Command Palette
Search for a command to run...
Trente Chercheurs Ont Publié Conjointement Une Revue Nature, Passant En Revue 10 Ans Et Déconstruisant La Façon Dont l'IA a Remodelé Le Paradigme De La Recherche Scientifique

La découverte scientifique est un processus complexe impliquant plusieurs étapes interdépendantes, notamment la formation d’hypothèses, la conception expérimentale et la collecte et l’analyse de données. Ces dernières années, l’intégration de l’IA et de la recherche scientifique fondamentale est devenue de plus en plus profonde. Grâce à l’IA, les scientifiques ont pu accélérer les progrès de la recherche scientifique et promouvoir la mise en œuvre des résultats de la recherche scientifique.
La revue de référence « Nature » a publié un article de Hanchen Wang, chercheur postdoctoral à l'École d'informatique et de technologie génétique de l'Université de Stanford, Tianfan Fu du Département d'informatique et d'ingénierie du Georgia Institute of Technology, et Yuanqi Du du Département d'informatique de l'Université Cornell, et 30 autres.Cet article examine le rôle de l’IA dans la recherche scientifique fondamentale au cours de la dernière décennie et souligne les défis et les lacunes restants.
Cet article résume les articles.
Lire l'article complet :https://www.nature.com/articles/s41586-023-06221-2

Étude de cas de l'intégration de l'IA et de la recherche scientifique fondamentale Source de l'image : article original, traduit en chinois par HyperAI
01 Collecte et organisation de données de recherche scientifique assistées par l'IA
Alors que l’échelle et la complexité des données collectées par les plateformes expérimentales continuent d’augmenter, le traitement en temps réel et le calcul haute performance (HPC) sont nécessaires pour stocker et analyser de manière sélective les données générées rapidement.
Sélection des données
En prenant comme exemple les expériences de collision de particules, plus de 100 To de données seront générées par seconde, ce qui représente un énorme défi pour les technologies de transmission et de stockage de données existantes. Dans ces expériences de physique, les métadonnées dépassant 99,99% doivent être détectées en temps réel et les données non pertinentes doivent être supprimées.Des technologies telles que l’apprentissage profond et les encodeurs automatiques peuvent aider à identifier des événements anormaux dans des recherches scientifiques similaires et réduire considérablement la pression de la transmission et du traitement des données.
Actuellement, ces technologies sont largement utilisées dans des domaines tels que la physique, les neurosciences, les sciences de la Terre, l’océanographie et l’astronomie.
Annotation des données
Les algorithmes de pseudo-étiquetage et de propagation d'étiquettes sont d'une grande importance pour remplacer l'étiquetage fastidieux des données. Ils peuvent permettre au modèle d’étiqueter automatiquement des données massives avec seulement une petite quantité de données étiquetées avec précision.
Génération de données
Grâce à l’augmentation automatique des données et aux modèles génératifs profonds, des points de données synthétiques supplémentaires peuvent être générés pour étendre les données de formation.Des expériences ont montré que les réseaux antagonistes génératifs (GAN) peuvent synthétiser des images réalistes dans de nombreux domaines.Ces données vont des collisions de particules, des coupes pathologiques, des radiographies thoraciques, du contraste par résonance magnétique, des microstructures de matériaux tridimensionnelles (3D), des fonctions protéiques aux séquences de gènes.
Optimisation des données
L’IA peut améliorer considérablement la résolution de l’image, réduire le bruit et éliminer les erreurs lors de la mesure de la rondeur, maintenant ainsi une cohérence de précision élevée sur tous les sites.Les exemples d’application incluent la visualisation de régions spatio-temporelles telles que les trous noirs, la capture de collisions de particules physiques, l’amélioration de la résolution des images de cellules vivantes et une meilleure détection des types de cellules dans différents environnements biologiques.
02 Apprendre des représentations significatives des données scientifiques
L’apprentissage profond peut extraire et optimiser des représentations significatives de données scientifiques à différents niveaux d’abstraction. Une représentation de haute qualité doit conserver autant d’informations que possible sur les données tout en restant concise et accessible. Voici 3 nouvelles stratégies qui répondent à ces exigences :Priorités géométriques, apprentissage auto-supervisé et modélisation du langage.
Priorités géométriques
La géométrie et la structure sont essentielles à la recherche scientifique. La symétrie est un concept important en géométrie, et les propriétés structurelles importantes sont stables dans les directions spatiales et ne changent pas. L’intégration de priors géométriques dans les représentations apprises s’est avérée efficace dans l’analyse d’images scientifiques.
Apprentissage profond géométrique
Les réseaux neuronaux graphiques sont devenus l’approche de référence pour l’apprentissage en profondeur sur des ensembles de données avec des structures géométriques et relationnelles sous-jacentes. En fonction des questions scientifiques, les chercheurs ont développé différentes représentations graphiques pour capturer des systèmes complexes.
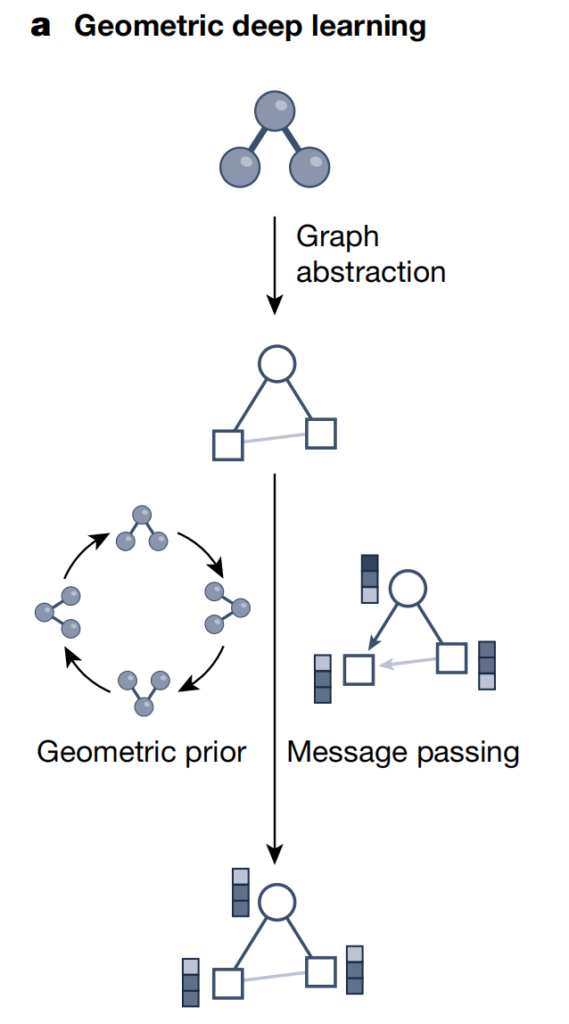
Comme le montre la figure ci-dessus, l’apprentissage profond géométrique utilise la structure graphique et la stratégie de transmission d’informations neuronales pour intégrer les informations de géométrie, de structure et de symétrie des données scientifiques telles que les molécules/matériaux. Cette approche échange des informations neuronales le long des bords de la structure du graphe pour générer des représentations latentes (vecteurs d'intégration) tout en prenant en compte d'autres priors géométriques (tels que les contraintes d'invariance et de progression arithmétique). donc,L’apprentissage profond géométrique peut intégrer des informations structurelles complexes dans des modèles d’apprentissage profond, permettant ainsi une meilleure compréhension et un meilleur traitement des ensembles de données géométriques sous-jacents.
Apprentissage auto-supervisé
L'apprentissage auto-supervisé permet au modèle de comprendre les caractéristiques générales de l'ensemble de données sans s'appuyer sur des étiquettes explicites. Il peut servir d’étape de prétraitement clé pour apprendre des fonctionnalités transférables à partir de données non étiquetées à grande échelle avant d’affiner le modèle pour effectuer des tâches en aval. Un tel modèle pré-entraîné avec une compréhension large du domaine scientifique est un prédicteur à usage général.Il peut être adapté à une variété de tâches, améliorant ainsi l’efficacité et surpassant les méthodes purement supervisées.
Comme le montre la figure ci-dessus, représenter efficacement différents échantillons tels que des images satellites nécessite de capturer à la fois leurs similitudes et leurs différences. Les stratégies d’apprentissage auto-supervisé telles que l’apprentissage contrastif peuvent atteindre cet objectif en générant des données de pairs augmentées, en alignant les données positives et en séparant les paires de données négatives. Ce processus itératif améliore les intégrations, ce qui donne lieu à des représentations latentes informatives et à de meilleures performances dans les tâches de prédiction en aval.
Modélisation du langage
La modélisation du langage masqué est une méthode populaire pour l’apprentissage auto-supervisé du langage naturel et des séquences biologiques (voir la figure ci-dessous).

Le traitement du langage naturel et le traitement des séquences biologiques s’influencent mutuellement.Lors de la formation, l'objectif est de prédire le prochain jeton dans la séquence, tandis que dans la formation basée sur le masque, la tâche auto-supervisée consiste à récupérer les jetons masqués dans la séquence en utilisant le contexte de séquence bidirectionnelle. Les modèles de langage protéique peuvent coder des séquences d’acides aminés, capturer des propriétés structurelles et fonctionnelles et évaluer l’aptitude évolutive des variantes virales. Lorsqu’il s’agit de séquences biochimiques, les modèles de langage chimique peuvent explorer efficacement le vaste espace chimique.
Comme le montre la figure ci-dessus, la modélisation du langage masqué peut capturer efficacement la sémantique des données de séquence, telles que le langage naturel et les séquences biologiques. Cette approche alimente les éléments masqués de l'entrée dans un module Transformer, qui comprend des étapes de prétraitement telles que le codage de position. La ligne grise représente le mécanisme d’auto-attention et la profondeur de couleur reflète la taille du poids de l’attention. Il combine la représentation de l'entrée non masquée pour prédire avec précision l'entrée masquée. La méthode produit des représentations de séquences de haute qualité en répétant ce processus de complétion automatique sur de nombreux éléments de l'entrée.
Architecture du transformateur
Transformer unifie les réseaux neuronaux graphiques et les modèles de langage, domine le traitement du langage naturel et a été appliqué avec succès à des domaines tels que la détection de signaux sismiques, la modélisation de séquences d'ADN et de protéines, la modélisation des effets de la variation de séquence sur les fonctions biologiques et la régression symbolique.
opérateurs neuronaux
En apprenant une cartographie entre les espaces de fonctions, l'opérateur neuronal est invariant en termes de discrétisation, peut fonctionner sur n'importe quelle discrétisation d'entrée et converge vers une valeur limite lorsque la grille est affinée. Une fois qu’un opérateur neuronal est formé, il peut être évalué à n’importe quelle résolution sans recyclage.
03 Générer des hypothèses scientifiques basées sur l'IA
L’IA peut générer des hypothèses en identifiant des expressions symboliques candidates à partir d’observations bruyantes. Ils peuvent aider à concevoir des objets, apprendre les probabilités postérieures bayésiennes des hypothèses et les utiliser pour générer des hypothèses compatibles avec les données et les connaissances scientifiques.
Prédicteur de boîte noire d'hypothèses scientifiques
L'apprentissage faiblement supervisé peut être utilisé pour former des modèles dans lesquels une supervision bruyante, limitée ou imprécise est utilisée comme signal de formation.
Les méthodes d’IA ont été formées avec des simulations haute fidélité et ont été utilisées pour cribler efficacement des bibliothèques moléculaires à grande échelle ; en génomique, l'architecture Transformer est formée pour prédire les valeurs d'expression des gènes à l'aide de séquences d'ADN, identifiant ainsi les mutations génétiques ; dans le repliement des protéines, AlphaFold2 peut prédire les coordonnées atomiques 3D des protéines à partir de séquences d'acides aminés ; en physique des particules, l'identification des quarks charmes inhérents aux protons implique de filtrer toutes les structures possibles et d'adapter les données expérimentales à toutes les structures potentielles.
Outre les problèmes directs, l’IA est également de plus en plus utilisée pour résoudre des problèmes inverses.
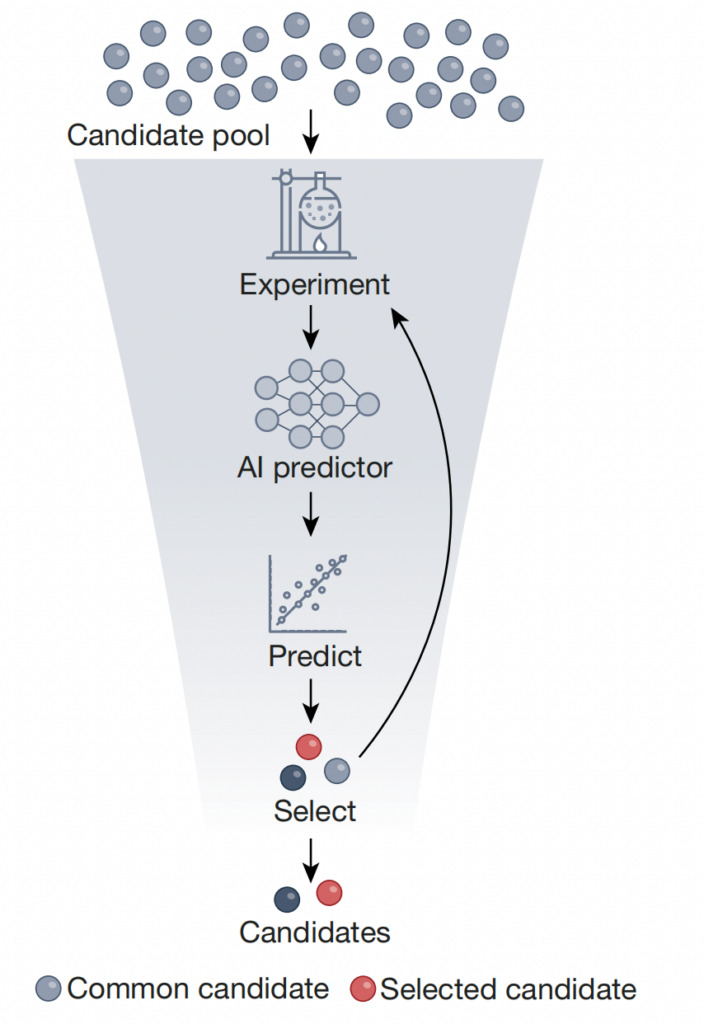
Comme le montre la figure ci-dessus, le criblage à haut débit fait référence à l’utilisation de prédicteurs d’IA formés sur des ensembles de données générés expérimentalement pour éliminer un petit nombre d’objets cibles présentant des caractéristiques idéales.Cela réduit la taille totale de la bibliothèque candidate de plusieurs ordres de grandeur.Cette approche peut utiliser l’apprentissage auto-supervisé pour pré-entraîner le prédicteur sur un grand nombre d’objets non filtrés, puis affiner le prédicteur sur un ensemble de données d’objets filtrés avec des lectures étiquetées. L’évaluation en laboratoire et la quantification de l’incertitude peuvent compléter cette approche, simplifiant ainsi le processus de sélection, le rendant plus rentable et plus rapide, et accélérant finalement l’identification des composés, matériaux et biomolécules candidats.
Exploration des espaces d'hypothèses combinatoires
Par rapport aux méthodes traditionnelles qui reposent sur des règles conçues manuellement, les stratégies d’IA peuvent être utilisées pour évaluer la récompense de chaque recherche et identifier les directions de recherche à plus forte valeur ajoutée.
Pour les problèmes d'optimisation, des algorithmes évolutionnaires peuvent être utilisés pour résoudre des tâches de régression symbolique. L'optimisation combinatoire s'applique également à des tâches telles que la découverte de molécules possédant des propriétés médicamenteuses souhaitables, où chaque étape de la conception moléculaire est un processus de décision discret. De plus, les méthodes d’apprentissage par renforcement ont été appliquées avec succès à divers problèmes d’optimisation, tels que la maximisation de l’expression des protéines, la planification de l’hydroélectricité dans la plaine amazonienne et l’exploration de l’espace des paramètres des accélérateurs de particules.
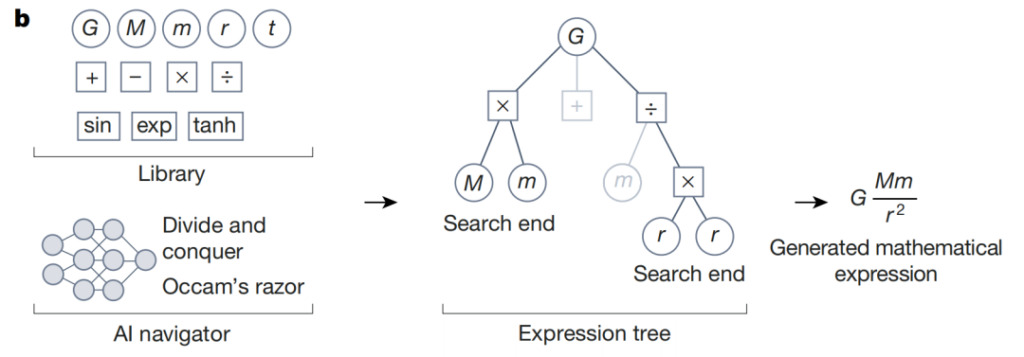
Comme le montre la figure ci-dessus, lors de la régression symbolique, le navigateur IA exploite les récompenses prédites par l’agent d’apprentissage par renforcement et les critères de conception tels que le rasoir d’Occam pour se concentrer sur les éléments les plus prometteurs des hypothèses candidates. L'exemple suivant illustre le processus de raisonnement pour l'expression mathématique de la loi de la gravitation universelle de Newton. Les chemins de recherche à faible score apparaissent sous forme de branches grises dans l'arbre d'expression symbolique. Guidé par l'action associée à la récompense prédite la plus élevée,Ce processus itératif converge vers une expression mathématique cohérente avec les données et répondant aux autres critères de conception.
Optimisation des espaces d'hypothèses différentiables
Les espaces différentiables conviennent aux méthodes basées sur le gradient, qui peuvent trouver efficacement des solutions optimales locales.Pour permettre l'optimisation basée sur le gradient, deux approches sont couramment utilisées :
* Utiliser des modèles tels que les VAE pour cartographier des hypothèses candidates discrètes dans un espace différentiable latent ;
* Assouplir l'hypothèse discrète en un objet différentiable qui peut être optimisé dans un espace différentiable (cette relaxation peut prendre différentes formes, comme le remplacement des variables discrètes par des variables continues, ou l'utilisation d'une version souple des contraintes d'origine).
En astrophysique, les VAE ont été utilisés pour estimer les paramètres des détecteurs d'ondes gravitationnelles sur la base de modèles de formes d'onde de trous noirs pré-entraînés. Cette méthode est six ordres de grandeur plus rapide que les méthodes traditionnelles. En science des matériaux, les règles thermodynamiques sont combinées avec des autoencodeurs pour concevoir un espace latent interprétable afin d'identifier les cartes de structure cristalline.
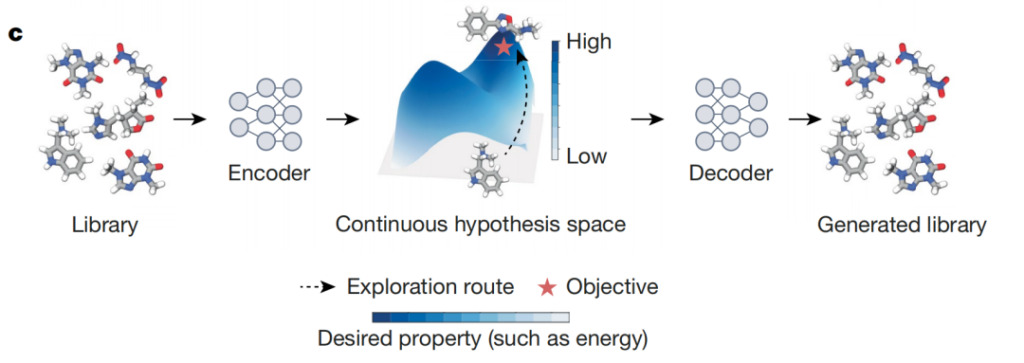
Comme le montre la figure ci-dessus, les différenciateurs IA sont un modèle d'auto-encodeur qui mappe des objets discrets (tels que des composés) à des points dans un espace latent continu différentiable. Cet espace permet l’optimisation des cibles, comme la sélection de composés à partir de grandes bibliothèques chimiques qui maximisent des paramètres biochimiques spécifiques. Le plan idéal représente l'espace latent appris, avec des couleurs plus foncées indiquant les zones où sont concentrés les objets avec des scores de prédiction plus élevés. En utilisant cet espace latent, le différenciateur d’IA peut identifier efficacement les objets qui maximisent les propriétés attendues des annotations en étoile rouge.
04 Expériences et simulations basées sur l'IA
Les simulations informatiques peuvent remplacer les expériences de laboratoire coûteuses et offrir des possibilités de test plus efficaces et plus flexibles.L’apprentissage profond peut identifier et affiner les hypothèses pour des tests efficaces et permet aux simulations informatiques de relier les observations aux hypothèses.
Évaluer efficacement les hypothèses scientifiques
Les systèmes d’IA fournissent des outils de conception et d’optimisation expérimentaux.Ces outils peuvent compléter les méthodes scientifiques traditionnelles, réduire le nombre d’expériences nécessaires et économiser des ressources.
Plus précisément, les systèmes d’IA peuvent aider à deux étapes clés des tests expérimentaux : la planification et le guidage. La planification de l’IA fournit une approche systématique pour concevoir des expériences, optimiser l’efficacité et explorer des domaines inconnus. Dans le même temps, le guidage par l’IA oriente le processus expérimental vers des hypothèses à haut rendement, permettant au système d’apprendre des observations précédentes et d’ajuster le processus expérimental. Ces approches d’IA peuvent être basées sur des modèles (utilisant des simulations et des connaissances préalables) ou sans modèle, basées uniquement sur des algorithmes d’apprentissage automatique.
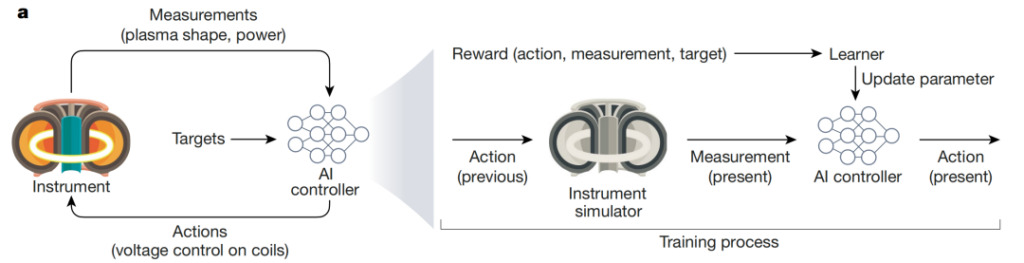
L'image ci-dessus montre l'utilisation de l'IA pour contrôler le processus complexe et dynamique de fusion nucléaire : Degrave et al. a développé un contrôleur d'IA capable de réguler la fusion nucléaire grâce au champ magnétique du réacteur tokamak. L'agent IA reçoit des mesures en temps réel des niveaux de tension électrique et de la configuration du plasma et prend des mesures pour contrôler le champ magnétique afin d'atteindre des objectifs expérimentaux (tels que le maintien d'une alimentation électrique normale). Le contrôleur est formé par simulation et met à jour les paramètres du modèle à l'aide de la fonction de récompense.
Dériver des observables à partir d'hypothèses à l'aide de simulations
La technologie de simulation informatique existante repose largement sur la compréhension et la cognition humaines des mécanismes sous-jacents du système. Les systèmes d’IA peuvent améliorer la simulation informatique en s’adaptant plus précisément et plus efficacement aux paramètres clés des systèmes complexes, en résolvant des équations différentielles qui peuvent contrôler des systèmes complexes et en modélisant les états des systèmes complexes.
Prenons l’exemple des champs de force moléculaires. Bien qu'ils soient interprétables, ils sont limités dans la représentation de diverses fonctions, et leur processus de génération nécessite de forts biais inductifs et une richesse de connaissances scientifiques. Afin d'améliorer la précision des simulations moléculaires, un potentiel neuronal basé sur l'IA qui s'adapte aux données mécaniques quantiques coûteuses et précises a été développé pour remplacer les champs de force traditionnels.
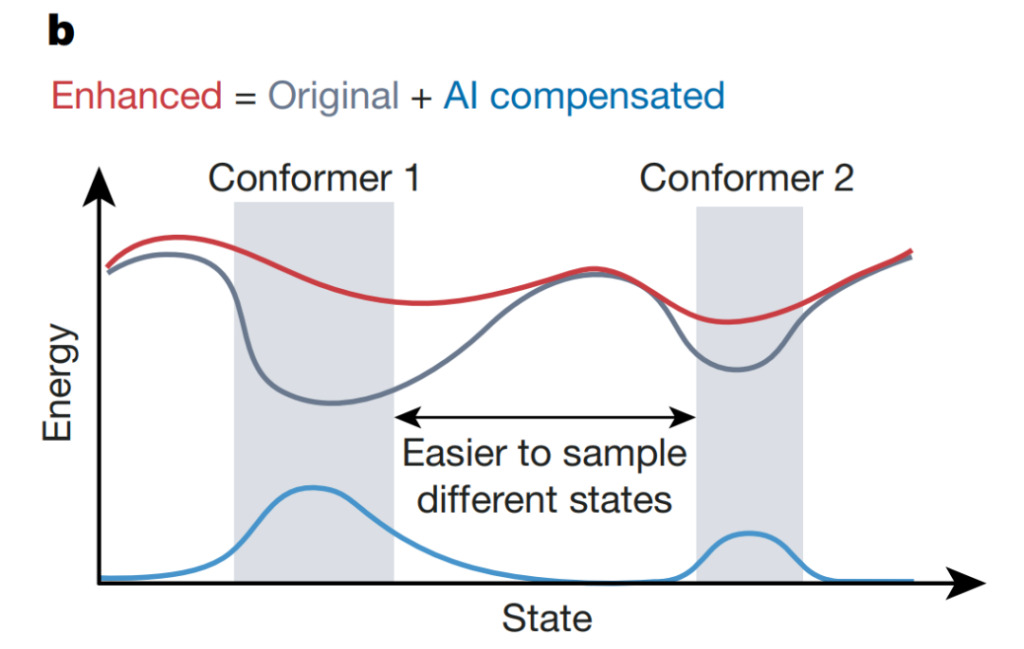
Dans les simulations informatiques de systèmes complexes, les systèmes d’IA peuvent accélérer la détection d’événements inhabituels, tels que les transitions entre les structures conformationnelles des protéines. Comme le montre la figure ci-dessus, Wang et al. a utilisé un estimateur d'incertitude basé sur un réseau neuronal pour guider l'augmentation de l'énergie potentielle qui compense l'énergie potentielle d'origine, permettant au système de s'échapper du minimum local (gris) et d'explorer l'espace de configuration plus rapidement. Cette approche pourrait améliorer l’efficacité et la précision des simulations, conduisant à une compréhension plus approfondie des phénomènes biologiques complexes.
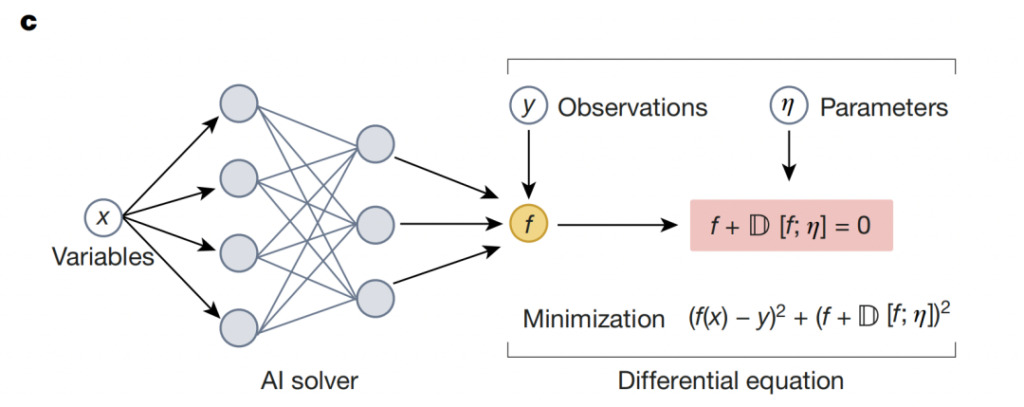
Les solveurs neuronaux combinent la physique avec la flexibilité de l'apprentissage profond:Création de réseaux neuronaux basés sur la connaissance du domaine
05 L'IA pour la science : un long chemin à parcourir
Les systèmes d’IA contribuent à la compréhension scientifique et se sont avérés capables d’étudier des processus et des objets difficiles à visualiser ou à détecter, et de générer systématiquement de nouvelles idées en construisant des modèles à partir de données et en combinant les données avec des simulations et des calculs évolutifs. Cependant, pour garantir la sécurité et la confidentialité de l’IA,Ce processus nécessite encore le déploiement d’une technologie mature.
Pour utiliser l’IA de manière responsable dans la recherche scientifique, les chercheurs doivent mesurer les niveaux d’incertitude, d’erreur et d’utilité des systèmes d’IA. À mesure que les systèmes d’IA continuent de se développer, on s’attend à ce que l’IA ouvre la porte à des découvertes scientifiques qui étaient auparavant hors de portée, mais il reste encore un long chemin à parcourir en termes de soutien aux théories, aux méthodes, aux logiciels et à l’infrastructure matérielle.
Références :








