Command Palette
Search for a command to run...
Nouvelles Utilisations Pour Les Anciens Médicaments : AdaDR Publié Par l'équipe De l'Université Centrale Du Sud Pour Le Repositionnement Des Médicaments Basé Sur Des Réseaux Convolutifs De Graphes Adaptatifs

Dans la société moderne, les humains doivent continuer à lutter contre des maladies complexes de plus en plus répandues telles que le cancer, le diabète et les maladies cardiovasculaires. Les médicaments existants ne peuvent plus répondre pleinement à la demande du marché et le développement de nouveaux médicaments est impératif. Cependant, le processus traditionnel de découverte de médicaments prend du temps et nécessite beaucoup d’investissements. Si nous pouvons examiner de manière proactive de nouveaux médicaments et cibles thérapeutiques à partir de médicaments antérieurs et de composés abandonnés, nous pouvons évidemment réduire considérablement les coûts de R&D et améliorer l’efficacité de la R&D.
Le repositionnement de médicaments, ou « nouvelles utilisations pour d’anciens médicaments », est une approche de développement de médicaments approuvée par la FDA qui applique les traitements existants à de nouveaux processus pathologiques. Par exemple, le sildénafil était à l’origine utilisé pour traiter les douleurs thoraciques, mais il s’est avéré plus tard être un inhibiteur de la PDE5 (phosphodiestérase de type 5), ce qui a rendu le sildénafil très populaire sur le marché.
En raison de ses avantages tels que la réduction des risques liés aux médicaments, le raccourcissement des cycles d’évaluation clinique, le faible coût et la grande efficacité, le repositionnement des médicaments existants est devenu un sujet brûlant dans la recherche industrielle actuelle.Avec le développement rapide de l’apprentissage en profondeur, les réseaux convolutifs graphiques (GCN) ont été largement utilisés dans les tâches de relocalisation de médicaments. Cependant, les méthodes existantes basées sur GCN présentent des limites dans l’intégration en profondeur des fonctionnalités des nœuds et des structures topologiques. En réponse à cela, des chercheurs de l'Université Centrale du Sud ont publié un article intitulé « Repositionnement de médicaments avec des réseaux convolutionnels de graphes adaptatifs » dans Bioinformatics.
Cette étude a proposé une méthode GCN adaptative appelée AdaDR pour effectuer le repositionnement des médicaments en intégrant en profondeur les caractéristiques des nœuds et les structures topologiques.Différent des réseaux convolutionnels de graphes traditionnels, AdaDR simule les informations interactives entre eux via des opérations de convolution de graphes adaptatives, améliorant ainsi la puissance expressive du modèle.
Plus précisément, AdaDR extrait les intégrations à partir des caractéristiques des nœuds et des structures topologiques, et utilise un mécanisme d'attention pour apprendre les pondérations d'importance adaptatives des intégrations.
Les résultats expérimentaux montrent qu’AdaDR surpasse plusieurs méthodes de base en matière de repositionnement de médicaments. De plus, dans les études de cas, des analyses exploratoires sont fournies pour découvrir de nouvelles associations médicament-maladie.
Points saillants de la recherche :
* Cette étude propose un cadre de réseau convolutionnel graphique adaptatif pour les tâches de relocalisation de médicaments, effectuant des opérations de convolution graphique sur des structures topologiques et des espaces de caractéristiques.
* Compte tenu des différences entre les structures et les caractéristiques topologiques, cette étude utilise le mécanisme d'attention pour les intégrer pleinement afin de distinguer leurs contributions aux résultats du modèle
* Le modèle proposé dans cette étude est pratique dans les tâches de repositionnement de médicaments et contribue à réduire le risque d'échec du développement de médicaments
Adresse du document :
https://academic.oup.com/bioinformatics/article/40/1/btad748/7467059
Adresse de téléchargement du jeu de données :
Suivez le compte officiel et répondez « relocation » pour obtenir le PDF complet
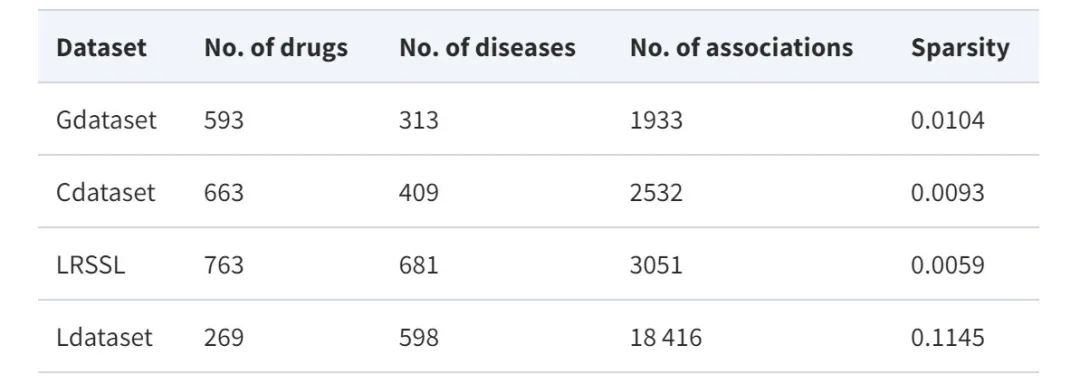
Ensemble de données : Utilisation de quatre principaux ensembles de données de référence
Afin d'évaluer de manière exhaustive les performances du modèle proposé,Cette étude a utilisé quatre ensembles de données de référence largement utilisés dans les tâches de repositionnement de médicaments, à savoir Gdataset, Cdataset, Ldataset et LRSSL.
* Gdataset :Considéré comme l'ensemble de données de référence, il comprend 593 médicaments de DrugBank et 1 933 associations médicament-maladie confirmées entre 313 maladies répertoriées dans la base de données OMIM.
* Ensemble de données C :Contient 663 médicaments, 409 maladies et 2 352 associations médicament-maladie en interaction.
* Ldataset :Compilé à partir de l'ensemble de données CTD, il comprend 18 416 associations entre 269 médicaments et 598 maladies.
*LRSSL :Au total, 3 051 associations médicament-maladie validées impliquant 763 médicaments et 681 maladies ont été incluses.
Parallèlement, afin de construire une carte des caractéristiques des médicaments et des maladies, l’étude a également utilisé les caractéristiques de similarité des médicaments et des maladies. Les statistiques de l'ensemble de données sont présentées dans le tableau suivant :
Architecture du modèle : un nouveau cadre GCN adaptatif AdaDR
Le cadre du modèle AdaDR proposé dans cette étude comprend principalement trois composants. Comme le montre la figure suivante :
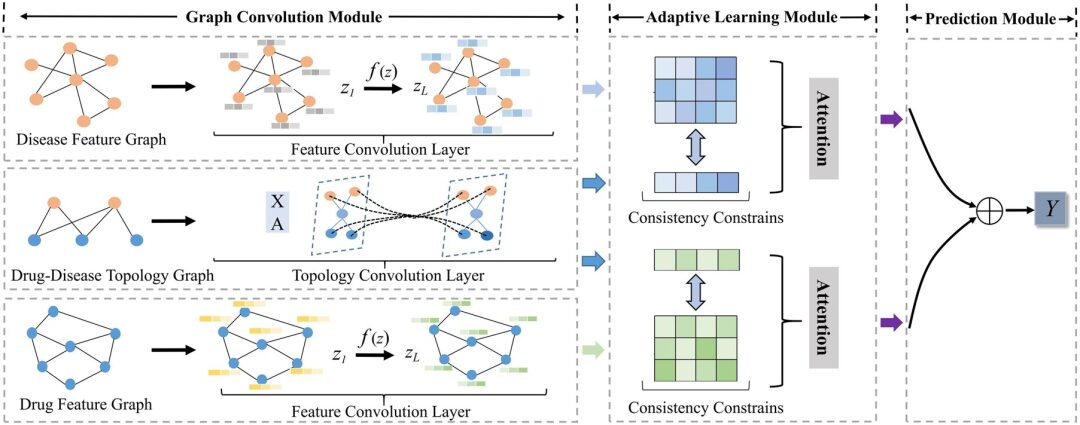
* Module de convolution graphique :Contient des couches convolutionnelles de fonctionnalités et des couches convolutionnelles topologiques pour représenter les inclusions de médicaments/maladies dans l'espace des fonctionnalités et l'espace topologique.
* Module d'apprentissage adaptatif :Le mécanisme d’attention est utilisé pour distinguer l’importance des inclusions acquises. Dans ce module, les contraintes de cohérence sont utilisées pour extraire des informations sémantiques communes entre les espaces de caractéristiques et topologiques.
* Module de prédiction :Les intégrations sont concaténées ensemble en tant que sortie pour prédire le résultat.
Résultats de recherche : AdaDR surpasse plusieurs méthodes de base en matière de repositionnement de médicaments
Dans l’ensemble, AdaDR, en tant que nouveau modèle, peut améliorer considérablement les performances des tâches de repositionnement des médicaments.
Tout d’abord, les performances en validation croisée :Cette étude a effectué une validation croisée 10 fois sur AdaDR et d’autres modèles, et a calculé la moyenne et l’écart type des résultats.
Selon les résultats, grâce à la capacité d'intégration des fonctionnalités d'AdaDR, ses résultats moyens finaux sur quatre ensembles de données obtenus lors de 10 validations croisées décuplées ont surpassé toutes les méthodes comparées.
Par exemple, sur les quatre jeux de données de référence Gdataset, Cdataset, LRSSL et Ldataset,Les résultats de cette étude sont respectivement 9,8%, 9,1%, 9,1% et 7,1% supérieurs à l'AUPRC (aire sous la précision-rappel) de la deuxième meilleure méthode DRHGCN, démontrant pleinement l'efficacité de la nouvelle méthode.
Vient ensuite la capacité de prédire les indications potentielles de nouveaux médicaments :Cette étude a mené une nouvelle expérience pour évaluer la capacité d’AdaDR à prédire les indications potentielles de nouveaux médicaments.
Comparé aux 7 autres méthodes, AdaDR obtient les meilleures performances (la barre bleue dans la figure ci-dessous représente AdaDR). En termes d'AUROC (aire sous la courbe caractéristique de fonctionnement du récepteur), comme le montre la figure (a) ci-dessous, AdaDR atteint une valeur AUROC de 0,948, ce qui est meilleur que les autres méthodes. Pendant ce temps, comme le montre la figure (b) ci-dessous, AdaDR atteint un AUPRC de 0,393, ce qui est supérieur à toutes les autres méthodes.
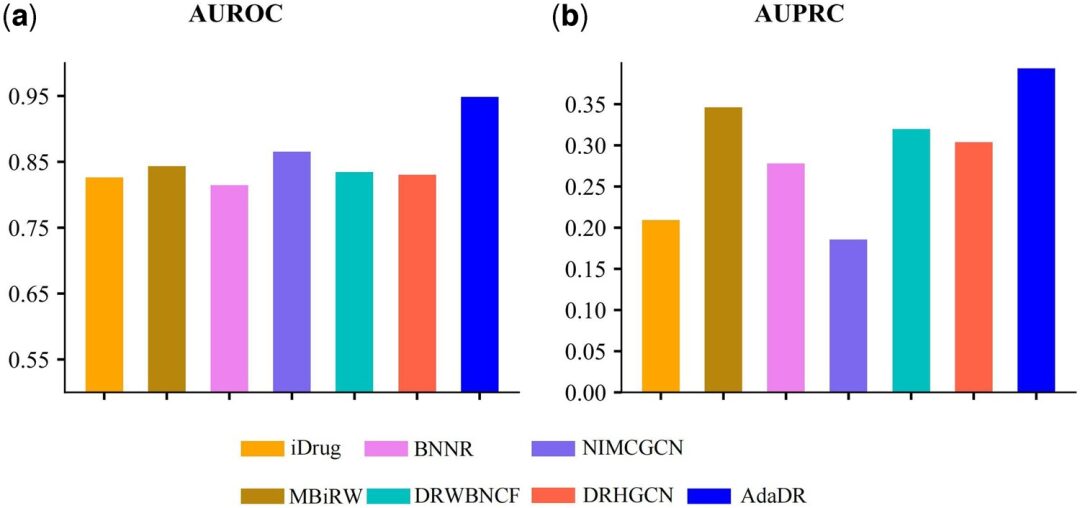
(a) AUROC des résultats de prédiction obtenus à l'aide d'AdaDR et d'autres méthodes concurrentes.
(b) AUPRC des résultats de prédiction obtenus en appliquant AdaDR et d'autres méthodes concurrentes.
Il convient de mentionner qu'afin de vérifier davantage les performances d'AdaDR, l'équipe de recherche a également appliqué AdaDR pour prédire les médicaments candidats pour la maladie d'Alzheimer (MA) et le cancer du sein (BRCA).
Parmi elles, la maladie d’Alzheimer est une maladie neurodégénérative à évolution progressive pour laquelle il n’existe actuellement aucun médicament efficace. Le cancer du sein est un phénomène dans lequel les cellules épithéliales mammaires prolifèrent de manière incontrôlable sous l’influence de multiples facteurs cancérigènes. Bien qu’il existe déjà une variété de médicaments pour traiter le cancer du sein, tels que le paclitaxel, le carboplatine, etc., davantage d’options médicamenteuses pourraient offrir de meilleures options de traitement. Le tableau ci-dessous présente les candidats médicaments avec des preuves à l’appui :
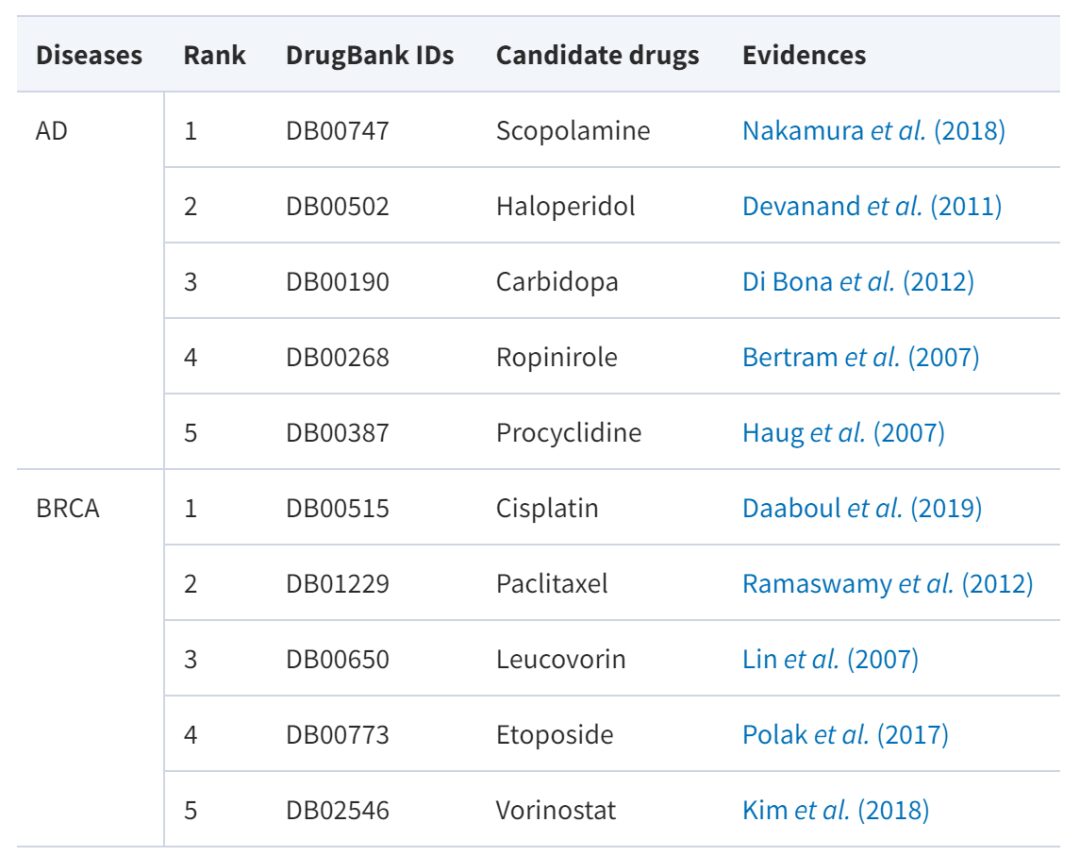
On peut constater que parmi les cinq premiers médicaments dans les scores de prédiction AdaDR, beaucoup ont été vérifiés par des sources et des publications faisant autorité (taux de réussite 100%). De plus, le modèle de l’étude peut produire des résultats interprétables. Prenant le paclitaxel comme exemple, le modèle prédit qu’il peut traiter le cancer du sein. Ceci est en effet soutenu par des sources et des écrits faisant autorité.
Il est intéressant de noter que les chercheurs ont découvert que le docétaxel figurait dans leur ensemble d’entraînement. Alors que le paclitaxel et le docétaxel sont des molécules similaires avec le même noyau de paclitaxel.Cela montre que le nouveau modèle peut utiliser les informations de similarité des médicaments pour faire des prédictions significatives.
Le retour sur investissement dans la R&D pharmaceutique continue de baisser, et le repositionnement des médicaments pourrait être la clé pour sortir de l'impasse.
Aujourd’hui, les sociétés pharmaceutiques connaissent des changements sans précédent. La pandémie de COVID-19 et la récession économique qui en a résulté ont posé une série de défis et d’incertitudes aux sociétés pharmaceutiques, les retours sur l’innovation devenant une priorité absolue pour chaque société pharmaceutique.
Bien que les sociétés biopharmaceutiques aient investi massivement dans la R&D pour l’innovation au cours de la dernière décennie, les rendements ont considérablement diminué au cours de la même période. L'évaluation du taux de retour sur investissement de l'innovation pharmaceutique 2019 publiée par le Centre Deloitte pour les solutions de santé montre que le retour sur investissement en R&D dans l'industrie pharmaceutique en 2019 était à son plus bas niveau depuis 2010, à seulement 1,8%. Selon les données des dix rapports, le retour sur investissement en R&D des sociétés pharmaceutiques a suivi une tendance à la baisse au cours de la dernière décennie.
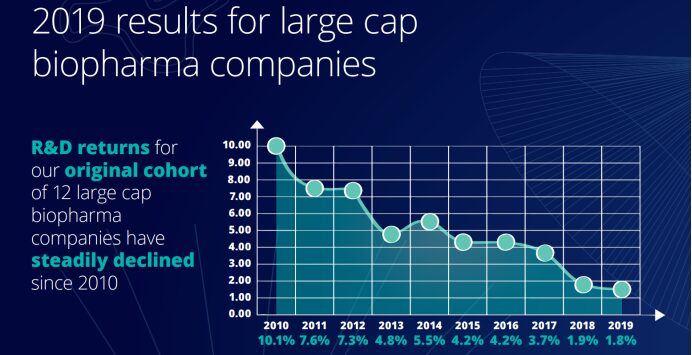
De plus, les ventes maximales de chaque nouveau médicament après son lancement ont également chuté de 407 millions de dollars américains en 2018 à 376 millions de dollars américains en 2019, tombant pour la première fois en dessous de 400 millions de dollars américains et à moins de la moitié des 816 millions de dollars américains de 2010. Le coût du lancement d'un nouveau médicament a augmenté de 67% par rapport à 2010, passant de 1,188 milliard de dollars en 2010 à 1,981 milliard de dollars en 2019.La baisse des ventes maximales contraste fortement avec l’augmentation du coût moyen de mise sur le marché d’un nouveau médicament, ce qui suggère que les sociétés pharmaceutiques consacrent plus de temps que jamais au processus de recherche et développement.
Les médicaments repositionnés peuvent permettre d’économiser les coûts initiaux et le temps nécessaire à la mise sur le marché d’un médicament, accélérant ainsi la transition entre les travaux de recherche fondamentale et le traitement clinique. Selon les initiés du secteur, un nouveau médicament doit passer par une série d’études, notamment in vitro, précliniques sur les animaux et cliniques de phases I, II et III, depuis le début de la recherche et du développement jusqu’à l’approbation de la commercialisation. Dix à quinze ans est une durée normale et cela coûte au moins 1 milliard de dollars. En comparaison, certaines études montrent que le repositionnement d’un médicament coûte en moyenne 300 millions de dollars et prend environ 6,5 ans pour atteindre le marché.
Le repositionnement des médicaments comprend principalement des méthodes basées sur l’apprentissage automatique, des méthodes basées sur l’exploration et le positionnement de données volumineuses et des méthodes basées sur le positionnement in vivo.Par rapport aux méthodes in vivo, la technologie de repositionnement de médicaments basée sur l'apprentissage automatique et l'exploration de données volumineuses présente les avantages d'une vitesse rapide et d'un faible coût, et est devenue une technologie potentiellement puissante.
L'article « A Review of Drug Repositioning Algorithms Based on Machine Learning and Big Data Mining » présente les progrès de la recherche sur le repositionnement informatique des médicaments au cours des dernières années.
dans,Basé sur la méthode traditionnelle de l'algorithme d'apprentissage automatique,Tout d'abord, les informations sur les médicaments et les effets secondaires, les informations sur la structure chimique des médicaments et les informations relatives aux maladies et aux gènes sont intégrées, puis les données de formation sont obtenues grâce à l'extraction et à la sélection de caractéristiques, puis l'algorithme d'apprentissage automatique pertinent est sélectionné pour la formation, et enfin le modèle d'algorithme formé est utilisé pour obtenir les résultats de repositionnement du médicament.
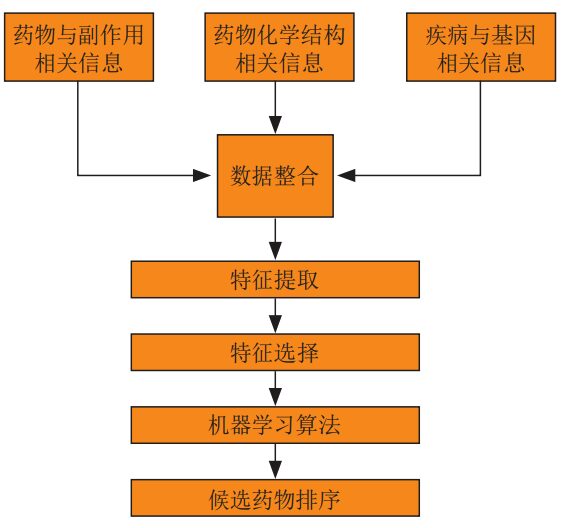
Dans les méthodes basées sur l'apprentissage profond,Certains chercheurs ont systématiquement comparé les réseaux neuronaux profonds avec diverses autres méthodes d’apprentissage automatique dans de multiples aspects du développement de médicaments. Les résultats montrent que l’apprentissage profond est plus performant que les algorithmes d’apprentissage automatique traditionnels.
Dans la méthode de raisonnement par similarité de réseau,Une équipe de recherche de l'Université des sciences et technologies de Chine orientale a proposé une méthode d'inférence basée sur le réseau (NBI) qui déduit de nouvelles cibles de médicaments connus en utilisant uniquement la similarité topologique des réseaux bipartites médicament-cible.
Avec le développement de la technologie d'exploration de données volumineuses, le repositionnement des médicaments basé sur l'apprentissage automatique et les algorithmes d'exploration de données volumineuses fournira des méthodes de plus en plus efficaces pour le traitement des maladies et est devenu le centre de la recherche biomédicale. Il y a des raisons de croire que le raisonnement rationnel et la modélisation informatique joueront un rôle important dans les futurs processus de repositionnement des médicaments.
Références :
1.https://www.cn-healthcare.com/article/20191224/content-527902.html
2.https://pps.cpu.edu.cn/cn/article/pdf/preview/b286f85e-a37a-4007-ab94-918629aef556.pdf
3.https://mp.weixin.qq.com/s/lD-HyfwUHiX4f-llS6lykQ








