Command Palette
Search for a command to run...
NVIDIA Huang Renxun a Lancé GB200, Qui a Une Capacité De Raisonnement 30 Fois Supérieure À Celle Du H100 Et Une Consommation d'énergie 25 Fois Inférieure, Transformant Les Capacités AI4S En Microservices

« Le moment iPhone de l’IA est arrivé. » Les paroles d'or de Huang Renxun lors de la NVIDIA GTC 2023 sont encore fraîches dans nos esprits. Cette année, le développement de l’IA a également prouvé que ce qu’il disait était vrai.
Au fil des années, avec l'accélération du développement de l'IA et la difficulté à ébranler les fossés technologiques et écologiques de Nvidia, GTC est progressivement passée d'une conférence technique initiale à un événement de l'industrie de l'IA auquel toute la chaîne industrielle prête attention. La « force » déployée par Nvidia pourrait être un catalyseur important pour l’innovation industrielle.
La conférence GTC AI 2024 de cette année aura lieu comme prévu. Du 18 au 21 mars, plus de 900 rencontres et plus de 20 conférences techniques auront lieu. Bien sûr, le discours le plus marquant était toujours celui du « Cuir Jaune ». Selon le programme annoncé précédemment, le discours de Huang Renxun débutera à 4 heures du matin le 19 mars, heure de Pékin, et durera jusqu'à 6 heures du matin. Tout à l'heure, Huang a largué une série de « bombes nucléaires IA » lors d'une séance de partage de deux heures :
* Blackwell, la plateforme GPU de nouvelle génération
* La première puce basée sur Blackwell, GB200 Grace Blackwell
* Supercalculateur d'IA de nouvelle génération DGX SuperPOD
* Plateforme de supercalcul IA DGX B200
* Commutateur réseau nouvelle génération série X800
* Service cloud d'informatique quantique
* Earth-2, une plateforme cloud de jumeaux numériques climatiques
* Microservices d'IA générative
* 5 nouvelles API Omniverse Cloud
* DRIVE Thor, une plateforme informatique embarquée conçue pour les applications d'IA générative
* Modèle de base BioNeMo
Lien de rediffusion en direct :
https://www.bilibili.com/video/BV1Z6421c7V6/?spm_id_from=333.337.search-card.all.click
cuLitho en action
Lors de la conférence GTC de l'année dernière, NVIDIA a lancé une bibliothèque de lithographie informatique - cuLitho, affirmant qu'elle peut accélérer la lithographie informatique de plus de 40 fois. Aujourd'hui, Huang Renxun a annoncé que TSMC et Synopsys ont intégré NVIDIA cuLipo à leurs logiciels, processus de fabrication et systèmes pour accélérer la fabrication de puces.Lors des tests de cuLitho sur un flux de travail partagé, les deux sociétés ont obtenu conjointement une accélération de 45 fois pour les flux curvilignes et une amélioration de l'efficacité de près de 60 fois pour les flux plus traditionnels de style Manhattan.
De plus, NVIDIA a développé des algorithmes permettant d’appliquer l’IA générative afin d’améliorer encore la valeur de la plateforme cuLitho. Plus précisément, sur la base de l'amélioration de l'efficacité du processus de production basé sur cuLitho,Cet algorithme d’IA génératif est également 2 fois plus rapide.
Il est rapporté qu'en appliquant l'IA générative, une solution de masque inversé presque parfaite peut être créée, en tenant compte de la diffraction de la lumière, puis en dérivant le masque final par des méthodes physiques traditionnelles, augmentant finalement la vitesse de l'ensemble du processus de correction de proximité optique (OPC) de 2 fois.
Plateforme Blackwell pour l'IA générative à l'échelle d'un billion de paramètres

L'introduction ci-dessus à l'application de cuLitho ressemble davantage à un « apéritif », démontrant les perspectives de développement de la technologie de lithographie computationnelle et, dans une certaine mesure, fournissant une garantie de base pour la mise à niveau générationnelle des puces d'IA de NVIDIA.
Ensuite, le plat principal commence. Suivant la tradition de NVIDIA de mettre à jour son architecture GPU tous les deux ans, le premier produit à succès proposé par Huang est la nouvelle plateforme GPU plus grande - Blackwell. Il a dit,Hopper est génial, mais nous avons besoin de GPU plus puissants.
L'architecture Blackwell est nommée en l'honneur de David Harold Blackwell, le premier Afro-Américain élu à l'Académie nationale des sciences.

En termes de performances, Blackwell dispose de 6 technologies révolutionnaires :
* La puce la plus puissante du monde :Le GPU d'architecture Blackwell est fabriqué à l'aide d'un processus TSMC 4NP personnalisé et contient 208 milliards de transistors. Il connecte deux puces GPU extrêmes en un GPU unifié via une liaison puce à puce de 10 To/seconde. Moteur Transformer de deuxième génération : Blackwell prendra en charge le double de la taille de calcul et de modèle grâce aux nouvelles capacités d'inférence d'IA à virgule flottante 4 bits.
* NVLink de cinquième génération :La dernière itération de NVIDIA NVLink offre un débit bidirectionnel révolutionnaire de 1,8 To/s par GPU, garantissant une communication haut débit transparente entre jusqu'à 576 GPU pour implémenter les LLM les plus complexes.
* Moteur RAS :Les GPU alimentés par Blackwell incluent un moteur dédié pour la fiabilité, la disponibilité et la facilité d'entretien. De plus, l'architecture Blackwell ajoute des capacités au niveau de la puce pour exécuter des diagnostics et prédire les problèmes de fiabilité à l'aide d'une maintenance préventive basée sur l'IA. Cela maximise la disponibilité du système, améliore la résilience des déploiements d’IA à grande échelle, leur permet de fonctionner sans interruption pendant des semaines, voire des mois, et réduit les coûts d’exploitation.
* IA sécurisée :Il protège les modèles d'IA et les données clients sans compromettre les performances et prend en charge les nouveaux protocoles de cryptage d'interface natifs, ce qui est essentiel pour les secteurs sensibles à la confidentialité tels que la santé et les services financiers.
* Moteur de décompression :Un moteur de décompression dédié prend en charge les formats les plus récents et accélère les requêtes de base de données, offrant les meilleures performances pour l'analyse et la science des données.
À l’heure actuelle, AWS, Google, Meta, Microsoft, OpenAI, Tesla et d’autres sociétés ont pris les devants en « réservant » la plateforme Blackwell.
GB200 Grace Blackwell

La première puce basée sur Blackwell a été nommée GB200 Grace Blackwell Superchip.Il connecte deux GPU NVIDIA B200 Tensor Core au processeur NVIDIA Grace via une interconnexion puce à puce NVLink ultra-basse consommation de 900 Go/s.
Parmi eux, le GPU B200 possède plus de deux fois plus de transistors que le H100 existant, avec 208 milliards de transistors. Il peut également fournir 20 pétaflops de performances de calcul élevées via un seul GPU, tandis qu'un seul H100 ne peut fournir qu'un maximum de 4 pétaflops de puissance de calcul IA. De plus, le GPU B200 est équipé de 192 Go de mémoire HBM3e, offrant jusqu'à 8 To/s de bande passante.

GB200 est un composant clé de NVIDIA GB200 NVL72.Le NVL72 est un système multi-nœuds, refroidi par liquide et monté en rack.Idéal pour les charges de travail les plus gourmandes en calcul, il combine 36 superpuces Grace Blackwell, dont 72 GPU Blackwell et 36 CPU Grace, interconnectés par NVLink de cinquième génération.
De plus, le GB200 NVL72 comprend l'unité de traitement de données NVIDIA BlueField®-3, qui permet l'accélération du réseau cloud, le stockage composable, la sécurité zéro confiance et l'élasticité du calcul GPU dans les clouds d'IA hyperscale. Le GB200 NVL72 offre des performances jusqu'à 30 fois supérieures sur les charges de travail d'inférence LLM avec un coût et une consommation d'énergie jusqu'à 25 fois inférieurs à ceux d'un GPU NVIDIA H100 Tensor Core avec le même nombre de GPU.
Supercalculateur d'IA de nouvelle génération DGX SuperPOD
NVIDIA DGX SuperPOD utilise une nouvelle architecture montée en rack refroidie par liquide et est construit à partir des systèmes NVIDIA DGX GB200.Il fournit 11,5 exaflops de puissance de supercalcul IA avec une précision FP4 et 240 To de mémoire rapide.Et il peut être étendu à des performances plus élevées avec des racks supplémentaires. DGX SuperPOD dispose d'une gestion prédictive intelligente qui surveille en permanence des milliers de points de données sur le matériel et les logiciels pour prédire et intercepter les sources de temps d'arrêt et d'inefficacité, économisant ainsi du temps, de l'énergie et des coûts de calcul.
Le système DGX GB200 est équipé de 36 super puces NVIDIA GB200, dont 36 processeurs NVIDIA Grace et 72 GPU NVIDIA Blackwell, connectés à un supercalculateur via le NVLink de cinquième génération.
Chaque DGX SuperPOD peut transporter huit DGX GB200 ou plus, évolutifs jusqu'à des dizaines de milliers de super puces GB200 connectées via NVIDIA Quantum InfiniBand. Par exemple, les utilisateurs peuvent connecter 576 GPU Blackwell à huit DGX GB200 en fonction de l'interconnexion NVLink.
Plateforme de supercalcul IA DGX B200
DGX B200 est une plate-forme informatique pour la formation, le réglage fin et l'inférence de modèles d'IA qui utilise une conception DGX traditionnelle à montage en rack refroidie par air. Le système DGX B200 atteint la précision FP4 dans la nouvelle architecture Blackwell, offrant jusqu'à 144 pétaflops de performances de calcul IA, 1,4 To de mémoire GPU massive et 64 To/s de bande passante mémoire.La vitesse d’inférence en temps réel pour les modèles à mille milliards de paramètres est augmentée de 15 fois par rapport à la génération précédente.
Le DGX B200, basé sur la nouvelle architecture Blackwell, est équipé de huit GPU Blackwell et de deux processeurs Intel Xeon de cinquième génération. Les utilisateurs peuvent également construire un DGX SuperPOD à l’aide du système DGX B200. Pour la connectivité réseau, le DGX B200 est équipé de huit cartes réseau NVIDIA ConnectX™-7 et de deux DPU BlueField-3, offrant jusqu'à 400 gigabits par seconde de bande passante.
Série de commutateurs réseau de nouvelle génération - X800
Il est rapporté que la nouvelle génération de commutateurs réseau de la série X800 est conçue pour l'intelligence artificielle à grande échelle, brisant les limites de performances réseau des charges de travail informatiques et d'IA.
La plate-forme comprend des commutateurs NVIDIA Quantum Q3400 et des cartes super réseau NVIDIA ConnectX@-8, atteignant un débit de bout en bout de 800 Gb/s, leader du secteur.La capacité de bande passante est augmentée de 5 fois par rapport à la génération précédente de produits.Parallèlement, en adoptant le protocole d'agrégation et de réduction hiérarchique évolutif (SHARPv4) de NVIDIA, il a atteint jusqu'à 14,4 Tflops de puissance de calcul en réseau.L'augmentation des performances est jusqu'à 9 fois supérieure à celle de la génération précédente.
Les services cloud d'informatique quantique accélèrent la recherche scientifique
Le service cloud d'informatique quantique de NVIDIA est basé sur la plate-forme informatique quantique open source CUDA-Q de la société.Les trois quarts des entreprises qui déploient actuellement des unités de traitement quantique (QPU) dans l’industrie utilisent la plateforme. Le service cloud d'informatique quantique de Nvidia permet aux utilisateurs de créer et de tester pour la première fois de nouveaux algorithmes et applications quantiques dans le cloud, notamment de puissants simulateurs et des outils de programmation hybride quantique.
Le Quantum Computing Cloud dispose de puissantes capacités et d'intégrations de logiciels tiers pour accélérer la découverte scientifique, notamment :
* Un solveur de valeurs propres quantiques génératif, développé en collaboration avec l’Université de Toronto, qui utilise de grands modèles de langage pour permettre aux ordinateurs quantiques de trouver plus rapidement l’énergie de l’état fondamental des molécules.
* L'intégration de Classiq avec CUDA-Q permet aux chercheurs quantiques de générer des programmes quantiques vastes et complexes et d'analyser et d'exécuter en profondeur des circuits quantiques.
* QC Ware Promethium peut résoudre des problèmes complexes de chimie quantique tels que les simulations moléculaires.
Lancement d'Earth-2, une plateforme cloud de jumeaux numériques climatiques
Earth-2 vise à simuler et à visualiser la météo et le climat à grande échelle, permettant ainsi de prévoir les phénomènes météorologiques extrêmes. L'API Earth-2 fournit des modèles d'IA et utilise le modèle CorrDiff.
CorrDiff est un nouveau modèle d'IA générative lancé par NVIDIA. Il utilise le modèle de diffusion SOTA.Les images obtenues ont une résolution 12,5 fois supérieure à celle des modèles numériques existants, sont 1 000 fois plus rapides et 3 000 fois plus économes en énergie.Il surmonte l’inexactitude des prédictions à résolution grossière et intègre des mesures essentielles à la prise de décision.

CorrDiff est un modèle d'IA génératif unique en son genre qui fournit une super-résolution, synthétise de nouvelles mesures importantes et apprend la physique de la météo locale à grain fin à partir d'ensembles de données haute résolution.
Lancement de microservices d'IA générative pour promouvoir le développement de médicaments, l'itération des technologies médicales et la santé numérique
La nouvelle suite de microservices de santé NVIDIA comprend des modèles d'IA NVIDIA NIM™ optimisés et des flux de travail API standard du secteur qui servent de blocs de construction pour la création et le déploiement d'applications cloud natives. Ces microservices incluent des fonctionnalités telles que l’imagerie avancée, la reconnaissance du langage naturel et de la parole, la génération de biologie numérique, la prédiction et la simulation.
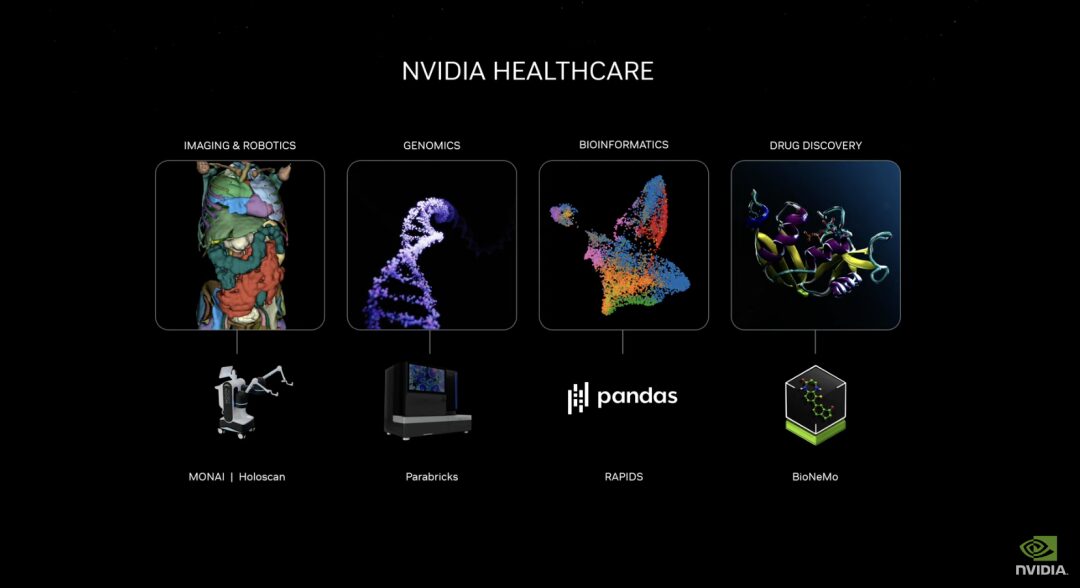
De plus, les kits de développement logiciel accélérés NVIDIA et les outils associés, notamment Parabricks®, MONAI, NeMo™, Riva et Metropolis, sont désormais accessibles via les microservices NVIDIA CUDA-X™.
Microservice d'inférence
Lancez des dizaines de microservices d’IA génératifs de niveau entreprise que les entreprises peuvent utiliser pour créer et déployer des applications personnalisées sur leurs propres plateformes tout en conservant leur propriété intellectuelle.
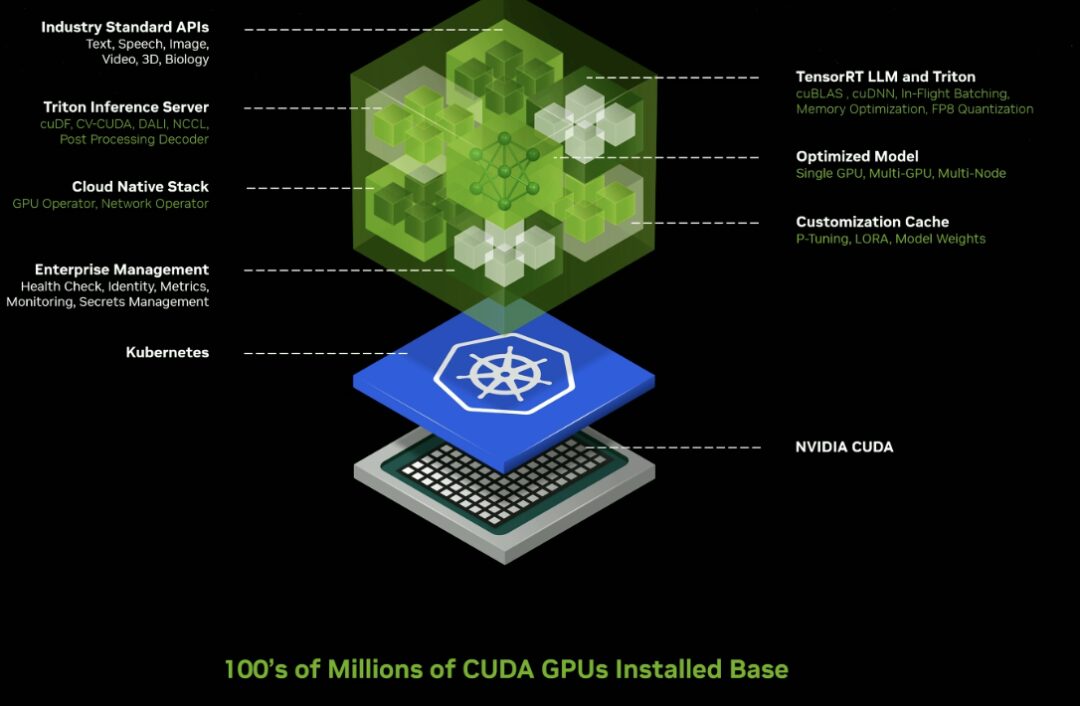
Nouveaux microservices NVIDIA NIM accélérés par GPU et points de terminaison cloud pour les modèles d'IA pré-entraînés optimisés pour s'exécuter sur des centaines de millions de GPU compatibles CUDA dans les clouds, les centres de données, les postes de travail et les PC.
Les entreprises peuvent utiliser des microservices pour accélérer le traitement des données, la personnalisation LLM, le raisonnement, la génération d'améliorations de récupération et la protection ;
Adopté par un large écosystème d'IA, notamment les principaux fournisseurs de plateformes d'applications Cadence, CrowdStrike, SAP, ServiceNow et d'autres.
NIM Microservices fournit des conteneurs pré-construits alimentés par le logiciel d'inférence NVIDIA, notamment Triton Inference Server™ et TensorRT™-LLM, qui peuvent réduire le temps de déploiement de plusieurs semaines à quelques minutes.
Lancement de l'API Omniverse Cloud pour renforcer les outils logiciels de jumeaux numériques industriels
Grâce à cinq nouvelles API Omniverse Cloud, les développeurs peuvent intégrer les technologies de base d'Omniverse directement dans les applications logicielles de conception et d'automatisation de jumeaux numériques existantes, ainsi que dans les flux de travail de simulation pour tester et valider des robots ou des voitures autonomes, comme la diffusion en continu de jumeaux numériques industriels interactifs vers Apple Vision Pro.
Ces API incluent :
* Rendu USD :Génération du rendu NVIDIA RTX™ des données OpenUSD mondiales tracées par rayons
* USD Écrire :Permet aux utilisateurs de modifier et d'interagir avec les données OpenUSD.
* Requête USD :Prise en charge de la requête de scène et de l'interaction de scène.
* USD Notifier :Suivez les changements en USD et fournissez des mises à jour.
* Chaîne Omniverse :Relier les utilisateurs, les outils et la réalité pour parvenir à une collaboration inter-scénarios
Huang Renxun estime qu’à l’avenir, tout ce qui sera fabriqué aura un jumeau numérique. Omniverse est le système d’exploitation permettant de créer et d’exécuter des jumeaux numériques de la réalité physique. L’omnivers et l’intelligence artificielle générative sont les technologies fondamentales pour la numérisation du marché de l’industrie lourde, d’une valeur de 50 000 milliards de dollars.
DRIVE Thor : IA générative avec architecture Blackwell pour alimenter la conduite autonome
DRIVE Thor est une plate-forme informatique embarquée conçue pour les applications d'IA générative, offrant une conduite simulée riche en fonctionnalités ainsi que des capacités de conduite hautement automatisées sur une plate-forme centralisée. En tant que prochaine génération d'ordinateur central de véhicule autonome, il est sûr et fiable, unifiant les fonctions intelligentes en un seul système pour améliorer l'efficacité et réduire le coût de l'ensemble du système.
DRIVE Thor intégrera également la nouvelle architecture NVIDIA Blackwell.L'architecture est conçue pour les charges de travail Transformer, LLM et IA générative.
BioNeMo : Aider à la découverte de médicaments
Le modèle de base de BioNeMo peut analyser les séquences d'ADN, prédire les changements de forme des protéines sous l'action des molécules de médicament et déterminer la fonction des cellules en fonction de l'ARN.
Actuellement, le premier modèle de génome DNABERT fourni par BioNeMo est basé sur des séquences d'ADN et peut être utilisé pour prédire les fonctions de régions spécifiques du génome, analyser les effets des mutations et des variations génétiques, etc. Son deuxième modèle, scBERT, qui est sur le point d'être lancé, est formé sur la base de données de séquençage d'ARN unicellulaire. Les utilisateurs peuvent l’appliquer à des tâches en aval telles que la prédiction des effets de l’inactivation de gènes (c’est-à-dire la suppression ou la désactivation de gènes spécifiques) et l’identification de types de cellules tels que les neurones, les cellules sanguines ou les cellules musculaires.
Il est rapporté qu'il existe actuellement plus de 100 entreprises dans le monde qui font progresser leur processus de recherche et développement basé sur BioNeMo, notamment Astellas Pharma, basée à Tokyo, le développeur de logiciels informatiques Cadence, la société de développement de médicaments Iambic, etc.
Derniers mots
En plus des nombreux nouveaux produits mentionnés ci-dessus, Huang Renxun a également présenté la conception de NVIDIA dans le domaine de la robotique. Huang a déclaré que tout ce qui bouge est un robot et que l'industrie automobile en sera une partie importante. Actuellement, les ordinateurs NVIDIA sont utilisés dans les voitures, les camions, les robots de livraison et les robots-taxis. Par la suite, elle a également lancé le kit de développement logiciel Isaac Perceptor, le modèle de base universel GR00T de robots humanoïdes et le nouvel ordinateur Jetson Thor pour robots humanoïdes basé sur le système sur puce NVIDIA Thor, et a apporté des mises à niveau majeures à la plate-forme robotique NVIDIA Isaac.
En résumé, la séance de partage de 2 heures a été remplie de produits performants et de présentations de modèles. Une conférence de presse aussi rapide et riche en contenu est exactement à l'image de l'état de développement actuel de l'industrie de l'IA : rapide et prospère.
En tant que fondement de l’ère de l’IA, la puissance de calcul représentée par les puces hautes performances est la clé pour déterminer le cycle de développement et la direction de l’industrie. Il ne fait aucun doute que Nvidia dispose actuellement d’un fossé inébranlable. Bien que de nombreuses entreprises aient commencé à attaquer Huang, et qu'OpenAI, Microsoft, Google, etc. cultivent également leurs propres « armées », cela pourrait être un plus grand élan pour Nvidia, qui avance toujours à grande vitesse.
La diffusion en direct en ligne est désormais terminée. Après chaque sortie de nouveau produit, Huang Renxun présentera les partenaires qui ont « réservé » les nouveaux services, et toutes les grandes entreprises sont sur la liste sans exception. À l’avenir, nous espérons également que les entreprises actuellement à la pointe du secteur seront en mesure de tirer parti de la productivité avancée du secteur pour proposer des produits et des applications plus innovants.








