Command Palette
Search for a command to run...
Simulation Informatique : Compilation d'IA DSA Basée Sur TVM

Bonjour à tous, je suis Dan Xiaoqiang de Shim Computing. Aujourd'hui, trois collègues et moi partagerons avec vous comment soutenir NPU sur TVM.
Le problème essentiel que résout le compilateur DSA est que différents modèles doivent être déployés sur le matériel, en utilisant des méthodes d'optimisation à différents niveaux abstraits pour que le modèle remplisse la puce autant que possible, c'est-à-dire pour compresser les bulles. En ce qui concerne la manière de planifier, le triangle de planification décrit par Halide est l’essence du problème.
Quel est le problème principal que résout le compilateur DSA ? Tout d’abord, nous faisons abstraction d’une architecture DSA. Comme le montre la figure, Habana, Ascend et IPU sont tous des instanciations de cette architecture abstraite. En général, chaque cœur dispose d’unités de calcul vectorielles, scalaires et tensorielles. Du point de vue des opérations d'instruction et de la granularité des données, de nombreux DSA peuvent avoir tendance à utiliser des instructions à granularité relativement grossière, telles que des instructions vectorielles et tensorielles bidimensionnelles et tridimensionnelles. Il existe également de nombreux matériels qui utilisent des instructions à granularité fine, telles que SIMD unidimensionnel et VLIW. Certaines des dépendances entre les instructions sont exposées via des interfaces explicites pour le contrôle logiciel, tandis que d'autres sont contrôlées par le matériel lui-même. La mémoire est une mémoire à plusieurs niveaux, principalement une mémoire bloc-notes. Il existe différentes granularités et dimensions de parallélisme, telles que le parallélisme de flux, le parallélisme de cluster, le parallélisme multicœur et le parallélisme de pipeline entre différents composants informatiques.
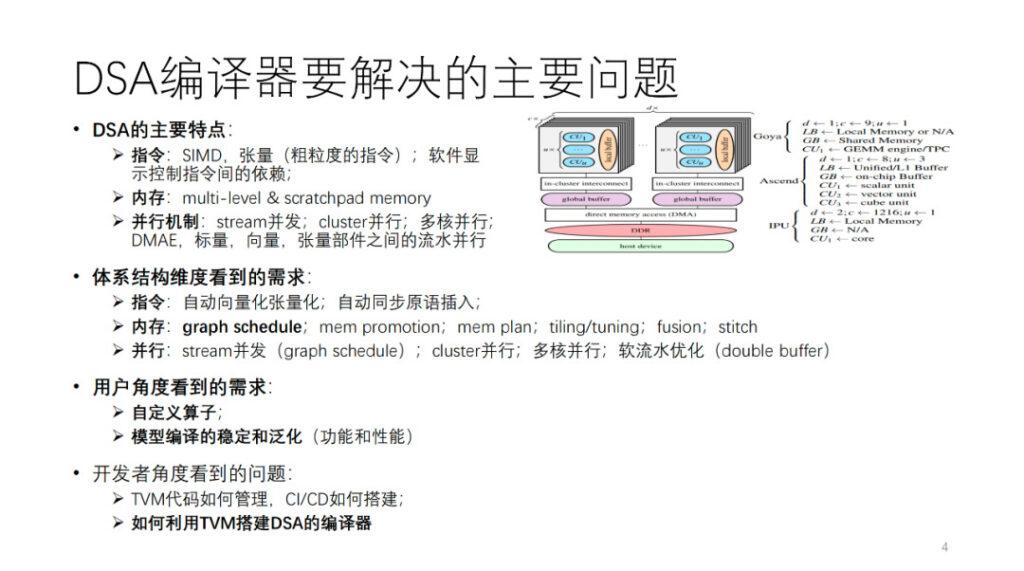
Pour prendre en charge ce type d'architecture, du point de vue des développeurs de compilateurs, différentes exigences sont avancées pour le compilateur AI à partir de plusieurs aspects de l'architecture mentionnée ci-dessus. Nous développerons cette partie plus tard.
Du point de vue de l'utilisateur, il doit tout d'abord y avoir un compilateur stable et généralisé capable de compiler avec succès autant de modèles ou d'opérateurs que possible. De plus, les utilisateurs espèrent que le compilateur pourra fournir une interface programmable pour personnaliser les algorithmes et les opérateurs afin de garantir que certains travaux d’innovation d’algorithmes clés puissent être effectués de manière indépendante. Enfin, des équipes comme la nôtre ou nos concurrents peuvent également se préoccuper de la manière d'utiliser TVM pour construire un compilateur d'IA, comme la manière de gérer les codes TVM auto-développés et open source, comment construire un CI efficace, etc. C'est ce que nous allons partager aujourd'hui. Mon collègue va maintenant parler de la partie optimisation de la compilation.
Wang Chengke de Shim Computing : Processus d'optimisation de la compilation DSA
Cette partie est partagée sur place par Wang Chengke, ingénieur informatique chez Shim.
Tout d’abord, permettez-moi de présenter le processus global de la pratique de compilation de Shim.
En réponse aux caractéristiques architecturales mentionnées ci-dessus, nous avons construit une passe d'optimisation auto-développée basée sur la structure de données TVM et réutilisé TVM pour former une nouvelle implémentation de modèle : tensorturbo.
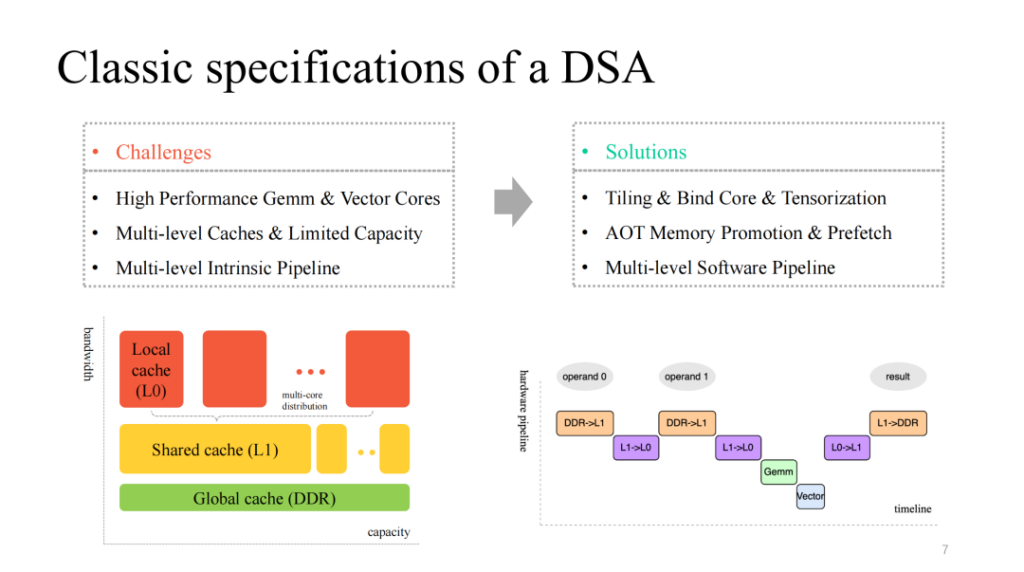
Nous voyons une architecture DSA relativement classique, qui fournit généralement des cœurs de calcul multicœurs de couche matricielle et vectorielle efficaces et personnalisés, dispose d'un mécanisme de cache multicouche pour y correspondre et fournit également des unités d'exécution multimodules qui peuvent s'exécuter en parallèle. En conséquence, nous devons traiter les questions suivantes :
- Divisez les calculs de données, liez efficacement les cœurs et vectorisez efficacement les instructions personnalisées ;
- Gérez finement le cache limité sur puce et pré-récupérez les données en conséquence à différents niveaux de cache ;
- Optimisez le pipeline multi-étapes exécuté par plusieurs modules et efforcez-vous d'obtenir un meilleur rapport d'accélération.
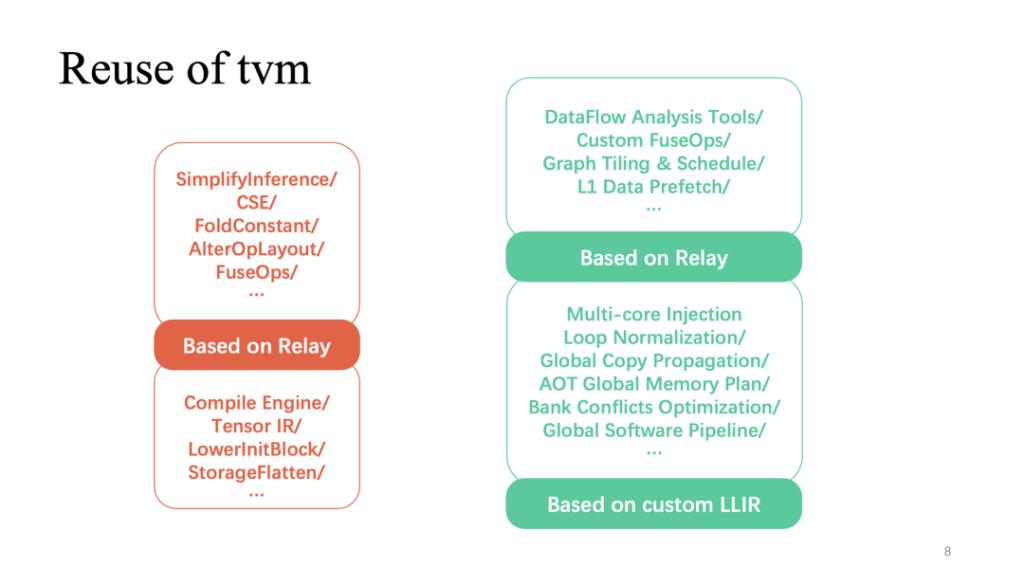
La partie rouge (ci-dessus) montre la partie avec la plus grande réutilisation de TVM dans l'ensemble du processus. Les optimisations liées aux couches les plus courantes implémentées sur le relais peuvent être directement réutilisées. De plus, l'implémentation de l'opérateur basée sur TensorIR et LLIR personnalisé est également largement réutilisée. L'optimisation personnalisée liée aux fonctionnalités matérielles, comme nous venons de le mentionner, nécessite davantage de travail d'auto-recherche.
Commençons par examiner un travail que j’ai développé moi-même sur les calques.
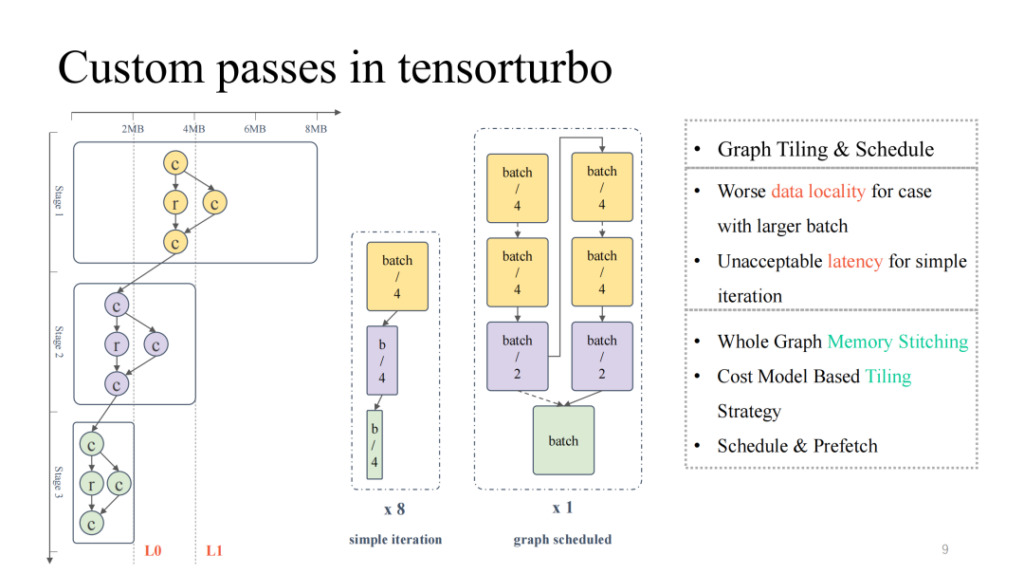
En regardant le diagramme de flux informatique le plus typique à l'extrême gauche, nous pouvons voir que de haut en bas, l'occupation globale du cache et l'occupation informatique diminuent constamment, présentant un état de pyramide inversée. Pour la première moitié, lorsque la taille du modèle est importante, nous devons nous concentrer sur la résolution du problème de résidence du cache sur puce ; tandis que pour la seconde moitié, lorsque la taille du modèle est petite, nous devons faire face au problème de la faible utilisation des unités de calcul. Si vous ajustez simplement la taille du modèle, par exemple en ajustant la taille du lot, une taille de lot plus petite peut entraîner une latence plus faible, mais le débit correspondant sera réduit ; de même, une taille de lot plus importante entraînera une latence plus élevée, mais elle peut améliorer le débit global.
Nous pouvons alors utiliser la planification graphique pour résoudre ce problème. Tout d’abord, une taille de lot relativement importante peut être saisie pour garantir une utilisation relativement élevée du calcul tout au long du processus. Ensuite, une analyse de stockage est effectuée sur l'ensemble du graphique, et une stratégie de segmentation et de planification est ajoutée afin que les résultats de la première moitié du modèle puissent être mieux mis en cache sur la puce, tout en obtenant une meilleure utilisation du cœur de calcul. En pratique, nous pouvons obtenir de bons résultats à la fois en termes de latence et de débit (pour plus de détails, veuillez prêter attention à l’article d’OSDI 23 Shim : Effectively Scheduling Computational Graphs of Deep Neural Networks towards Their Domain-Specific Accelerators, qui sera disponible en juin).
Ce qui suit est un autre travail d’accélération du flux d’eau douce.
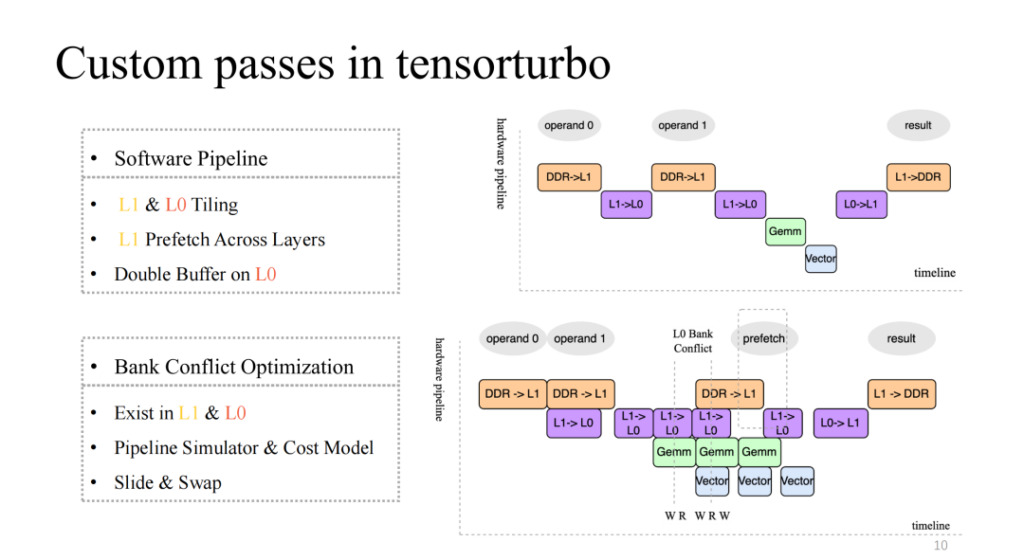
Faites attention à l’image en haut à droite, qui implémente un pipeline à quatre étapes relativement natif, mais ce n’est évidemment pas un pipeline efficace. En règle générale, un pipeline efficace doit être capable de synchroniser et de paralléliser les quatre unités d’exécution après plusieurs itérations. Cela nécessite un certain travail, notamment la segmentation sur L1 et L0, la prélecture des données inter-couches sur L1 et les opérations de double tampon au niveau L0. Grâce à ce travail, nous pouvons obtenir un pipeline avec une accélération relativement élevée comme le montre la figure en bas à droite.
Cela introduira également un nouveau problème. Par exemple, lorsque le nombre de lectures et d'écritures simultanées de plusieurs unités d'exécution dans le cache est supérieur à la concurrence prise en charge par le cache actuel, une concurrence se produit. Ce problème entraînera une baisse exponentielle de l'efficacité de l'accès à la mémoire, ce qui constitue le problème du conflit bancaire. Pour résoudre ce problème, nous allons simuler statiquement le pipeline au moment de la compilation, extraire les objets en conflit et utiliser le modèle de coût pour échanger et décaler les adresses allouées, ce qui peut réduire considérablement l'impact de ce problème.
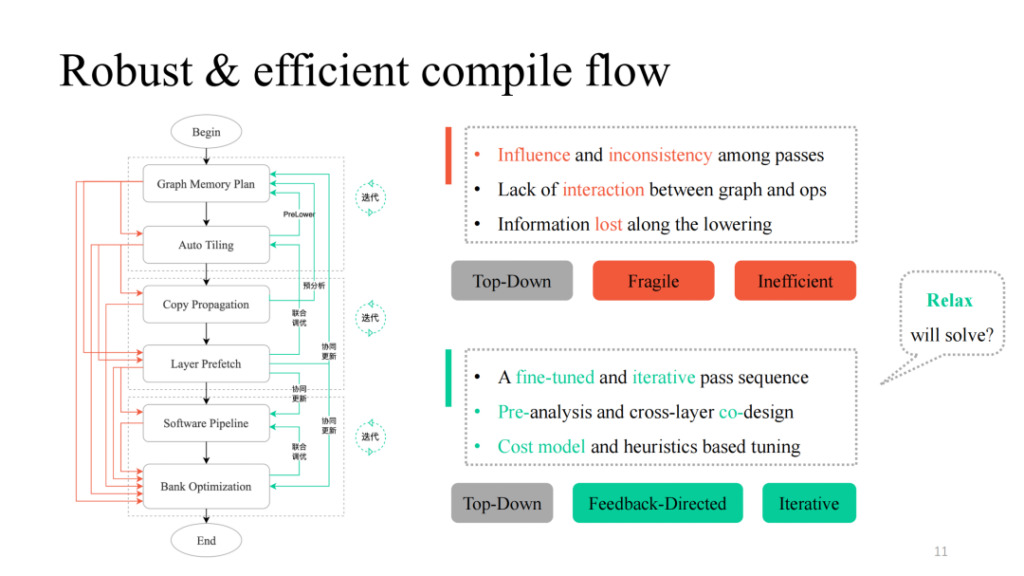
Après avoir réalisé différents passages, nous pouvons les combiner de manière simple de haut en bas. En suivant le processus noir de la figure de gauche, nous pouvons obtenir un pipeline de compilation fonctionnellement réalisable. Cependant, de nombreux problèmes ont été constatés dans la pratique, notamment l'influence mutuelle entre les passes mentionnée par Siyuan, le manque de logique d'interaction et le manque de logique de communication entre les couches et les opérateurs. Vous pouvez voir le processus indiqué par la partie rouge dans la figure de gauche. En pratique, on constate que chaque chemin ou leur combinaison entraînera un échec de compilation. Comment le rendre plus robuste ? Shim fournit un chemin de rétroaction à chaque passage susceptible d'échouer, introduit une logique interactive entre les couches et les opérateurs, effectue des opérations de pré-analyse et de pré-abaissement et introduit certains mécanismes de réglage itératifs dans les parties clés, obtenant finalement une implémentation de pipeline globale avec une généralisation élevée et de fortes capacités de réglage.
Nous avons également remarqué que la transformation de la structure des données et les idées de conception associées dans le travail ci-dessus présentent de nombreuses similitudes avec la conception actuelle de TVM Unity. Nous espérons également que Relax apportera davantage de possibilités.
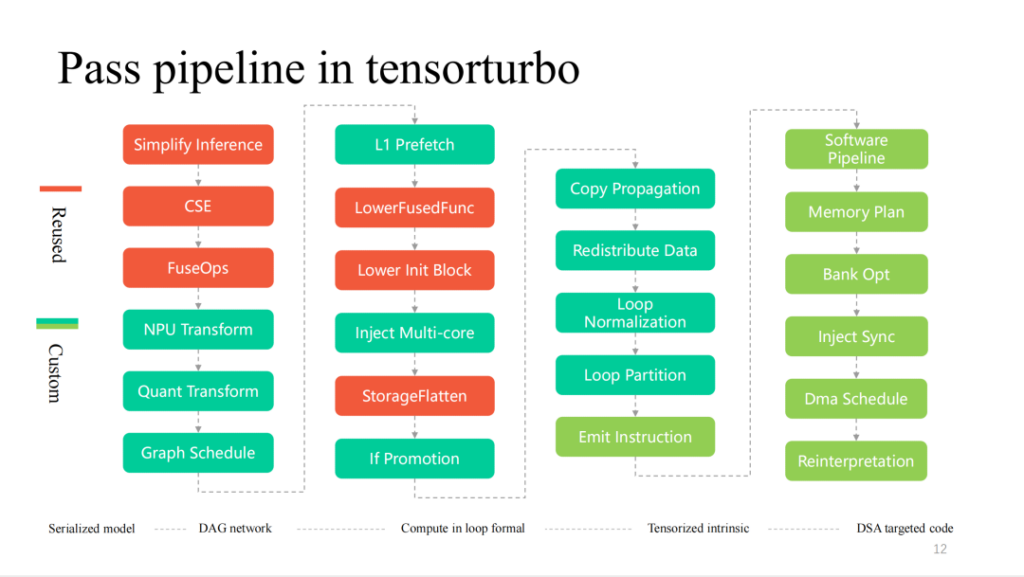
Voici des passages plus détaillés dans le processus de compilation de Xim. De gauche à droite, il s’agit d’un processus de diminution couche par couche. La partie rouge est fortement réutilisée par TVM. Plus les fonctionnalités matérielles sont proches, plus les passes personnalisées seront nombreuses.
Ce qui suit est une introduction détaillée à certains modules.
Sim Computing Liu Fei : Vectorisation et tensorisation de DSA
Cette partie est partagée sur le site par Liu Fei, ingénieur informatique chez Shim.
Ce chapitre présentera le travail de vectorisation de Shim et de quantification tensorielle. Du point de vue de la granularité des instructions, plus la granularité des instructions est grossière, plus elle est proche de l'expression de boucle multicouche du Tensor IR, de sorte que la difficulté de quantification du tenseur vectorisé est plus facile. Au contraire, plus la granularité des instructions est fine, plus la difficulté est grande. Nos instructions NPU prennent en charge les calculs de données tensorielles unidimensionnelles/bidimensionnelles/tridimensionnelles. Shim a également pris en compte le processus de tensorisation TVM natif, mais compte tenu de la capacité limitée de Compute Tensorize à exprimer des expressions complexes, il est difficile de tensoriser des expressions complexes telles que la condition if, et après la vectorisation de la tensorisation, elle ne peut pas être planifiée.
De plus, TensorIR Tensorize était en cours de développement à l'époque et ne pouvait pas répondre aux besoins de développement, donc Shim a fourni son propre ensemble de processus de vectorisation d'instructions, que nous appelons émission d'instructions. Dans le cadre de ce processus, nous prenons en charge environ 120 instructions Tensor, y compris des instructions de différentes dimensions.

Notre flux d’instructions est grossièrement divisé en trois modules :
- Optimisation avant le lancement. La transformation de l’axe du cycle offre davantage de conditions et de possibilités pour l’émission de commandes ;
- Module de transmission de commandes. Analyser les résultats et les informations de la boucle et sélectionner une méthode optimale de génération d'instructions ;
- Le module après l'émission de la commande. Traitez la transmission spécifiée après son échec pour garantir une exécution correcte sur le processeur.
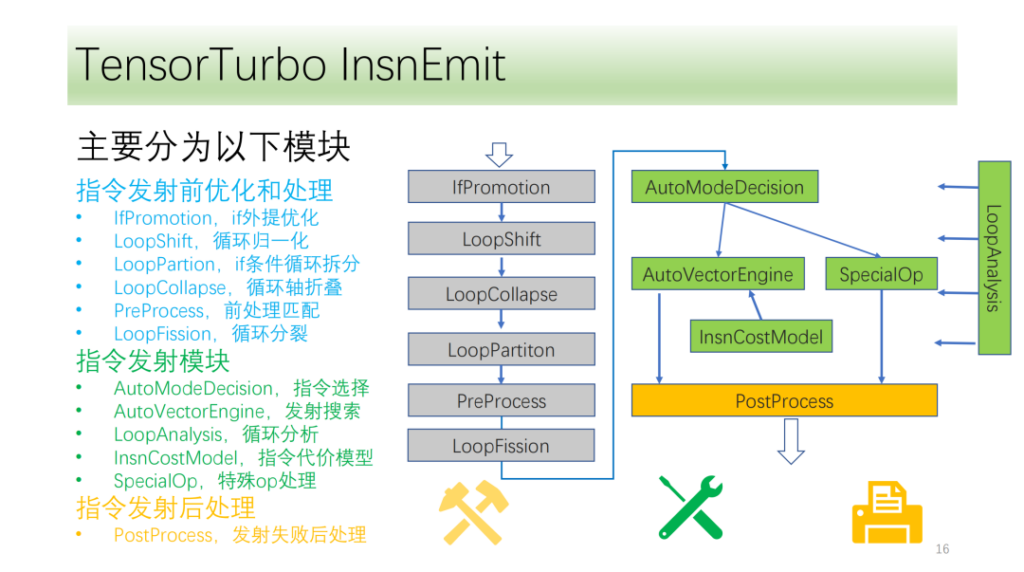
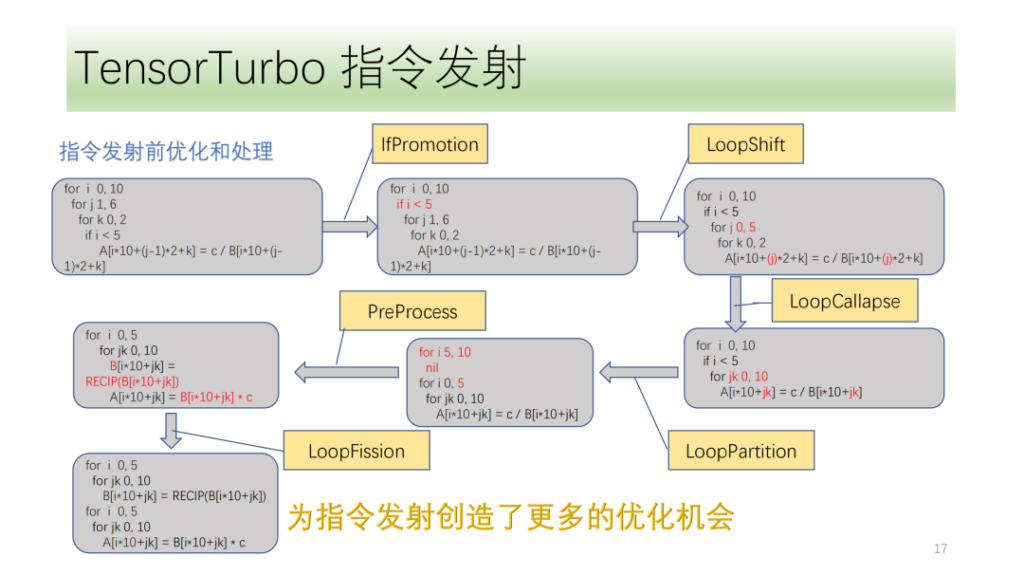
Ci-dessousModule d'optimisation et de traitement avant émission de commande,Ils sont tous composés d'un ensemble de passes d'optimisation, parmi lesquelles IfPromotion consiste à supprimer autant que possible les instructions if qui entravent l'émission des axes de boucle, PreProcess consiste à diviser les opérateurs sans instructions correspondantes, LoopShift consiste à normaliser les limites des axes de boucle, LoopCallapse consiste à fusionner autant que possible les axes de boucle consécutifs, LoopPartition consiste à diviser les axes de boucle liés à if, et LoopFission consiste à diviser plusieurs instructions de stockage dans la boucle.
À partir de cet exemple, nous pouvons voir qu’initialement l’IR ne peut émettre aucune instruction. Après optimisation, il peut enfin émettre deux instructions Tensor et tous les axes de boucle peuvent émettre des instructions.
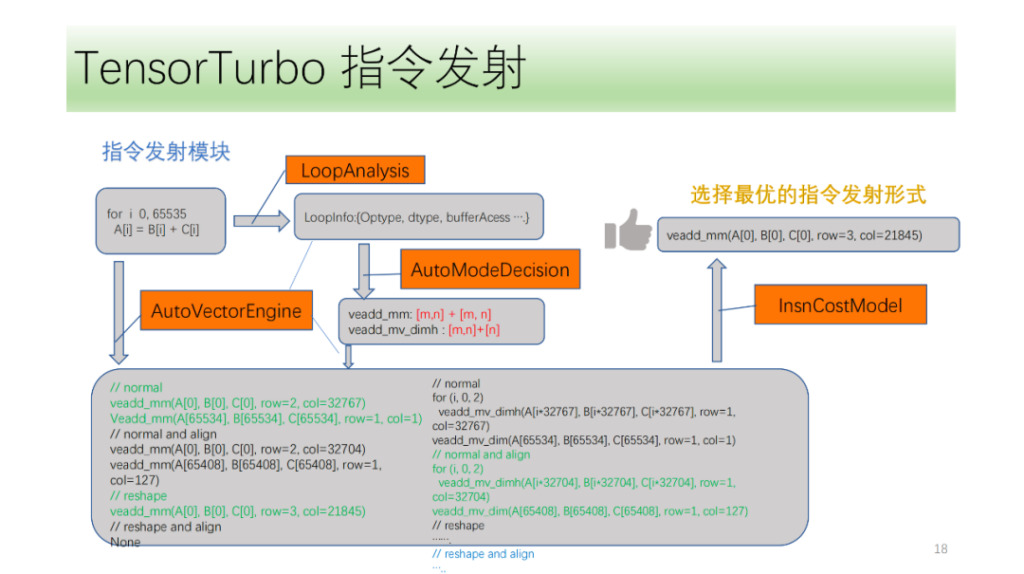
Ensuite, il y a le module de transmission de commandes. Tout d'abord, le module d'émission d'instructions analysera cycliquement la structure de la boucle et obtiendra des informations telles que Optype, dtype, bufferAcess, etc. Après avoir obtenu ces informations, la reconnaissance d'instructions identifiera les instructions que l'axe de boucle peut émettre. Étant donné qu'une structure IR peut correspondre à plusieurs instructions NPU, nous identifierons toutes les instructions possibles à émettre et laisserons le moteur de recherche VectorEngine rechercher la possibilité d'émettre chaque instruction en fonction d'une série d'informations telles que l'alignement et le remodelage des instructions. Enfin, CostModel calculera et trouvera la forme d’émission optimale pour l’émission.
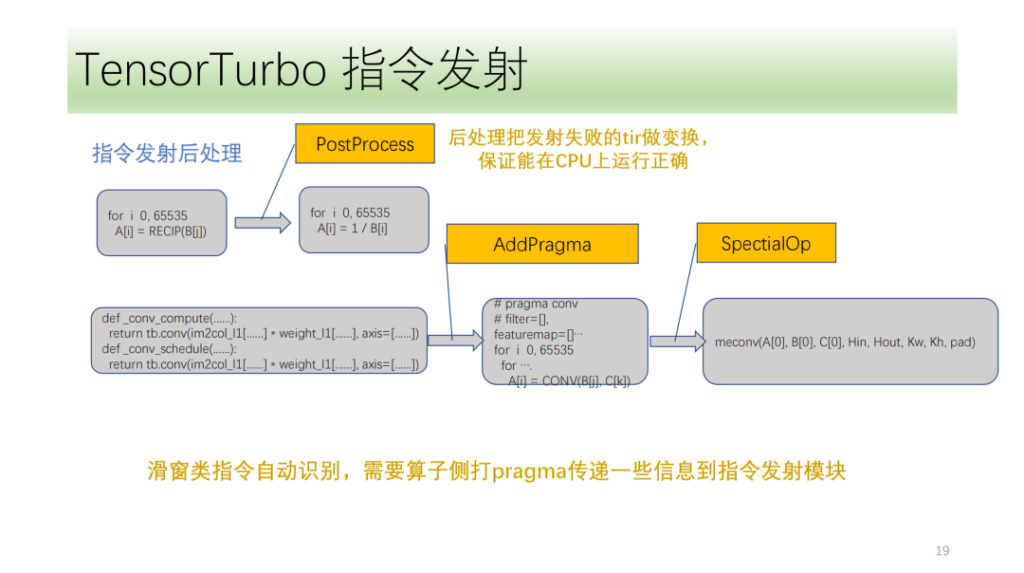
Le dernier est le module de traitement post-instruction. L'objectif principal est de traiter le tir qui n'a pas réussi à émettre l'instruction pour garantir qu'il peut s'exécuter correctement sur le processeur. Il existe également des instructions spéciales que Shim doit marquer au début de l'algorithme. Le module de transmission d'instructions utilise ces marques et sa propre analyse IR pour transmettre correctement les instructions correspondantes.
Ce qui précède représente l’intégralité du processus de quantification et de vectorisation du tenseur DSA de Shim. Nous avons également exploré certaines directions, comme la solution micro-noyau, qui est également un sujet très discuté récemment. Son idée de base est de diviser un processus informatique en deux couches, une couche est épissée sous la forme d'un micro-noyau combiné et l'autre est recherchée. Enfin, les résultats des deux couches sont assemblés pour sélectionner le résultat optimal. L’avantage de cette méthode est qu’elle utilise pleinement les ressources matérielles tout en réduisant la complexité de la recherche et en améliorant son efficacité.
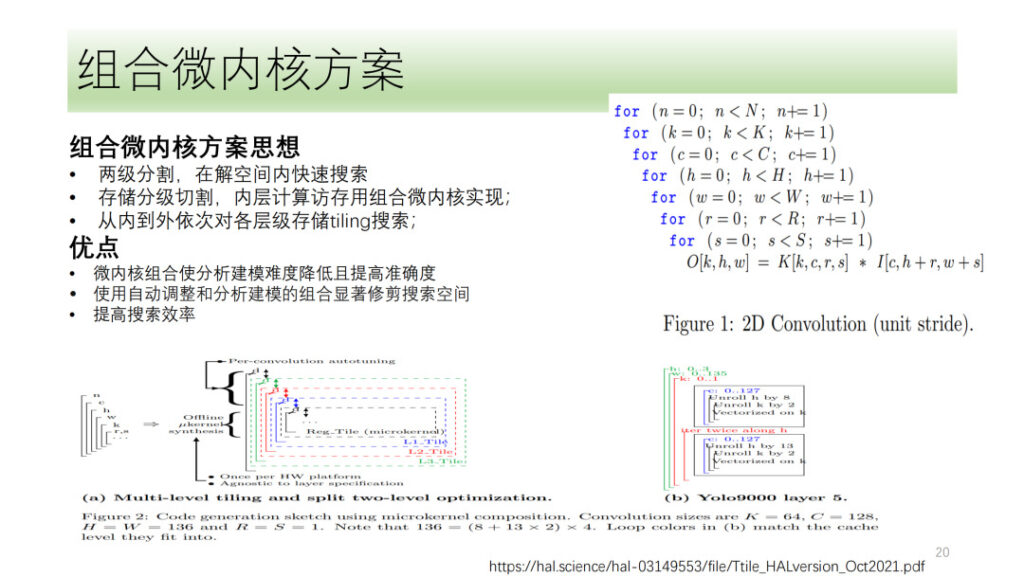

Shim a également exploré le micro-noyau, mais considérant que la solution micro-noyau n'a pas amélioré de manière significative les performances par rapport aux solutions actuelles, Shim est encore au stade exploratoire dans la direction du micro-noyau.
Yuan Sheng, Shim Computing : Opérateurs personnalisés pour DSA
Cette partie est partagée sur le site par l'ingénieur informatique de Shim, Yuan Sheng.
Tout d’abord, nous savons que le développement des opérateurs rencontre actuellement quatre problèmes majeurs :
- Il existe de nombreux opérateurs de réseaux neuronaux qui doivent être pris en charge. Après classification, il existe plus de 100 opérateurs de base.
- Comme l’architecture matérielle est en constante itération, les instructions et la logique correspondantes impliquées dans les opérateurs doivent être modifiées ;
- Considérations sur les performances. La fusion d'opérateurs (mémoire locale, mémoire partagée) et le transfert d'informations de calcul graphique (segmentation, etc.) que j'ai mentionnés précédemment ;
- Les opérateurs doivent être ouverts aux utilisateurs, et les utilisateurs ne peuvent accéder au logiciel que pour personnaliser les opérateurs.
Je l’ai principalement divisé en trois aspects suivants. Le premier est l’opérateur graphique, qui est basé sur l’API relais et est adapté aux opérateurs de langage de base.
Prenons l’exemple de la figure suivante :
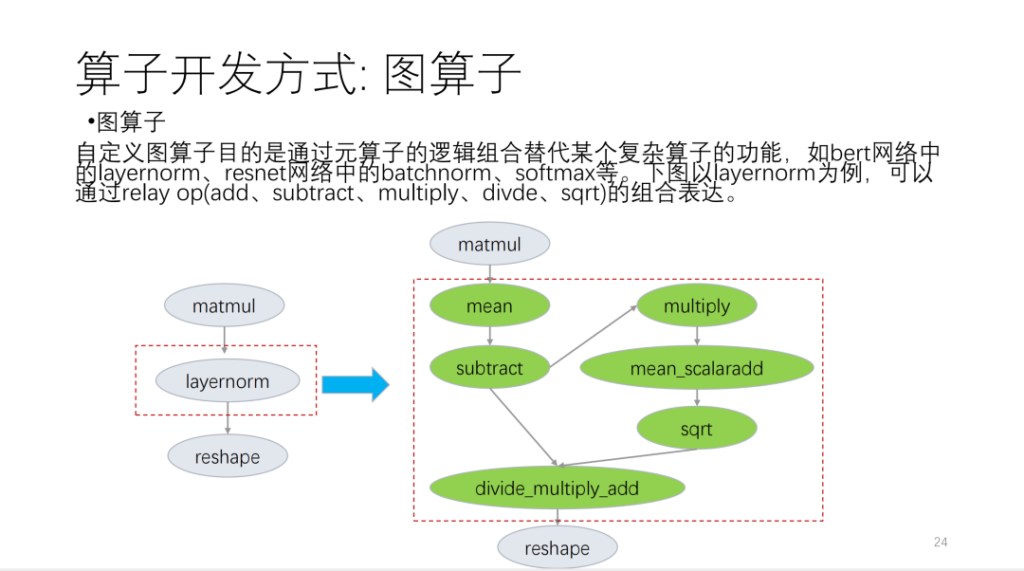
Le deuxième est le méta-opérateur. Le soi-disant méta-opérateur est basé sur TVM Topi et utilise compute/schedule pour décrire la logique de l'algorithme de l'opérateur et la logique liée à la transformation de boucle. Lorsque nous développons des opérateurs, nous constatons que de nombreux programmes d’opérateurs peuvent être réutilisés. Sur la base de cette situation, Shim fournit un ensemble de modèles similaires aux plannings. Nous divisons désormais les opérateurs en plusieurs catégories. Sur la base de ces catégories, les nouveaux opérateurs réutiliseront un grand nombre de modèles de planification.
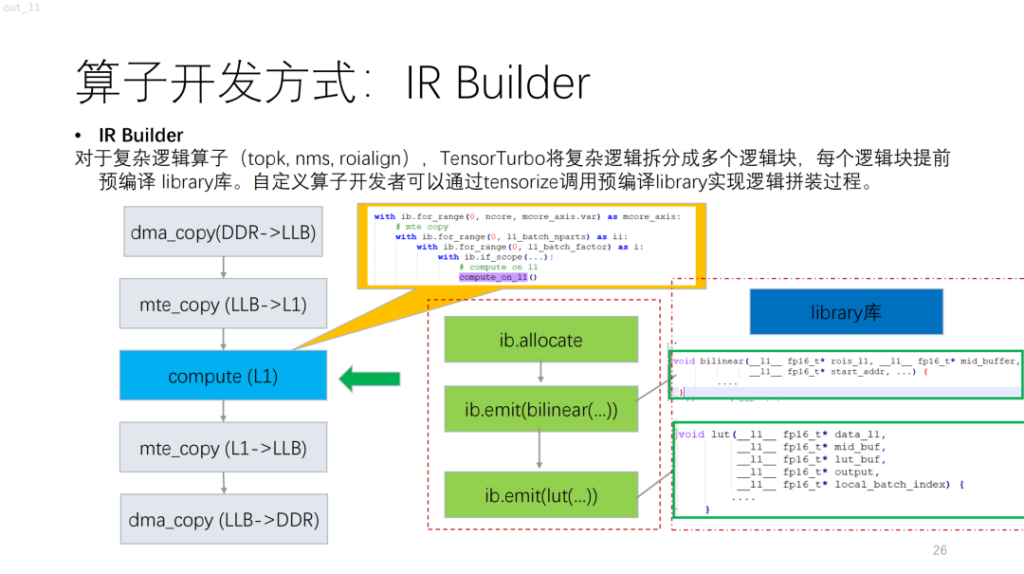
Vient ensuite un opérateur plus complexe. Sur la base de NPU, vous constaterez que les algorithmes avec flux de contrôle tels que topk et nms comportent de nombreux calculs scalaires, qui sont actuellement difficiles à décrire à l'aide de compute/schedule. Pour résoudre ce problème, Shim fournit une bibliothèque similaire. Cela équivaut à compiler d'abord une logique complexe dans la bibliothèque, puis à générer la logique de l'opérateur entier en la combinant avec le générateur IR.
Vient ensuite la segmentation des opérateurs. Pour NPU, par rapport au GPU et au CPU, chaque instruction de TVM fonctionnera sur un bloc de mémoire continu et il y aura une limite de taille de mémoire. En même temps, dans ce cas, l’espace de recherche n’est pas grand. Sur la base de ces problèmes, Shim a fourni des solutions. Tout d’abord, il y aura un ensemble de candidats, et les solutions réalisables seront placées dans l’ensemble de candidats. Deuxièmement, la faisabilité est expliquée, en tenant principalement compte des exigences de performance et des limitations des instructions NPU. Enfin, la fonction de coût est introduite, qui prend en compte les caractéristiques de l'opérateur et les caractéristiques des unités de calcul qui peuvent être utilisées.
L’aspect le plus difficile du développement de l’opérateur est l’opérateur de fusion. Nous sommes actuellement confrontés à deux problèmes explosifs. La première est que nous ne savons pas comment combiner nos propres opérateurs avec d’autres opérateurs. La deuxième est que nous pouvons voir qu’il existe de nombreux niveaux de mémoire dans le NPU, et qu’il y a une fusion explosive des niveaux de mémoire. Shim LLB disposera d'une combinaison fusionnée de mémoire partagée et de mémoire locale. Sur la base de cette situation, nous fournissons également un cadre de génération automatique. Tout d'abord, selon les informations de planification fournies par la couche, l'opération de déplacement de données est insérée, puis les informations de planification sont affinées en fonction de l'opération maître et de l'opération salve dans la planification. Enfin, un post-traitement est effectué en fonction des limitations des instructions actuelles et d’autres problèmes.

Enfin, les opérateurs pris en charge par Shim sont principalement présentés. Il existe environ 124 opérateurs ONNX, et actuellement environ 112 sont pris en charge, ce qui représente 90,3%. Parallèlement, Shim dispose d'un ensemble de tests aléatoires qui peuvent tester de grands nombres premiers, des combinaisons de fusion et certaines combinaisons de fusion de motifs.
Résumer
Cette partie est partagée sur le site par l'ingénieur informatique de Shim, Dan Xiaoqiang.
Il s'agit du CI construit par Shim sur la base de TVM, qui exécute plus de 200 modèles et de nombreux tests unitaires. Si MR n'occupe pas les ressources CI, il faut plus de 40 minutes pour soumettre un code. La quantité de calcul est très importante et implique plus de 20 cartes de calcul développées par nos soins et quelques machines à processeur.
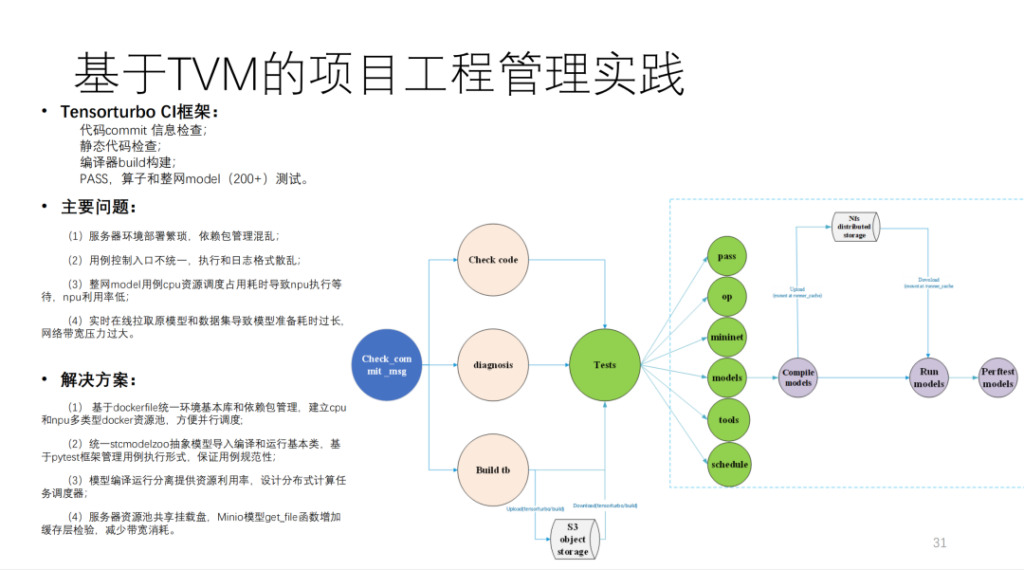
Pour résumer, voici le schéma d'architecture de Shim, comme indiqué ci-dessous :
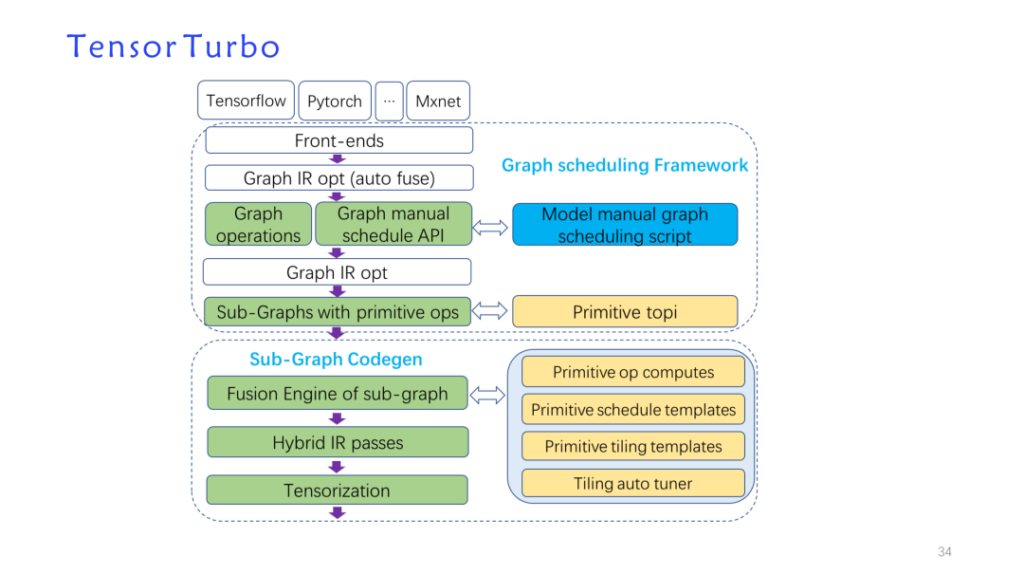
D’après les résultats, les performances ont été grandement améliorées. De plus, si la génération automatique est comparée à une autre équipe de modèles d'écriture manuscrite, elle peut essentiellement atteindre leur 90% ou plus.

C'est la situation du code Xim. Le côté gauche montre comment les codes TVM et auto-développés sont gérés. TVM est utilisé comme structure de données dans third_party. Xim a sa propre source et ses propres éléments Python. Si nous devons apporter des modifications à TVM, nous pouvons modifier TVM dans le dossier de correctifs. Il y a ici trois principes :
- La plupart d’entre eux utilisent des passes développées en interne et développent également des modules personnalisés ;
- Le patch limitera la modification du code source de TVM et le diffusera en amont à temps si possible ;
- Synchronisez-vous régulièrement avec la communauté TVM et mettez à jour le dernier code dans le référentiel.
La quantité totale de code est également indiquée dans la figure ci-dessus.
Résumer:
- Nous prenons en charge les puces de première et deuxième génération de HIMU de bout en bout basées sur TVM ;
- Mettre en œuvre toutes les exigences d’optimisation de la compilation basées sur le relais et le tir ;
- Génération automatique terminée de plus de 100 instructions de tenseur vectoriel basées sur tir ;
- Mise en œuvre d'une solution d'opérateur personnalisée basée sur TVM ;
- La première génération du modèle prend en charge 160+, et la deuxième génération a permis 20+ ;
- Les performances du modèle sont proches de celles de l’écriture manuscrite.
Questions et réponses
Q1 : Je suis intéressé par l'opérateur de fusion. Comment se combine-t-il avec le TIR de TVM ?
A1 : Pour la figure de droite, pour le même niveau d'opérateur, tout d'abord, si l'opérateur a deux entrées et une sortie, alors il y a 27 formes d'opérateur. Deuxièmement, lorsque plusieurs opérateurs sont connectés, la portée peut être l’une des trois, nous ne supposons donc pas de modèle fixe. Alors comment l'implémenter sur TVM ? Tout d’abord, en fonction de la planification des couches, décidez où se trouvent les ajouts avant et arrière et la portée intermédiaire. La couche est un processus très complexe. Le résultat de sortie permet de déterminer dans quel cache l'opérateur existe et quelle quantité de cache est disponible. Grâce à cette planification, nous générons automatiquement des opérateurs fusionnés au niveau de la couche opérateur. Par exemple, nous insérons automatiquement des opérations de migration de données en fonction des informations de portée pour terminer la construction du flux de données.
Le mécanisme des informations de planification est très similaire à celui de TVM natif. La taille utilisée par chaque portée de membre doit être prise en compte lors du processus de fusion. Donc c'est du contenu natif de TVM. Nous utilisons simplement un framework spécial pour l'intégrer ici et le rendre automatique.
Sur cette base, le calendrier requis par le développeur est établi, et il peut également y avoir un post-traitement.

Q2 : Pourriez-vous partager plus de détails sur CostModel ? La fonction de coût est-elle conçue en fonction des fonctionnalités au niveau de l’opérateur ou au niveau du matériel ?
A1 : L’idée générale est ici. Tout d’abord, un ensemble de candidats est généré. Le processus de génération est lié à la structure NPL. Ensuite, il y a un processus d'élagage, prenant en compte les restrictions d'instructions et les optimisations ultérieures, le multi-cœur, le double tampon, etc. Enfin, il existe une fonction de coût pour les trier.
Nous savons que l’essence de la routine d’optimisation est de savoir comment masquer le mouvement des données dans les calculs. Il ne s’agit de rien d’autre que de simuler l’opération selon cette norme et de calculer finalement le coût.
Q3 : En plus des règles de fusion par défaut prises en charge par TVM, TVM a-t-il généré de nouvelles règles de fusion, telles qu'une fusion unique personnalisée pour différents matériels de la couche informatique ?
A3 : Concernant la fusion, il y a en fait deux niveaux. La première est la fusion tampon et la seconde est la fusion boucle. La méthode de fusion TVM vise en fait ce dernier. Shim suit fondamentalement le modèle de fusion TVM que vous avez mentionné, mais avec certaines restrictions.








