Command Palette
Search for a command to run...
Tutoriel En Ligne | Lancement En Un Clic De l'alternative Open Source De Sora, Capturant 450 000 Développeurs d'IA

En 1888, Edison déposa un brevet pour un « projecteur d'images animées », un appareil qui, pour la première fois, lisait des photos statiques en continu, créant un effet d'image dynamique, ouvrant ainsi la voie au développement de la vidéo.
En regardant l’histoire, la vidéo a connu des itérations allant de rien à quelque chose, du noir et blanc à la couleur et des signaux analogiques aux signaux numériques. Dans le passé, la production vidéo comprenait plusieurs étapes telles que la création d’un script/scénario, le tournage, le montage, le doublage et la relecture. À ce jour, tout, des vidéos populaires sur les plateformes de vidéos courtes aux films à gros budget projetés dans les salles de cinéma, suit toujours ce format de production à longue chaîne.
Ces dernières années, avec l’émergence de l’IA générative, la production vidéo a également inauguré l’innovation.Depuis l’émergence de ChatGPT, la capacité de l’IA générative à comprendre le texte a apporté à plusieurs reprises des surprises.
Le 26 février, OpenAI a publié le modèle Sora, qui peut générer jusqu'à une minute de vidéo en recevant des instructions textuelles. Non seulement il a une bonne capacité à comprendre de longs textes, mais il peut également comprendre et simuler des situations physiques du monde réel, générant des scènes complexes avec plusieurs personnages et des types de mouvements spécifiques qui sont à la fois logiques et réalistes.Cependant, OpenAI n'a publié qu'une vidéo de démonstration du modèle Sora, et l'accès à celle-ci n'a été accordé qu'à un petit nombre de chercheurs et de créatifs.
Dans le même temps, il existe désormais de nombreux modèles vidéo open source générés par l’IA et disponibles pour une utilisation gratuite. Jack-Cui, un up-master populaire sur Bilibili, a présenté dans son tutoriel vidéo que la meilleure solution de génération de vidéo IA open source actuellement est la combinaison de Stable Diffusion + Prompt Travel + AnimateDiff.
Parmi eux, Stable Diffusion est un « modèle de diffusion latente » qui mappe d'abord les données originales de haute dimension (telles que les images) à l'espace latent via l'encodeur, diffuse et débruite dans cet espace, puis reconstruit les données nettoyées dans l'espace latent vers l'espace de haute dimension via le décodeur.Le résultat final est de générer une image statique correspondante selon les instructions du texte.
Par rapport au modèle de diffusion actuel dans le domaine de la génération de vidéos IA, Stable Diffusion introduit une étape d'encodage-décodage supplémentaire, qui lui permet d'être appliqué à des données de haute dimension (telles que des images) dans un espace latent de faible dimension qui contient des caractéristiques importantes des données d'origine.Amélioration de l'efficacité et de la qualité de génération du modèle.
Voyage rapide est un ajustementInstructions textuellesDe cette façon, les utilisateurs peuvent fournir différents mots-clés et descriptions dans différentes chronologies de la vidéo en fonction de leurs intentions créatives, guidant le modèle d'IA pour générer une série d'images cohérentes et changeantes.
Enfin, AnimateDiff ajoute un élément nouvellement initialiséModule de modélisation de mouvementet utilisez l'ensemble de données de clips vidéo pour former des connaissances préalables raisonnables sur les mouvements. Une fois le module de mouvement formé, il est inséré dans le modèle graphique basé sur du texte, permettant au modèle de générer des clips vidéo textuels divers et personnalisés.
Actuellement, le didacticiel de déploiement de modèle a été lancé sur le site officiel d'HyperAI et vous pouvez le cloner en un clic.
https://hyper.ai/tutorials/30038
Le « tutoriel en ligne Stable-Diffusion » produit par Jack-Cui, un maître populaire sur Bilibili, est le suivant. Ce tutoriel vous apprendra étape par étape comment maîtriser la peinture IA et les vidéos générées par IA en un seul clic !
Selon le tutoriel, l'éditeur a réussi à générer diverses belles images et vidéos, et l'effet est tout simplement incroyable !

Essai de démonstration
1. Cliquez sur « Exécuter ce didacticiel en ligne » pour accéder à OpenBayes et obtenir gratuitement RTX 4090.
2. Cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
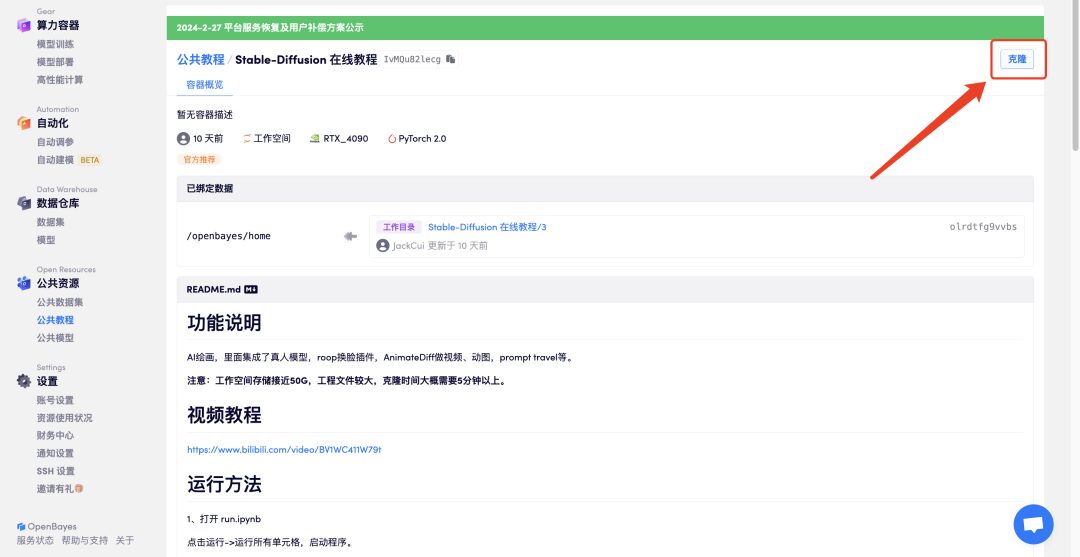
3. Cliquez sur « Vérifier et exécuter » - « Continuer l'exécution ». Il est recommandé d'utiliser RTX 4090. Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps de calcul sans CPU !
Lien d'invitation :
https://openbayes.com/console/signup?r=GraceXiii_W8qO
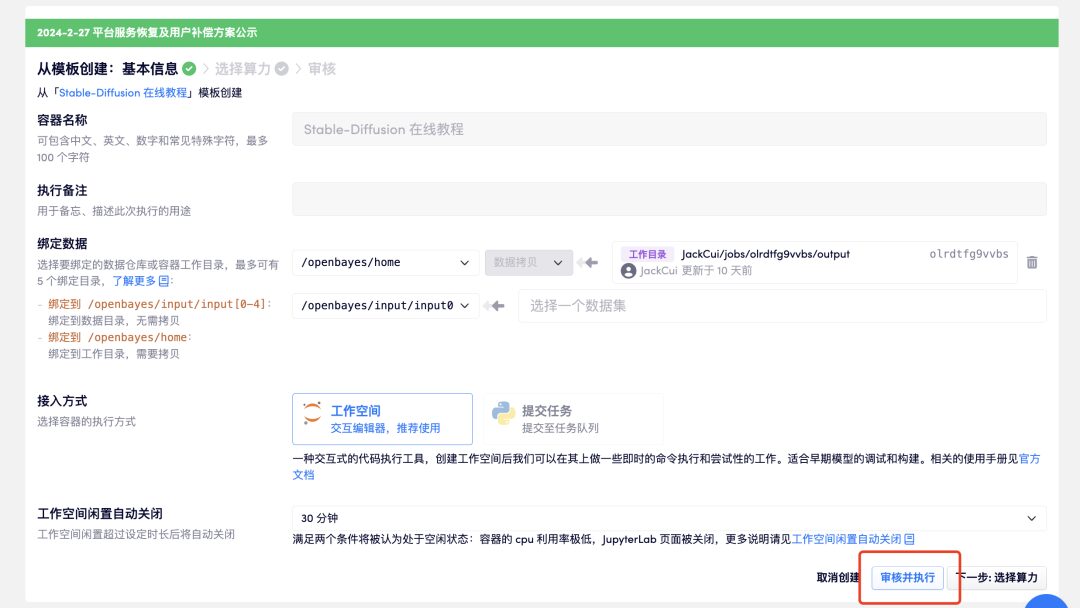
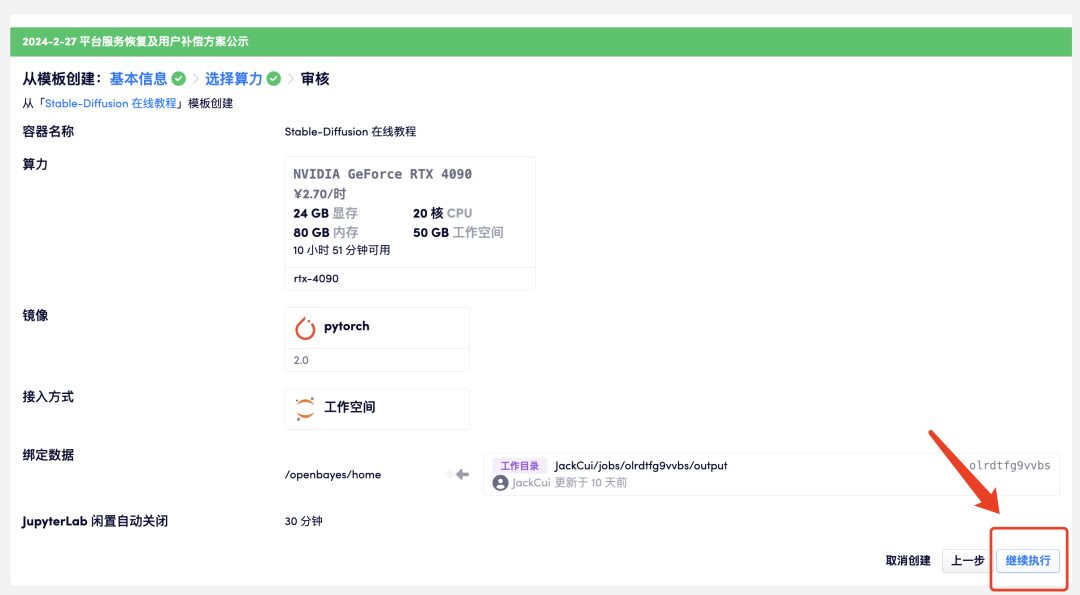
4. Attendez un moment, puis lorsque le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail ». Le conteneur contient une grande quantité de données. Il faut environ 8 à 10 minutes pour démarrer le conteneur pour la première fois. S'il vous plaît soyez patient.
Si le conteneur est toujours dans l'état « allocation de ressources » pendant plus de 15 minutes, vous pouvez essayer d'arrêter et de redémarrer le conteneur ; si le problème ne peut toujours pas être résolu après le redémarrage, veuillez contacter le service client de la plateforme sur le site officiel.
5. Après avoir ouvert l'espace de travail, cliquez sur « run.ipynb » sur la gauche, puis cliquez sur « Exécuter toutes les cellules » via le bouton « Exécuter » de la barre de menus.
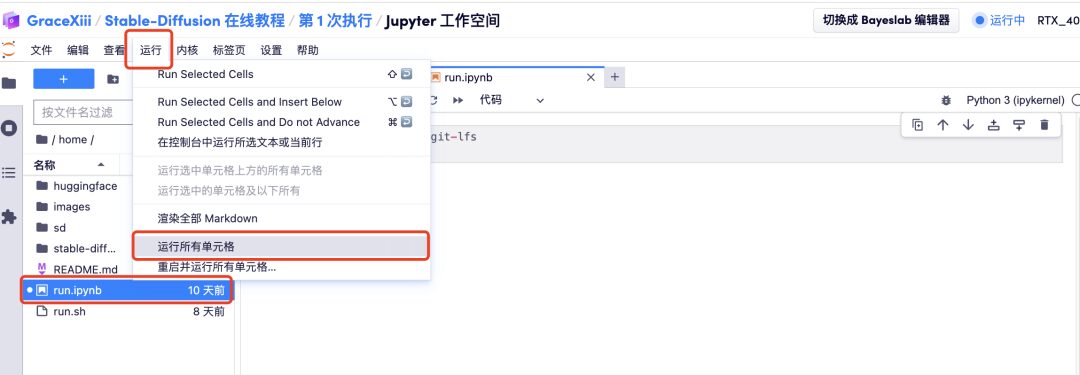
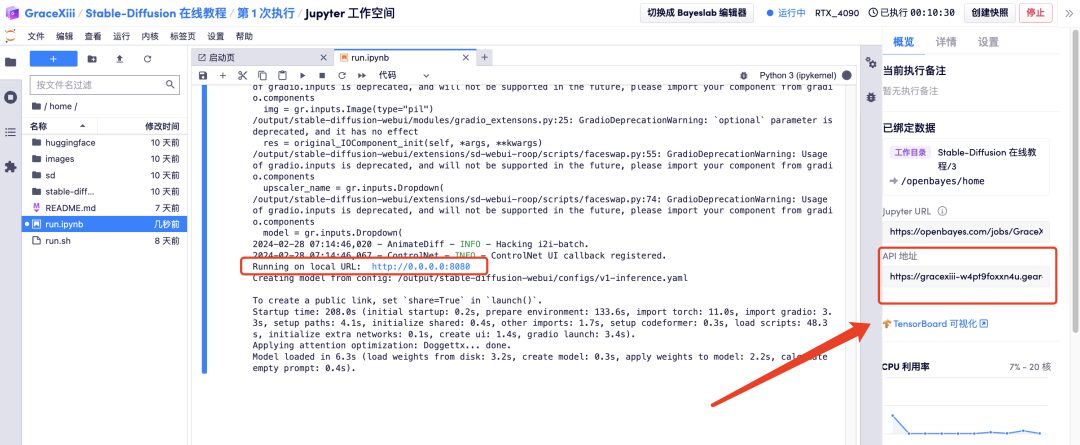
6. Attendez un moment, puis une fois l'URL locale générée, ouvrez l'« Adresse API » sur la droite. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
Affichage des effets
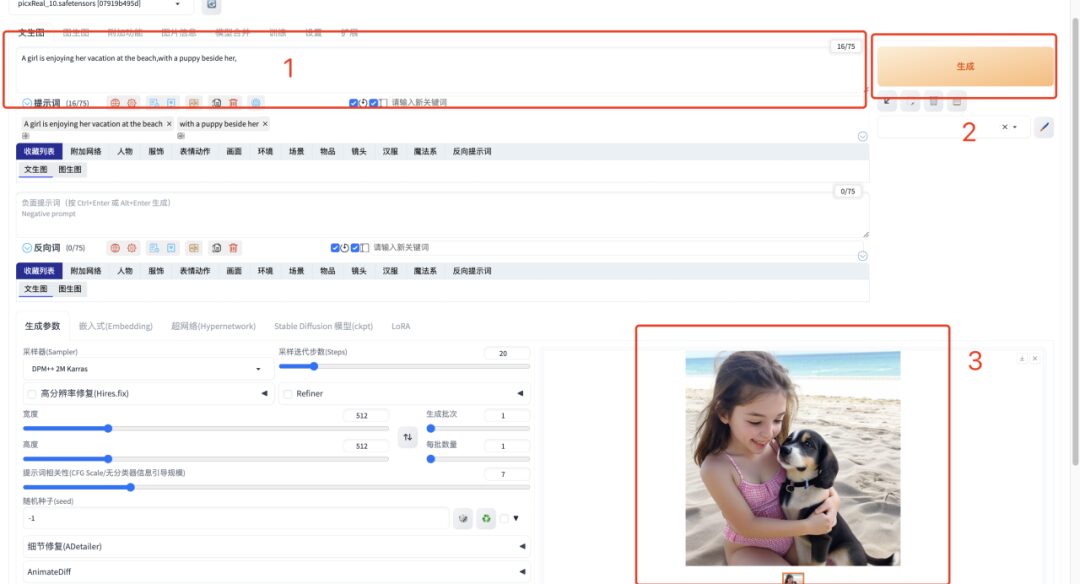
1. Après avoir ouvert l'« adresse API », saisissez le mot d'invite en anglais dans la zone de texte et cliquez sur « Générer ». Il ne faut qu'une seconde pour générer rapidement l'image.
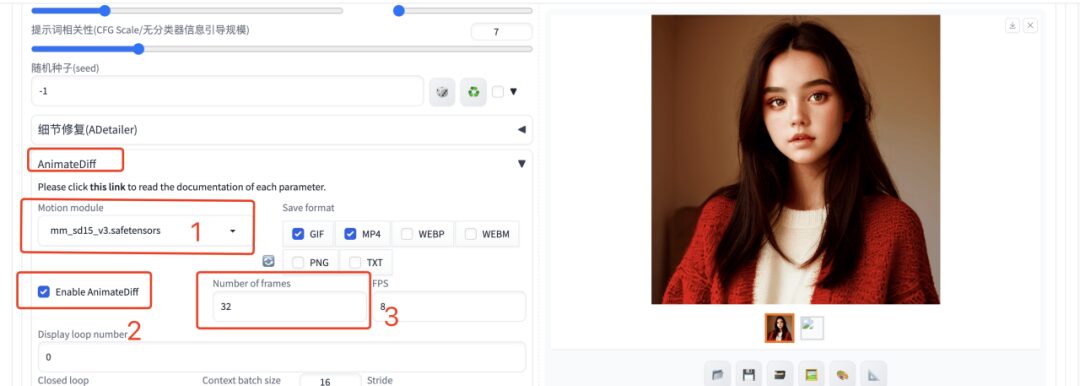
2. Si vous souhaitez générer une vidéo, vous devez saisir le mot d'invite en anglais, sélectionner le plug-in AnimateDiff, renseigner le nombre d'images générées à 32 images et laisser les autres paramètres par défaut. Attendez un instant et vous pourrez générer l’image ou la vidéo animée.
À l’heure actuelle, le site Web officiel d’HyperAI a lancé des centaines de tutoriels sélectionnés liés à l’apprentissage automatique, qui sont organisés sous la forme de Jupyter Notebook.
Cliquez sur le lien pour rechercher des tutoriels et des ensembles de données associés :
Ce qui précède est tout le contenu partagé par l'éditeur cette fois-ci. J'espère que ce contenu vous sera utile. Si vous souhaitez découvrir d'autres tutoriels intéressants, veuillez laisser un message pour nous indiquer l'adresse du projet. L'éditeur vous concoctera un cours sur mesure et vous apprendra à jouer avec l'IA.
Références :
1.https://zhuanlan.zhihu.com/p/627133524
2.https://fuxi.163.com/database/739
3.https://zhuanlan.zhihu.com/p/669814884








