Command Palette
Search for a command to run...
L'Université Columbia Lance Une Version Améliorée Du Réseau Neuronal Org-NN Pour Prédire Avec Précision Les Précipitations Extrêmes

Sommaire en un coup d'œil:Alors que les changements environnementaux s’intensifient, des phénomènes météorologiques extrêmes se sont produits fréquemment dans le monde entier ces dernières années. Prédire avec précision l’intensité des précipitations est très important pour les humains et pour l’environnement naturel. Le modèle traditionnel prédit les précipitations avec une faible variance, tend à prédire les pluies légères et sous-estime les précipitations extrêmes.
Mots-clés: Réseaux neuronaux d'apprentissage implicite pour les conditions météorologiques extrêmes
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~
Touchée par le typhon Dusurui, Pékin a connu de fortes pluies pendant plusieurs jours consécutifs depuis le 29 juillet, certaines zones connaissant des pluies extrêmement fortes. Des pluies extrêmement fortes ont provoqué une inondation à grande échelle dans le bassin de la rivière Haihe, et de graves inondations se sont produites à Mentougou, Zhuozhou et dans d'autres endroits.
Selon un rapport de CCTV.com du 31 juillet, au cours de ces fortes pluies, Pékin a drainé plus de 10 millions de mètres cubes d'eau, ce qui équivaut à drainer environ cinq lacs de Kunming dans le Palais d'été.Une prévision opportune, précise et efficace des précipitations extrêmes peut minimiser les pertes et réduire les pertes causées par les catastrophes météorologiques.
La paramétrisation traditionnelle des modèles climatiques manque d'informations sur la structure et l'organisation des nuages à l'échelle sous-grille, ce qui affecte l'intensité et le caractère aléatoire des précipitations à une résolution grossière, ce qui entraîne l'incapacité de prédire avec précision les conditions de précipitations extrêmes.Le laboratoire LEAP de l'Université de Columbia a utilisé des simulations d'analyse des tempêtes mondiales et l'apprentissage automatique pour créer un nouvel algorithme qui résout le problème des informations manquantes et fournit une méthode de prévision plus précise.
Actuellement, la recherche a été publiée dans PNAS, et le titre de l'article est « L'apprentissage implicite de l'organisation convective explique la stochasticité des précipitations ».

L'article a été publié dans PNAS
Adresse de l'article : https://www.pnas.org/doi/10.1073/pnas.2216158120#abstract
Préparation : 10 jours de données météo + 2 réseaux neuronaux
Données et traitement
L'ensemble de données utilisé par l'équipe expérimentale estDYAMOND (Dynamique de la circulation générale atmosphérique modélisée sur des domaines non hydrostatiques) Une partie de la dynamique de circulation atmosphérique simulée lors du projet de comparaison de phase II. Ce projet a simulé 40 jours d’hiver dans l’hémisphère nord. Les expérimentateurs ont utilisé les 10 premiers jours comme période de démarrage du modèle et ont sélectionné au hasard 10 jours au cours des 30 jours suivants comme ensemble d’entraînement.
Les chercheurs ont sélectionné des données appropriées.Ces données sont grossièrement granulaires et divisées en sous-domaines avec des grilles égales ou comparables à la taille du GCM.
Ensuite, afin de fournir des ensembles de données de formation, de validation et de test, l’équipe a divisé les 10 jours en 6 jours, 2 jours et 2 jours pour la formation, la validation et les tests, respectivement.Seuls les échantillons dont les précipitations sont supérieures au seuil (0,05 mm/h) sont conservés afin de pouvoir se concentrer uniquement sur l'intensité des précipitations plutôt que sur la cause des précipitations. . Finalement, le nombre total d’échantillons était de 108.
Architecture des réseaux neuronaux
Dans leurs expériences, les chercheurs ont utilisé deux réseaux neuronaux :Le modèle traditionnel Baseline-NN (réseau neuronal de base) et le nouveau modèle Org-NN proposé .
Baseline-NN est un réseau feed-forward entièrement connecté avec un taux d'apprentissage ajusté par génération.En tant que modèle traditionnel, Baseline-NN ne peut accéder qu'à des variables à grande échelle et prédire les précipitations.
Org-NN contient un autoencodeur, dont la partie encodeur comprend trois couches convolutives unidimensionnelles et deux couches entièrement connectées.. L'entrée de l'encodeur est une anomalie PW (eau précipitable) haute résolution de taille 32 x 32, et la sortie est une variable org. La dimension org est un hyperparamètre du réseau, que les chercheurs ont fixé à 4. Le décodeur reçoit la variable org et reconstruit le champ haute résolution d'origine, qui est l'inverse de la structure de l'encodeur. La partie réseau neuronal d'Org-NN est similaire à Baseline-NN, avec l'ajout d'une variable latente organisationnelle (org) comme entrée. .
Les deux ont été implémentés à l'aide de TensorFlow version 2.9 et les hyperparamètres ont été réglés à l'aide de la bibliothèque d'optimisation Sherpa.
Résultats expérimentaux
L’équipe expérimentale a pré-entraîné deux modèles.Pour évaluer les performances prédictives du réseau neuronal, les chercheurs ont choisi R2, une mesure couramment utilisée pour quantifier les performances des modèles de régression.. La formule de calcul est la suivante :
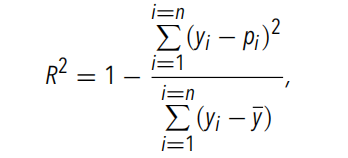
Modèle traditionnel de référence-NN
L’équipe expérimentale a d’abord utilisé Baseline-NN.La figure ci-dessous montre la prévisibilité des précipitations lors de l'utilisation de PW, SST, qv2m et T2m à gros grains comme entrée. Parmi eux, qv2m et T2m sont utilisés pour fournir des informations sur l'état de la couche limite à Baseline-NN. L'équipe expérimentale a divisé les PW à gros grains en groupes et a fait la moyenne des valeurs prédites et réelles des précipitations à gros grains dans chaque groupe.La variance des valeurs de précipitations à gros grains au sein de chaque groupe a également été calculée..
PW: eau précipitable
SST:température de surface de la mer, température de surface de la mer
qv2: humidité spécifique proche de la surface
T2m:Humidité de l'air à 2 m près de la surface, température de surface
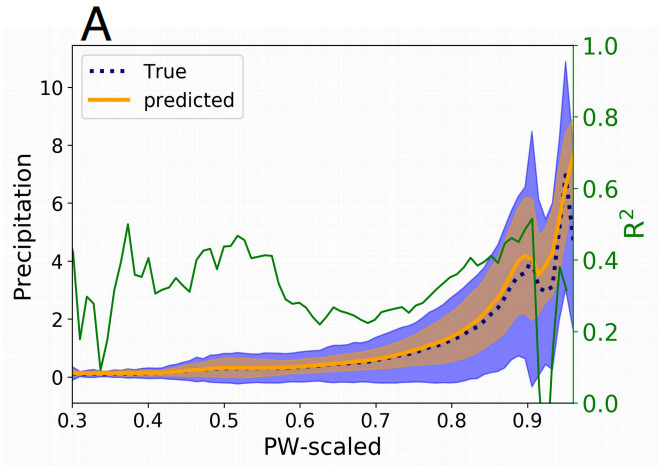
Figure 1 : Valeur moyenne des précipitations à gros grains sur la cuve PW
ligne pointillée:La vraie moyenne des précipitations
Ligne orange: Moyenne des précipitations prévues
Ligne verte: R2 calculé dans chaque bac PW
Ombre: Variance au sein de chaque groupe
Baseline-NN récupère avec précision les comportements clés de la moyenne des précipitations (c'est-à-dire la moyenne des groupes) dans des conditions de PW, ainsi que les transitions rapides se produisant à proximité du point critique. mais,L'équipe expérimentale a constaté qu'elle ne pouvait pas expliquer la variabilité des précipitations observée dans les simulations de tempêtes mondiales., et ses performances (mesurées par la valeur R2 de tous les échantillons) sont d'environ 0,45. Une faible valeur R2 indique queBien qu’une certaine variabilité des précipitations puisse être capturée, aucune relation forte entre l’apport et les précipitations ne peut être trouvée., et la valeur R2 calculée pour chaque compartiment PW ne dépassait pas 0,5.
Dans le même temps, l’équipe expérimentale a également comparé la fonction de densité de probabilité des précipitations prédites par Baseline-NN avec les précipitations réelles.Cela montre que le modèle ne peut pas prédire la queue de distribution des précipitations, c’est-à-dire qu’il ne peut pas prédire les précipitations extrêmes..
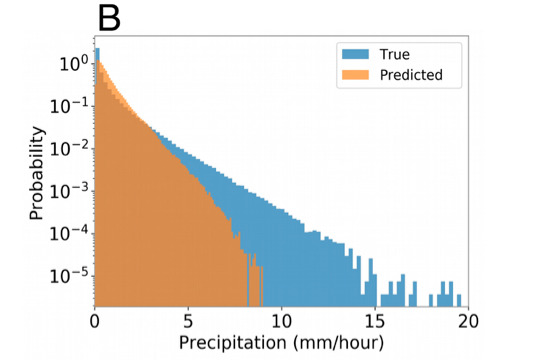
Figure 2 : Diagramme schématique de la fonction de densité de probabilité des précipitations
Partie bleue:Fonction de densité de probabilité des précipitations réelles
Partie orange:Selon la fonction de densité de probabilité des précipitations prévues
Les chercheurs ont également utilisé la couverture nuageuse totale à un niveau grossier comme l’une des entrées du réseau neuronal pour tester davantage le Baseline-NN.. La couverture nuageuse totale est une variable paramétrée dans les modèles climatiques et n'a pas de relation directe avec les précipitations. Son utilisation comme entrée dans le réseau neuronal peut donc fournir des indices sur la condensation, qui sont directement utilisés dans la paramétrisation des précipitations. En réalité, cela n’améliore que légèrement les prévisions, mais cela souligne que la couverture nuageuse moyenne ne fournit pas d’informations pertinentes pour prédire avec précision les précipitations. En outre, l’équipe expérimentale a mené des analyses plus approfondies.Il a été confirmé que CAPE et CIN ne peuvent pas être utilisés comme prédicteurs et ne peuvent pas améliorer les résultats de prédiction..
Figure 3 : Fonction de densité de probabilité de précipitations
Partie bleue: Fonction de densité de probabilité de précipitations réelles
Partie orange: Prédire la fonction de densité de probabilité des précipitations
un: l'entrée est [PW, SST, qv2m, T2m, flux de chaleur sensible, flux de chaleur latente]
b: l'entrée est [PW, SST, qv2m, T2m, couverture nuageuse totale]
c: L'entrée est [PW, SST, qv2m, T2m, CAPE, CIN]
La conclusion est que Baseline-NN a une faible capacité à prédire avec précision les précipitations et la variabilité..
Nouveau modèle Org-NN
L’équipe expérimentale a ensuite renversé la méthode traditionnelle et utilisé Org-NN pour la prédiction. Étant donné qu'Org-NN contient un autoencodeur, il peut recevoir directement un retour de la fonction objective du réseau neuronal via la rétropropagation.L'autoencodeur pourra ainsi extraire passivement des informations pertinentes pour améliorer les prévisions de précipitations..
La figure ci-dessous montre les résultats de prévision des précipitations d'Org-NN avec des variables à gros grains et org comme entrée. Par rapport à Baseline-NN, Org-NN a fait des progrès significatifs. Lorsqu'il est calculé sur tous les points de données, le R2 prédit augmente à 0,9. Pour chaque intervalle de PW, à l’exception de l’intervalle avec des précipitations plus faibles, les valeurs R2 calculées sont presque proches de 0,80.
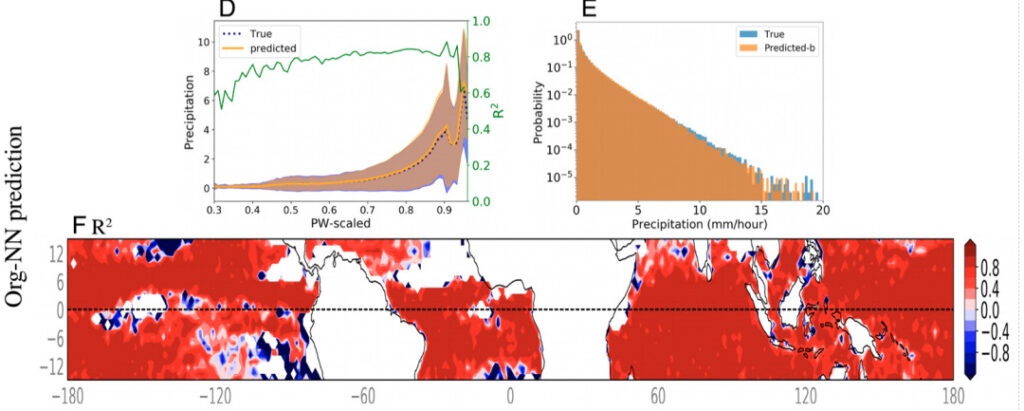
Figure 4 : Résultats de la prédiction Org-NN
D:Valeur moyenne des précipitations à gros grains sur la cuve PW
E:Diagramme schématique de la fonction de densité de probabilité des précipitations
F: Valeurs R2 calculées sur le pas de temps pour chaque emplacement de latitude et de longitude dans la figure D. Les zones blanches de la figure indiquent des précipitations inférieures à 0,05 mm/h et sont exclues de l'entrée du modèle. À l’exception des zones proches des points qui n’ont pas atteint le seuil de précipitations, les valeurs R2 de Org-NN étaient significativement supérieures à 0,8 dans la plupart des zones.
L'équipe expérimentale a comparé les fonctions de densité de probabilité des précipitations réelles d'Org-NN et des modèles de précipitations à haute résolution pour quantifier davantage les performances d'Org-NN. Il s’avère que Org-NN capture entièrement la fonction de densité de probabilité, y compris la queue de sa distribution, qui correspond aux précipitations extrêmes.Cela montre qu’Org-NN peut prédire avec précision les précipitations extrêmes..
Les résultats obtenus par l’équipe expérimentale ont montré que les prévisions de précipitations étaient considérablement améliorées en incorporant l’org dans l’entrée. Cela suggère que la structure à l’échelle sous-maille peut être une information manquante importante dans les paramétrisations de convection et de précipitations dans les modèles climatiques actuels..
Résumé du processus expérimental
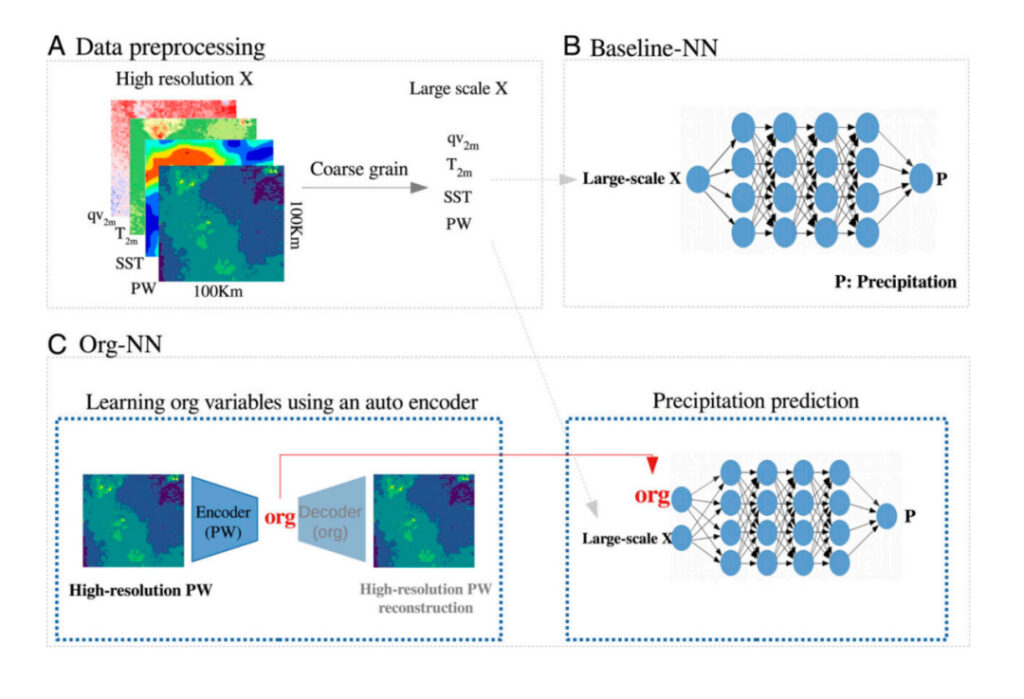
Figure 5 : Aperçu du processus expérimental
UNProcessus de traitement des données : données à haute résolution à gros grains
B:Référence-NN : ce réseau reçoit des variables à grande échelle (telles que SST et PW) en entrée et prédit les précipitations à grande échelle.
C:Org-NN : La figure de gauche montre l'autoencodeur, qui reçoit le PW haute résolution en entrée et le reconstruit après avoir traversé le goulot d'étranglement. La figure de droite montre un réseau neuronal prédisant les précipitations à grande échelle.
Les modèles climatiques traditionnels sont sur le point de changer
L'équipe de cette expérience venait de Apprendre la Terre avec l'intelligence artificielle et la physique (LEAP), un centre scientifique et technologique NSF lancé par l'Université de Columbia en 2021,Sa principale stratégie de recherche consiste à combiner la modélisation physique et l’apprentissage automatique, en utilisant l’expertise en science du climat et en simulation climatique avec des algorithmes d’apprentissage automatique de pointe pour améliorer les prévisions climatiques à court terme.. Cela profitera au développement de la science du climat et de la science des données.

Brève présentation de certains membres du LEAP Lab
|Site officiel du laboratoire : https://leap.columbia.edu
Les chercheurs appliquent actuellement leur approche d’apprentissage automatique aux modèles climatiques.Améliorer les prévisions d’intensité et de variabilité des précipitations et permettre aux scientifiques de prédire avec plus de précision les changements dans le cycle de l’eau et les conditions météorologiques extrêmes dans le contexte du réchauffement climatique.
Parallèlement, cette étude ouvre également de nouvelles pistes de recherche, comme l’exploration de la possibilité que les précipitations aient un effet mémoire, c’est-à-dire que l’atmosphère conserve des informations sur les conditions météorologiques récentes, ce qui affecte à son tour les conditions atmosphériques ultérieures. La nouvelle méthode pourrait avoir de vastes applications au-delà des simulations de précipitations, comme de meilleures simulations des calottes glaciaires et des surfaces océaniques.
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~








