Command Palette
Search for a command to run...
L'AGU Des États-Unis Publie Un Manuel d'application De l'IA, Clarifiant Six Lignes Directrices Majeures

Applications explosives de l'IA : risques et opportunités coexistent
Dans les domaines des sciences spatiales et environnementales, les outils d’IA sont de plus en plus utilisés pour des applications telles que les prévisions météorologiques et la simulation climatique, la gestion des ressources énergétiques et hydriques, etc. On peut dire que nous assistons à une explosion sans précédent des applications de l’IA, et nous devons réfléchir plus attentivement aux opportunités et aux risques qui y sont liés.
Le rapport de suivi de l’American Geophysical Union (AGU) révèle une fois de plus l’application généralisée des outils d’IA.Entre 2012 et 2022, le nombre d’articles mentionnant l’IA dans leurs résumés a augmenté de façon exponentielle, soulignant son énorme impact dans les prévisions météorologiques, la simulation climatique, la gestion des ressources, etc.
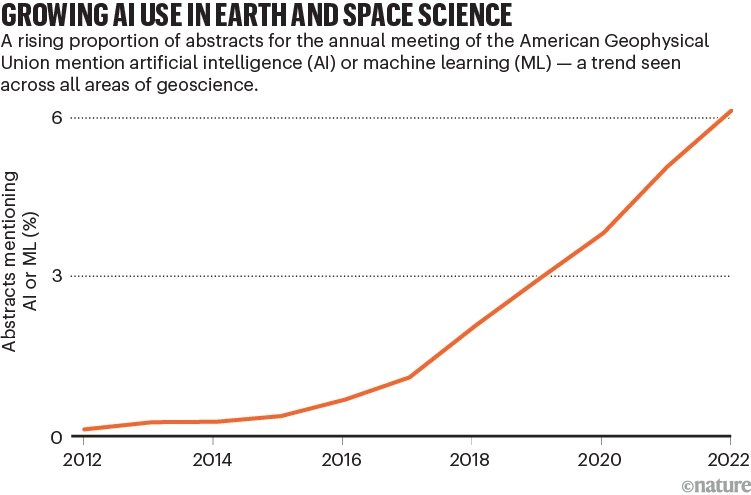
Tendances de publication d'articles liés à l'IA
Cependant, si l’IA libère une énergie puissante, elle comporte également des risques potentiels. Parmi eux, des modèles insuffisamment formés ou des ensembles de données mal conçus peuvent conduire à des résultats peu fiables, voire à des dommages potentiels. Par exemple, étant donné les rapports de tornades comme ensemble de données d’entrée, les données d’entraînement peuvent être biaisées en faveur des zones densément peuplées, car davantage d’événements météorologiques y sont observés et signalés. En conséquence, le modèle peut surestimer les tornades dans les zones urbaines et sous-estimer les tornades dans les zones rurales, causant ainsi des dommages.
Ce phénomène soulève également des questions importantes : quand et dans quelle mesure les gens peuvent-ils faire confiance à l’IA et éviter les risques éventuels ?
Avec le soutien de la NASA, l’AGU a réuni des experts pour élaborer un ensemble de lignes directrices pour l’application de l’intelligence artificielle dans les sciences spatiales et environnementales., en se concentrant sur les problèmes éthiques et moraux qui peuvent exister dans les applications de l’IA. Il ne se limite pas au domaine spécifique des sciences spatiales et environnementales, mais fournit également des orientations pour des applications complètes de l’IA. Du contenu connexe a été publié dans « Nature ».

L'article a été publié dans Nature
Lien vers l'article :
https://www.nature.com/articles/d41586-023-03316-8
Suivez le compte officiel et répondez « Directives » pour obtenir le PDF complet du document
Six lignes directrices pour aider à instaurer la confiance
Actuellement, de nombreuses personnes restent indécises quant à la fiabilité de l’IA/ML. Pour aider les chercheurs et les institutions de recherche scientifique à renforcer la confiance dans l’IA, l’AGU a établi six lignes directrices :
Afin de préserver le sens original, l'auteur joint ensemble la traduction et le texte original.
Conseils aux chercheurs
1. Transparence, documentation et reporting
Dans la recherche en IA/ML, la transparence et une documentation complète sont cruciales. Il faut non seulement fournir des données et du code, mais aussi les participants et la manière dont le problème a été résolu, y compris la gestion de l’incertitude et des biais. La transparence doit être prise en compte tout au long du processus de recherche, depuis l’élaboration du concept jusqu’à son application.
2. Intentionnalité, interprétabilité, explicabilité, reproductibilité et réplicabilité
Lors de la conduite de recherches utilisant l’IA/ML, il est important de se concentrer sur l’intentionnalité, l’explicabilité, la reproductibilité et la reproductibilité. Privilégier les méthodes scientifiques ouvertes, améliorer l’interprétabilité et la reproductibilité des modèles et encourager le développement de méthodes pour expliquer les modèles d’IA.
3. Risque, biais et effets
Comprendre et gérer les risques et les biais potentiels dans les ensembles de données et les algorithmes est essentiel à la recherche. En comprenant mieux les sources de risque et de biais, ainsi que les méthodes permettant d’identifier ces problèmes, les résultats négatifs peuvent être gérés et traités plus efficacement, maximisant ainsi les avantages et l’efficacité pour le public.
4. Méthodes participatives
Dans la recherche en IA/ML, il est très important d’adopter une approche de conception et de mise en œuvre inclusive. Veiller à ce que les personnes issues de communautés, de domaines professionnels et d’horizons différents aient la parole, en particulier pour les communautés susceptibles d’être affectées par la recherche. La coproduction de connaissances, la participation à des projets et la collaboration sont essentielles pour garantir l’inclusivité dans la recherche.
Conseils aux organisations universitaires (y compris les instituts de recherche, les éditeurs, les associations et les investisseurs)
5. Sensibilisation, formation et pratiques exemplaires
Les organisations universitaires doivent apporter leur soutien à l’industrie et veiller à ce qu’une formation sur l’utilisation éthique de l’IA/ML soit dispensée aux chercheurs, aux praticiens, aux bailleurs de fonds et à la communauté plus large de l’IA/ML. Les sociétés scientifiques, les institutions et autres organisations devraient fournir des ressources et une expertise, soutenir la formation à l’éthique de l’IA/ML et sensibiliser les décideurs sociétaux à la valeur et aux limites de l’IA/ML dans la recherche afin que des décisions responsables puissent être prises pour réduire ses impacts négatifs.
6. Considérations pour les organisations, les institutions, les éditeurs, les sociétés et les bailleurs de fonds
Les organisations universitaires ont la responsabilité de prendre l’initiative d’établir et de gérer des politiques liées aux questions éthiques liées à l’IA/ML, notamment des codes de conduite, des principes, des méthodes de rapport, des processus de prise de décision et des formations. Ils devraient articuler des valeurs et concevoir des structures de gouvernance, y compris la construction culturelle, pour garantir que des pratiques éthiques en matière d’IA/ML soient mises en œuvre. En outre, l’application de ces responsabilités dans l’ensemble des organisations et des institutions est nécessaire pour garantir que des pratiques éthiques soient mises en œuvre dans l’ensemble du domaine.
Des conseils plus détaillés sur les applications de l'IA
1. Attention aux lacunes et aux biais
En ce qui concerne les modèles et les données d’IA, méfiez-vous des lacunes et des biais. Des facteurs tels que la qualité des données, la couverture et les préjugés raciaux peuvent affecter la précision et la fiabilité des résultats du modèle, ce qui peut entraîner des risques inattendus.
Par exemple, la couverture ou l’authenticité des données environnementales dans certaines régions est bien meilleure que dans d’autres. Les régions avec une couverture nuageuse fréquente (comme les forêts tropicales humides) ou les zones avec une couverture de capteurs moindre (comme les pôles) fourniront des données moins représentatives.
La richesse et la qualité des ensembles de données favorisent souvent les zones riches et négligent les groupes défavorisés, notamment les communautés qui ont historiquement souffert de discrimination. Ces données sont souvent utilisées pour fournir des recommandations et des plans d’action au public, aux entreprises et aux décideurs politiques. Par exemple, dans les données de santé, les algorithmes dermatologiques formés sur des données blanches sont moins précis pour diagnostiquer les lésions cutanées et les éruptions cutanées chez les personnes noires.
Les institutions devraient se concentrer sur la formation des chercheurs, l’examen de l’exactitude des données et des modèles et la mise en place de comités professionnels pour superviser l’utilisation des modèles d’IA.
2. Développer des moyens d’expliquer le fonctionnement des modèles d’IA
Lorsque les chercheurs mènent des recherches et publient des articles en utilisant des modèles classiques, les lecteurs s’attendent souvent à ce qu’ils fournissent l’accès au code sous-jacent et aux spécifications associées. Cependant, les chercheurs ne sont pas encore explicitement tenus de fournir de telles informations, ce qui entraîne un manque de transparence et d’explicabilité des outils d’IA qu’ils utilisent. Cela signifie que même si le même algorithme est utilisé pour traiter les mêmes données expérimentales, différentes méthodes expérimentales peuvent ne pas reproduire avec précision les résultats. Par conséquent, dans les recherches publiées publiquement, les chercheurs doivent clairement documenter la manière dont les modèles d’IA sont construits et déployés afin que d’autres puissent évaluer les résultats.
Les chercheurs recommandent d’effectuer des comparaisons entre les modèles et de diviser les sources de données en groupes de comparaison à des fins d’examen. L’industrie a besoin de toute urgence de normes et de directives supplémentaires pour expliquer et évaluer le fonctionnement des modèles d’IA afin que les résultats qu’ils produisent puissent être évalués avec un niveau de confiance statistique proportionnel à celui des données produites.
Actuellement, les chercheurs et les développeurs travaillent sur une technique appelée IA explicable (XAI), qui vise à donner aux utilisateurs une meilleure compréhension du fonctionnement des modèles d’IA en quantifiant ou en visualisant leurs résultats. Par exemple, dans les prévisions météorologiques à court terme, les outils d’intelligence artificielle peuvent analyser de grandes quantités de données d’observation par télédétection obtenues toutes les quelques minutes, améliorant ainsi la capacité à prédire les catastrophes météorologiques graves.
Une explication claire de la manière dont les résultats ont été obtenus est essentielle pour évaluer la validité et l’utilité des prévisions. Par exemple, lorsqu’il s’agit de prédire la probabilité et l’étendue des incendies ou des inondations, cette explication peut aider les humains à décider s’il faut alerter le public ou utiliser les résultats d’autres modèles d’IA. Dans les géosciences, XAI tente de quantifier ou de visualiser les caractéristiques des données d’entrée pour mieux comprendre les sorties du modèle. Les chercheurs doivent examiner ces explications et s’assurer de leur plausibilité.

Des outils d’intelligence artificielle sont utilisés pour évaluer les observations environnementales
3. Forger des partenariats et favoriser la transparence
Les chercheurs doivent se concentrer sur la transparence à chaque étape : partage des données et du code, prise en compte de tests supplémentaires pour garantir la reproductibilité et la reproductibilité, prise en compte des risques et des biais dans leurs méthodes et signalement des incertitudes. Ces étapes nécessitent une description plus détaillée de la méthode. Pour garantir l’exhaustivité, les équipes de recherche devraient inclure des experts dans l’utilisation de divers types de données, ainsi que des membres de la communauté qui peuvent être impliqués dans la fourniture de données ou qui peuvent être affectés par les résultats de la recherche. Par exemple, un projet basé sur l’IA combine les connaissances traditionnelles du peuple Tharu du Canada avec des données recueillies par des méthodes non autochtones pour identifier les zones les mieux adaptées à l’aquaculture. (Voir go.nature.com/46yqmdr).

Photos du projet d'aquaculture
4. Maintenir le soutien à la conservation et à la gestion des données
Les exigences en matière de rapports sur les données, le code et les logiciels dans les domaines de recherche interdisciplinaires doivent être conformes aux principes FAIR : trouvables, accessibles, interopérables et réutilisables. Pour renforcer la confiance dans l’IA et l’apprentissage automatique, il est nécessaire de disposer d’ensembles de données accessibles au public, de qualité éprouvée, avec des bugs et des solutions rendus publics.
Le défi actuel est le stockage des données, car l’utilisation généralisée de référentiels communs peut entraîner des problèmes de métadonnées, affectant le suivi de la provenance des données et l’accès automatisé. Certains référentiels de données de recherche disciplinaire avancée fournissent des services de contrôle de la qualité et de complément d'informations, mais cela nécessite généralement des coûts en main-d'œuvre et en temps.
En outre, l’article mentionne des problèmes tels que le financement des référentiels, les limitations des différents types de référentiels et le manque de demande pour des référentiels spécifiques à un domaine. Les organisations universitaires, les organismes de financement et autres devraient fournir un investissement financier soutenu pour soutenir et maintenir des référentiels de données appropriés.
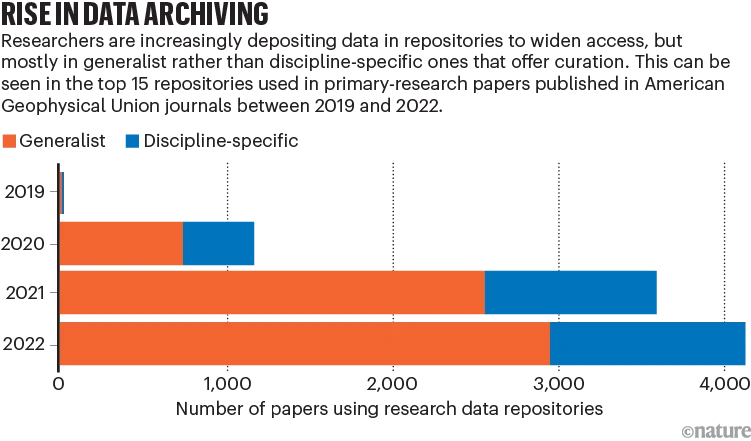
Les chercheurs choisissent de plus en plus des référentiels de données communs
5. Examiner l’impact à long terme
Alors que nous étudions l’application généralisée de l’intelligence artificielle et de l’apprentissage automatique dans le domaine scientifique, nous devons examiner l’impact à long terme et veiller à ce que ces technologies puissent réduire les écarts sociaux, renforcer la confiance et inclure activement différentes opinions et voix.
Ce que dit la Chine sur l'utilisation de l'IA
« Comment utiliser l’IA et comment bien l’utiliser » est également un sujet brûlant dans le domaine de l’IA dans mon pays ces dernières années.
Aux yeux des deux sessions de cette année, l'intelligence artificielle est l'un des domaines les plus actifs de l'innovation en matière de technologies numériques, avec l'IA générative (AIGC), les modèles pré-entraînés à grande échelle et l'IA basée sur la connaissance ouvrent de nouvelles opportunités dans l'industrie, et nous devons saisir la « fenêtre temporelle » du développement technologique.
Lei Jun, fondateur, président et PDG du groupe Xiaomi, a proposé d'encourager et de soutenir la chaîne industrielle de l'innovation scientifique et technologique, en promouvant la planification et l'aménagement de l'industrie des robots bioniques ; accélérer la formulation de normes de sécurité des données pour l’ensemble du cycle de vie des automobiles afin de guider le développement industriel ; construire un mécanisme et une plateforme de partage de données automobiles pour promouvoir le partage et l’utilisation des données automobiles.
Le fondateur de 360, Zhou Hongyi, espère créer la combinaison « Microsoft + OpenAI » de la Chine, diriger la recherche sur la technologie des grands modèles et créer un écosystème d'innovation ouverte pour le crowdsourcing open source.
L'académicien Zhang Boli a suggéré de mettre en place un projet spécial majeur pour la fabrication biopharmaceutique, de soutenir la recherche et le développement de technologies et d'équipements clés pour la fabrication pharmaceutique intelligente et d'encourager le développement d'équipements biopharmaceutiques.
On constate que les représentants et les membres des deux sessions sont très optimistes quant à la piste de l’intelligence artificielle. En plus de permettre la mise en place de technologies, nous espérons également que l’IA pourra mieux contribuer au développement des entreprises et de la société, dans le respect des principes de confiance et de prudence.
Références :
https://www.nature.com/articles/d41586-023-03316-8
https://doi.org/10.22541/essoar.168132856.66485758/v1








