Command Palette
Search for a command to run...
Tutoriel En ligneLe Volume De Transactions Des Débuts De Liu Qiangdong En Tant qu'humain Numérique a Dépassé Les 50 Millions ! Générez Un Humain Numérique Parlant En Temps Réel Avec GeneFace++
Récemment, le fondateur de JD.com, Liu Qiangdong, s'est transformé en « Dongge AI Digital Human Achats et Ventes » et a commencé ses débuts en diffusion en direct dans la salle de diffusion en direct des achats et des ventes des appareils électroménagers, des meubles de maison et des supermarchés de JD.com. La diffusion en direct a attiré plus de 20 millions de téléspectateurs et le montant total des transactions a dépassé les 50 millions.Il démontre pleinement l’énorme potentiel des personnes numériques IA dans le domaine du streaming en direct du commerce électronique.
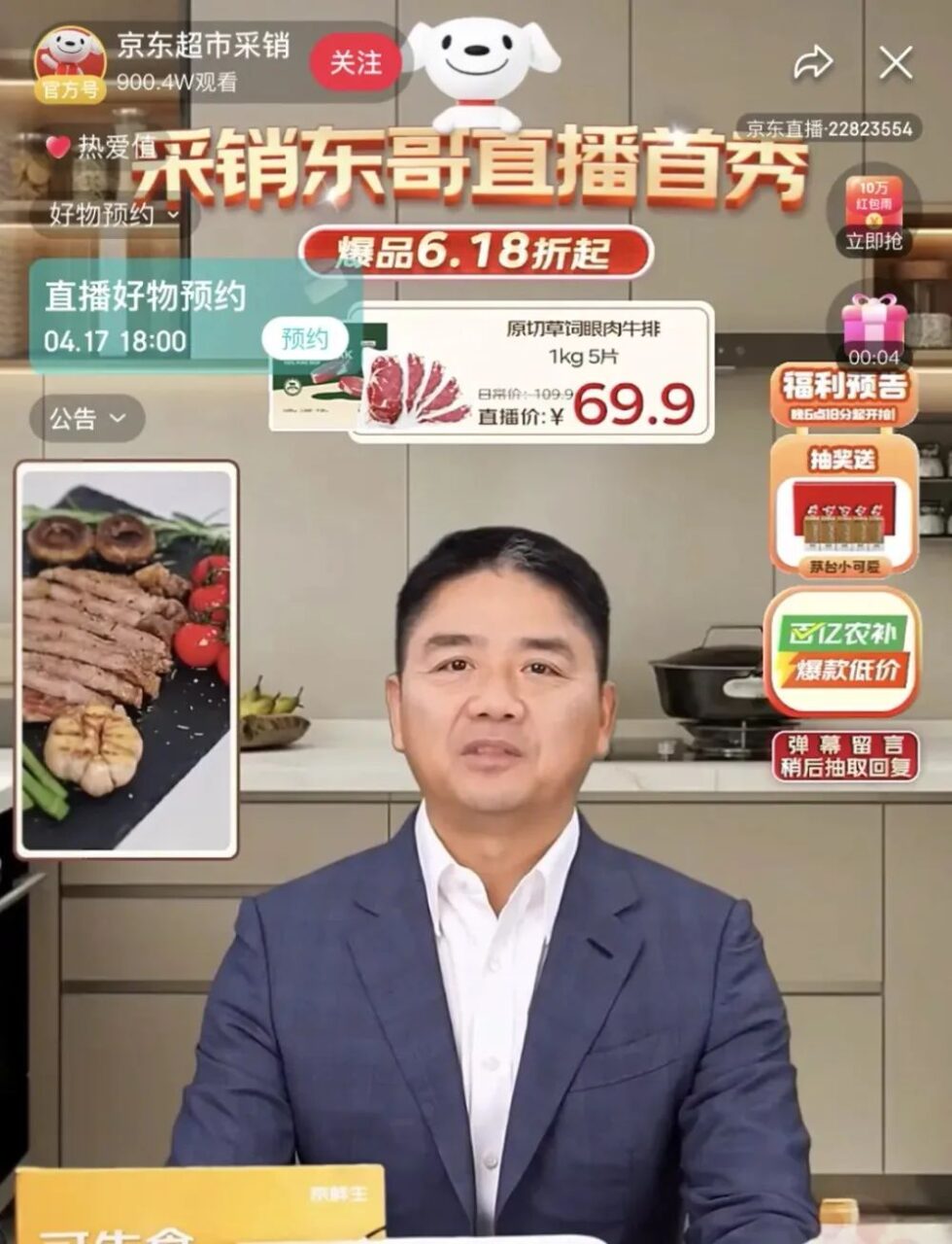
Source de l'image : Guanchazhe.com
Il est entendu que le « Dongge AI Digital Human Achats et Ventes » peut afficher avec précision les expressions, postures, gestes et caractéristiques de timbre personnalisés de Liu Qiangdong en apprenant et en entraînant son image et sa voix. Il est difficile de distinguer la différence entre l’humain numérique et la personne réelle à l’œil nu en 120 secondes.

IDC a déclaré dans son rapport « China's AI Digital Human Market Status and Opportunity Analysis 2022 » que l'ampleur du marché chinois de l'IA numérique devrait atteindre 10,24 milliards de yuans d'ici 2026. Il faut dire que les humains numériques IA sont reproductibles, peu coûteux et peuvent travailler 24 heures sur 24. Leur application dans des scénarios tels que les opérations d’auto-médias, la vente de courtes vidéos, la diffusion humaine numérique et l’assistance aux humains dans l’accomplissement de diverses tâches pourrait devenir une tendance majeure à l’avenir.
Dans ce domaine, la génération de visages parlants pilotée par l’audio est un sujet brûlant. Grâce à cette technologie, il vous suffit de saisir un clip vocal pour créer une vidéo parlante du visage de la personne cible, ce qui peut aider la personne cible à assister à certaines scènes où de vraies personnes sont gênées ou incapables d'apparaître. dans,GeneFace++ est une technologie générale et stable de génération de visages parlants 3D pilotée par l'audio en temps réel qui est la première à réaliser la génération de visages parlants en temps réel en améliorant la synchronisation labiale, la qualité vidéo et l'efficacité du système.
Plus précisément, GeneFace++ entraîne indépendamment le module audio-mouvement et le module mouvement instantané-vidéo. Le processus de formation implique la cartographie de l'apprentissage entre l'audio et les mouvements du visage, l'apprentissage par transfert pour l'adaptabilité du domaine et l'apprentissage de la technologie de rendu en temps réel de portraits 3D pilotée par des points de repère, ce qui permet finalement au modèle de générer des vidéos de visage parlant 3D synchronisées sur les lèvres, de haute qualité et en temps réel, basées sur un son arbitraire.
Cependant, créer un humain numérique réaliste en synchronisation labiale n’est pas une tâche facile. Afin d'aider les débutants à démarrer rapidement et à éviter les difficultés courantes de construction d'environnement et techniques,HyperIASuper NeuroLe tutoriel « GeneFace++ Digital Human Demo » a été lancé.Ce tutoriel a créé un environnement pour tout le monde et simplifié le processus de création d'humains numériques. Vous n’avez pas à vous soucier de problèmes tels que la configuration de l’environnement, les exigences matérielles et la compatibilité des versions. Cliquez simplement sur Cloner pour le démarrer en un clic, et l'effet est très réaliste !
Adresse du didacticiel public HyperAI Hyperneural :
https://hyper.ai/tutorials/31157
Préparation préliminaire
Préparez une vidéo de 3 à 5 minutes :
* L'image doit être claire et de taille carrée (de préférence 512*512) ;
* Afin que le modèle puisse mieux extraire l’arrière-plan, l’arrière-plan vidéo doit être d’une couleur unie sans autres facteurs d’interférence ;
* Les visages des personnes dans la vidéo doivent être clairs et relativement grands, et doivent être de face. Les images capturées doivent de préférence être au-dessus des épaules et les mouvements des personnes ne doivent être ni trop grands ni trop petits ;
* L'audio de la vidéo est exempt de bruit ;
* Il est préférable de nommer la vidéo en anglais.
Remarque : cette vidéo sera utilisée pour la formation du modèle. Plus la qualité vidéo est bonne, meilleurs sont les résultats. Il est donc nécessaire de consacrer plus de temps et d’efforts à la préparation des données.
Voici un exemple d’écran vidéo :

Essai de démonstration
1. Connectez-vous à hyper.ai et sur la page Tutoriel, sélectionnez GeneFace++ Digital Human Demo. Cliquez sur Exécuter ce didacticiel en ligne.

2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.

3. Cliquez sur « Suivant : sélectionner le taux de hachage » dans le coin inférieur droit.

4. Après le saut, sélectionnez « NVIDIA GeForce RTX 4090 » et cliquez sur « Suivant : Réviser ».Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps de calcul sans CPU !
Lien d'invitation exclusif HyperAI (copiez et ouvrez dans le navigateur pour vous inscrire) :
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej

5. Cliquez sur « Continuer » et attendez que les ressources soient allouées. Le premier processus de clonage prendra environ 3 à 5 minutes. Lorsque le statut passe à « En cours d’exécution », cliquez sur « Ouvrir l’espace de travail ». Si le problème persiste pendant plus de 10 minutes et que le système est toujours dans l’état « Allocation des ressources », essayez d’arrêter et de redémarrer le conteneur. Si le redémarrage ne résout toujours pas le problème, veuillez contacter le service client de la plateforme sur le site officiel.



6. Après avoir ouvert l'espace de travail, créez une nouvelle session de terminal sur la page de démarrage, puis entrez le code suivant dans la ligne de commande pour démarrer l'environnement. Il suffit de le copier et de le coller.
conda env export -p /output/geneface
conda activer /output/geneface


7. Attendez un instant et exécutez la commande suivante dans le terminal pour configurer les variables d’environnement.
source bashrc

8. Attendez un moment, entrez le code suivant dans la ligne de commande pour démarrer l'interface Web et attendez environ 1 minute.
/openbayes/home/start_web.sh
9. Lorsque la ligne de commande affiche « Exécution sur l'URL locale : https://0.0.0.0:8080 », copiez l'adresse API à droite dans la barre d'adresse du navigateur pour accéder à l'interface GeneFace++.Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.

Affichage des effets
1. Après avoir ouvert l'interface GeneFace++, importez la vidéo préparée à l'avance, sélectionnez le nombre d'étapes de formation « 50 000 » et cliquez sur « Former » pour démarrer la formation.
Remarque : cette étape nécessite une attente de plus de 2 heures. Pendant cette période, vous pouvez vérifier 1 à 2 fois si la formation se déroule normalement pour éviter toute perte de temps causée par l'interruption du processus mais toujours en attente.
Le nombre d'étapes de formation « 50 000 » ici est par défaut. Si les résultats de 50 000 étapes d'entraînement sont médiocres, veuillez modifier les données d'entraînement et vous entraîner à nouveau.

2. Lorsque « Train Success » apparaît, actualisez l'interface GeneFace++.

3. Dans l'interface GeneFace++, téléchargez l'audio sur la gauche et ne modifiez pas les paramètres du module du milieu.
Sélectionnez le modèle de pilote audio « model_ckpt_steps_400000.ckpt » dans le modèle de droite.
Sélectionnez le modèle de torse « model_ckpt_steps_50000.ckpt » correspondant à l'entraînement de moins de 50 000 pas.
Sélectionnez le modèle de tête « model_ckpt_steps_50000.ckpt » correspondant à l'entraînement de moins de 50 000 pas.
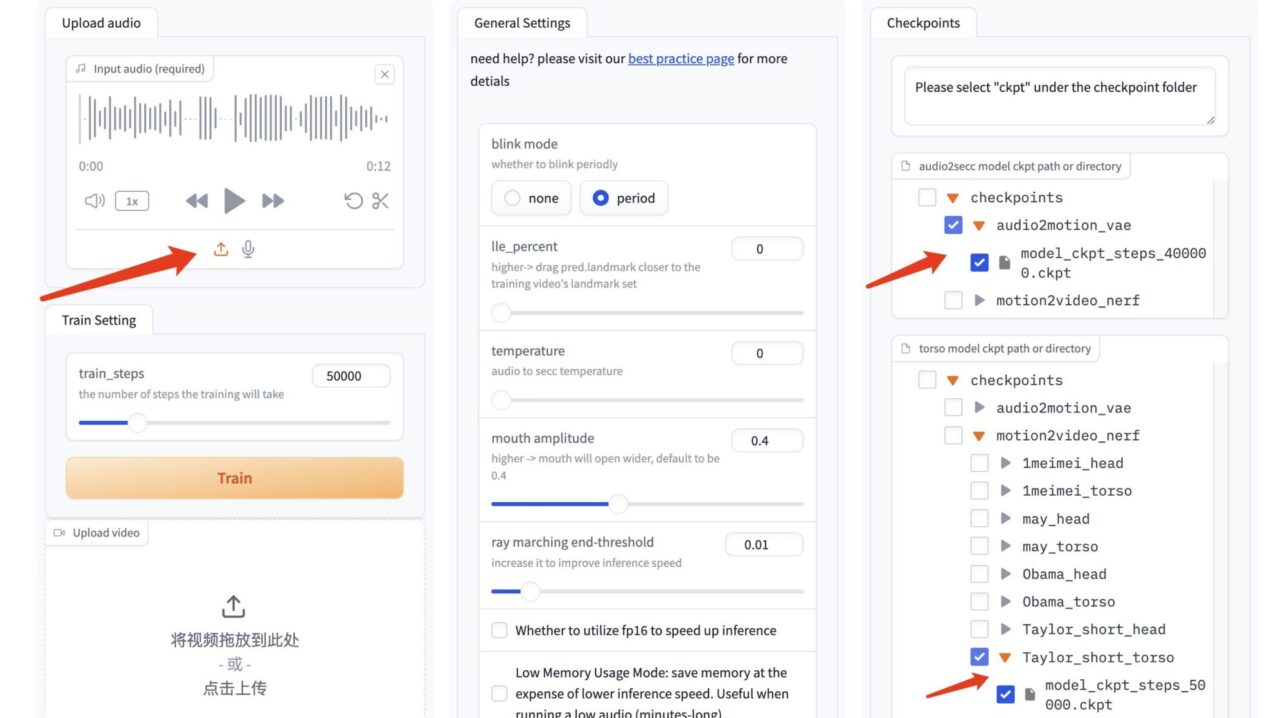
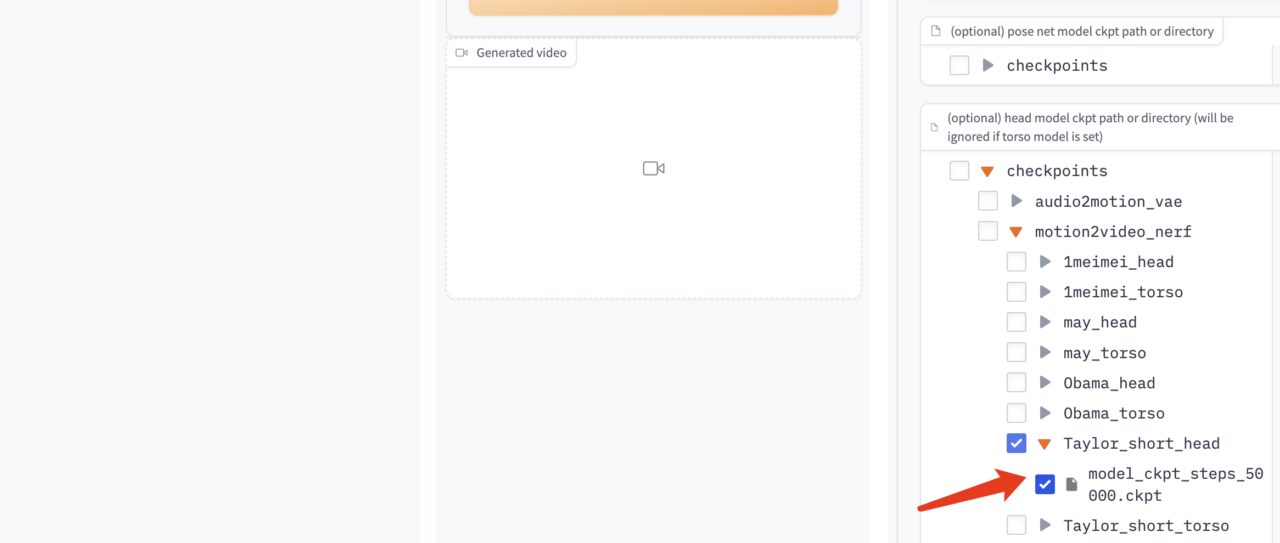
4. Cliquez sur « Générer » pour générer l'effet.

5. Si vous souhaitez une formation complémentaire. Supprimez le dossier head_done et le dossier torso_done sous le modèle correspondant.
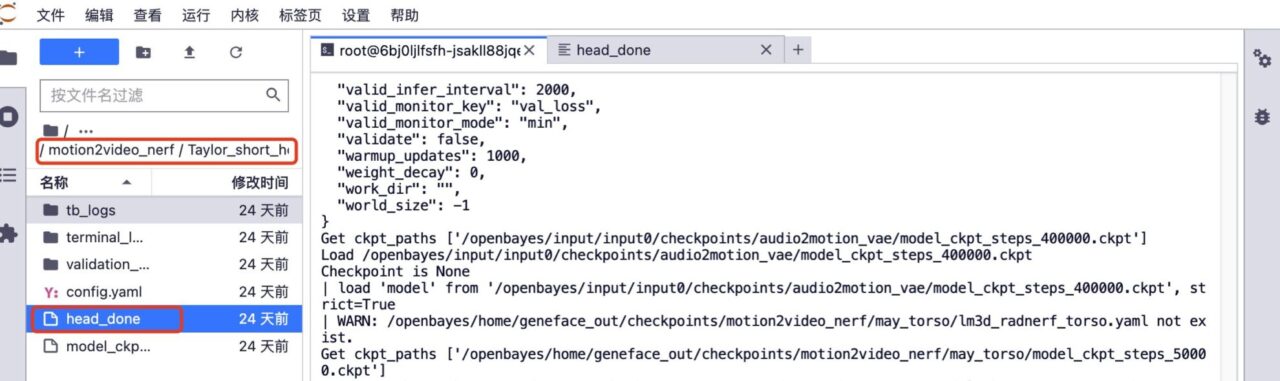
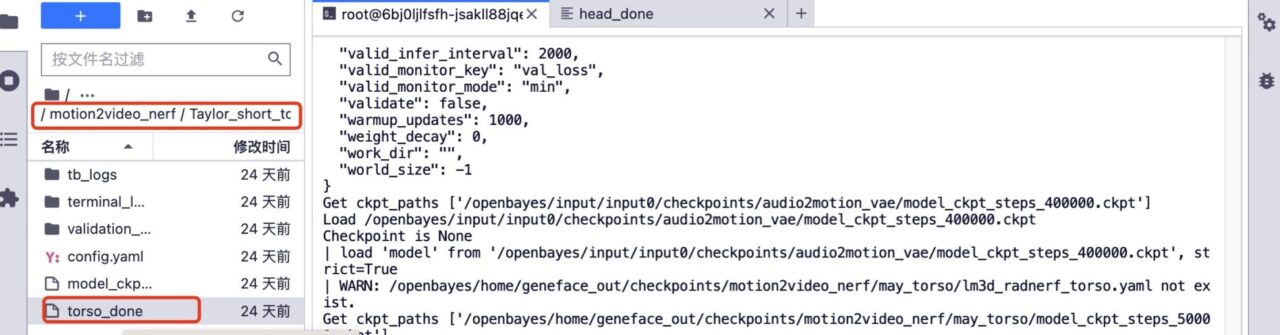
6. Téléchargez la vidéo de formation précédente, conservez le nom du fichier vidéo inchangé, augmentez le nombre d'étapes de formation et cliquez sur « Former » pour démarrer la formation.


7. Une fois la formation terminée, dans l'interface GeneFace++, sélectionnez le modèle audio par défaut, le modèle de torse correspondant à la formation de 150 000 pas et le modèle de tête correspondant à la formation de 150 000 pas. Cliquez sur « Générer » pour générer l’effet final.
À l’heure actuelle, le site Web officiel d’HyperAI a lancé des centaines de tutoriels sélectionnés liés à l’apprentissage automatique, qui sont organisés sous la forme de Jupyter Notebook.
Cliquez sur le lien pour rechercher des tutoriels et des ensembles de données associés :
Ce qui précède est tout le contenu partagé par l'éditeur cette fois-ci. J'espère que ce contenu vous sera utile. Si vous souhaitez apprendre d'autres tutoriels intéressants, veuillez laisser un message ou nous envoyer un message privé à l'adresse du projet. L'éditeur vous concoctera un cours sur mesure et vous apprendra à jouer avec l'IA.
Références :
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/128895215








