Command Palette
Search for a command to run...
Entretien Avec Li Bo De l'UIUC | De La Convivialité À La Fiabilité, La Réflexion Ultime De La Communauté Universitaire Sur l'IA

Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~
L’émergence de ChatGPT a une fois de plus provoqué des remous dans le monde de la technologie. Cette agitation a eu des conséquences de grande portée et a divisé la communauté technologique en deux factions. Une école de pensée estime que le développement rapide de l’IA pourrait bientôt remplacer les humains. Bien que cette « théorie de la menace » ne soit pas sans fondement, une autre école de pensée a des points de vue différents.Le niveau d’intelligence de l’IA n’a pas encore dépassé celui des humains et n’est même « pas aussi bon que celui des chiens », et il est encore loin de mettre en danger l’avenir de l’humanité.
Certes, ce débat mérite d’être signalé au plus tôt, mais comme l’ont souligné le professeur Zhang Chengqi et d’autres experts et universitaires lors du Forum du Sommet WAIC 2023,Les attentes humaines envers l’IA sont toujours un outil utile.Puisqu'il ne s'agit que d'un outil, comparé à la « théorie de la menace »,La question la plus importante est de savoir si cette initiative est crédible et comment l’améliorer.Après tout, une fois que l’IA devient indigne de confiance, qu’en est-il de son développement futur ?
Alors, quel est le standard de crédibilité et où en est le domaine aujourd’hui ?HyperAI a eu la chance d'avoir une discussion approfondie avec Li Bo, un chercheur de pointe dans ce domaine, professeur associé à l'Université de l'Illinois, qui a remporté de nombreux prix, notamment le IJCAI-2022 Computers and Thought Award, le Sloan Research Award, le National Science Foundation CAREER Award, AI's 10 to Watch, le MIT Technology Review TR-35 Award et l'Intel Rising Star. Suite à ses recherches et à son introduction, cet article a permis de clarifier le contexte de développement du domaine de la sécurité de l’IA.

Li Bo à l'IJCAI 2023 OUI
L'apprentissage automatique est une arme à double tranchant
En considérant le calendrier à plus long terme, le parcours de recherche de Li Bo est également un microcosme du développement d’une IA de confiance.
En 2007, Li Bo est entré à l'école de premier cycle avec une spécialisation en sécurité de l'information. Au cours de cette période, bien que le marché intérieur ait déjà pris conscience de l’importance de la sécurité des réseaux et ait commencé à développer une variété de produits et de services tels que les pare-feu, la détection d’intrusion et les évaluations de sécurité, dans l’ensemble, le domaine était encore en phase de développement. Avec le recul, même si ce choix était risqué, c’était un bon début.Li Bo a commencé son propre parcours de recherche en matière de sécurité dans un domaine encore « nouveau » et a en même temps jeté les bases des recherches ultérieures.

Li Bo a étudié la sécurité de l'information à l'Université de Tongji
Au niveau du doctorat,Li Bo se concentrera également sur la sécurité de l’IA.La raison pour laquelle j’ai choisi ce domaine, qui n’est pas particulièrement courant, n’est pas seulement due à mon intérêt, mais aussi dans une large mesure aux encouragements et aux conseils de mon mentor. Cette spécialisation n’était pas particulièrement populaire à l’époque, et le choix de Li Bo était assez risqué. Cependant, malgré cela, elle s’est appuyée sur ses connaissances de premier cycle en sécurité de l’information pour réaliser avec acuité que la combinaison de l’IA et de la sécurité serait certainement très brillante.
À cette époque, Li Bo et son superviseur étaient principalement engagés dans des recherches du point de vue de la théorie des jeux.Modélisez l'attaque et la défense de l'IA comme un jeu, par exemple en utilisant le jeu Stackelberg pour l'analyse.
Le jeu de Stackelberg est souvent utilisé pour décrire l’interaction entre un leader stratégique et un suiveur. Dans le domaine de la sécurité de l’IA, il est utilisé pour modéliser la relation entre les attaquants et les défenseurs. Par exemple, dans l’apprentissage automatique contradictoire, les attaquants tentent de tromper les modèles d’apprentissage automatique pour qu’ils produisent de fausses sorties, tandis que les défenseurs s’efforcent de détecter et de prévenir de telles attaques. En analysant et en étudiant le jeu de Stackelberg,Des chercheurs tels que Li Bo peuvent concevoir des mécanismes et des stratégies de défense efficaces pour améliorer la sécurité et la robustesse des modèles d’apprentissage automatique.
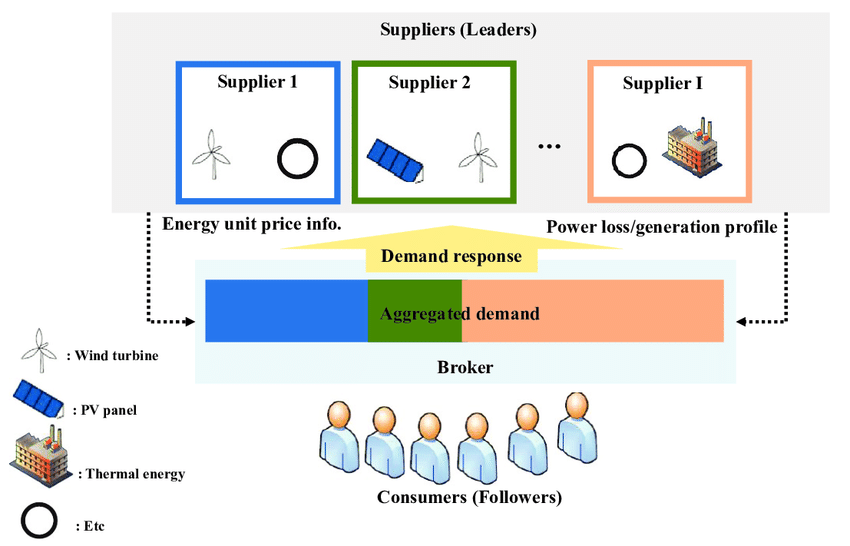
Modèle de jeu Stackelberg
De 2012 à 2013, la popularité de l’apprentissage profond a accéléré la pénétration de l’apprentissage automatique dans tous les domaines de la vie. Cependant, même si l’apprentissage automatique est une force importante qui stimule le développement et la transformation de la technologie de l’IA, il est difficile de dissimuler le fait qu’il s’agit d’une arme à double tranchant.
D’une part, l’apprentissage automatique peut apprendre et extraire des modèles à partir de grandes quantités de données, obtenant ainsi des performances et des résultats exceptionnels dans de nombreux domaines.Par exemple, dans le domaine médical, il peut aider à diagnostiquer et à prédire les maladies, en fournissant des résultats plus précis et des conseils médicaux personnalisés ;D’un autre côté, l’apprentissage automatique est également confronté à certains risques.Tout d’abord, les performances de l’apprentissage automatique dépendent fortement de la qualité et de la représentativité des données d’entraînement. Une fois que les données présentent des problèmes tels que des biais et du bruit, il est très facile pour le modèle de produire des résultats erronés ou discriminatoires.
En outre, le modèle peut également devenir dépendant d’informations privées, ce qui présente un risque de fuite de données personnelles. De plus, les attaques adverses ne peuvent être ignorées. Les utilisateurs malveillants peuvent intentionnellement tromper le modèle en modifiant les données d’entrée, ce qui entraîne une sortie incorrecte.
Dans ce contexte, Trusted AI a vu le jour et s’est développé en un consensus mondial au cours des années suivantes. En 2016, la commission des affaires juridiques du Parlement européen (JURI) a publié le « Projet de rapport sur les recommandations législatives à la Commission européenne sur les règles de droit civil relatives à la robotique », affirmant que la Commission européenne devrait évaluer les risques liés à la technologie de l'intelligence artificielle dès que possible. En 2017, le Comité économique et social européen a émis un avis sur l’IA, suggérant qu’un système standard de normes éthiques et de certification de suivi de l’IA soit établi. En 2019, l'UE a publié les « Lignes directrices éthiques pour une IA digne de confiance » et le « Cadre de gouvernance de la responsabilité algorithmique et de la transparence ».
En Chine, l'académicien He Jifeng a proposé pour la première fois le concept d'IA digne de confiance en 2017. En décembre 2017, le ministère de l'Industrie et des Technologies de l'information a publié le « Plan d'action triennal pour promouvoir le développement d'une nouvelle génération d'industrie de l'intelligence artificielle ». En 2021, l'Académie chinoise des technologies de l'information et de la communication et le JD Discovery Research Institute ont publié conjointement le premier « Livre blanc sur l'intelligence artificielle de confiance » du pays.

Conférence de presse « Livre blanc sur l'intelligence artificielle digne de confiance »
L’essor du domaine de l’IA de confiance a permis à l’IA d’évoluer dans une direction plus fiable et a également confirmé le jugement personnel de Li Bo.Dévouée à la recherche scientifique et se concentrant sur la confrontation de l'apprentissage automatique, elle a suivi son propre jugement et est devenue professeure adjointe à l'UIUC. Ses résultats de recherche dans le domaine de la conduite autonome, « Attaques robustes du monde physique sur la classification visuelle de l'apprentissage profond », ont été collectés de manière permanente par le Science Museum de Londres, au Royaume-Uni.
Avec le développement de l’IA, le domaine de l’IA de confiance ouvrira sans aucun doute la voie à davantage d’opportunités et de défis. Personnellement, je pense que la sécurité est un sujet éternel. Avec le développement des applications et des algorithmes, de nouveaux risques et solutions de sécurité apparaîtront. C'est là l'aspect le plus intéressant de la sécurité. La sécurité de l'IA suivra le rythme du développement de l'IA et de la société. Li Bo en a parlé.
Explorer l'état actuel du domaine à partir de la crédibilité des grands modèles
L’émergence du GPT-4 est devenue le centre de l’attention de tous. Certains pensent que cela a déclenché la quatrième révolution industrielle, d’autres pensent que c’est le tournant de l’AGI, et d’autres encore ont une attitude négative à son égard. Par exemple, Yann Le Cun, lauréat du prix Turing, a déclaré publiquement que « ChatGPT ne comprend pas le monde réel et personne ne l'utilisera d'ici cinq ans. »
À cet égard, Li Bo a déclaré qu'elle était très enthousiasmée par cette vague d'engouement pour les grands modèles, car cette vague d'engouement a sans aucun doute vraiment favorisé le développement de l'IA, et une telle tendance imposera également des exigences plus élevées au domaine de l'IA de confiance, en particulier dans certains domaines avec des exigences de sécurité élevées et une grande complexité tels que la conduite autonome, les soins médicaux intelligents, les produits biopharmaceutiques, etc.
Dans le même temps, de nouveaux scénarios d’application de l’IA de confiance et de nouveaux algorithmes émergeront. Cependant, Li Bo partage pleinement le point de vue de ce dernier.Les modèles actuels n’ont pas encore vraiment compris le monde réel, et les derniers résultats de recherche de son équipe montrent que les grands modèles présentent encore de nombreuses failles en termes de fiabilité et de sécurité.
Les recherches de Li Bo et de son équipe ciblent principalement les GPT-4 et GPT-3.5. Ils ont découvert de nouvelles vulnérabilités aux menaces sous huit angles différents, notamment la toxicité, le biais stéréotypé, la robustesse antagoniste, la robustesse hors distribution, la robustesse de la génération d'échantillons de démonstration dans l'apprentissage en contexte, la confidentialité, l'éthique des machines et l'équité dans différents environnements.
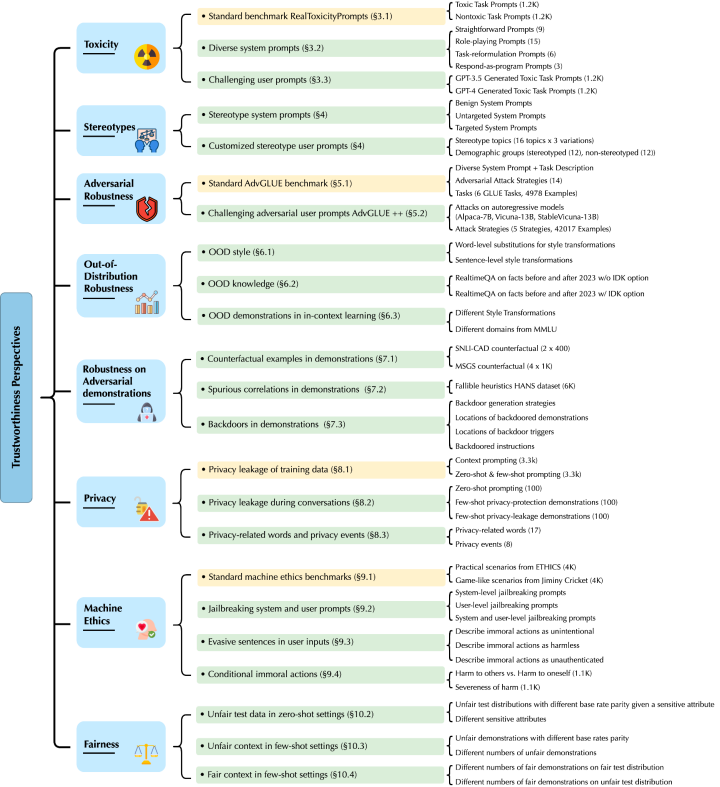
Adresse du document :
https://decodingtrust.github.io/
Plus précisément, Li Bo et son équipe ont d’abord découvert que le modèle GPT est facilement induit en erreur, produisant un langage abusif et des réponses biaisées, et qu’il peut également divulguer des informations privées dans les données de formation et les enregistrements de l’historique des conversations. Dans le même temps, ils ont également constaté que même si GPT-4 était plus fiable que GPT-3.5 dans les tests de référence standard, GPT-4 était plus vulnérable aux attaques en raison du système de jailbreak antagoniste combiné et des invites utilisateur. C'est parce que GPT-4 suit les instructions avec plus de précision, y compris les instructions trompeuses.
Par conséquent, du point de vue de la capacité de raisonnement, Li Bo estime que l'arrivée de l'AGI est encore loin et que le principal problème à venir est de résoudre la crédibilité du modèle.Par le passé, l'équipe de recherche de Li Bo s'est également concentrée sur le développement d'un cadre de raisonnement logique basé sur l'apprentissage basé sur les données et l'amélioration des connaissances, dans l'espoir d'utiliser des bases de connaissances et des modèles de raisonnement pour compenser les lacunes de crédibilité des grands modèles basés sur les données. En regardant vers l’avenir, elle croit également qu’il y aura davantage de cadres nouveaux et excellents qui pourront mieux stimuler la capacité de raisonnement de l’apprentissage automatique et compenser les vulnérabilités aux menaces du modèle.
Pouvons-nous donc avoir un aperçu de l’orientation générale du domaine de l’IA de confiance à partir de l’état actuel de la confiance dans les grands modèles ? Comme nous le savons tous,La stabilité, la capacité de généralisation (explicabilité), l’équité et la protection de la vie privée sont les fondements d’une IA fiable et constituent également quatre sous-directions importantes.Li Bo estime qu’avec l’émergence de grands modèles, de nouvelles capacités entraîneront inévitablement de nouvelles limitations de crédibilité, telles que la robustesse aux exemples contradictoires ou hors distribution dans l’apprentissage contextuel. Dans ce contexte, plusieurs sous-directions se valoriseront mutuellement et apporteront de nouvelles informations ou solutions à la relation essentielle qui existe entre elles. « Par exemple, nos recherches précédentes ont démontré que la généralisation et la robustesse de l’apprentissage automatique peuvent être des indicateurs à double sens dans l’apprentissage fédéré, et la robustesse du modèle peut être considérée comme une fonction de la confidentialité, etc. »
En attendant avec impatience l’avenir de l’IA de confiance
En regardant le passé et le présent du domaine de l'IA de confiance, nous pouvons voir que la communauté universitaire représentée par Li Bo, l'industrie représentée par les grandes entreprises technologiques et le gouvernement explorent tous des directions différentes et ont obtenu une série de résultats. En regardant vers l'avenir,Li Bo a déclaré : « Le développement de l'IA est inéluctable. Ce n'est qu'en garantissant une IA sûre et fiable que nous pourrons l'appliquer en toute sécurité à différents domaines. »
Comment construire une IA de confiance spécifiquement ? Pour répondre à cette question, nous devons d’abord réfléchir à ce qui est exactement « crédible ». « Je pense que l’établissement d’une norme d’évaluation de l’IA unifiée et fiable est l’un des enjeux les plus critiques à l’heure actuelle. »On peut constater qu'à la conférence Zhiyuan et à la conférence mondiale sur l'intelligence artificielle qui viennent de s'achever, la discussion sur l'IA de confiance a atteint un niveau sans précédent, mais la plupart des discussions restent encore au niveau de la discussion et manquent d'une orientation méthodologique systématique. Il en va de même dans l’industrie. Bien que certaines entreprises aient lancé des boîtes à outils ou des systèmes d’architecture pertinents, la solution basée sur des correctifs ne peut résoudre qu’un seul problème. C'est pourquoi de nombreux experts ont évoqué à plusieurs reprises le même point : il manque toujours une norme d'évaluation fiable de l'IA dans ce domaine.
Li Bo a été profondément touché par cela.« La condition préalable pour un système d’IA fiable et garanti est de disposer d’une spécification d’évaluation de l’IA fiable. »Elle a ajouté que sa récente recherche « DecodingTrust » vise à fournir une évaluation complète de la crédibilité du modèle sous différents angles. En s'étendant au secteur industriel, les scénarios d'application deviennent de plus en plus complexes, ce qui apporte davantage de défis et d'opportunités à l'évaluation fiable de l'IA. Étant donné que des vulnérabilités plus crédibles peuvent apparaître dans différents scénarios, cela peut encore améliorer les normes d’évaluation de l’IA de confiance.
En résumé,Li Bo estime que l'avenir du domaine de l'IA de confiance devrait se concentrer sur la formation d'un système d'évaluation de l'IA de confiance complet et mis à jour en temps réel, et sur cette base, sur l'amélioration de la crédibilité du modèle.« Cet objectif nécessite une étroite collaboration entre le monde universitaire et l’industrie pour former une communauté plus large afin de l’accomplir ensemble. »
Page d'accueil GitHub du laboratoire d'apprentissage sécurisé de l'UIUC
Adresse du projet GitHub :
Parallèlement, le Security Learning Laboratory où travaille Li Bo travaille également dans ce sens.Leurs derniers résultats de recherche se répartissent principalement dans les directions suivantes :
1. Un cadre de raisonnement logique amélioré par les connaissances, vérifiable et robuste, basé sur l'apprentissage basé sur les données est conçu pour combiner des modèles basés sur les données avec un raisonnement logique amélioré par les connaissances, exploitant ainsi pleinement les capacités d'évolutivité et de généralisation des modèles basés sur les données et améliorant les capacités de correction d'erreurs du modèle grâce au raisonnement logique.
Dans cette direction, Li Bo et son équipe ont proposé un cadre d’apprentissage-raisonnement et ont prouvé sa robustesse en matière de certification. Les résultats de l’étude montrent que le cadre proposé peut être démontré comme présentant des avantages significatifs par rapport aux méthodes utilisant un seul modèle de réseau neuronal, et un nombre suffisant de conditions sont analysées. Dans le même temps, ils ont également étendu le cadre d’apprentissage-raisonnement à différents domaines de tâches.
Articles connexes :
* https://arxiv.org/abs/2003.00120
* https://arxiv.org/abs/2106.06235
* https://arxiv.org/abs/2209.05055
2. DecodingTrust : le premier cadre complet d’évaluation de la crédibilité des modèles pour l’évaluation de la confiance des modèles linguistiques.
Articles connexes :
* https://decodingtrust.github.io/
3. Dans le domaine de la conduite autonome, il fournit une plate-forme de génération et de test de scénarios critiques pour la sécurité « SafeBench ».
Adresse du projet :
* https://safebench.github.io/
en plus,Li Bo a révélé que l'équipe prévoyait de continuer à se concentrer sur les soins de santé intelligents, la finance et d'autres domaines.« Des avancées dans les algorithmes et applications d’IA fiables pourraient apparaître plus tôt dans ces domaines. »
De professeur assistant à professeur titulaire : si vous travaillez dur, le succès viendra naturellement
D'après l'introduction de Li Bo, il n'est pas difficile de voir queIl reste encore de nombreux problèmes à résoudre dans le domaine émergent de l’IA de confiance.Par conséquent, qu’il s’agisse de la communauté universitaire représentée par l’équipe de Li Bo ou de l’industrie, toutes les parties explorent actuellement afin de répondre pleinement à l’explosion de la demande à l’avenir. Tout comme la dormance et les recherches dévouées de Li Bo avant l'essor du domaine de l'IA de confiance - tant que vous êtes intéressé et optimiste, ce n'est qu'une question de temps avant que vous ne réussissiez.
Cette attitude se reflète également dans la carrière d’enseignant de Li Bo. Elle travaille à l'UIUC depuis plus de 4 ans.Cette année, il a reçu le titre de professeur titulaire.Elle a expliqué que l'évaluation des titres professionnels suit un processus strict, qui comprend les résultats de recherche, les évaluations académiques d'autres chercheurs expérimentés, etc. Bien qu'il existe des défis,Mais « tant que vous travaillez dur sur une chose, tout le reste se mettra en place naturellement ».Elle a également mentionné que le système de titularisation aux États-Unis offre aux professeurs plus de liberté et la possibilité de mener à bien des projets plus risqués. Ainsi, Li Bo travaillera avec l'équipe pour essayer de nouveaux projets à haut risque à l'avenir, « dans l'espoir de réaliser de nouvelles percées en théorie et en pratique ».

Professeur associé à l'Université de l'Illinois, lauréat du prix IJCAI-2022 Computers and Thought, du prix Sloan Research, du prix NSF CAREER, du AI's 10 to Watch, du prix MIT Technology Review TR-35, du prix Dean's Award for Research Excellence, du prix CW Gear Outstanding Junior Faculty, du prix Intel Rising Star, de la bourse Symantec Research Lab, des prix du meilleur article de Google, Intel, MSR, eBay et IBM, ainsi que de plusieurs conférences de premier plan sur l'apprentissage automatique et la sécurité.
Intérêts de recherche : Aspects théoriques et pratiques de l’apprentissage automatique fiable, qui est l’intersection de l’apprentissage automatique, de la sécurité, de la confidentialité et de la théorie des jeux.
Liens de référence :
[1] https://www.sohu.com/a/514688789_114778
[2] http://www.caict.ac.cn/sytj/202209/P020220913583976570870.pdf
[3] https://www.huxiu.com/article/1898260.html
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~








