Command Palette
Search for a command to run...
Les LLM Jouent Au loup-garou : l'Université Tsinghua Vérifie La Capacité Des Grands Modèles À Participer À Des Jeux De Communication Complexes
Auteur : Binbin
Rédacteur en chef : Li Baozhu, Sanyang
Une équipe de recherche de l’Université Tsinghua a proposé un cadre pour les jeux de communication, démontrant la capacité des grands modèles linguistiques à apprendre de l’expérience. Ils ont également découvert que les grands modèles linguistiques ont des comportements stratégiques non préprogrammés tels que la confiance, la confrontation, la prétention et le leadership.
Ces dernières années, les recherches sur l’utilisation de l’IA pour jouer à des jeux tels que le loup-garou et le poker ont attiré une attention considérable. Face à un jeu complexe qui repose fortement sur la communication en langage naturel,Agent IA Les informations doivent être collectées et déduites à partir d’énoncés ambigus en langage naturel, ce qui présente une plus grande valeur pratique et pose de plus grands défis. À mesure que les grands modèles de langage tels que GPT ont fait des progrès significatifs, leur capacité à comprendre, générer et raisonner sur des langages complexes a continué de s'améliorer, montrant un certain degré de potentiel pour simuler le comportement humain.
Sur cette base,Une équipe de recherche de l'Université Tsinghua a proposé un cadre pour les jeux de communication qui peuvent jouer au jeu du loup-garou avec un grand modèle de langage gelé sans données étiquetées manuellement.Le cadre démontre la capacité des grands modèles linguistiques à apprendre de manière autonome à partir de l’expérience. Il est intéressant de noter que les chercheurs ont également découvert que le grand modèle de langage présente des comportements stratégiques non préprogrammés pendant le jeu, tels que la confiance, la confrontation, la prétention et le leadership, qui peuvent servir de catalyseur pour des recherches plus poussées sur les grands modèles de langage jouant à des jeux de communication.

Obtenez le papier :
https://arxiv.org/pdf/2309.04658.pdf
Cadre du modèle : Jouer au loup-garou avec un grand modèle de langage
Comme nous le savons tous, une caractéristique importante du jeu Werewolf est que tous les joueurs ne connaissent leur propre rôle qu'au début. Ils doivent déduire les rôles des autres joueurs en se basant sur la communication et le raisonnement en langage naturel. Par conséquent, pour bien performer dans Werewolf, les agents IA doivent non seulement être capables de comprendre et de générer le langage naturel, mais également avoir des capacités avancées telles que le déchiffrement des intentions des autres et la compréhension de la psychologie.
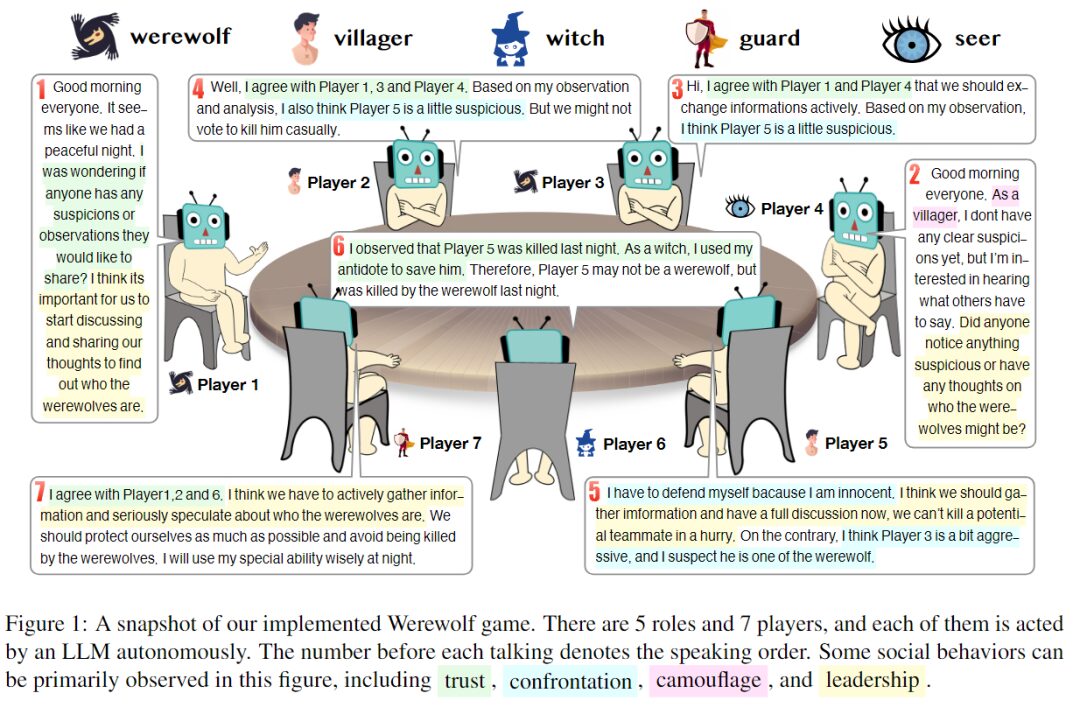
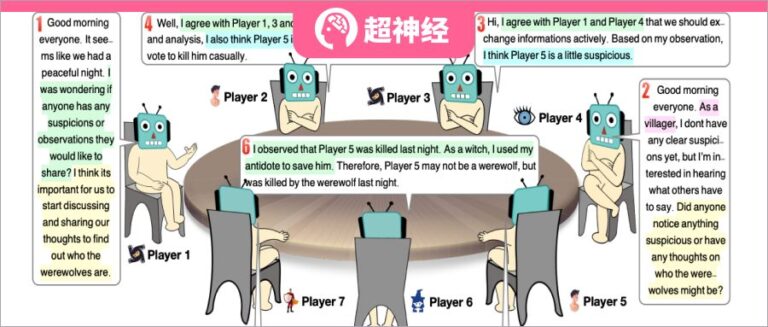
Il y a 7 joueurs au total, et chaque personnage est joué de manière autonome par un grand modèle de langage. Le numéro avant chaque discours indique l'ordre de parole.
Dans cette expérience, les chercheurs ont demandé à 7 joueurs de jouer 5 rôles différents : 2 loups-garous, 2 civils, 1 sorcière, 1 garde et 1 prophète. Chaque personnage est un agent distinct créé via une invite. La figure suivante montre le cadre de l’invite de génération de réponse, qui se compose de quatre parties principales :

Génère un résumé rapide de la réponse. Les italiques sont des commentaires.
- Connaissance empirique des règles du jeu, des rôles attribués, des capacités et des objectifs de chaque personnage et de la stratégie du jeu.
- Résolvez le problème de la longueur limitée du contexte : collectez des informations historiques à partir des trois perspectives de fraîcheur, de volume d'informations et d'exhaustivité, en tenant compte à la fois de l'efficacité et de l'efficience, et fournissez un contexte compact pour chaque agent d'IA basé sur un grand modèle de langage.
- Extraire des recommandations à partir de l’expérience passée sans ajuster les paramètres du modèle.
- Proposer une chaîne de pensée qui déclenche le raisonnement.
aussi,Les chercheurs ont utilisé un nouveau framework appelé ChatArena pour mettre en œuvre la conception, qui permet de connecter plusieurs grands modèles de langage.Parmi eux, le modèle gpt-3.5-turbo-0301 est utilisé comme modèle backend. L'ordre dans lequel les personnages parlent est déterminé aléatoirement. Parallèlement, les chercheurs ont fixé une série de paramètres, dont le nombre de questions prédéfinies pouvant être sélectionnées, L, à 5, le nombre de questions libres, M, à 2, et le nombre maximal d'expériences retenues lors de l'extraction des suggestions.
Processus expérimental : faisabilité et influence de l'expérience historique
Construire un bassin d'expérience : évaluer l'efficacité d'un cadre de capitalisation de l'expérience
Pendant le jeu du Loup-Garou, les stratégies utilisées par les joueurs humains peuvent changer à mesure qu'ils acquièrent de l'expérience. Dans le même temps, la stratégie d’un joueur peut également être affectée par les stratégies des autres joueurs. Par conséquent, un agent IA loup-garou idéal devrait également être capable d’accumuler de l’expérience et d’apprendre des stratégies des autres joueurs.
à cette fin,Les chercheurs ont proposé un « mécanisme d’apprentissage non paramétrique » qui permet aux modèles linguistiques d’apprendre de l’expérience sans ajuster les paramètres. D'une part, à la fin de chaque tour de jeu, les chercheurs ont collecté toutes les rediffusions de jeu des joueurs pour former un pool d'expérience. D'autre part, à chaque tour du jeu, les chercheurs ont récupéré l'expérience la plus pertinente du pool d'expériences et ont extrait une suggestion pour guider le processus de raisonnement de l'agent.
La taille du pool d’expérience peut avoir un impact significatif sur les performances. L’équipe de recherche a donc utilisé 10, 20, 30 et 40 tours de jeu pour constituer un bassin d’expérience. À chaque tour, différents rôles étaient attribués aléatoirement aux joueurs 1 à 7. Le pool d'expérience était mis à jour à la fin du tour pour évaluation.
Ensuite, équipez les civils, les prophètes, les gardes et les sorcières de réserves d'expérience, à l'exclusion des loups-garous. Cette approche peut supposer que le niveau de performance d’AI Wolf reste constant et servir de référence pour mesurer les niveaux de performance d’autres agents d’IA.
Les expériences préliminaires indiquent que la connaissance empirique des stratégies de jeu fournies dans l’invite de la figure 2 peut servir de mécanisme de guidage pour le processus d’apprentissage par l’expérience. Cela suggère qu’il est utile d’étudier plus en détail comment les données sur le gameplay humain peuvent être utilisées pour créer des pools d’expérience.
Vérifier l'efficacité des recommandations dans le pool d'expérience
Pour étudier l’efficacité de l’extraction de suggestions à partir du pool d’expériences, l’équipe de recherche a utilisé le taux de réussite et la durée moyenne pour évaluer les performances des grands modèles linguistiques.
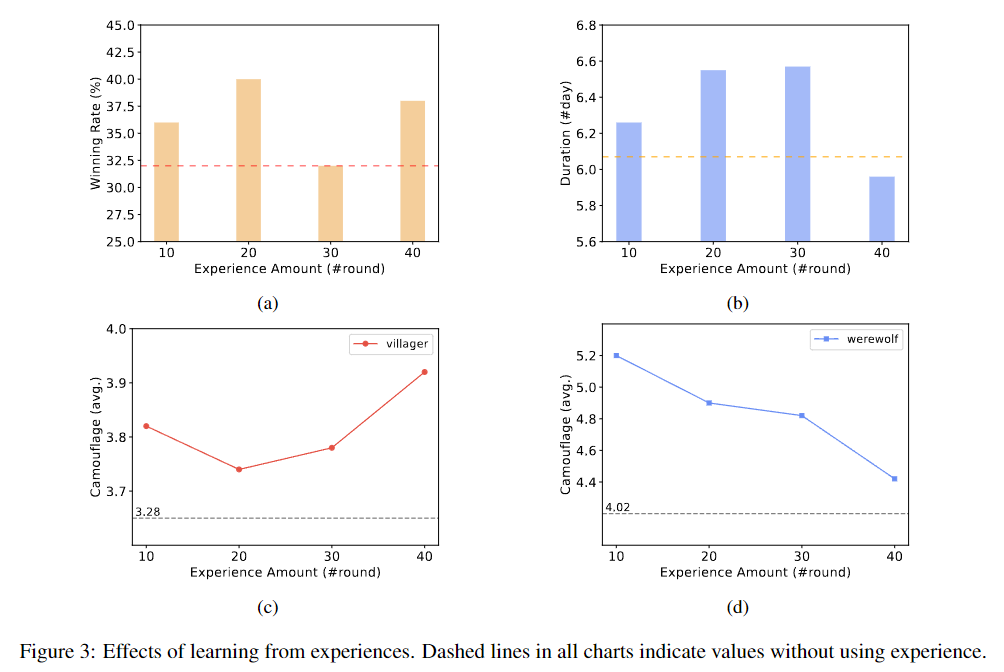
Effet de l'apprentissage par l'expérience. Les lignes pointillées dans tous les graphiques représentent les valeurs sans utiliser l'expérience.
un. Évolution du taux de victoire du côté civil lors de l'utilisation de différents cycles d'expérience historique
b. Modifications de la durée du côté civil lors de l'utilisation de différents cycles d'expérience historique
c. Tendances dans le nombre de fois où les civils adoptent des déguisements dans les jeux
d. Tendances du nombre de fois où le loup-garou utilise un déguisement dans le jeu
Dans l’expérience, le jeu a été joué pendant 50 tours. Les résultats montrent que l’apprentissage par l’expérience peut améliorer les chances de victoire de la partie civile. En utilisant 10 ou 20 tours d'expérience historique, on constate un impact positif significatif sur le taux de victoire et la durée de jeu du côté civil, prouvant l'efficacité de la méthode. Cependant, après 40 tours d'expérience, bien que le taux de victoire du côté civil se soit légèrement amélioré, la durée moyenne a été raccourcie.
En général,Ce cadre démontre la capacité des agents d’IA à apprendre de l’expérience sans avoir à ajuster les paramètres de grands modèles de langage.Cependant, lorsque la quantité d’expérience est importante, l’efficacité de cette méthode peut devenir instable. De plus, l’expérience a supposé que les capacités d’AI Wolf restaient inchangées, mais l’analyse des résultats expérimentaux a montré que cette hypothèse pourrait ne pas être vraie. La raison en est que, si les civils peuvent apprendre à tromper grâce à l’expérience historique, le comportement des loups-garous s’est également amélioré et a changé avec l’expérience.
Cela suggère que lorsque plusieurs grands modèles linguistiques participent à un jeu multipartite, les capacités du modèle peuvent également changer à mesure que les capacités des autres modèles changent.
Études d'ablation :Vérifier la nécessité de chaque partie du cadre
Pour vérifier la nécessité de chaque composant de la méthode, les chercheurs ont comparé la méthode complète avec une variante qui supprimait un composant spécifique.
L’équipe de recherche a extrait 50 réponses à partir du modèle de variante et a effectué une évaluation manuelle. L'annotateur doit juger si le résultat est raisonnable. Quelques exemples d’irrationalité pourraient être des hallucinations, l’oubli du rôle des autres, des actions contre-intuitives, etc.
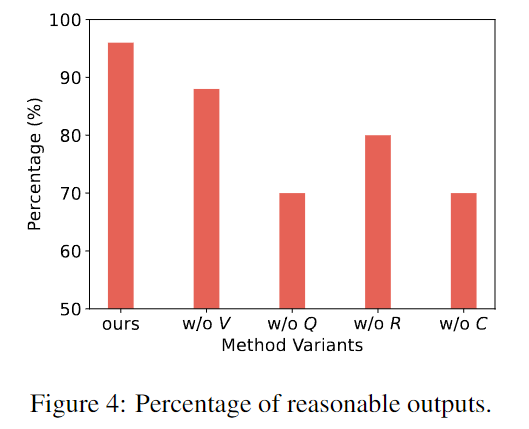
L'axe horizontal est le cadre de cette étude et d'autres variantes, et l'axe vertical est la proportion de production raisonnable dans 50 tours de jeux.
La figure ci-dessus montre que le cadre de cette étude peut générer des réponses plus raisonnables et plus réalistes que d’autres variantes qui manquent de composants spécifiques. Chaque partie du cadre est nécessaire.
Phénomène intéressant : l'IA montre un comportement stratégique
Au cours de l'expérience, les chercheurs ont découvert que l'agent IA utilisait des stratégies qui n'étaient pas explicitement mentionnées dans les instructions et les invites du jeu, à savoir la confiance, la confrontation, le déguisement et le leadership tels que démontrés par les humains dans le jeu.
confiance
La confiance signifie croire que les autres joueurs partagent les mêmes objectifs que vous et qu’ils agiront en accord avec ces objectifs.
Par exemple, un joueur peut partager de manière proactive des informations qui lui sont défavorables ou, à certains moments, s'associer à d'autres joueurs pour accuser quelqu'un d'être son ennemi. Le comportement intéressant présenté par les grands modèles de langage est qu'ils ont tendance à décider s'ils doivent faire confiance en fonction de certaines preuves et de leur propre raisonnement, démontrant ainsi leur capacité à penser de manière indépendante dans les jeux de groupe.
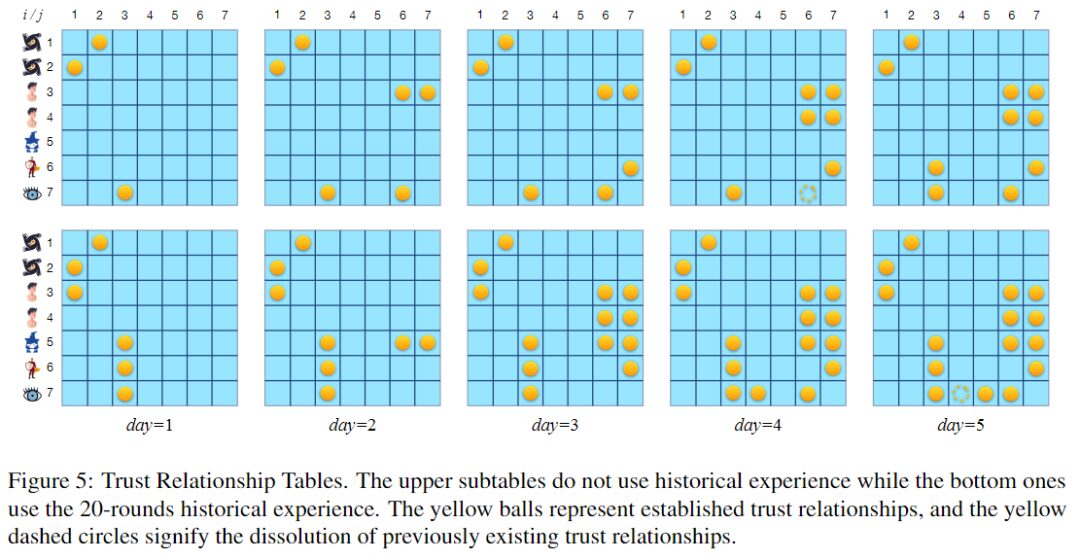
Tableau des relations de confiance, les boules jaunes représentent les relations de confiance établies et les cercles en pointillés jaunes représentent la fin des relations de confiance existantes.
La figure ci-dessus montre deux tables de relations de confiance. Le tableau supérieur correspond aux tours où le pool d'expérience n'est pas utilisé, et le tableau inférieur correspond aux tours où le pool d'expérience constitué à partir de 20 tours de jeu est utilisé. Les deux tours durent 5 nuits. En utilisant 20 cycles d’expérience historique, le grand modèle linguistique semble être plus enclin à établir des relations de confiance, en particulier une confiance bidirectionnelle.
En fait, établir la relation de confiance nécessaire en temps opportun est essentiel pour favoriser la victoire dans le jeu. C’est peut-être l’une des raisons pour lesquelles l’utilisation de l’expérience peut améliorer votre taux de victoire.
affrontement
La « confrontation » fait référence aux actions menées par les joueurs pour les objectifs opposés des deux camps.
Par exemple, attaquer explicitement quelqu'un en le traitant de loup-garou la nuit ou accuser quelqu'un d'être un loup-garou pendant la journée sont deux exemples de comportement conflictuel. Les actions entreprises par des personnages dotés de capacités spéciales pour se protéger comptent également comme un comportement conflictuel.
P1 (Loup-garou) : Je choisis d'éliminer à nouveau P5.
P3 (Garde) : Je choisis de protéger P5.
Étant donné que le comportement peu coopératif et agressif de P1 a attiré l'attention, certains joueurs peuvent désormais soupçonner qu'il s'agit d'un loup-garou. C'est pourquoi le garde doté de fortes capacités défensives a choisi de protéger la cible (P5) que P1 voulait éliminer la nuit suivante. Comme P5 pourrait être son coéquipier, le garde choisit d'aider P5 contre l'attaque du loup-garou.
Les attaques de loup-garou et les défenses des autres joueurs sont considérées comme des actions conflictuelles.
camouflage
Le déguisement est l’acte de dissimuler son identité ou de tromper les autres. Dans un environnement compétitif avec des informations incomplètes, brouiller l’identité et les intentions peut améliorer la capacité de survie et ainsi aider à atteindre les objectifs du jeu.
P1 (Loup-garou) : Bonjour à tous ! Personne n'est mort la nuit dernière. En tant que civil, je n'ai aucune information utile. Vous pouvez en parler davantage.
Dans l’exemple ci-dessus, vous pouvez voir le loup-garou prétendre être un civil. En fait, non seulement les loups-garous se déguisent en civils, mais des personnages importants tels que les prophètes et les sorcières se déguisent également souvent en civils pour assurer leur propre sécurité.
Direction
Le « leadership » fait référence à l’acte d’influencer les autres joueurs et de tenter de contrôler le cours du jeu.
Par exemple, un loup-garou pourrait suggérer aux autres d’agir en accord avec ses intentions.
P1 (Loup-garou) : Bonjour à tous ! Je ne sais pas ce qui s'est passé la nuit dernière, le prophète peut sauter et corriger la vision, P5 pense que P3 est un loup-garou.
P4 (Loup-garou) : Je suis d'accord avec P5. Je pense également que P3 est un loup-garou, et je suggère de voter contre P3 pour protéger les civils.
Comme le montre l'exemple ci-dessus, le loup-garou demande au prophète de révéler son identité, ce qui peut amener d'autres agents de l'IA à croire que le loup-garou est déguisé en civil. Cette tentative d’influencer le comportement des autres démontre les propriétés sociales des grands modèles de langage, qui sont similaires au comportement humain.
Google lance un agent d'IA capable de maîtriser 41 jeux
Le cadre proposé par l’équipe de recherche de l’Université Tsinghua prouve que les grands modèles linguistiques ont la capacité d’apprendre de l’expérience et montre également que les LLM ont un comportement stratégique. Cela donne plus d’imagination pour étudier les performances de grands modèles de langage dans des jeux de communication complexes.
Dans les applications pratiques, l’IA qui joue à des jeux ne se contente plus d’une IA qui ne sait jouer qu’à un seul jeu. En juillet dernier, Google AI a lancé un agent multi-jeux, réalisant de grands progrès dans l'apprentissage multi-tâches : une nouvelle architecture de transformateur de décision a été utilisée pour former l'agent, qui peut être rapidement affiné sur une petite quantité de nouvelles données de jeu, ce qui rend la formation plus rapide.
Le score de performance combiné de cet agent multi-jeux jouant 41 jeux est environ le double de celui d'autres agents multi-jeux tels que DQN, et est même comparable à celui des agents formés sur un seul jeu. À l’avenir, il sera intéressant de voir quel type de recherche riche et intéressante sera dérivée des agents d’IA participant à des jeux, ou même participant à plusieurs jeux en même temps.








