Command Palette
Search for a command to run...
Remplissez Les Blancs Dans l'espace Matériel : Le MIT Utilise l'apprentissage Profond Pour Résoudre Les Problèmes De Tests Non Destructifs

Contenu en un coup d'œil :Les tests de matériaux jouent un rôle essentiel dans l’ingénierie, la science et la fabrication. Les méthodes traditionnelles de test des matériaux, telles que la découpe et les tests par réactifs chimiques, sont destructives, chronophages et gourmandes en ressources. Récemment, des scientifiques du MIT ont utilisé l’apprentissage profond pour développer une technique capable de compléter les informations manquantes et de déterminer plus précisément la structure interne des matériaux grâce à des observations de surface.
Mots-clés:Tests de matériel d'apprentissage profond CNN
Auteur : daserney
Rédacteur en chef|Sanyang
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~
Lors du traitement des données, l’un des défis souvent rencontrés est de restaurer une image complète à partir d’images floues ou d’informations partielles.Ce défi est appelé le « problème inverse » et il est non seulement courant dans les diagnostics médicaux, mais se produit également fréquemment dans la science des matériaux.Si nous pouvons efficacement compléter ces informations manquantes, il sera possible de comprendre les propriétés des tissus ou des matériaux biologiques de manière plus complète et plus précise, et ainsi de prendre des décisions plus précises.
La question de savoir comment tester de manière non destructive la structure interne des matériaux a préoccupé de nombreux praticiens du domaine. Les tests non destructifs font référence à l’utilisation de technologies et d’équipements modernes pour détecter la structure interne des matériaux sans endommager ou affecter l’organisation interne et les performances des matériaux.Bien que la détection puisse être effectuée à l’aide de techniques telles que les rayons X, ces méthodes sont généralement coûteuses et nécessitent un équipement encombrant.
À cette fin, l’étudiant en doctorat chinois du MIT (Massachusetts Institute of Technology) Zhenze Yang et le professeur Markus Buehler ont combiné plusieurs architectures d’apprentissage en profondeur.Dans les cas 2D et 3D, respectivement, les parties manquantes du matériau sont récupérées avec des informations limitées et la microstructure est davantage caractérisée.
Actuellement, les résultats de la recherche ont été publiés dans la revue Advanced Materials, intitulée « Fill in the Blank: Transferrable Deep Learning Approaches to Recover Missing Physical Field Information ».

L'étudeLes résultats ont été publiés dans Advanced Materials
Adresse du document :
https://onlinelibrary.wiley.com/doi/full/10.1002/adma.202301449
Aperçu expérimental : Combinaison de modèles pour le « puzzle à trous »
La figure ci-dessous montre le schéma général de l’étude.Dans l’image de gauche, le cube gris est la pièce manquante. Dans les cas 2D et 3D, deux modèles d’IA sont combinés pour effectuer la tâche, respectivement. Les chercheurs ont formé le premier modèle d'IA pour « combler les lacunes » et restaurer le champ complet à partir du champ masqué, et ont formé le deuxième modèle d'IA pour « résoudre le puzzle », en utilisant le champ complet restauré comme entrée pour obtenir inversement la microstructure correspondante du matériau composite.
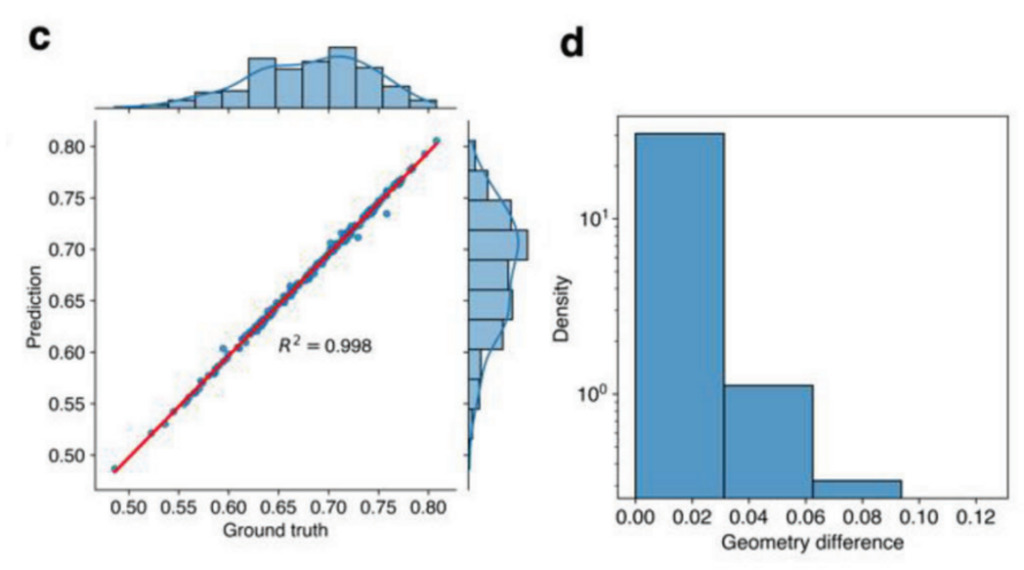
Figure 1 : Schéma général
Les chercheurs ont utilisé l’analyse par éléments finis (FEA) pour calculer les champs de déformation et de contrainte des matériaux composites 2D et 3D dans des conditions spécifiques.
Dans le cas 2D,Les chercheurs ont créé une grille symétrique 8×8 pour construire la géométrie composite (un total de 232 géométries possibles). Alors,1 000 microstructures composites différentes ont été générées aléatoirement pour des tests de traction uniaxiale.
Dans le cas 3D,Les chercheurs ont utilisé une grille 2×4×4 pour créer deux couches de microstructures (un total de 232 géométries possibles) et une grille 4×4×4 pour construire un composite à quatre couches (un total de 264 géométries possibles). Pour conserver le même nombre de géométries possibles que dans le cas 2D, les chercheurs ont choisi une grille 2×4×4 comme base de référence.Et 2 000 géométries différentes ont été générées aléatoirement pour les calculs FEA.
Visualisation et prétraitement des données
Dans le cas 2D,À l’aide des outils de visualisation Abaqus, les chercheurs ont généré des images des champs de contrainte et de déformation obtenus à partir de l’analyse par éléments finis.Il est représenté par des barres blanches et rouges.Ensuite, il est prétraité avec Python pour le recadrage, le redimensionnement et la recoloration. La taille de l'image prétraitée est de 256 × 256. Dans une géométrie ou une microstructure composite, les blocs rouges représentent les matériaux souples, tandis que les blocs blancs représentent les matériaux rigides.Les chercheurs ont introduit des masques de forme régulière et irrégulière, les masques réguliers étant de forme carrée et dont la taille variait de 96 à 128.
Dans le cas 3D, les chercheurs ont collecté les valeurs de déformation et de contrainte pour chaque élément.Il est ensuite normalisé pour former une matrice 16×32×32×1.Similaire au cas 2D,Utilisez le code Python pour visualiser les contours des champs de contrainte et de déformation.Une série d'images de terrain sont stockées dans une matrice 16×32×32×3, qui est utilisée comme représentation des données pour la formation et le test des modèles d'apprentissage en profondeur.La visualisation de la microstructure composite 3D correspondante a été réalisée par rendu volumique à l'aide de la bibliothèque Matplotlib.
Sélection du modèle : GAN + ViViT + CNN
Cette étude a utilisé une variété de modèles d’apprentissage profond.Y compris les réseaux antagonistes génératifs (GAN), les modèles ViViT basés sur des transformateurs et les réseaux neuronaux convolutifs (CNN).
- GAN: Pour remplir les images 2D, les chercheurs ont utilisé un modèle GAN, connu sous le nom de deuxième version du modèle DeepFill, qui peut effectuer une restauration d'image de forme libre.
- ViViT : Dans le cas 3D, les chercheurs ont utilisé le modèle ViViT basé sur l’architecture Transformer pour combler les lacunes.
- CNN : Après avoir obtenu le champ complet, les modèles CNN ont été utilisés dans les cas 2D et 3D pour établir un lien inverse entre le comportement mécanique et la microstructure du matériau composite.
Résultats expérimentaux : ViViT + CNN réalise une prédiction parfaite
Cas 2D
Pour obtenir l’erreur de prédiction, les chercheurs ont tracé un nuage de points de la moyenne de contrainte prédite par rapport à la valeur réelle dans la zone masquée. La forme du masque est générée aléatoirement.Comme le montre la figure c ci-dessous, étant donné 200 données de test R2 L'indice atteint 0,998, indiquant que le modèle GAN fonctionne bien.
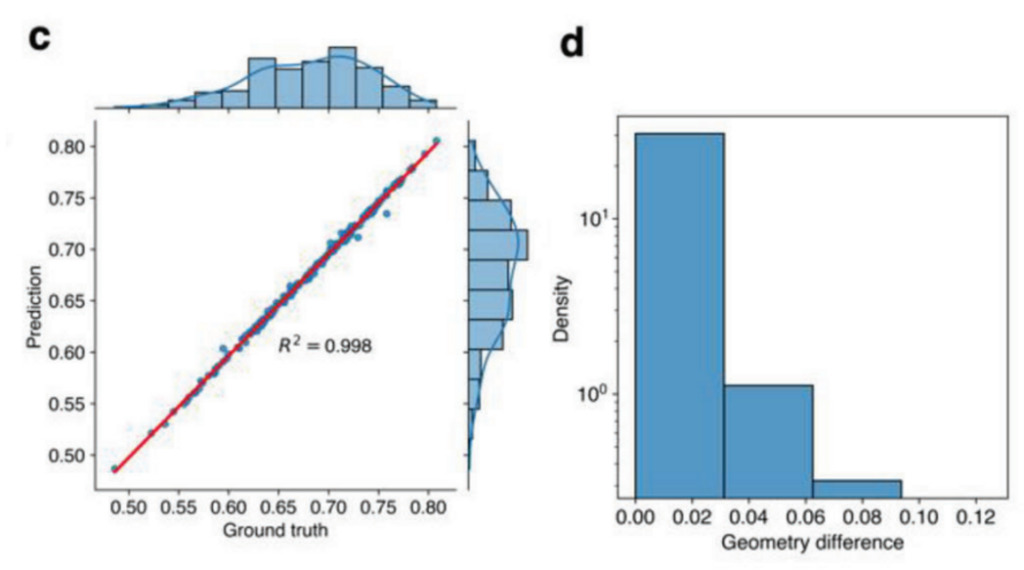
Figure 2 : Performances du modèle en 2D
c : Performances du modèle GAN sur l'image rembourrée. La vérité terrain et la valeur prédite montrent une cohérence élevée (R2 = 0,998).
d : Performances du modèle CNN pour la reconnaissance géométrique. La figure montre la distribution de la différence géométrique entre la vérité terrain et les résultats de prédiction.
De plus, les chercheurs ont évalué les performances du modèle CNN dans la reconnaissance géométrique en calculant la différence géométrique. La différence de géométrie est le nombre de blocs de matériaux différents entre les séquences vraies et prédites.Comme le montre la figure 2d, la plupart des séquences prédites sont les mêmes que les séquences réelles, la différence géométrique maximale parmi les 200 données de test est de 0,0625 et il existe deux différences dans 32 blocs.Si l’image de champ récupérée est inexacte, l’erreur géométrique augmentera. Par conséquent, les prédictions précises du modèle CNN valident davantage les hautes performances du modèle GAN.
Situation 3D
Dans la pratique de l’ingénierie réelle, la microstructure des matériaux composites 3D est généralement plus compliquée que celle des matériaux 2D. La figure ci-dessous montre la comparaison entre 8 cadres de terrain prédits et la vérité terrain. Les résultats montrent queLe modèle ViViT amélioré est capable d'utiliser les champs mécaniques d'une couche (images 1 à 8) dans le matériau composite pour prédire avec précision les champs d'une autre couche (images 9 à 16).
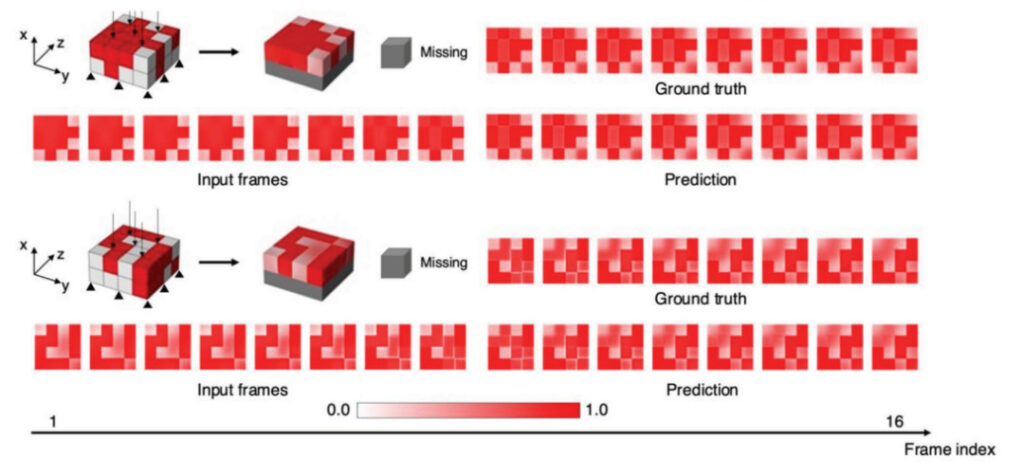
Figure 3 : Prédictions du cadre de champ pour deux exemples de matériaux composites à deux couches.
Les 8 premières images sont prises en entrée et les 8 images restantes sont prédites par le modèle d'apprentissage en profondeur.
La figure 4 montre l’erreur quadratique moyenne (MSE) des images 9 à 16 pour les 200 données de test. Le MSE pour chaque point de données est calculé en faisant la moyenne des différences au carré des valeurs de pixels entre les cartes de champ prédites et les valeurs réelles. Le MSE global des 8 images prédites est très faible et le MSE moyen de toutes les images est inférieur à 0,001, ce qui montre les excellentes performances du modèle ViViT.
L'erreur quadratique moyenne (MSE) est un indicateur couramment utilisé pour évaluer la précision des modèles de prédiction. Dans le processus de prédiction, le MSE est utilisé pour mesurer le degré de différence entre la valeur prédite et la valeur réelle. Plus la valeur MSE est petite, plus la précision du modèle de prédiction est élevée.
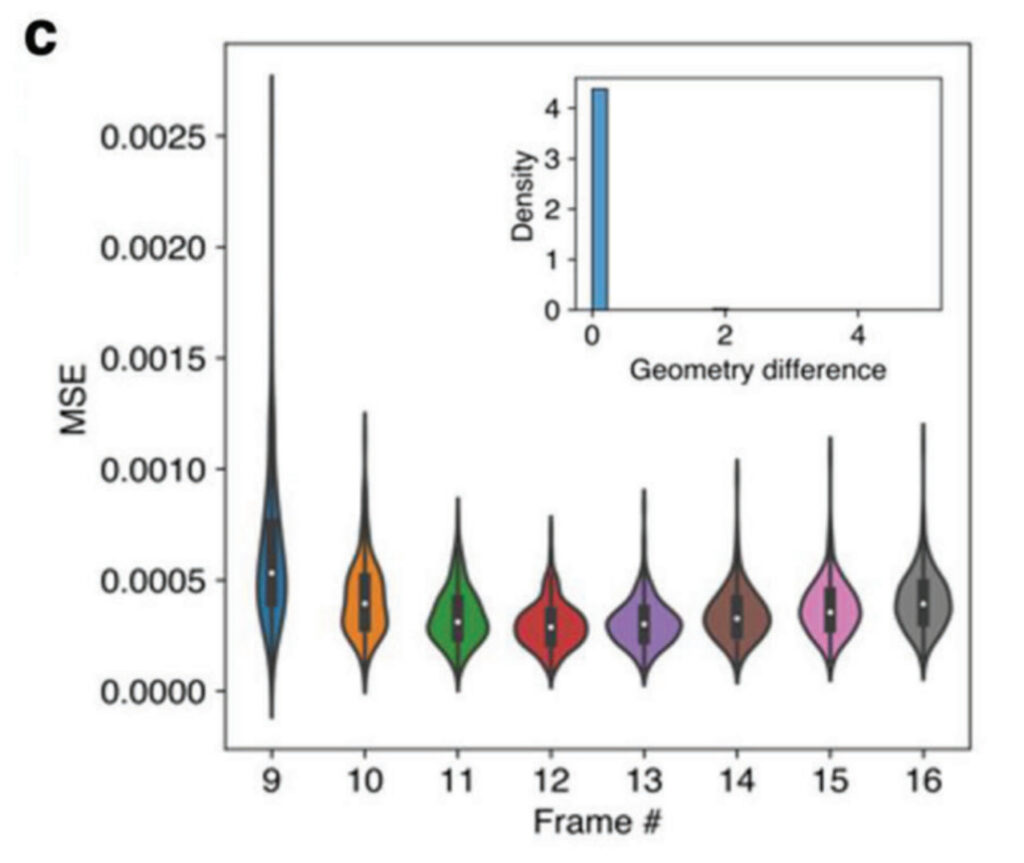
Figure 4 : Distribution des erreurs
Grâce au cadre de champ prédit, les champs mécaniques 3D complets peuvent être utilisés pour déterminer la microstructure du matériau composite. Comme dans le cas 2D, les chercheurs ont utilisé un modèle CNN pour faire des prédictions. Comme le montre la sous-image en haut à droite de la figure 4,La différence de géométrie est de 0. En combinant le modèle ViViT amélioré avec le modèle CNN, une identification précise des microstructures 3D internes peut être obtenue, la plupart des formes géométriques étant parfaitement prédites.
Laboratoire LAMM : Lier la structure et la fonction des matériaux
La recherche a été réalisée conjointement par l'étudiant chinois au doctorat du MIT, Zhenze Yang, et le professeur Markus Buehler.Zhenze Yang est doctorant au MIT et travaille au Laboratoire de mécanique atomique et moléculaire du MIT (LAMM). Ses intérêts de recherche incluent la combinaison de techniques d'apprentissage automatique et d'apprentissage profond avec des méthodes de simulation multi-échelles pour accélérer le calcul des performances et la conception de divers matériaux tels que les composites, les nanomatériaux et les biomatériaux.Avant cela, Yang Zhenze a obtenu une licence en physique de l'Université de l'Académie chinoise des sciences.

Yang Zhenze et le professeur Markus Buehler
Site Web personnel de Yang Zhenze :
Adresse du laboratoire :
http://lamm.mit.edu/
L'auteur correspondant, Markus Buehler, est chercheur principal au LAMM. Markus Buehler est un chercheur universitaire très cité avec plus de 450 publications en science des matériaux computationnels, biomatériaux et nanotechnologie.L’un de ses objectifs est d’utiliser la musique et la conception sonore, combinées à l’intelligence artificielle, pour simuler, optimiser et créer de nouvelles formes de matière autonome à partir de zéro de manière abstraite, à travers les échelles (par exemple, du nano au macro) et les espèces (par exemple, des humains aux araignées).
LAMM se consacre au développement d'un nouveau paradigme pour la conception de matériaux à partir de l'échelle moléculaire. En combinant des concepts d'ingénierie structurelle, de science des matériaux et de biologie, LAMM relie les structures chimiques fondamentales à l'échelle atomique à l'échelle fonctionnelle en comprenant comment les biomatériaux forment des structures hiérarchiques pour obtenir des propriétés mécaniques supérieures.Mélanger les concepts de structure et de fonction.
Liens de référence :
[1] https://zhuanlan.zhihu.com/p/632154023
[2]https://scitechdaily.com/mits-ai-system-reveals-internal-structure-of-materials-from-surface-observations/?expand_article=1
[3]https://professional.mit.edu/programs/faculty-profiles/markus-j-buehler
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~








