Command Palette
Search for a command to run...
Nouvelle Interprétation Du Code Du Millénaire : DeepMind Développe Ithaca Pour Déchiffrer Les Inscriptions Grecques

Les inscriptions et les stèles reflètent les pensées, la culture et la langue des civilisations passées. Afin de déchiffrer les codes datant de milliers d’années, les épigraphistes doivent accomplir trois tâches principales : la restauration du texte, l’attribution temporelle et l’attribution régionale.
La méthode de recherche la plus courante est la « correspondance de chaînes », qui consiste à faire correspondre des inscriptions avec des polices similaires en fonction de la mémoire ou du corpus de requêtes, ce qui conduit à une confusion et à une mauvaise évaluation des résultats.
À cette fin, DeepMind et l’Université de Venise Foscari ont développé conjointement Ithaca, qui utilise l’IA pour aider les chercheurs humains à déchiffrer les inscriptions grecques.
Auteur | Ajouter zéro
Rédacteur | Xuecai, Sanyang
L'épigraphie, l'étude des inscriptions épigraphiques, des stèles et des inscriptions anciennes, relie les pensées, la culture et la langue des civilisations passées. Aujourd’hui, la communauté académique est confrontée à une question importante : comment étudier en profondeur et comprendre ces patrimoines ?
D'une manière générale, l'interprétation des inscriptions et des stèles exige que les épigraphistes accomplissent les trois tâches fondamentales suivantes :
- Restauration de texte : compléter les parties manquantes du texte ;
- Attribution chronologique : déterminer quand une inscription a été écrite ;
- Attribution géographique : Déterminer l'emplacement d'origine où l'inscription a été écrite.
Pour accomplir ces tâches, les épigraphistes doivent mener des études comparatives approfondies combinant le contexte avec les corpus existants. Bien que l’émergence de corpus numériques puisse réduire dans une certaine mesure la charge de travail des chercheurs, la méthode de correspondance des chaînes qu’ils adoptent conduit souvent à une confusion et à une mauvaise appréciation des résultats. Parallèlement, en raison de leur ancienneté, de nombreuses inscriptions ont été endommagées ou perdues, ce qui rend la tâche plus compliquée.

Icône de réparation d'inscription
L’IA est capable de découvrir et d’appliquer des modèles statistiques complexes pour analyser de grandes quantités de données difficiles à traiter pour les humains.. C'est pourquoi des chercheurs de DeepMind et de l'Université Ca' Foscari de Venise ont développé conjointement Ithaca, qui vise à aider les épigraphes dans le travail de restauration de texte, d'attribution chronologique et d'attribution géographique.
Les expériences ont confirmé que la précision du travail de restauration du texte d'Ithaca atteignait 62%, l'erreur d'attribution temporelle était de moins de 30 ans, la précision d'attribution régionale atteignait 71% et il y avait une bonne synergie. L'article correspondant a été publié dans « Nature ».

Les résultats connexes ont été publiés dans Nature
Obtenez le papier :
https://www.nature.com/articles/s41586-022-04448-z
Le code pertinent d'Ithaca a été ouvert sur la plateforme GitHub, et les épigraphistes peuvent également utiliser l'interface publique pour mener des recherches.
Code source : https://GitHub.com/deepmind/Ithaca
Interface publique : https://Ithaca.deepmind.com
Procédures expérimentales
Ensemble de données
Collection d'inscriptions exploitables par machine I.PHI
Les chercheurs ont mené leurs recherches en s'appuyant sur l'ensemble de données publiques consultables sur les inscriptions grecques (PHI) du Packard Humanities Institute.
Remarque : PHI signifie l'ensemble de données publiques Searchable Greek Inscriptions du Packard Humanities Institute.
Pour faciliter le fonctionnement de la machine, les chercheurs ont filtré le texte dans PHI, attribué des identifiants numériques, des emplacements annotés correspondants et des informations temporelles aux textes sélectionnés, et ont finalement obtenu l'ensemble de données I.PHI.
L'ensemble de données I.PHI est actuellement le plus grand ensemble de données d'inscription exploitable par machine, contenant 78 608 inscriptions.

I. Exemple d'ensemble de données PHI
Formation d'algorithmes:Formation pour 3 tâches majeures
1. Retouche de texte : utilisez la fonction de perte d'entropie croisée pour masquer une partie du texte d'entrée et entraînez le modèle Ithaca à prédire les caractères masqués ;
2. Attribution temporelle : avec des intervalles de 10 ans, Ithaque a discrétisé la période autour de 800 avant J.-C. en périodes de temps avec une probabilité égale, ce que l'on appelle la distribution de probabilité cible. En utilisant la divergence de Kullback-Leibler, minimisez la différence entre la distribution de probabilité prédite et la distribution de probabilité cible ;
3. Attribution régionale : en utilisant la fonction de perte d'entropie croisée, les métadonnées régionales sont utilisées comme étiquette cible et la technique de lissage d'étiquette avec un coefficient de lissage de 10% est appliquée pour éviter le surajustement.
Sur cette base, Ithaca a été formé pendant une semaine sur 128 pods TPU v4 sur Google Cloud Platform avec une taille de lot de 8 192 textes et un optimiseur LAMB avec un 3 × 10-4 Le taux d'apprentissage optimise les paramètres d'Ithaca.
Structure du modèle:Le modèle Ithaca se compose de 4 parties :
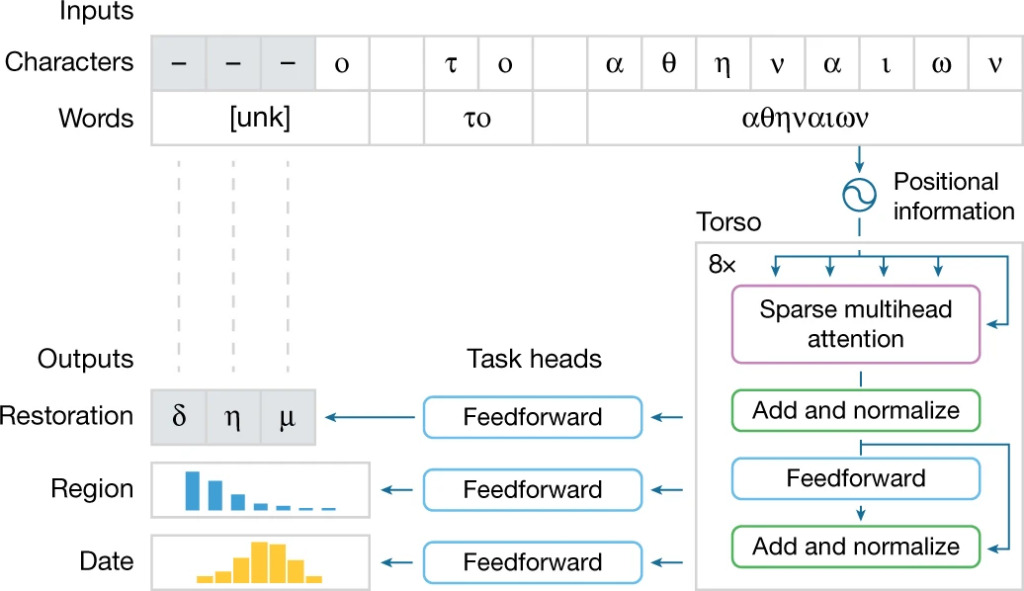
Flux de traitement des tâches du modèle Ithaca
La structure du modèle Ithaca peut être résumée dans les quatre parties suivantes :
1. Entrées : Le texte d'entrée est traité à la fois comme des caractères et des mots, garantissant qu'Ithaca peut comprendre des caractères individuels et les intégrer dans des mots pour une compréhension contextuelle. Les mots inconnus et corrompus sont remplacés par le symbole spécial « unk » ;
2. Torse : Le torse d'Ithaca adopte une architecture de réseau neuronal Transformer empilé, qui utilise un mécanisme d'attention pour mesurer l'impact des caractères et des mots d'entrée sur le processus de décision du modèle.
Dans la partie corps, Ithaca combine le texte d'entrée avec les informations de position et le normalise en une séquence de longueur égale au nombre de caractères d'entrée, où chaque élément de la séquence est un vecteur d'intégration de 2 048 dimensions. Cette séquence est transmise à 3 chefs de tâches différents ;
3. Têtes de tâches : Ithaca dispose de 3 têtes de tâches différentes, chaque tête étant constituée d'un réseau neuronal à propagation avant peu profond, spécialisé dans les tâches de restauration de texte, d'attribution temporelle et d'attribution régionale.
4. Résultats : Les trois tâches génèrent respectivement les résultats correspondants.
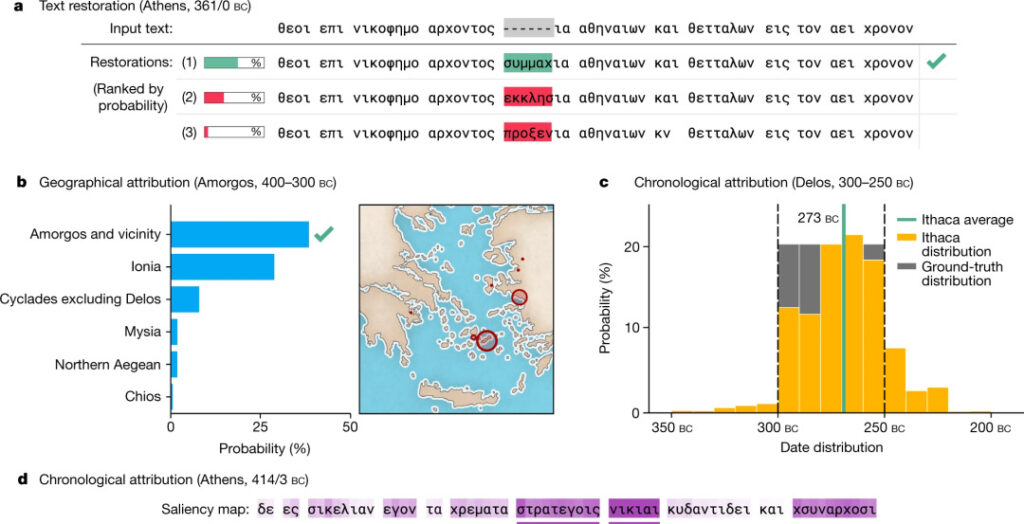
Sortie d'Ithaque
- Réparation de texte : Ithaca prédit 3 caractères manquants et fournit un ensemble de 20 meilleures prédictions de décodage classées par probabilité (a ci-dessus) ;
- Attribution régionale : Ithaca divise le texte d'entrée en 84 régions et utilise des cartes et des graphiques à barres pour mettre en œuvre intuitivement un tableau de classement de prédiction régionale possible (Figure b ci-dessus) ;
- Attribution du temps : pour étendre l'interprétabilité des tâches d'attribution du temps, Ithaca remonte à 800 avant J.-C. à 800 après J.-C. et prédit une distribution catégorique des dates au lieu de produire une seule valeur de date (Figure 2c ci-dessus).
Résultats de la formation du modèle
Comparaison complète:Ithaca a des performances supérieures
* 4 mécanismes de contraste
1. Historien antique : les anthropologues utilisent l’ensemble d’entraînement pour trouver des similitudes dans les textes et comparer les résultats avec Ithaque ;
2. Historien antique et Ithaque : Ithaque propose 20 restaurations possibles aux épigraphistes et évalue la synergie entre Ithaque et les anthropologues ;
3. Pythia : un réseau neuronal récurrent séquence à séquence pour les tâches de peinture de texte, évaluant les performances de peinture de texte d'Ithaca ;
4. Onomastique : Les chercheurs ont utilisé la distribution connue des noms personnels grecs dans le temps et l'espace pour compléter l'attribution temporelle et régionale d'un ensemble de textes et évaluer les performances d'attribution temporelle et régionale d'Ithaque.
* 3 indicateurs d'évaluation majeurs
1. Taux d'erreur de caractère (CER) : évalue les tâches de réparation de texte et calcule la différence normalisée entre la séquence de réparation prédite la plus élevée et la séquence cible ;
2. Précision Top-k : évalue les tâches de restauration de texte ou d'attribution régionale et calcule la proportion des k premiers résultats avec la probabilité la plus élevée dans les résultats de prédiction qui contiennent des étiquettes correctes. La précision supérieure 1 est souvent utilisée ;
3. métrique de distance (méthodes) : évalue la tâche d'attribution temporelle et calcule la distance en années entre la moyenne de la distribution prédite et l'intervalle de vérité terrain.
* Résultats expérimentaux
1. Réparation de texte

Tâches de réparation de texte
a : inscription originale ;
b : inscription restaurée de Rhodes-Osborne ;
c : Restauration de Pythia, qui présente 74 discordances avec la version Rhodes-Osborne ;
d : Restauration d'Ithaque, qui présente 45 discordances avec la version Rhodes-Osborne ;
Les pièces réparées correctes sont indiquées en vert sur la figure et les erreurs sont surlignées en rouge.
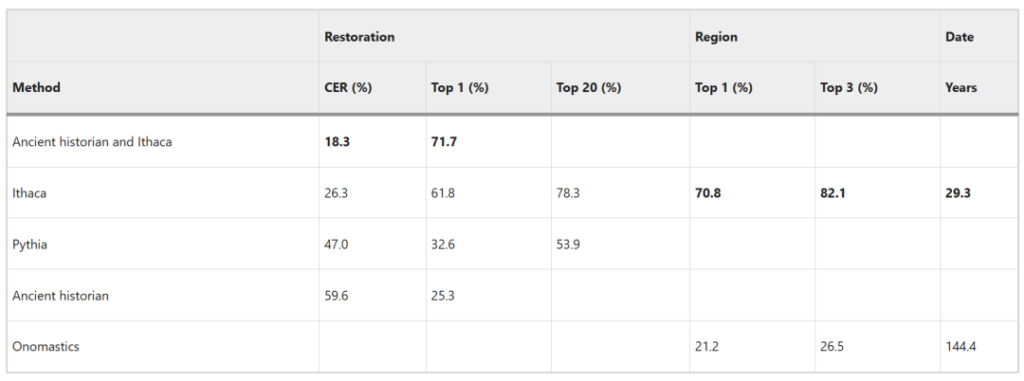
L'inscription originale (IG II² 116) manque de 378 caractères. Sur la base de la restauration réalisée par Rhodes-Osborne en 2003 (Figure b), le CER d'Ithaca est de 26,3% et la précision du top 1 atteint 61,8%.
Comparé aux épigraphistes, le CER d’Ithaque est 2,2 fois inférieur. La précision des 20 meilleures prédictions d'Ithaca est de 78,3%, ce qui est 1,5 fois plus élevé que celui de Pythia.
2. Attribution géographique
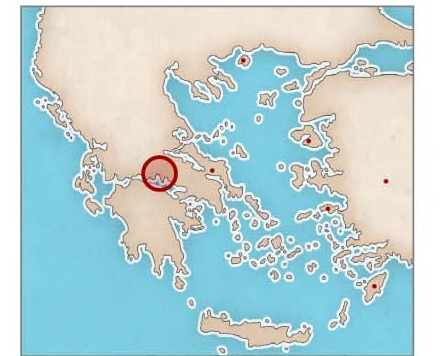
Tâches d'attribution géographique
Dans la tâche d'attribution de région, Ithaca a obtenu une précision de 70,8% dans le top 1 et une précision de 82,1% dans le top 3.Le diagramme ci-dessus montre qu'Ithaque a correctement attribué l'inscription de manumission à la région de Delphes.
3. Attribution du temps
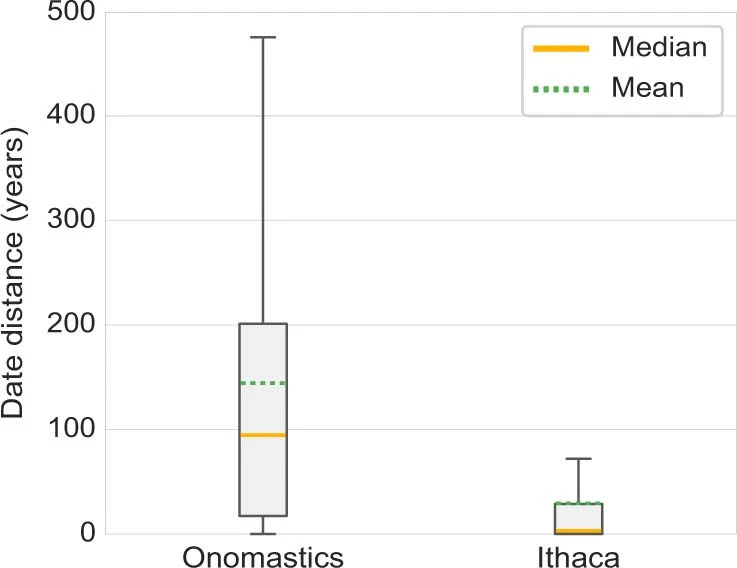
Tâche d'attribution du temps
Pour la tâche d'attribution du temps, la prédiction moyenne des experts humains était de 144,4 ans et la médiane était de 94,5 ans, tandis que la prédiction d'Ithaca avait une différence moyenne de 29,3 ans par rapport à l'intervalle de vérité terrain et une différence médiane de seulement 3 ans.
En combinant les performances d'Ithaca dans les trois tâches, les résultats sont résumés comme suit :
Comparé aux experts humains et à la Pythie, Ithaque démontre des performances supérieures dans les trois tâches.
Lorsque des experts humains ont collaboré avec Ithaca, ils ont obtenu un CER de 18,3% et une précision de premier ordre de 71,7%., montrant une amélioration de 3,2 fois et de 2,8 fois par rapport aux épigraphistes travaillant seuls, et une amélioration significative par rapport à Ithaca accomplissant la tâche seul.Démontrer la synergie supérieure d'Ithaca.
Comparaison des résultats expérimentaux d'Ithaca
Attribution du temps:JEThaca résout les conflits
La datation de certaines inscriptions a été controversée. Le critère traditionnel de datation sigma utilisé pour la datation ne peut pas garantir l'exactitude, et les épigraphes ne peuvent pas déterminer si ces inscriptions ont été faites avant ou après 446/5 av. J.-C.
L'inscription ci-dessous était traditionnellement datée de 446/5 av. J.-C., mais a récemment été redatée à 424/3 av. J.-C.

Une inscription controversée (partielle)
Cet ensemble controversé d'inscriptions existe dans l'ensemble de données I.PHI, et les résultats d'attribution temporelle d'Ithaque renversent l'interprétation historique traditionnelle basée sur la norme de datation sigma, et la différence avec les faits de base nouvellement découverts est en moyenne de 5 ans.
Cela prouve queIthaca peut aider les historiens à réduire les plages de dates et à augmenter la précision de leur attribution d’événements historiques.
IA et humains : 1 + 1 > 2 ?
La partie résultat de sortie d'Ithaca est très intéressante. Il ne produit pas une réponse unique, mais propose plusieurs résultats possibles parmi lesquels les chercheurs peuvent choisir.
Cela vaut la peine d’apprendre de cela pour les autres développeurs et utilisateurs d’IA. Au lieu de s’appuyer sur les résultats de l’IA, il est préférable d’utiliser l’IA pour « explorer la voie », éliminer certaines mauvaises réponses et élargir la profondeur et l’étendue de la pensée indépendante.
En combinant la puissance de calcul de l’IA avec la créativité et la réflexion approfondie des humains, Ithaca nous aide à créer un nouveau paradigme pour travailler main dans la main avec l’IA.
À l’avenir, nous nous attendons à ce que l’IA et les chercheurs humains travaillent ensemble pour atteindre l’objectif « 1+1 > 2 ».
Références :
https://www.nature.com/articles/s41586-022-04448-z
https://www.nature.com/articles/d41586-023-03212-1
-- sur--








