Command Palette
Search for a command to run...
Les Dernières Avancées De L’équipe AI4S De Fei-Fei Li : 16 Technologies Innovantes, Couvrant La biologie/les matériaux/les Soins médicaux/le Diagnostic…

Il n'y a pas longtemps,Le centre de recherche en intelligence artificielle (HAI) Human-Center de l'université de Stanford a publié le « Rapport sur l'indice d'intelligence artificielle 2024 ».En tant que septième chef-d'œuvre de Stanford HAI, ce rapport de 502 pages suit de manière exhaustive les tendances de développement de l'intelligence artificielle mondiale en 2023. Par rapport aux années précédentes, le champ de recherche a été élargi pour couvrir les tendances fondamentales telles que la technologie de l'IA, la perception publique de la technologie de l'IA et la dynamique politique entourant son développement, et des prédictions ont été faites sur les tendances futures de développement de l'IA.

Le philosophe John Etchemend (à gauche) co-dirige
La partie la plus accrocheuse de ce rapport est le chapitre nouvellement ajouté :Explorez l’impact profond de l’intelligence artificielle dans la science et la médecine.Le rapport présente les brillantes réalisations de l’IA dans le domaine scientifique en 2023, ainsi que les résultats innovants importants obtenus par l’IA dans le domaine médical, notamment des technologies révolutionnaires telles que SynthSR et ImmunoSEIRA. En outre, le rapport analyse également attentivement les tendances en matière d’approbation par la FDA des dispositifs médicaux d’IA, fournissant ainsi une référence précieuse pour l’industrie.
Suivez le compte officiel et répondez « HAI2024 » pour télécharger le rapport complet
L'IA : un moteur pour accélérer la recherche scientifique
Le rapport 2024 sur l'indice d'intelligence artificielle indique queEn 2023, l'industrie a produit 51 modèles d'apprentissage automatique célèbres, tandis que le monde universitaire n'en a contribué que 15. De plus, 108 modèles de base nouvellement publiés proviennent de l'industrie et 28 du monde universitaire.
Bien que la vitesse de développement du monde universitaire soit nettement plus lente que celle de l’industrie, il est important de noter que l’IA n’a été officiellement utilisée dans le domaine de la découverte scientifique qu’en 2022. D’AlphaDev, qui optimise l’efficacité du tri des algorithmes, à GNoME, qui révolutionne le processus de découverte des matériaux, nous assistons à l’émergence d’applications d’IA plus importantes et plus pertinentes.
Aujourd’hui, l’IA s’est développée dans des domaines tels que la science des matériaux, le changement climatique et l’informatique. Heureusement, la Chine prend la tête de ce cycle de changement.Selon le « Rapport de recherche sur la carte de l'innovation scientifique et de l'IA en Chine » compilé par l'Institut chinois d'information scientifique et technologique et le Centre de recherche sur le développement de l'intelligence artificielle de nouvelle génération du ministère des Sciences et de la Technologie, mon pays se classe au premier rang en termes de nombre d'articles publiés dans le domaine de la recherche scientifique axée sur l'IA, et les logiciels de base de recherche scientifique sur l'IA produits au niveau national deviennent de plus en plus matures, fournissant aux chercheurs des ensembles de données riches, des modèles de base et des outils spécialisés.
En général, l’application de l’IA dans le domaine scientifique est diversifiée et favorise le développement et le progrès de la science à une vitesse sans précédent. Mais il convient de noter qu’au stade actuel de développement de l’IA pour la science,Des problèmes tels que la pénurie de talents complets, la difficulté de réutiliser des solutions techniques et la mauvaise qualité des données de recherche dans les disciplines verticales ont été progressivement mis en évidence.
Par exemple, dans le débat autour de la question « Les talents de l’IA devraient-ils s’engager dans la recherche scientifique ou les talents de la recherche scientifique devraient-ils apprendre l’IA ? », les chercheurs ayant des connaissances interdisciplinaires se démarquent. Ils possèdent non seulement une connaissance approfondie de leurs domaines de recherche scientifique, mais sont également capables de maîtriser rapidement divers outils et technologies d’IA. On peut toutefois imaginer leur rareté, et la culture de talents complets ne se fait pas du jour au lendemain. Par conséquent, la manière de construire rapidement un pont de communication entre l’IA et la recherche scientifique est une question importante liée à la promotion à grande échelle de l’IA pour la science.
Dans le même temps, il n’est pas nécessaire de s’étendre sur les riches domaines couverts par la recherche scientifique. Différents groupes de recherche peuvent avoir des besoins différents en matière d’outils d’IA en raison d’orientations de recherche légèrement différentes. Alors qu’il est difficile pour chaque équipe d’avoir des chercheurs ayant des antécédents interdisciplinaires, abaisser le seuil d’utilisation des outils d’IA et simplifier le processus de réglage fin des modèles peut également permettre d’accélérer dans une certaine mesure la promotion de l’IA dans le domaine de la recherche scientifique.
Accélérer les mises à jour, l'auto-itération et l'avancement de la technologie
Les progrès de la technologie de l’IA ont favorisé l’étendue et la profondeur de ses applications, tout en imposant des exigences de plus en plus élevées aux algorithmes. Actuellement, la plupart des algorithmes ont atteint un stade où il est difficile de s’appuyer sur des experts humains pour les optimiser davantage, ce qui entraîne une aggravation continue des goulots d’étranglement informatiques. Cependant, les scientifiques n’ont jamais cessé d’explorer le domaine des algorithmes.
AlphaDev
Recréer le coup de maître d'AlphaGo
L'algorithme de tri est un outil de base permettant aux systèmes informatiques d'organiser les éléments de données dans l'ordre. Pour réaliser des percées innovantes dans ce domaine, Google DeepMind a adopté une approche innovante et a exploré le domaine relativement peu étudié des instructions d'assemblage d'ordinateurs.Grâce au système AlphaDev, DeepMind peut trouver des algorithmes de tri plus efficaces directement à partir du niveau des instructions d'assemblage du processeur.
Le système AlphaDev se compose de deux composants principaux : l’algorithme d’apprentissage et la fonction de représentation.
L'algorithme d'apprentissage est une extension de l'algorithme avancé AlphaZero, combinant l'apprentissage par renforcement profond (DRL) et des algorithmes d'optimisation de recherche aléatoire pour effectuer des tâches de recherche d'instructions à grande échelle ; la fonction de représentation est basée sur l'architecture Transformer, qui peut capturer la structure sous-jacente du langage assembleur et la convertir en une représentation de séquence spéciale.
En utilisant le système AlphaDev,DeepMind a découvert avec succès des algorithmes de tri de séquences courtes à longueur fixe, à savoir Sort 3, Sort 4 et Sort 5, qui sont supérieurs aux algorithmes actuels réglés manuellement, et a intégré le code correspondant dans la bibliothèque C++ standard LLVM.En particulier, en découvrant l'algorithme Sort 3, AlphaDev a adopté une approche apparemment contre-intuitive qui était en fait un raccourci, rappelant le « 37e coup » qu'AlphaGo a utilisé dans son match contre le légendaire joueur de Go Lee Sedol - une stratégie inattendue qui a finalement conduit à la victoire.
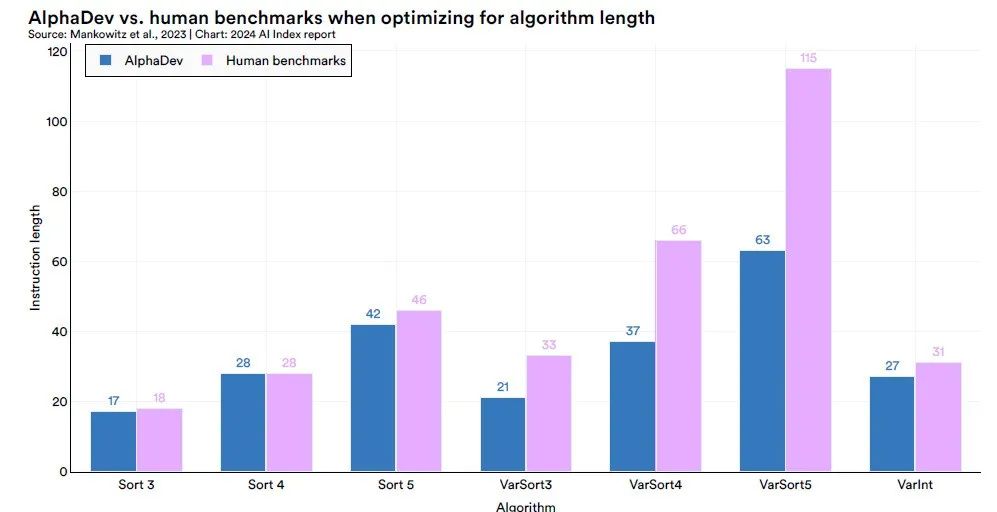
Les applications d’AlphaDev ne se limitent pas aux algorithmes de tri. DeepMind a généralisé sa méthode et l'a également appliquée aux algorithmes de hachage dans la plage de 9 à 16 octets, obtenant une augmentation significative de la vitesse de 30%. Cela montre qu’AlphaDev a un large potentiel et une valeur d’application dans l’optimisation des tâches informatiques sous-jacentes.
Lien vers l'article :
https://www.nature.com/articles/s41586-023-06004-9
FlexiCubes
Générer des modèles 3D de haute qualité à l'aide de l'IA
De la reconstruction de scènes aux pistes d’IA génératives, la nouvelle génération de modèles d’IA a obtenu un succès remarquable dans la génération de modèles 3D réalistes et détaillés. Étant donné que ces modèles sont généralement créés sous forme de maillages triangulaires standard, la qualité du maillage est essentielle. à cette fin,Les chercheurs de Nvidia ont développé une nouvelle méthode de génération de maillage, FlexiCubes, qui améliore considérablement la qualité du maillage dans le pipeline de génération de réseau 3D et peut être intégrée au moteur physique pour créer facilement des objets flexibles dans des modèles 3D.
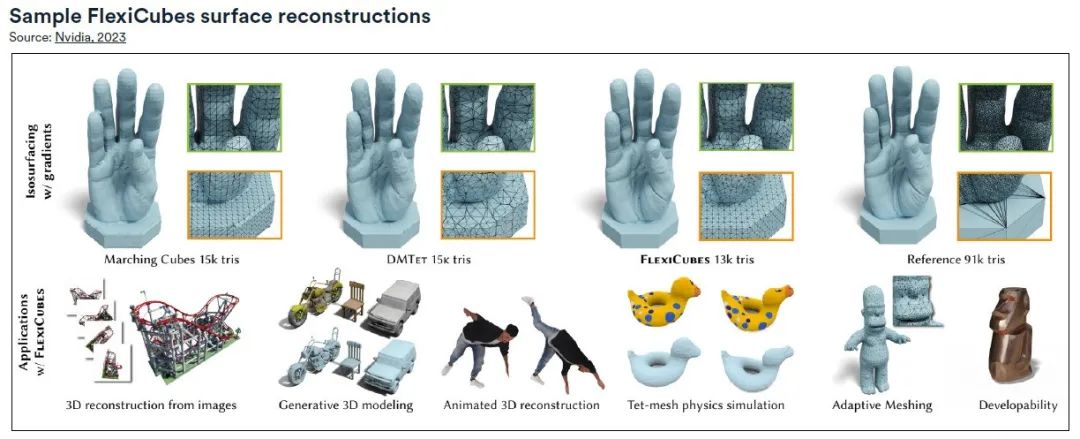
L'idée clé de FlexiCubes est d'introduire des paramètres « flexibles » qui permettent des ajustements précis dans le processus de génération du maillage.En mettant à jour ces paramètres pendant le processus d’optimisation, la qualité du maillage est considérablement améliorée. Cette approche met FlexiCubes en contraste frappant avec les pipelines traditionnels basés sur une grille tels que l'algorithme Marching Cubes largement utilisé, lui permettant de remplacer de manière transparente les pipelines d'IA basés sur l'optimisation.
Les maillages de haute qualité générés par FlexiCubes excellent dans la représentation de détails complexes, améliorant le réalisme global et la fidélité des modèles 3D générés par l'IA. Ces maillages sont particulièrement utiles pour les simulations physiques, dans des domaines tels que la photogrammétrie et l'IA générative, permettant aux pipelines d'IA de restituer avec précision les détails dans des formes complexes.
Lien vers l'article :
https://research.nvidia.com/labs/toronto-ai/flexicubes
Accélérer la création et améliorer l'efficacité au-delà de l'effort humain
Synbot
Robot chimiste alimenté par l'IA
Au plus profond des laboratoires de chimie, une révolution se déroule tranquillement : la synthèse de composés organiques n'est plus un processus lent et fastidieux, mais devient réalité grâce à la magie de l'automatisation.Au cœur de cette transformation se trouve le Synbot, un robot synthétique autonome créé par des scientifiques de Samsung Electronics.
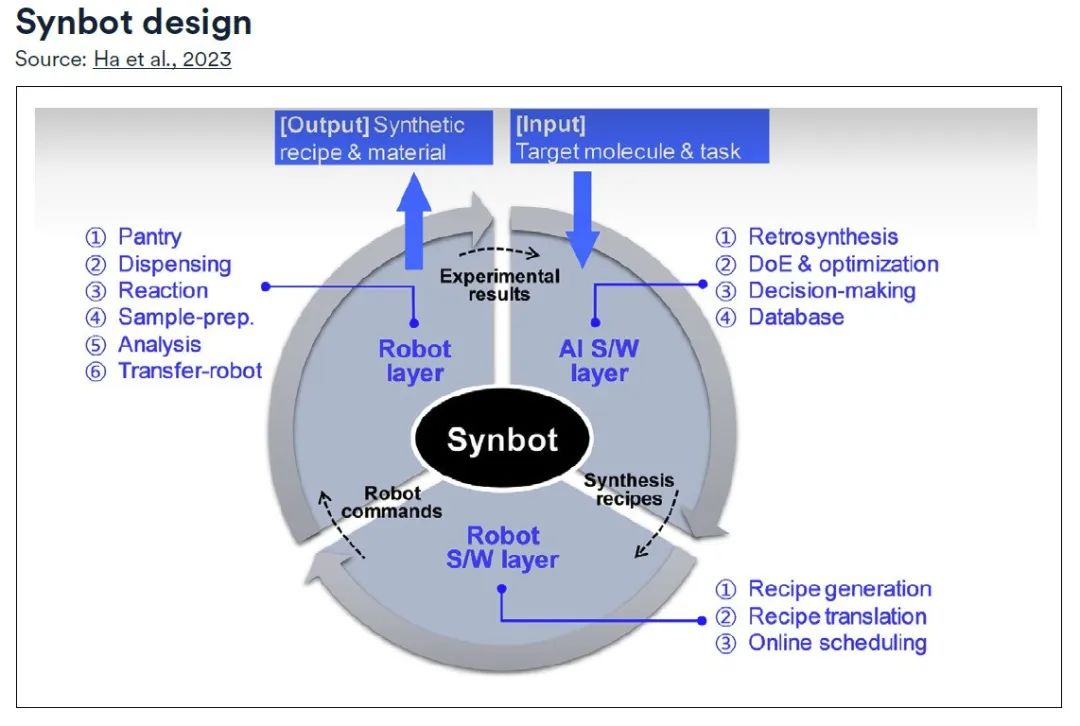
Plus précisément, Synbot se compose de trois couches :
* Couche logicielle IA :Diriger le processus de planification global, équipé de modules de rétrosynthèse, de modules de conception expérimentale et d'optimisation, et utiliser des modules de prise de décision pour guider la direction expérimentale ;
* Couche logicielle du robot :Responsable de la conversion en commandes exploitables pour le robot via le module de génération de recettes et le module de traduction ;* Couche robot :Sous la supervision du module de planification en ligne, les différentes fonctions du laboratoire de synthèse sont modularisées et les recettes planifiées sont exécutées systématiquement, mettant à jour en continu la base de données jusqu'à ce que les objectifs prédéfinis soient atteints.
Les recherches montrent queLe Synbot peut effectuer en moyenne 12 réactions en 24 heures. En supposant qu’un chercheur humain puisse réaliser deux de ces expériences par jour, Synbot est au moins six fois plus efficace que ses homologues humains.Avec l’ajout de Synbot, les scientifiques sont libérés des opérations fastidieuses et peuvent consacrer plus d’énergie à l’innovation et à l’exploration.
Lien vers l'article :
https://www.science.org/doi/full/10.1126/sciadv.adj0461
Gnome
Réinventer le processus de découverte des matériaux
Google DeepMind a publié un article dans Nature disant :L'outil d'IA GNoME (Graph Networks for Materials Exploration) basé sur l'exploration des matériaux a découvert 2,2 millions de nouvelles prédictions cristallines (équivalent à près de 800 ans de connaissances accumulées par les scientifiques humains), dont 380 000 sont des structures cristallines stables.On espère que grâce à la synthèse expérimentale, certains matériaux pourront déclencher des changements technologiques, tels que la prochaine génération de batteries et de supraconducteurs.
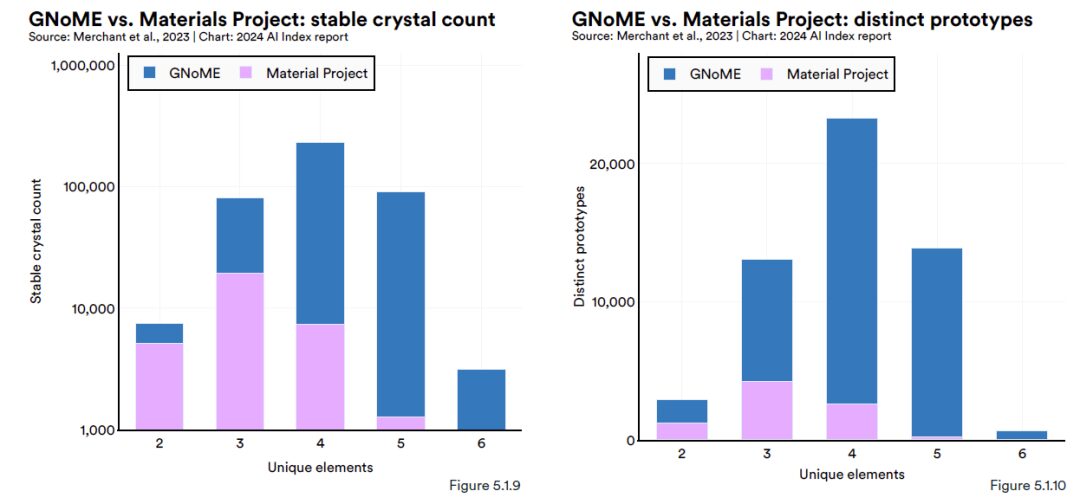
GNoME est un modèle avancé de réseau neuronal graphique (GNN). Les données d'entrée se présentent principalement sous forme de graphiques, formant des connexions similaires à celles entre les atomes, ce qui permet également à GNoME de découvrir plus facilement de nouveaux matériaux cristallins. Il est rapporté que GNoME peut prédire la structure de nouveaux cristaux stables, puis les tester via DFT (théorie fonctionnelle de la densité) et réinjecter les données de formation de haute qualité résultantes dans la formation du modèle.
À ce stade,Le nouveau modèle augmentera la précision de la prédiction de la stabilité des matériaux d'environ 50% à 80%, et le taux de découverte de nouveaux matériaux de moins de 10% à plus de 80%.(Cliquez pour voir le rapport complet : 800 ans d’avance sur les humains ? DeepMind lance GNoME, qui utilise l’apprentissage profond pour prédire 2,2 millions de nouveaux cristaux)
Accélérer le changement et gérer sereinement le « rhinocéros gris » de l'environnement écologique
GraphCast
Produire les prévisions météorologiques mondiales les plus précises
GraphCast, publié par Google DeepMind, est un système de prévision météorologique basé sur l'apprentissage automatique et les réseaux de neurones graphiques (GNN). Il utilise une configuration « encoder-traiter-décoder », possède un total de 36,7 millions de paramètres et peut faire des prédictions à une haute résolution de 0,25 degré de longitude/latitude (28 km x 28 km à l'équateur).La chaîne couvre toute la surface de la Terre. À chaque point de la grille, le modèle prédit cinq variables de la surface de la Terre (notamment la température, la vitesse du vent, la direction du vent, la pression moyenne au niveau de la mer, etc.), ainsi que six variables atmosphériques, notamment l'humidité spécifique, la vitesse du vent, la direction du vent et la température à 37 altitudes différentes.
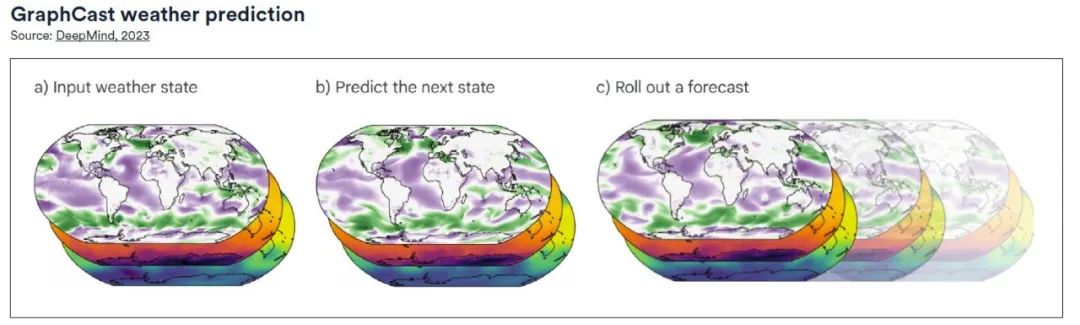
Dans le test de base complet,Comparé à HRES (High Resolution Forecast), GraphCast fournit des prévisions plus précises pour près de 90% sur 1 380 variables testées.Selon une analyse comparative, GraphCast peut également identifier les événements météorologiques violents plus tôt que les modèles de prévision traditionnels. (Cliquez ici pour le rapport complet : Le Hailstorm Center collecte des données, de grands modèles soutiennent les prévisions météorologiques extrêmes et les « Storm Chasers » sont sur scène)
Prévision des inondations
L'intelligence artificielle transforme la prévision des inondations
En 2018, Google a lancé la Google Flood Forecasting Initiative, utilisant l'IA et une puissance de calcul puissante pour créer de meilleurs modèles de prévision des inondations et collaborer avec les gouvernements de plusieurs pays. En 2023,L'équipe de recherche de Google a développé un modèle de prévision des crues basé sur l'apprentissage automatique qui peut prédire de manière fiable les inondations cinq jours à l'avance. Lorsqu’il s’agit de prévoir des inondations qui se produisent une fois tous les cinq ans, ses performances sont meilleures ou équivalentes à celles de la prévision actuelle des inondations qui se produisent une fois par an. Le système peut couvrir plus de 80 pays.
Cette étude a construit un modèle avancé de prédiction fluviale en adoptant l’application de deux réseaux de mémoire à long et court terme (LSTM).L'architecture principale du modèle est basée sur le framework encodeur-décodeur.Plus précisément, le module Hindcast LSTM est responsable du traitement des données météorologiques historiques, tandis que le module Forecast LSTM traite les données météorologiques prévues. Le résultat du modèle est les paramètres de distribution de probabilité pour chaque point de temps de prédiction, ce qui peut fournir une prédiction de probabilité du débit d'une rivière spécifique à un moment précis.
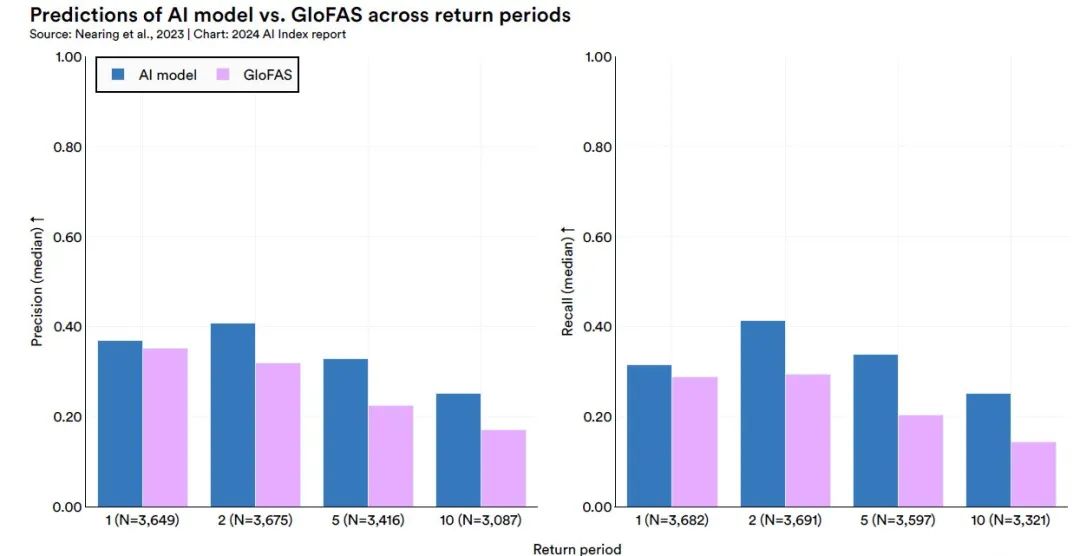
Les résultats de l’étude ont montré queLe modèle surpasse le système de modélisation actuel de pointe, le Copernicus Emergency Management Service Global Flood Awareness System (GloFAS).Cette découverte confirme le potentiel et la fiabilité du modèle proposé dans le domaine de la prévision fluviale et fournit un nouveau moyen technique pour l’alerte aux inondations et la gestion des ressources en eau. (Cliquez ici pour voir le rapport complet : Le modèle de prévision des inondations de Google est à nouveau publié dans Nature, battant le système n°1 mondial et couvrant plus de 80 pays)
IA : ouvrir une nouvelle ère en médecine
Le « Rapport sur l'indice d'intelligence artificielle 2024 » montre que la technologie de l'IA a obtenu des résultats dans de nombreux domaines tels que l'imagerie médicale, les questions et réponses médicales, le diagnostic médical, etc. En fait, l'application de l'IA dans le domaine de la santé médicale est connue depuis longtemps. Grâce aux algorithmes d’apprentissage automatique, l’IA est capable d’analyser de grandes quantités de données médicales et d’aider les médecins à diagnostiquer les maladies avec plus de précision. Par exemple, dans la détection du cancer, l’IA peut identifier des anomalies subtiles dans les images médicales, améliorant ainsi le taux de réussite du diagnostic précoce.
En outre, l’IA joue également un rôle important dans le développement de médicaments.d'une part,L’IA a approfondi notre compréhension des cibles médicamenteuses et de la synthèse des composés, optimisé les étapes de la découverte de médicaments et augmenté considérablement les chances de succès des lancements de nouveaux médicaments.d'autre part,La technologie de l’IA est utilisée pour raccourcir le cycle de développement de nouveaux médicaments, réduire les coûts et améliorer considérablement l’efficacité du développement de médicaments et la compétitivité des entreprises.
Il convient de noter que le « Rapport sur l'indice d'intelligence artificielle 2024 » résume également les dispositifs médicaux liés à l'intelligence artificielle, et le nombre d'approbations de dispositifs médicaux liés à l'IA par la Food and Drug Administration (FDA) des États-Unis continue d'augmenter. En 2022, la FDA a approuvé 139 dispositifs médicaux liés à l'IA, soit une augmentation de 12,1% par rapport à l'année précédente. Ce chiffre a été multiplié par plus de 45 depuis 2012, ce qui montre l’utilisation généralisée de l’IA dans les applications médicales du monde réel.
Bien que l’application de la technologie de l’IA dans les soins médicaux réels ait apporté de nombreuses opportunités, elle est également confrontée à une série de défis qui doivent être relevés, tels que les problèmes éthiques de l’IA, la protection de la confidentialité des données, les goulots d’étranglement techniques, la supervision et la responsabilité, la collaboration interdisciplinaire et l’applicabilité clinique. En particulier,UNLa nature « boîte noire » du modèle I rend son processus de prise de décision difficile à expliquer, ce qui constitue un défi majeur pour le diagnostic médical qui nécessite un degré élevé de transparence et de traçabilité.Le manque d’explicabilité peut affecter la confiance des médecins dans les résultats de diagnostic assistés par l’IA.
Par conséquent, outre l'itération technologique, la manière de combler les lacunes dans les politiques, les normes, la supervision, la sécurité, etc., et de briser les caractéristiques de la « boîte noire » exige toujours que le gouvernement et les entreprises concernées promeuvent conjointement des solutions.
Imagerie médicale : apporter des solutions plus complètes et plus approfondies
L’application de la technologie de l’IA dans le domaine de l’imagerie médicale devient de plus en plus diversifiée et approfondie. De l’aide au diagnostic à l’amélioration des flux de travail en passant par la promotion de la médecine personnalisée, l’IA devient un outil indispensable pour l’imagerie médicale.
SynthSR
Convertir des images haute résolution et réparer les lésions
Développé par le laboratoire d'informatique et d'intelligence artificielle du MIT, SynthSR entraîne un réseau neuronal convolutif (CNN) à super-résolution à l'aide d'un ensemble de données en accès libre de scanners IRM isotropes à haut champ de 1 mm et d'une segmentation précise de 39 régions d'intérêt (ROI) dans le cerveau.La technologie se concentre sur les séquences d'IRM cérébrale pondérées en T1 et T2 à faible champ (0,064 T), tout en utilisant la technologie d'acquisition d'écho de gradient rapide préparé par magnétisation (MPRAGE), visant à produire des images de haute qualité avec une résolution spatiale isotrope de 1 mm.
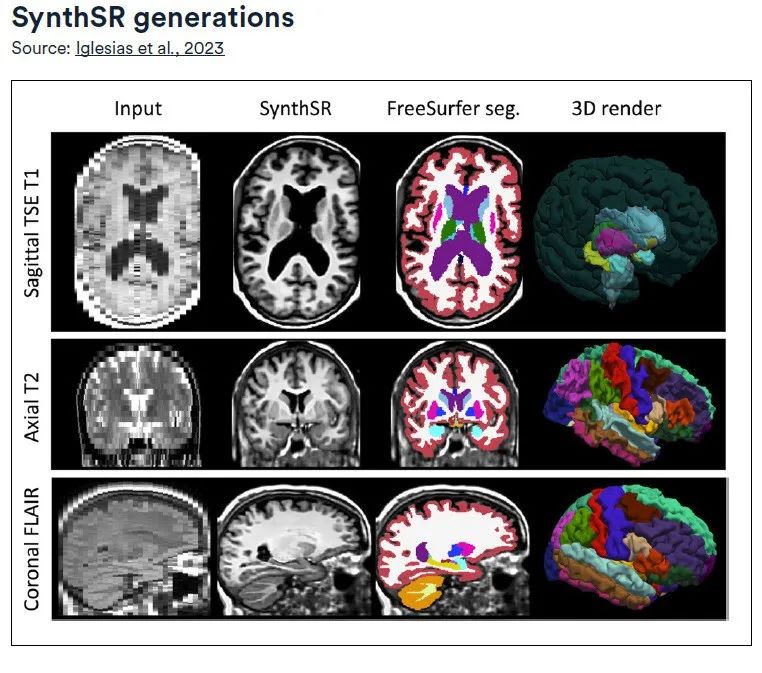
Les fonctionnalités avancées de SynthSR sont :Il peut convertir les données d'IRM cliniques de différentes directions, résolutions et contrastes en images MPRAGE isotropes de 1 mm et réparer les lésions au cours du processus.
Les images synthétiques MPRAGE converties peuvent être directement appliquées aux outils d'analyse d'images IRM cérébrales 3D existants, tels que l'enregistrement ou la segmentation d'images.Aucune formation supplémentaire n'est requise.De plus, en comparant les données morphométriques cérébrales des images synthétiques avec des images réelles à champ élevé, l'étude a vérifié davantage le potentiel d'application du LF-SynthSR dans le domaine de la neuroradiologie quantitative.
Lien vers l'article :
http://arxiv.org/pdf/2012.13340v1.pdf
CT Panda
Dépistage précoce du cancer du pancréas
Compte tenu de la localisation cachée du cancer du pancréas et de l’absence de manifestations évidentes sur les images CT simples,L'Alibaba DAMO Academy, en collaboration avec des équipes de recherche de plus d'une douzaine d'institutions médicales à travers le monde, a utilisé l'IA pour dépister le cancer du pancréas chez les personnes asymptomatiques, a construit un cadre d'apprentissage profond unique et a finalement formé le modèle PANDA pour la détection précoce du cancer du pancréas.
Le modèle PANDA est un outil avancé d’analyse d’images médicales qui combine plusieurs techniques d’apprentissage en profondeur pour améliorer l’efficacité et la précision de la détection des lésions pancréatiques. Le modèle utilise d’abord un réseau de segmentation (U-Net) pour localiser avec précision la région pancréatique, puis utilise un réseau neuronal convolutif multitâche (CNN) pour identifier les anomalies dans l’image. Enfin, un modèle de transformateur à deux canaux a été utilisé pour classer les anomalies détectées et identifier les types de lésions pancréatiques spécifiques.
Le principal avantage de cette technologie est qu’elle peut utiliser des algorithmes d’IA pour agrandir et identifier de minuscules lésions dans des images de tomodensitométrie simples qui sont difficiles à identifier à l’œil nu.Cela permet non seulement de détecter efficacement et en toute sécurité le cancer du pancréas à un stade précoce, mais également de résoudre efficacement le problème du taux élevé de faux positifs dans les méthodes de dépistage précédentes.
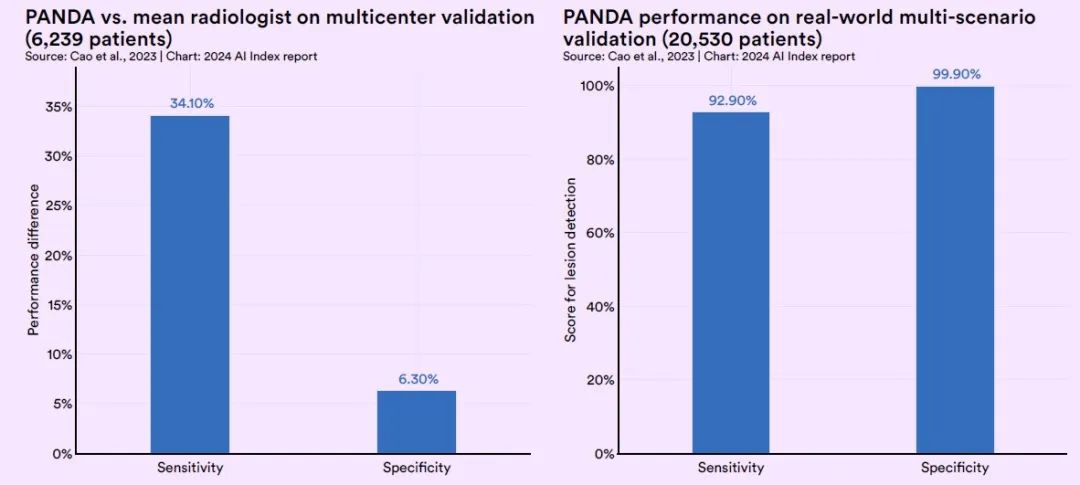
Lors du test de validation, la sensibilité de PANDA était 34,1% supérieure à celle des radiologues ordinaires et sa spécificité était 6,3% supérieure à celle des radiologues ordinaires.Dans un test à grande échelle en conditions réelles impliquant environ 20 000 patients, PANDA avait une sensibilité de 92,9% et une spécificité de 99,9%.(Cliquez ici pour voir le rapport complet : 31 diagnostics manqués ont été identifiés parmi 20 000 cas, et Alibaba Damo Academy a pris l'initiative de publier un « scanner simple + grand modèle » pour dépister le cancer du pancréas)
Diagnostic médical : Élaborer des plans de diagnostic et de traitement personnalisés et précis
De l’amélioration de l’efficacité et de la précision du diagnostic à la fourniture de plans de traitement personnalisés, la technologie de l’IA a un grand potentiel dans le domaine du diagnostic médical, contribuant à améliorer la qualité des services médicaux et l’expérience des patients.
Capteurs infrarouges plasmoniques couplés
Améliorer le diagnostic des maladies neurodégénératives
Dans le domaine du diagnostic des maladies neurodégénératives, le manque d’outils efficaces pour détecter les biomarqueurs précliniques a fait que le diagnostic précoce de maladies telles que le syndrome de Parkinson et la maladie d’Alzheimer est confronté à des défis majeurs. Bien que les méthodes de détection traditionnelles, telles que la spectrométrie de masse et le test immuno-enzymatique (ELISA), soient utiles dans une certaine mesure, elles sont limitées dans l’identification des changements dans l’état structurel des biomarqueurs.
Pour résoudre ce problème,Une équipe de recherche de l'EPFL a développé une méthode de diagnostic innovante qui combine la technologie des réseaux neuronaux, des capteurs infrarouges plasmoniques utilisant la spectroscopie d'absorption infrarouge à surface améliorée (SEIRA) et la technologie d'immunoessai (ImmunoSEIRA) pour permettre une analyse quantitative du stade et de la progression des maladies neurodégénératives.
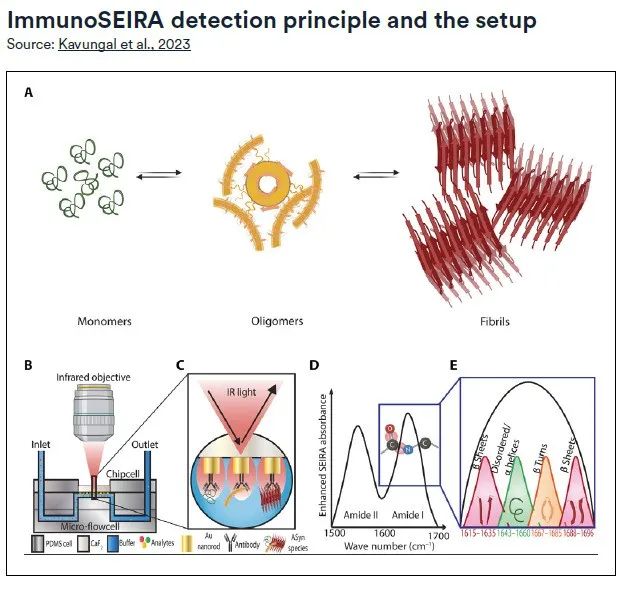
Le capteur ImmunoSEIRA utilise un ensemble de nanobâtonnets d'or modifiés avec des anticorps ciblant des protéines spécifiques, qui peuvent capturer des biomarqueurs cibles à partir de quantités extrêmement petites d'échantillons en temps réel et effectuer une analyse structurelle sur eux. Les réseaux neuronaux ont ensuite été utilisés pour identifier les protéines mal repliées, les oligomères et les agrégats de fibrilles, atteignant des niveaux de précision de détection sans précédent. L’introduction de cette méthode fournit un nouveau moyen technique pour le diagnostic précoce et l’évaluation précise des maladies neurodégénératives.
CoDoC
Intégration logique entre l’IA et le diagnostic des médecins
Google DeepMind a développé un système d'intelligence artificielle d'assistance médicale appelé CoDoC, conçu pour fournir une interprétation et une analyse approfondies des images médicales. Grâce à l’apprentissage, le système peut décider quand se fier à son propre jugement et quand adopter l’avis du médecin.
Plus précisément, l’équipe DeepMind a exploré divers scénarios d’application dans lesquels les cliniciens utilisent des outils d’IA pour aider à interpréter les images médicales. Pour tout cas théorique dans un contexte clinique, le système CoDoC ne nécessite que trois entrées pour chaque cas dans l'ensemble de données de formation :* d'abord,Un score de confiance pour la sortie d’IA prédite, qui varie de 0 (certainement aucune maladie) à 1 (certainement une maladie) ;* Deuxièmement,interprétation des images médicales par les cliniciens;
* enfin,L'existence objective de la maladie.
Il convient de noter queLe système CoDoC ne nécessite pas d’accès direct aux images médicales elles-mêmes.
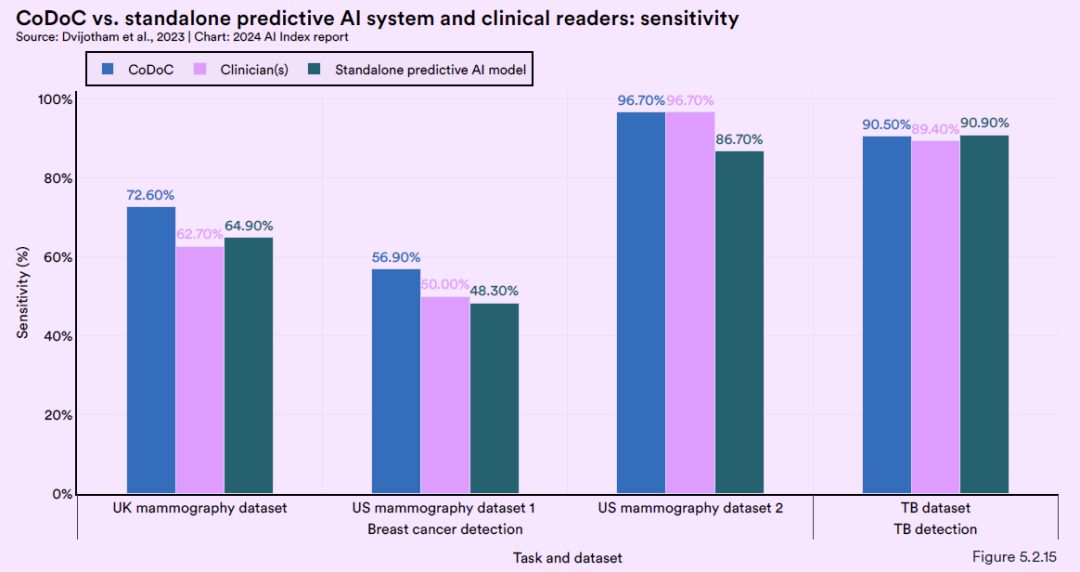
De plus, DeepMind a effectué des tests complets sur le système CoDoC en utilisant plusieurs ensembles de données historiques anonymisées du monde réel. Les résultats des tests montrent que la combinaison de l’expertise médicale humaine avec les prédictions des modèles d’IA peut fournir le diagnostic le plus précis.Sa précision dépasse celle que l’on peut obtenir en utilisant l’une ou l’autre méthode seule.Cette découverte souligne l’importance de l’IA travaillant en collaboration avec des experts humains et offre de nouvelles perspectives pour améliorer la précision et la fiabilité des diagnostics d’imagerie médicale.
Questions et réponses médicales : améliorer la précision du diagnostic, optimiser les plans de traitement et améliorer l'expérience de service aux patients
En 2020, les chercheurs ont proposé un système de questions-réponses médicales basé sur un graphique de connaissances, MedQA, qui utilise des graphiques de connaissances pour représenter et stocker des données structurées et semi-structurées dans le domaine médical, puis récupère ou génère des réponses à partir du graphique de connaissances via des techniques de recherche, de raisonnement ou de correspondance de graphiques. Depuis la sortie de MedQA, la capacité de l’IA à répondre aux questions médicales a reçu une attention plus large.
GPT-4 Medprompt
La précision dépasse 90%
GPT-4 Medprompt développé par l'équipe de recherche Microsoft a dépassé pour la première fois la précision de 90% sur l'ensemble de données MedQA (questions d'examen de licence médicale aux États-Unis).Surpasse un certain nombre de méthodes de réglage fin telles que BioGPT et Med-PaLM. Les chercheurs ont également déclaré que la méthode Medprompt est universelle et applicable non seulement à la médecine, mais également à des professions telles que l’ingénierie électrique, l’apprentissage automatique et le droit.
Medprompt est une combinaison de plusieurs stratégies d’incitation, notamment :* Sélection dynamique de quelques échantillons :Les chercheurs ont d’abord utilisé le modèle text-embedding-ada-002 pour générer des représentations vectorielles pour chaque échantillon d’entraînement et échantillon de test. Ensuite, pour chaque échantillon de test, les k échantillons les plus similaires sont sélectionnés parmi les échantillons d'entraînement en fonction de la similarité vectorielle.* Chaîne de pensée auto-générée :La méthode de la chaîne de pensée (CoT) consiste à laisser le modèle réfléchir étape par étape et à générer une série d'étapes de raisonnement intermédiaires. Par rapport aux exemples de chaîne de pensée élaborés par des experts dans le modèle Med-PaLM 2, les raisonnements de chaîne de pensée générés par GPT-4 sont plus longs et la logique de raisonnement étape par étape est plus fine.
* Intégration de la lecture aléatoire des options :Lorsque GPT-4 répond à des questions à choix multiples, il peut y avoir un biais, c'est-à-dire que, quelles que soient les options, il aura tendance à toujours choisir A ou toujours choisir B. Il s'agit d'un biais de position. Pour réduire ce problème, les chercheurs ont choisi de mélanger l’ordre d’origine des options, puis de laisser GPT-4 effectuer plusieurs séries de prédictions, en utilisant un ordre différent des options à chaque série.

L'étude a montré que Medprompt a surpassé le Flan-PaLM 540B, classé en tête, en 2022 de 3,0, 21,5 et 16,2 points de pourcentage dans les sections à choix multiples de plusieurs tests de référence médicaux bien connus, notamment PubMedQA, MedMCQA et MMLU, respectivement. Ses performances ont également dépassé celles du Med-PaLM 2 le plus avancé de l’époque.
MediTron-70B
Meilleur modèle de langage open source à grande échelle pour les soins de santé
Étant donné que GPT-4 Medprompt est un système à source fermée, son utilisation gratuite auprès du grand public est limitée. Pour résoudre ce problème,Des chercheurs de l'École polytechnique fédérale de Lausanne ont développé le MediTron-70B sur la base de ce système, dans le but de fournir unUn modèle de langage open source, haute performance et à grande échelle pour le domaine médical.
MediTron est un algorithme d'apprentissage profond.Construit sur l'architecture Llama 2 et affiné à l'aide du formateur distribué Megatron-LM de Nvidia,Parallèlement, une pré-formation approfondie a été réalisée sur un corpus médical complet. Le corpus est une sélection rigoureuse d'articles, de résumés et de directives médicales reconnues internationalement par PubMed.
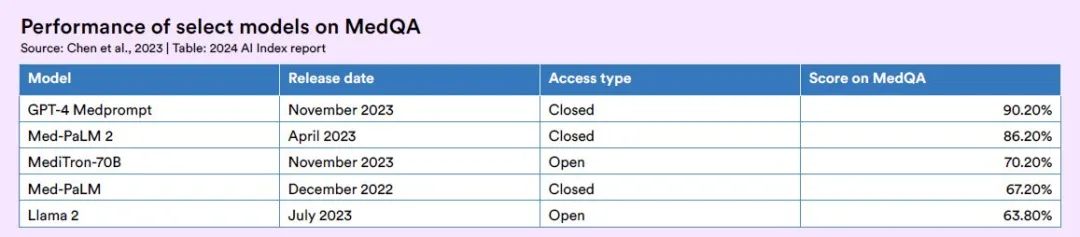
La série MediTron comprend deux modèles : MediTron-7B et MediTron-70B. dans,Les performances du MediTron-70B ont dépassé celles du GPT-3.5 et du Med-PaLM, et sont proches du niveau du GPT-4 et du Med-PaLM-2.
Afin de promouvoir le développement de LLM médicaux open source, l'équipe de développement a rendu public le corpus de pré-formation médicale qu'elle utilise et le code de pondération du modèle MediTron. MediTron-70B obtient le score le plus élevé parmi les modèles open source sur MedQA, une réussite qui marque une avancée importante dans le domaine des LLM médicaux open source.
Lien vers l'article :
https://arxiv.org/pdf/2311.16079.pdf
MedAlign
Réduire la charge administrative des soins de santé
Les ensembles de données actuels de réponses aux questions des dossiers médicaux électroniques (DME) pour les tâches de génération de texte dans le domaine de la santé ne capturent pas de manière adéquate la complexité à laquelle les cliniciens sont confrontés dans l'analyse des besoins d'information et le traitement des documents.
Pour combler cette lacune, une équipe de 15 cliniciens issus de différents domaines d’expertise a lancé MedAlign - Un ensemble de données de référence basé sur les données du DSE. L'ensemble de données contient 983 questions cliniques réelles et leurs instructions, ainsi que des réponses fournies par 303 cliniciens, et des paires instructions-réponses ont été construites en analysant 276 données EHR longitudinales.
Ce travail répond non seulement au manque d’une référence d’évaluation pour la praticité des LLM dans les tâches cliniques complexes, mais favorise également les progrès de la recherche sur la génération de langage naturel dans le domaine de la santé en fournissant un ensemble de données de réponse aux commandes réaliste et complet.
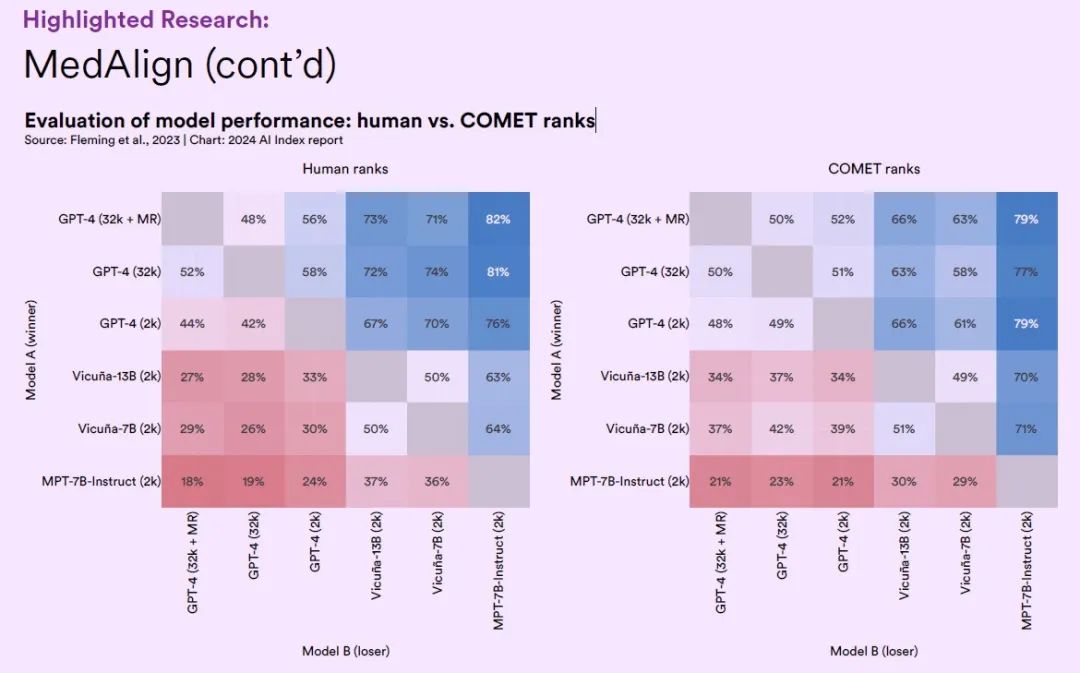
Sur l’ensemble de données MedAlign, les chercheurs ont testé six grands modèles linguistiques issus de différents domaines généraux et ont évalué la précision et la qualité des réponses générées par chaque grand modèle par les cliniciens.
Les résultats montrent queLa variante du modèle GPT-4 qui a subi une optimisation en plusieurs étapes a atteint une précision de 65,0%, ce qui est généralement préféré aux autres LLM. En tant que premier ensemble de données de référence couvrant largement les applications EHR, MedAlign marque une étape importante dans l'utilisation de la technologie de l'intelligence artificielle pour réduire la charge administrative des soins de santé.
Lien vers l'article :
https://arxiv.org/pdf/2308.14089.pdf
Recherche médicale : utiliser l’IA pour construire la ligne de défense la plus solide pour la santé humaine
Avec les progrès continus de la technologie, l’application de la technologie de l’IA dans le domaine de la recherche médicale est devenue plus étendue et plus approfondie. Aujourd’hui, les scientifiques exploitent la puissance de l’IA pour explorer en profondeur le code des gènes humains et utilisent l’IA pour nous aider à construire une ligne de défense médicale solide.
AlphaMissence
Identifier efficacement les mutations faux-sens pathogènes dans les gènes
Sur la base d'AlphaFold, l'équipe Google DeepMind a développé un nouveau modèle d'IA : AlphaMissense.Le modèle combine le modèle de structure protéique de haute précision fourni par AlphaFold et l'algorithme d'évolution contrainte extrait des séquences associées. Le processus de formation d'AlphaMissense est divisé en deux étapes :
* La première étape est similaire à la formation d’AlphaFold, en se concentrant sur l’amélioration des poids du modèle de langage protéique ;
* La deuxième phase se concentre sur le réglage fin du modèle pour correspondre plus précisément à la pathogénicité, en attribuant une étiquette bénigne ou pathogène à la mutation en fonction de sa fréquence dans la population.
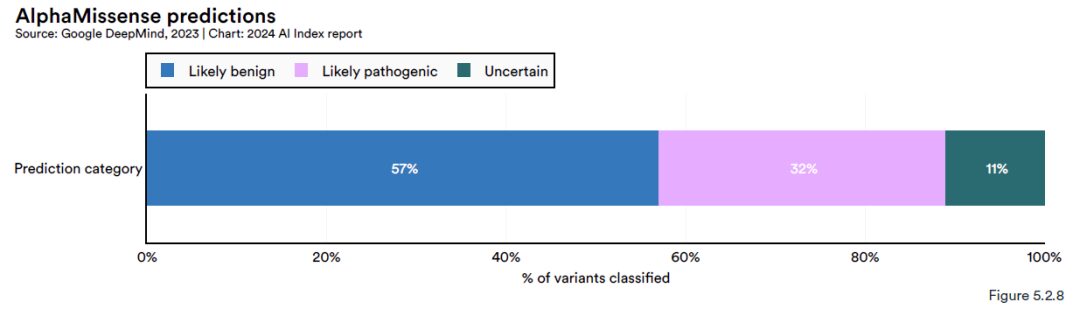
Les résultats de l’étude montrent queAlphaMissense a prédit avec succès 71 millions de mutations faux-sens dans les gènes codant pour les protéines humaines.Les mutations faux-sens sont des variations héréditaires qui affectent la fonction des protéines et peuvent conduire à diverses maladies, dont le cancer. Parmi ces variantes faux-sens potentielles,AlphaMissense a pu classer 891 variantes TP3T, dont environ 571 TP3T ont été jugées comme des variantes probablement bénignes (Probablement bénignes), 321 TP3T ont été jugées comme des variantes probablement pathogènes (Probablement pathogènes) et les variantes restantes ont été classées comme de nature incertaine (Incertain).
Cette capacité de classification dépasse de loin celle des annotateurs humains, qui n’ont pu identifier que 0,11 TP3T parmi toutes les mutations faux-sens. La haute efficacité et la précision d’AlphaMissense constituent un outil puissant pour la recherche et le diagnostic clinique des maladies génétiques.
Lien vers l'article :
https://www.science.org/doi/10.1126/science.adg7492
EVEscape
Système d'alerte précoce pour les pandémies
Une équipe de recherche de la Harvard Medical School et de l'Université d'Oxford a développé conjointement un cadre modulaire universel innovant, EVEscape.Capacité à prédire le potentiel d’échappement du virus sans s’appuyer sur des données de séquençage ou des informations sur la structure des anticorps pendant la pandémie.
La précision d'EVEscape dans la prédiction des mutations pandémiques du SRAS-CoV-2 est comparable à celle de la technologie d'analyse des mutations profondes à haut débit (DMS), et son application ne se limite pas au SRAS-CoV-2 mais peut être étendue à d'autres types de virus. Ce système d’alerte précoce guide la prise de décision et la préparation en matière de santé publique, contribuant ainsi à minimiser les impacts négatifs de la pandémie sur la santé humaine et la situation socio-économique.
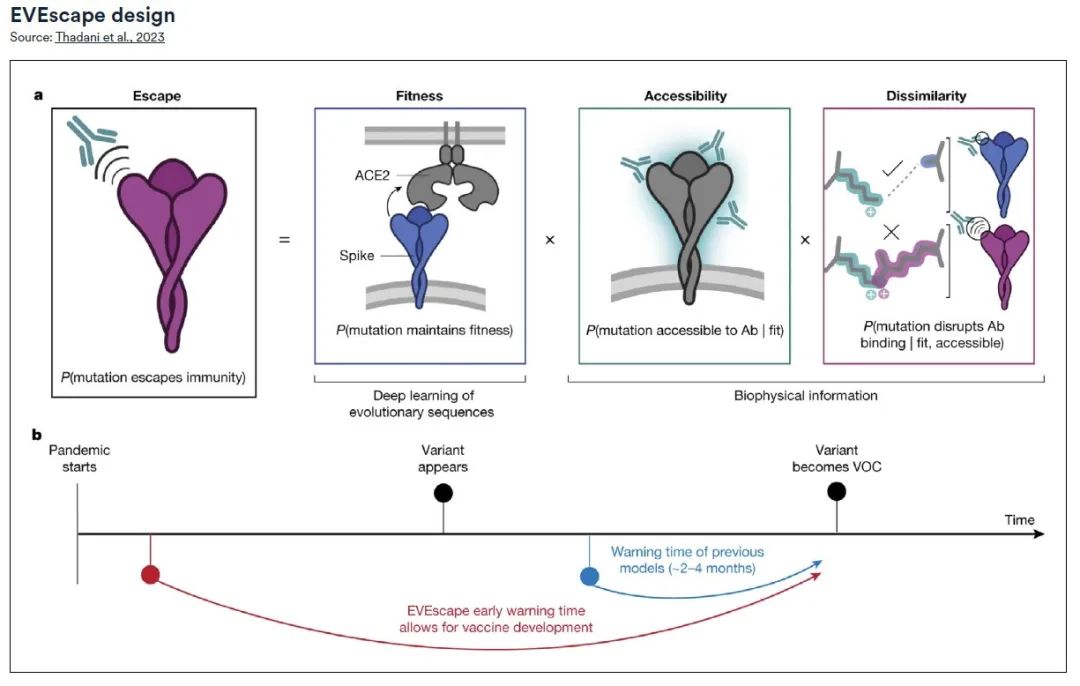
Le framework EVEscape se compose de deux parties principales :* Une partie est un modèle permettant de générer des séquences évolutives,Le modèle fournit des informations sur les mutations virales possibles, similaires au modèle utilisé dans le projet EVE (Evolutionary Virus Escape) ;
* Une autre partie est une base de données contenant des informations biologiques et structurelles détaillées sur le virus.En intégrant ces deux composants, EVEscape est capable de prédire les caractéristiques des variantes virales avant qu’elles n’apparaissent réellement.
Grâce à une analyse rétrospective de la pandémie de SRAS-CoV-2, l’équipe de recherche a confirmé l’efficacité d’EVEscape pour prédire les mutations ayant un potentiel d’échappement à la pandémie, des mois plus tôt que les méthodes reposant sur des expériences traditionnelles d’anticorps et de sérologie, tout en conservant une précision comparable. L’identification précoce des mutations d’échappement potentielles à l’aide d’EVEscape peut fournir des informations essentielles pour la conception de vaccins et de thérapies afin de contrôler plus efficacement la propagation du virus.
Lien vers l'article :
https://doi.org/10.1038/s41586-023-06617-0
Référence sur le pangénome humain
Première ébauche de la cartographie du pan-génome humain
Au début du 21e siècle, le Projet Génome Humain a publié avec succès l'ébauche préliminaire du génome humain de référence, marquant une avancée dans la compréhension par l'humanité de son propre modèle de vie. Cependant, en raison des limites de la technologie de séquençage de l’époque, le projet contenait plusieurs zones vides non remplies.
En 2023, un consortium international de 119 scientifiques de 60 institutions, dirigé par la faculté de médecine de l’Université de Washington et l’Université de Californie, a utilisé la technologie de l’intelligence artificielle pour développer la première ébauche mise à jour et plus représentative du pan-génome humain.
Le projet a utilisé une technologie avancée de « séquençage à lecture longue » pour mener une analyse approfondie de 94 échantillons de génomes provenant de 47 individus ayant des origines ancestrales différentes à travers le monde.Les longs fragments d’ADN ont ensuite été assemblés en une séquence de génome plus complète à l’aide d’un algorithme personnalisé. Les résultats ont montré que le projet a atteint une couverture 99% de la séquence attendue, tout en dépassant également 99% en termes de structure et de précision des paires de bases.
Comparé à l'ancien flux de travail basé sur GRCh38, le nouveau projet est plus efficace lors de l'analyse des données à lecture courte.L'erreur dans la découverte de petites variantes génétiques a été réduite de 34%, tandis que le taux de détection des variantes structurelles d'haplotype a été amélioré de 104%, ajoutant 119 millions de paires de bases.En outre, le nouveau projet a également révélé deux nouveaux composants importants qui régulent l’expression des gènes : HIRA et SATB2. Ces résultats sont d’une grande importance pour une compréhension plus approfondie de la structure et de la fonction du génome humain.
2024, l'IA mène l'avenir de la recherche scientifique
L’intelligence artificielle, avec son potentiel incroyable, devient un moteur essentiel du progrès scientifique et des avancées en médecine. En 2024, le développement rapide de l’IA apporte des changements révolutionnaires à la recherche scientifique et à la médecine, avec une vitesse et un impact bien plus importants que jamais auparavant. L’IA accélère non seulement le cycle d’accumulation des connaissances et d’innovation, mais redéfinit également la manière dont nous comprenons et résolvons les problèmes complexes.
Dans le domaine de la recherche scientifique,Les algorithmes et modèles d’IA aident les scientifiques à traiter et à analyser d’énormes ensembles de données, révélant ainsi des informations approfondies cachées derrière les données. Ils ont démontré d’énormes avantages dans la simulation et la prédiction du comportement de systèmes complexes, conduisant à des découvertes révolutionnaires dans de nombreux domaines scientifiques fondamentaux tels que la physique, la chimie et la biologie.
Dans le domaine médical,Les outils de diagnostic assistés par l’IA deviennent plus précis, permettant une détection plus précoce des signes de maladie et un traitement plus rapide pour les patients. Dans le même temps, l’application de l’IA à la médecine personnalisée peut personnaliser des plans de traitement plus précis pour les patients en analysant les informations génétiques individuelles et les biomarqueurs, améliorant ainsi considérablement les résultats du traitement et la qualité de vie des patients.
aussi,Le rôle de l’IA dans le développement de médicaments ne peut être sous-estimé.En prédisant l’activité des molécules et les effets secondaires des médicaments, il raccourcit considérablement le cycle des nouveaux médicaments du laboratoire au marché, réduit les coûts de R&D et accélère le processus de mise sur le marché de nouveaux médicaments.
On peut dire que chaque étape de progrès dans l’IA est comme une pierre jetée dans le long fleuve de la sagesse humaine, provoquant des ondulations et repoussant les limites de la recherche scientifique et de la médecine. Les humains qui savent utiliser les outils finiront par utiliser la puissance de ces stimuli pour évoluer vers une nouvelle ère de plus grande intelligence et de meilleure santé.








