercheurs ont choisi d'effectuer la cartographie du trafic dans la dernière unité LSTM car les informations complètes du modèle Seq2Seq doivent être décodées à la fin, et cette couche de décodage peut capturer la tendance des informations à l'envers. Les chercheurs peuvent coder et décoder différents comportements de réponse hydrologique pour différents bassins versants séparément.
En fin de compte, le réseau apprend la relation de cartographie des séries chronologiques dynamiques au débit observé sous des attributs statiques régionaux, fournissant ainsi des capacités CSF cohérentes, permettant au modèle de « reconnaître » de manière abstraite les caractéristiques de réponse hydrologique de différents bassins.
Résultats de la recherche : le modèle ED-DLSTM possède d'excellentes capacités de prédiction et de généralisation
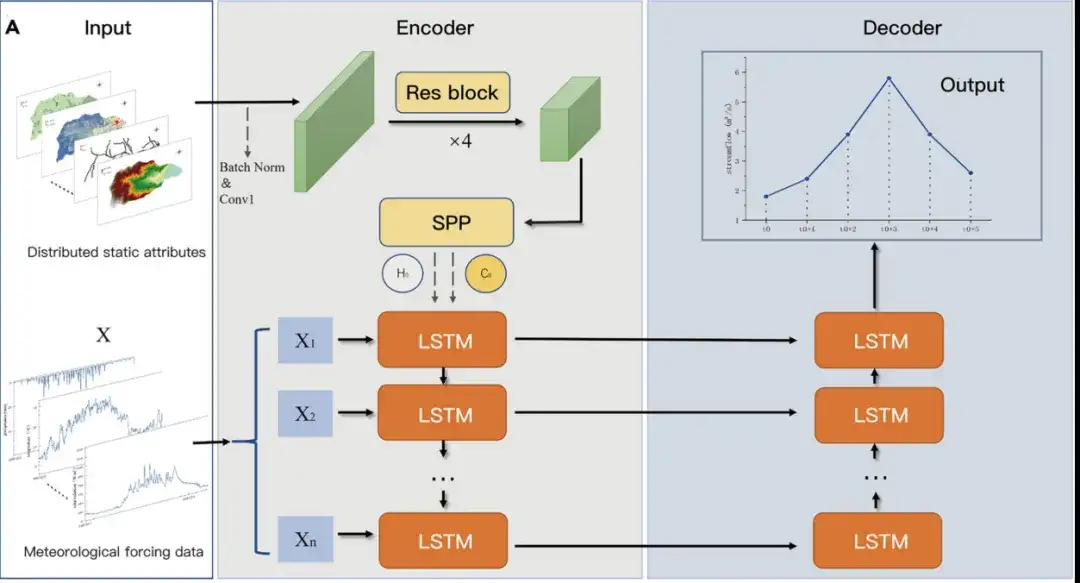
Dans un premier temps, les chercheurs ont procédé à une évaluation comparative de la crédibilité de prédiction du modèle ED-DLSTM du 1er janvier 2010 au 1er janvier 2012 et l’ont évaluée quantitativement à l’aide de l’efficacité de Nash-Sutcliffe (NSE).
- NSE (la plage de valeurs est (-∞, 1]) est utilisée pour évaluer les résultats de simulation des modèles hydrologiques (plus la valeur NSE est proche de 1, plus les résultats de simulation du modèle sont cohérents avec les observations réelles, et la valeur NSE inférieure à 0 indique que les résultats de simulation du modèle sont médiocres)
Comme le montre la figure ci-dessus :
- Aux États-Unis, 438 des 482 bassins versants analysés présentaient des NSE supérieurs à 0, avec un NSE moyen de 0,78 et un NSE médian de 0,80.
- Dans la région canadienne, 695 des 740 bassins versants analysés présentaient des NSE supérieurs à 0, avec un NSE moyen de 0,80 et un NSE médian de 0,82.
- Au Royaume-Uni, 391 des 406 bassins versants analysés présentaient des NSE supérieurs à 0, avec un NSE moyen de 0,68 et un NSE médian de 0,70.
- En Europe centrale, 433 des 461 bassins fluviaux étudiés ont des NSE supérieurs à 0, avec un NSE moyen de 0,73 et un NSE médian de 0,79.
Dans l'ensemble,Les bassins versants avec des précipitations plus élevées ou des coefficients de ruissellement plus importants produisent généralement de meilleurs résultats de prévision. Il convient de noter que le NSE moyen des bassins versants 81.8% est supérieur à 0,6, soulignant les excellentes capacités de prédiction et de généralisation du modèle ED-DLSTM.
Sur la base des modèles pré-entraînés des quatre régions ci-dessus (hémisphère nord), les chercheurs ont fait des prédictions pour 160 bassins nouveaux et inconnus au Chili (hémisphère sud) (sans aucune formation de données de surveillance historiques) pour tester la capacité de prédiction du modèle dans les bassins sans données de surveillance. Les résultats sont présentés dans la figure ci-dessous :
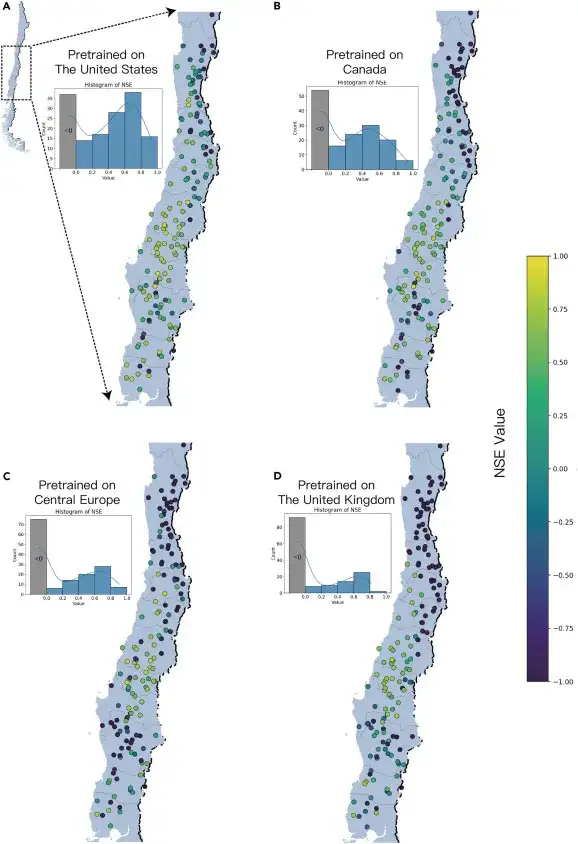
Lorsque ED-DLSTM a été déployé directement dans la nouvelle région du Chili, le modèle pré-entraîné aux États-Unis a montré que le NSE était supérieur à 0 dans 76,9% de bassins versants ; le modèle pré-entraîné au Canada a atteint un NSE supérieur à 0 dans 66,2% de bassins versants; le modèle pré-entraîné en Europe centrale a atteint un NSE supérieur à 0 dans 53,1% de bassins versants ; et le modèle pré-entraîné au Royaume-Uni a obtenu les pires résultats, avec seulement 42,5% de bassins versants ayant un NSE supérieur à 0.
Les résultats de prédiction de différents modèles pré-entraînés ont montré une forte cohérence dans la distribution spatiale, démontrant le grand potentiel de l'IA pour la prévision du débit d'eau et des inondations dans les bassins fluviaux non mesurés.
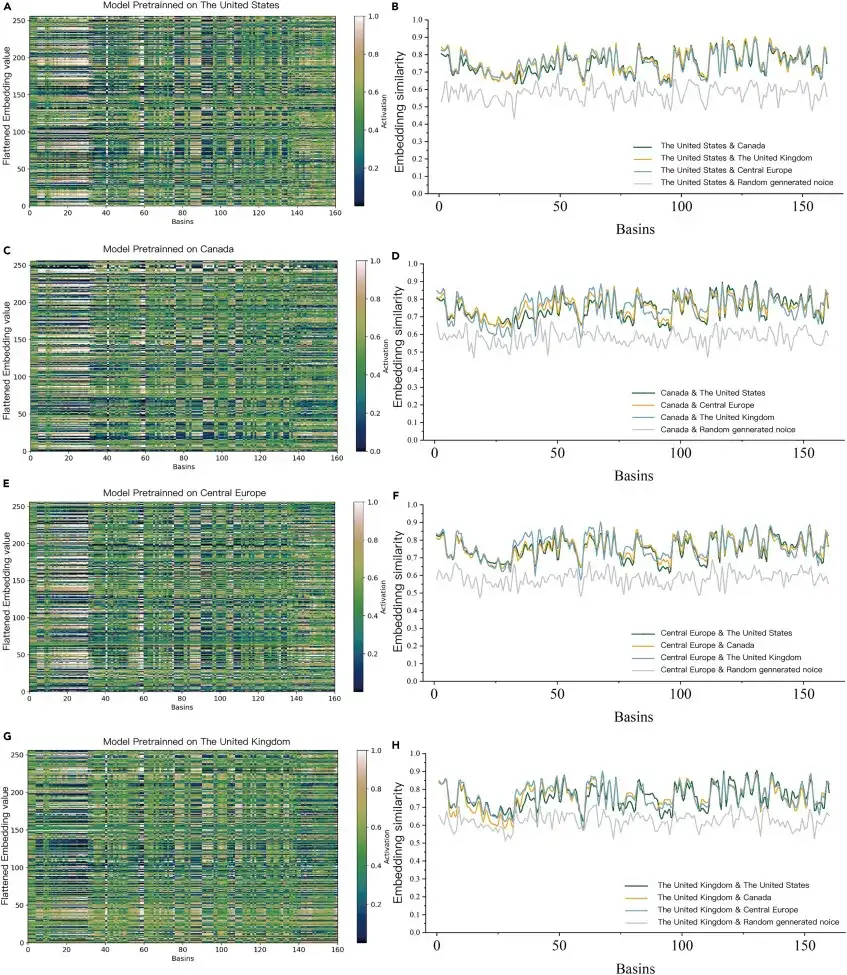
Lorsque le modèle pré-entraîné a été utilisé pour prédire 160 bassins versants au Chili sans données de surveillance, les caractéristiques de chaque bassin versant ont été visualisées (côté gauche de la figure ci-dessous) et la similarité analysée (côté droit de la figure ci-dessous) à l'aide de l'encodeur ED-DLSTM. Il a été constaté que la similarité d'encodage moyenne entre les modèles pré-entraînés était 38,4% supérieure à celle du bruit aléatoire, indiquant que la couche d'intégration d'ED-DLSTM n'est pas un signal aléatoire désordonné, mais une information de caractéristiques de haute dimension reconnue et utilisée par le modèle.Cela prouve que l’IA peut apprendre des « connaissances hydrologiques » dans différents bassins fluviaux.
IA + Hydrologie, promouvoir le développement d'une conservation intelligente de l'eau
La prévision des inondations est l’une des branches importantes de l’hydrologie. En parlant d’hydrologie, mon pays dispose déjà de mesures des précipitations et du niveau de l’eau depuis la période pré-Qin. Durant la période des Royaumes combattants, la « Loi foncière » de l'État de Qin stipulait que les fonctionnaires locaux devaient signaler en temps opportun les précipitations et le nombre d'acres de terres qui en avaient bénéficié et qui en avaient été affectées. Depuis lors, toutes les dynasties ont eu un système de signalement des inondations.
Les prévisions hydrologiques constituent une base importante pour la prise de décisions en matière de contrôle des inondations et de lutte contre la sécheresse, d’utilisation rationnelle des ressources en eau, de protection de l’environnement écologique et d’exploitation et de gestion des projets de conservation de l’eau et d’hydroélectricité.Les méthodes traditionnelles de prévision hydrologique utilisent principalement des modèles hydrologiques axés sur les processus, combinés à l’hydraulique, pour simuler des processus physiques complexes. Cependant, des données physiques de haute qualité, des outils mathématiques complexes et un grand nombre d’hypothèses simplifiées posent des défis en matière d’étalonnage et de vérification.Avec le développement de la technologie de l’intelligence artificielle et des sujets interdisciplinaires, de nombreux chercheurs ont mené des recherches approfondies sur les modèles de prévision hydrologique basés sur l’intelligence artificielle.
En 2019, une équipe de recherche du Laboratoire clé d'État des ressources en eau et de l'ingénierie hydroélectrique de l'Université de Wuhan a proposé un réseau d'apprentissage profond qui combine le réseau neuronal à mémoire à long terme LSTM avec l'apprentissage par lots, la régularisation et le neurone d'abandon, et l'a appliqué à la prévision des crues du réservoir des Trois Gorges. À partir de l'évaluation complète des quatre indicateurs du taux de qualification des prévisions, de l'erreur relative du pic de crue, de l'erreur quadratique moyenne et du degré d'ajustement de référence, on peut voir que par rapport au réseau neuronal statique BPNN et au réseau neuronal dynamique NARX, le réseau neuronal à mémoire à long terme LSTM combiné à trois algorithmes auxiliaires d'apprentissage profond a efficacement amélioré la précision des prévisions de la crue entrante du réservoir des Trois Gorges.
En 2020, une équipe de recherche de la Northwestern Polytechnical University a travaillé avec le Yellow River Conservancy Research Institute pour numériser l'annuaire hydrologique du fleuve Jaune et compiler une variété de facteurs, notamment le sol, le climat, la topographie et la géologie.Les premières données hydrologiques systématiques du bassin du fleuve Jaune en Chine ont été établies.En termes d'algorithmes de modélisation, ils ont réalisé des percées dans le modèle de prédiction intelligente à site unique, ont été les pionniers d'un modèle de prédiction intelligente de groupe de sites et ont surmonté l'un des dix défis majeurs dans le domaine de l'hydrologie, à savoir la prévision des inondations dans les zones où les données historiques sont manquantes. Cela a considérablement amélioré la précision des prévisions d’inondations et prolongé la période de prévision. Des algorithmes de prévision intelligents ont été appliqués avec succès aux principales zones productrices de sable du plateau de Loess, aux zones non contrôlées de Sanmenxia à Huayuankou dans les cours moyen et inférieur du fleuve Jaune, et à Tangnaihai dans le cours supérieur du fleuve Jaune, améliorant considérablement les capacités de prévision des inondations.
En mars 2024, Grey Nearing et ses collègues de l'équipe de prévision des inondations de Google Research ont développé un modèle d'IA capable de prédire le ruissellement quotidien dans les bassins non jaugés sur une période de prévision de 7 jours en l'entraînant à l'aide de 5 680 jauges existantes. Ils ont ensuite testé le modèle d’IA par rapport au Global Flood Alert System (GloFAS), le principal logiciel de prévision des inondations à court et à long terme au monde.
Les résultats montrent que la précision des prévisions du modèle le jour même est comparable, voire supérieure, à celle des systèmes actuels. De plus, la précision du modèle dans la prédiction d’événements météorologiques extrêmes avec une fenêtre de retour de cinq ans est comparable ou supérieure à la précision de GloFAS dans la prédiction d’événements avec une fenêtre de retour d’un an. L'article de recherche pertinent, intitulé « Prévision mondiale des inondations extrêmes dans les bassins versants non jaugés », a été publié dans la revue scientifique faisant autorité Nature. (Cliquez ici pour un rapport détaillé : Le modèle de prévision des inondations de Google apparaît à nouveau dans Nature, battant le système n°1 mondial et couvrant plus de 80 pays)

Aujourd'hui, la conservation intelligente de l'eau est passée de l'Internet des objets d'origine à l'Internet intelligent, c'est-à-dire que les appareils IoT collectent des données, l'IA analyse et prédit en fonction des données, et renvoie les résultats de prédiction au personnel concerné en temps réel pour achever l'évacuation des personnes et la protection des biens publics avant que les inondations ne se produisent. À l'avenir, la conservation intelligente de l'eau basée sur le développement de la technologie de l'IA continuera de promouvoir l'intelligence de la planification de la conservation de l'eau, de la construction de projets, de la gestion des opérations et des services sociaux, d'améliorer l'efficacité de l'utilisation des ressources en eau et la capacité de prévenir les catastrophes liées à l'eau et à la sécheresse, et d'améliorer l'environnement aquatique et l'écologie de l'eau.
Références :
1.https://mp.weixin.qq.com/s/sKPl55AEVf9GoXsLv0-8Hg
2.https://www.hanspub.org/journal/PaperInformation?paperID=28786








