Command Palette
Search for a command to run...
Pour Prévenir Le Vieillissement Cellulaire Et Éviter Les Maladies Liées À l'âge, l'Université d'Édimbourg a Publié Trois « Prescriptions Anti-âge IA » Pour Les Cellules
Contenu en un coup d'œil :Des études ont montré que la sénescence cellulaire est étroitement liée à des maladies telles que le cancer, le diabète de type 2, l’arthrose et les infections virales. Bien que les médicaments destinés à éliminer les cellules sénescentes soient progressivement devenus un sujet de recherche et de développement. Cependant, en raison du manque de cibles moléculaires bien caractérisées, peu de composés anti-âge (sénolytiques) ont été découverts. Récemment, un résultat de recherche a été publié dans la revue internationale Nature Communications, dans lequel les chercheurs ont découvert trois nouveaux types de sénolytiques.
Mots-clés:Apprentissage automatique Senolytics XGBoost
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~
Depuis l’Antiquité, les hommes recherchent l’immortalité. Ce qui est surprenant, c’est que ces dernières années, des sujets tels que l’anti-âge et la longévité passent du monde mystérieux et illusoire des produits de santé au monde médical et de la santé reconnu par le public. On pense généralement que le vieillissement est un processus au cours duquel les fonctions du corps s’affaiblissent lentement. Ce processus est irréversible, les humains ne peuvent donc que laisser la nature suivre son cours et tout abandonner au destin. Cependant, ce que beaucoup de gens ne comprennent pas, c’est queDès 2018, l’Organisation mondiale de la santé a déclaré que le vieillissement était une maladie traitable dans le Code international des maladies.
Dans le cadre de la définition large du vieillissement, la sénescence cellulaire est l’une des directions de recherche les plus en vogue des scientifiques ces derniers temps. La sénescence cellulaire est un phénomène caractérisé par l’arrêt de la division cellulaire.Normalement, le système immunitaire humain peut éliminer efficacement les cellules sénescentes, mais à mesure que nous vieillissons, cette fonction d’élimination s’affaiblit progressivement. En plus de provoquer une détérioration de la vision et une mobilité limitée, il est également très susceptible de provoquer le cancer, la maladie d’Alzheimer et d’autres maladies.
En 2015, le Dr James L. Kirkland et d’autres chercheurs de la Mayo Clinic ont découvert le premier médicament anti-âge (Senolytics) capable d’éliminer les cellules sénescentes.Les sénolytiques font référence à de petits composés moléculaires qui induisent sélectivement la mort des cellules sénescentes. Son nom dérive de Sénescence (vieillissement) et Lytique (destruction).Dans la dernière étude, l'Université d'Édimbourg et l'Université de Cantabrie ont utilisé l'apprentissage automatique pour découvrir trois sénolytiques - la ginkgétine, la périplocine et l'oléandrine, et ont vérifié leurs effets anti-âge dans les lignées cellulaires humaines.La recherche a été publiée dans la revue Nature Communications sous le titre « Découverte de sénolytiques à l’aide de l’apprentissage automatique ».

Figure 1 : Ce résultat de recherche a été publié dans Nature Communications
Adresse du document :
https://www.nature.com/articles/s41467-023-39120-1#Sec2
Procédures expérimentales
Ensemble de données
Les ensembles de données expérimentales proviennent de multiples canaux, notamment de publications universitaires et de brevets commerciaux.Tout d’abord, les chercheurs ont extrait 58 sénolytiques connus, puis ont extrait une variété de non-sénolytiques à partir de deux bibliothèques chimiques existantes, LOPAC-1280 et Prestwick FDA-approved-1280. L'ensemble de données combine les deux.Au total, 2 523 composés ont été inclus, dont 2,3% étaient des Senolytics.
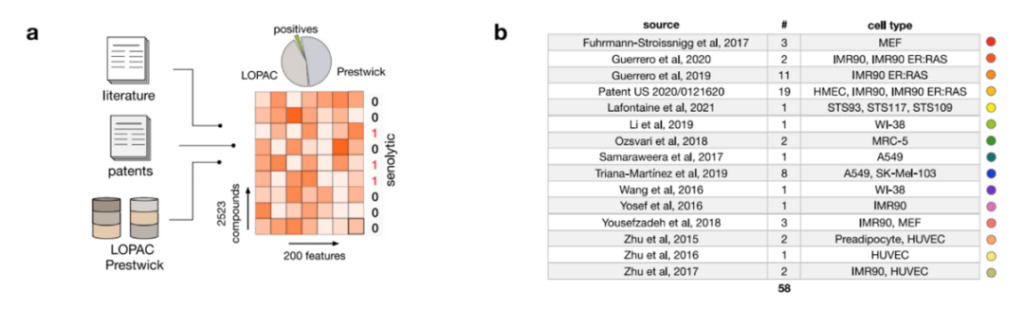
Figure 2 : Composés utilisés pour entraîner des modèles d'apprentissage automatique
un:Les données de formation proviennent de plusieurs sources.
b:58 sources de sénolytiques utilisées pour la formation, y compris le nombre de composés et de lignées cellulaires pour chaque source.
Formation de modèle
Les chercheurs ont utilisé l’ensemble de données ci-dessus pour former un modèle permettant d’identifier les composés présentant des caractéristiques sénolytiques (positives). Tout d’abord, les chercheurs ont effectué une sélection de caractéristiques sur l’ensemble de données.Au cours de ce processus, ils ont utilisé le modèle de forêt aléatoire (RF) pour calculer la réduction moyenne de l’indice de Gini de chaque caractéristique et ont sélectionné les 165 caractéristiques les plus importantes, réduisant ainsi le nombre de caractéristiques et la complexité du modèle.
- L'indice de Gini mesure le degré de confusion des échantillons dans un nœud. Plus la valeur est faible, plus les échantillons du nœud sont purs.
Deuxièmement, les chercheurs ont développé plusieurs modèles de classification binaire des sénolytiques (identifiant les sénolytiques ou les non-sénolytiques) en utilisant les 165 caractéristiques les plus importantes et divers échantillons de données provenant de l’ensemble de données complet.Pour comparer les modèles et exploiter pleinement le nombre limité d'échantillons Senolytics, les chercheurs ont effectué une validation croisée en 5 étapes sur l'ensemble de données et ont évalué les modèles à l'aide de trois mesures de performance : précision, rappel et score F1.
Au départ, les chercheurs se sont concentrés sur les machines à vecteurs de support (SVM) et les modèles RF, mais les expériences ont montré que leurs performances n’étaient pas satisfaisantes.Ils ont également évalué d’autres modèles de complexité différente, notamment des régresseurs logistiques, des classificateurs bayésiens naïfs et SMOTE, mais les résultats ont montré que les performances de ces modèles n’étaient pas aussi bonnes que celles des modèles SVM et RF.
Les chercheurs ont donc développé un modèle XGBoost basé sur les performances RF.Améliorez la puissance prédictive en formant de manière itérative des modèles d’arbres de décision.Comme le montre la Fig. 3b, le modèle XGBoost a amélioré la précision, le rappel et le score F1, et est le plus performant parmi tous les modèles considérés.
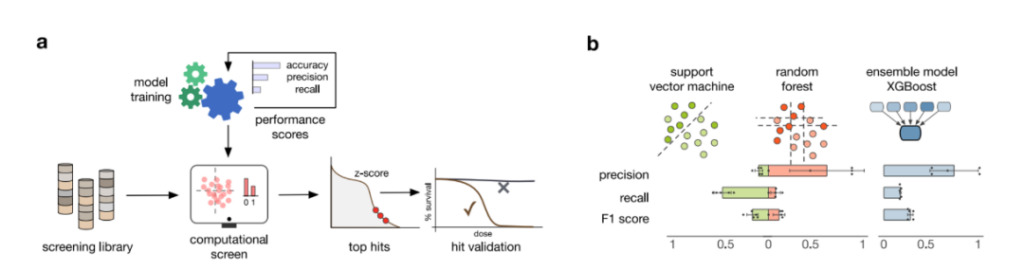
Figure 3 : Formation d'un modèle d'apprentissage automatique
un:Processus de formation de modèles, de criblage de composés et de vérification des résultats, utilisant plusieurs indicateurs de performance pour sélectionner des modèles appropriés.
b:Performance de 3 modèles d'apprentissage automatique. Le graphique à barres montre les mesures de performance moyennes calculées lors de la validation croisée en 5 étapes. Les barres d’erreur représentent un écart type.
L'adresse de cet ensemble de données expérimentales sera synchronisée ultérieurement avec le site officiel d'HyperAI :
https://doi.org/10.5281/zenodo.7870357
Résultats expérimentaux
Dans un premier temps, les chercheurs ont examiné plus de 4 340 composés pour en identifier 21 ayant une activité anti-âge potentielle. Ils ont ensuite testé ces 21 composés.Comme le montre la figure 4, trois d’entre eux ont pour effet d’éliminer les cellules sénescentes : la périplocine et l’oléandrine (deux glycosides cardiaques dont la capacité à éliminer les cellules sénescentes n’a pas encore été confirmée) et la ginkgétine (un composé biflavonoïde naturel non toxique).
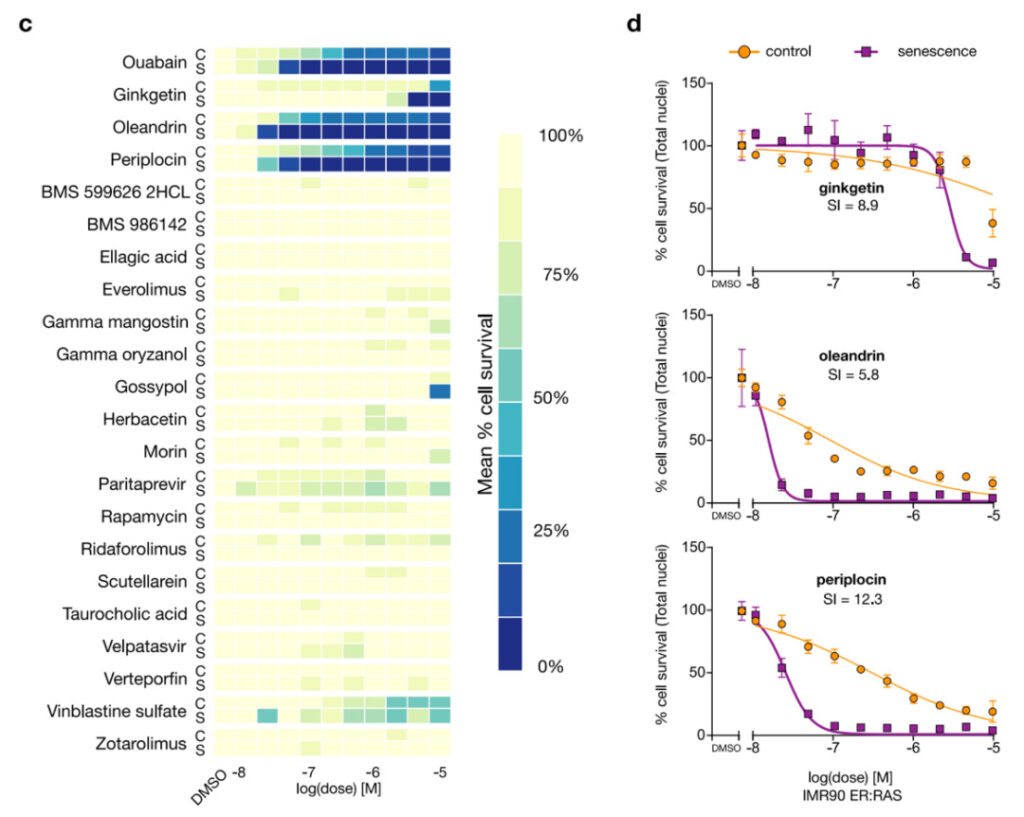
Figure 4 : Périplocine, oléandrine et ginkgétine A pour effet d'éliminer les cellules sénescentes
c:Vérification expérimentale. Trois des 21 composés ont montré une activité anti-âge : la ginkgétine, l’oléandrine et la périplocine ; la carte thermique montre la moyenne de n = 3 répliques. Sur la figure, l'ouabaïne est un sénolytique connu.
d:Courbes dose-réponse de 3 composés anti-âge nouvellement découverts. SI est l'indice anti-âge.
De plus, au cours des expériences ci-dessus,Les chercheurs ont également découvert que l’oléandrine récemment découverte avait des propriétés anti-âge plus fortes que l’ouabaïne, en particulier à de faibles concentrations.Les chercheurs ont donc comparé les activités anti-âge de la périplocine, de l’oléandrine et de l’ouabaïne à une faible concentration de 10 nM.
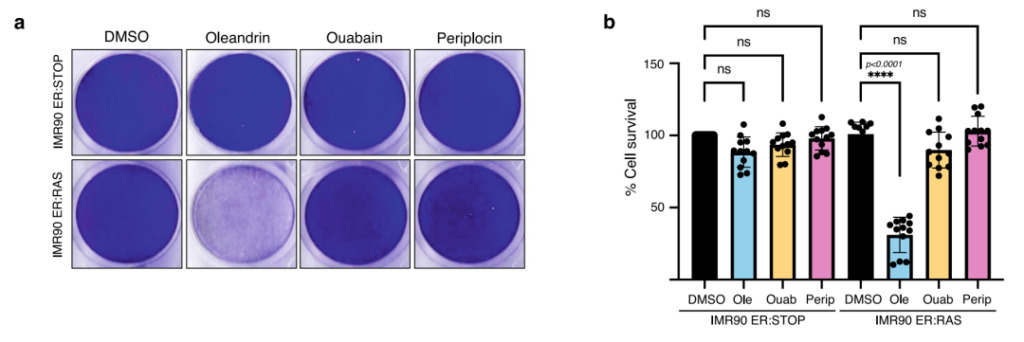
Figure 5 : Périplocine, oléandrine et périplocine Comparaison des performances anti-âge à faibles concentrations
un:La figure montre des boîtes de culture tissulaire d'IMR90 ER:RAS (cellules sénescentes) et d'IMR90 ER:STOP (témoin) cultivées en présence de 100 nM de 4OHT. Au cours des 72 heures suivantes, les cellules ont été traitées avec 10 nM d'oléandrine, d'ouabaïne et de périplocine, ainsi que du DMSO (témoin).
b:La viabilité cellulaire a été évaluée par analyse quantitative.
Comme le montre la figure 5b, de faibles concentrations d'Ouabaïne et de Periplocine n'ont montré aucune cytotoxicité significative dans IMR90-ER:STOP et IMR90-ER:RAS.Après un traitement à l'oléandrine, le taux de survie des cellules sénescentes dans IMR90-ER:RAS a été significativement diminué, indiquant que l'oléandrine a une activité anti-âge plus forte à des concentrations de médicament plus faibles.Sur la base des résultats expérimentaux ci-dessus,L'apprentissage automatique peut trouver avec succès des composés anti-âge, et a également découvert l'oléandrine, qui a des effets anti-âge plus forts que les composés anti-âge existants.
Découverte de médicaments basée sur l'IA
L’IA joue un rôle important à chaque étape du développement de nouveaux médicaments. Actuellement, la recherche se concentre sur la découverte de médicaments et les étapes de développement préclinique. Cette étude démontre le potentiel de l’IA dans le développement de médicaments, en particulier lorsqu’il s’agit de lutter contre des maladies aux structures biologiques complexes ou à peu de cibles moléculaires connues. L'auteur Diego Oyarzún souligne :« L’IA est très efficace pour nous aider à découvrir de nouveaux médicaments candidats, en particulier dans les premières étapes de la découverte de médicaments. »
Vanessa Smer-Barreto, première auteure de l’étude, a souligné l’importance d’une étroite collaboration entre les data scientists, les chimistes et les biologistes. Elle a dit :« Ce travail est né d’une étroite collaboration entre des scientifiques des données, des chimistes et des biologistes.Nous avons profité de cette collaboration interdisciplinaire pour construire un modèle robuste et économiser les coûts de sélection en utilisant uniquement des données publiées pour la formation du modèle."Ce modèle collaboratif offre de nouvelles opportunités pour accélérer l’application de l’IA et devrait stimuler l’innovation et le développement dans la recherche et le développement de médicaments.
À l’heure actuelle, bien que l’IA ait réalisé des percées dans la recherche et le développement de nouveaux médicaments, elle est toujours confrontée à certains défis, tels que la qualité et la fiabilité des données, l’interprétabilité des algorithmes et la capacité de généralisation des modèles.Avec les progrès continus de la technologie et l’augmentation des ressources de données, les perspectives d’application de l’IA dans la recherche et le développement de médicaments sont encore très larges.En renforçant le partage des données et la collaboration interdisciplinaire, nous pouvons mieux utiliser les avantages de l’IA, accélérer la découverte et le développement de nouveaux médicaments et apporter des avantages à la santé humaine.
Articles de référence :
[1] http://zixun.69jk.cn/shwx/79532.html
[2]https://en.wikipedia.org/wiki/Cellular_senescence#Caractéristiques_des_cellules_senescentes
[3]https://newatlas.com/medical/machine-learning-algorithm-identifies-natural-anti-aging-chemicals/
[4]https://www.sohu.com/a/673349496_121124375
[5]https://www.ed.ac.uk/institute-genetics-cancer/news-and-events/news-2023/ai-algorithms-find-drugs-that-could-combat-ageing
[6]http://www.stcn.com/article/detail/904319.html
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~








