Command Palette
Search for a command to run...
Siyuan Feng : Apache TVM Et Le Développement De La Compilation d'apprentissage Automatique

Cet article a été publié pour la première fois sur le compte officiel WeChat de HyperAI~
Bonjour, bienvenue à tous à 2023 Meet TVM aujourd'hui. En tant qu'Apache TVM PMC,Permettez-moi de partager avec vous le développement de TVM et le futur framework Unity de TVM.
Évolution d'Apache TVM
Tout d’abord, pourquoi existe-t-il MLC (Machine Learning Compilation) ? À mesure que les modèles d’IA continuent de se développer, de plus en plus de demandes apparaîtront dans les applications de production réelles. Les applications d'IA de première couche de nombreuses applications (comme illustré dans la figure) sont partagées, notamment ResNet, BERT, Stable Diffusion et d'autres modèles.

Le scénario de deuxième niveau est différent. Les développeurs doivent déployer ces modèles dans différents scénarios, en commençant par le cloud computing et le calcul haute performance, qui nécessitent une accélération GPU. Avec l'accélération du domaine de l'IA, la tâche la plus importante est de l'introduire dans des milliers de foyers, c'est-à-dire sur des PC personnels, des téléphones portables et des appareils Edge.
Cependant, différents scénarios ont des exigences différentes, notamment la réduction des coûts et l’amélioration des performances. Out of the Box doit garantir que les utilisateurs peuvent l'utiliser immédiatement après avoir ouvert une page Web ou téléchargé une application. Le téléphone portable doit économiser de l'énergie. Edge doit fonctionner sur du matériel sans système d'exploitation. Parfois, la technologie doit également fonctionner sur des puces à faible consommation d’énergie et à faible puissance de calcul. Ce sont les difficultés que chacun rencontre dans différentes applications. Comment les résoudre ?
Il existe un consensus dans le domaine du MLC, à savoir la conception IR à plusieurs niveaux.Le noyau comporte trois couches : la première couche IR au niveau graphique, la couche intermédiaire IR au niveau tenseur et la couche suivante IR au niveau matériel. Ces couches sont nécessaires car le modèle est un graphique, la couche intermédiaire est un IR au niveau du tenseur et le cœur du MLC est d'optimiser le calcul du tenseur. Les deux couches ci-dessous, IR au niveau matériel et matériel, sont liées l'une à l'autre, ce qui signifie que TVM ne sera pas impliqué dans la génération directe des instructions d'assemblage, car il y aura des techniques d'optimisation plus détaillées au milieu, qui seront résolues par le fabricant ou le compilateur.

ML Compiler a été conçu avec les objectifs suivants à l'esprit :
- Minimisation des dépendances
Tout d’abord, minimisez le déploiement des dépendances.La raison pour laquelle les applications d’IA n’ont pas vraiment décollé est que le seuil de déploiement est trop élevé. Plus de personnes ont utilisé ChatGPT que Stable Diffusion, non pas parce que Stable Diffusion n'est pas assez puissant, mais parce que ChatGPT fournit un environnement qui peut être utilisé prêt à l'emploi. À mon avis, avec Stable Diffusion, vous devez d'abord télécharger un modèle depuis GitHub, puis ouvrir un serveur GPU pour le déployer, mais ChatGPT fonctionne immédiatement. L’objectif principal de l’utilisation prête à l’emploi est de minimiser les dépendances afin qu’elle puisse être utilisée par tout le monde et dans tous les environnements.
- Prise en charge matérielle variée
Le deuxième point est qu’il peut prendre en charge différents matériels.Le déploiement diversifié du matériel n'est pas le problème le plus important dans les premières étapes du développement, mais avec le développement des puces d'IA au pays et à l'étranger, il deviendra de plus en plus important, en particulier compte tenu de l'environnement national actuel et du statu quo des sociétés de puces nationales, ce qui nous oblige à avoir un bon support pour tous les types de matériel.
- Optimisation de la compilation
Le troisième point est l’optimisation générale de la compilation.En compilant les couches précédentes d’IR, les performances peuvent être optimisées, notamment en améliorant l’efficacité opérationnelle et en réduisant l’utilisation de la mémoire.
Aujourd’hui, la plupart des gens considèrent la compilation et l’optimisation comme le point le plus important, mais pour l’ensemble de la communauté, les deux premiers points sont essentiels. Parce que cela se passe du point de vue du compilateur, et que ces deux points sont des avancées de zéro à un, l’optimisation des performances est souvent la cerise sur le gâteau.
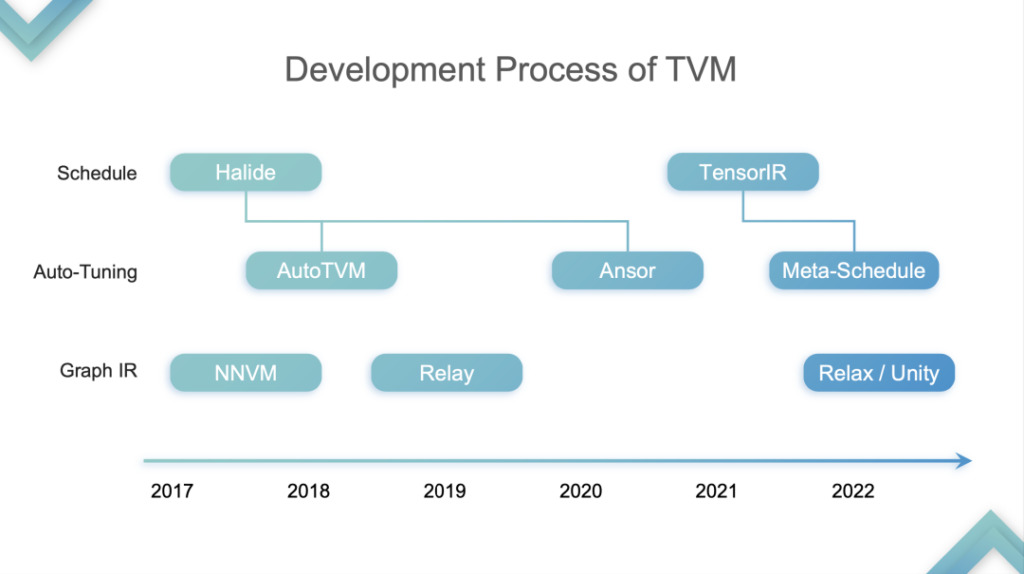
Revenons au sujet du discours,Je divise le développement de TVM en quatre étapes :Ceci n'est que mon opinion personnelle.
Abstraction TensorIR
Étape 1 :À ce stade, TVM optimise et accélère l’inférence sur le CPU et le GPU. Le GPU fait spécifiquement référence à la partie matérielle du SIMT. À ce stade, de nombreux fournisseurs de cloud computing ont commencé à utiliser TVM car ils ont découvert qu'il pouvait accélérer à la fois le CPU et le GPU. Pourquoi? J'ai mentionné plus tôt que le CPU et le GPU ne prennent pas en charge la tensorisation. La première génération de TVM TE Schedule était basée sur Halide et ne disposait pas d'un bon support de tensorisation. Par conséquent, le développement ultérieur de TVM a suivi la voie technique du développement d'Halide, y compris Auto TVM et Ansor, qui n'étaient pas favorables à la prise en charge de la tensorisation.
Commençons par examiner le processus de développement du matériel. Le passage du CPU au GPU s'est fait vers 2015 et 2016, et du GPU au TPU vers 2019. Pour prendre en charge la tensorisation,TVM a d’abord analysé les caractéristiques des programmes tensorisés.
- Nids de boucles optimisés avec liaison de fil
Tout d’abord, un test de boucle est nécessaire, ce qui est requis pour tous les programmes tensorisés. Il y a un chargement de données multidimensionnelles en dessous. Ceci est différent de CMT et CPU. Il stocke et calcule en tenseurs plutôt qu'en scalaires.
- Chargement/stockage de données multidimensionnelles dans une mémoire tampon spécialisée
Deuxièmement, il est stocké dans une mémoire tampon spéciale.
- Corps de calcul tensorisé opaque Multiplication matricielle 16×16
Troisièmement, il y aura un pool de matériel pour permettre le calcul. Le Tensor Primitive suivant est utilisé comme exemple pour calculer la multiplication de matrice 16*16. Ce calcul n'est plus exprimé comme un mode de calcul avec combinaison scalaire, mais est calculé comme une unité de compte avec une instruction.

Sur la base des trois analyses qualitatives ci-dessus du programme tensorisé, TVM a introduit le bloc de calcul. Le bloc est une unité de calcul, avec une imbrication sur la couche la plus externe, un itérateur d'itération et des relations de dépendance au milieu et un corps en bas. Son concept est de séparer le calcul des couches internes et externes, c'est-à-dire d'isoler le calcul interne du calcul tensorisé.
Étape 2 :À ce stade, TVM effectue une auto-tensorisation. Voici un exemple pour expliquer en détail comment le mettre en œuvre.

Auto-tensorisation
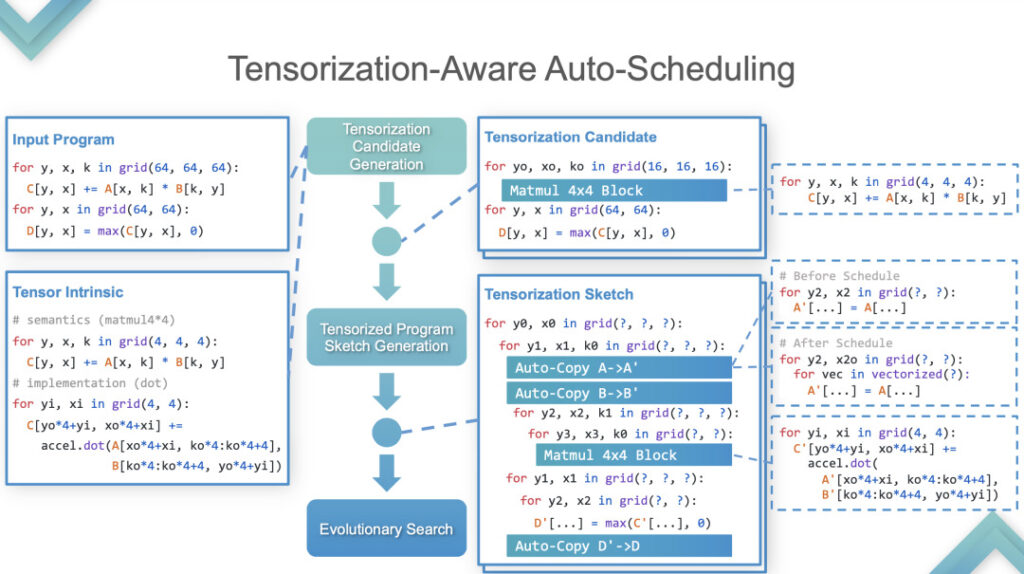
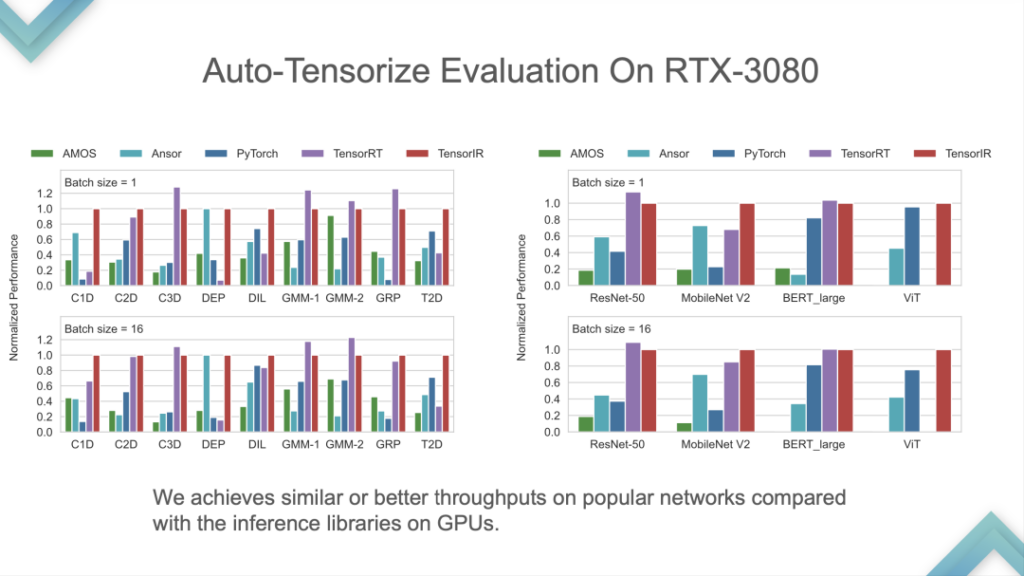
Le programme d'entrée et le tenseur intrinsèque sont des entrées. Les résultats montrent que TensorIR et TensorRT sont fondamentalement à égalité sur le GPU, mais les performances de certains modèles standards ne sont pas très bonnes. Étant donné que le modèle standard est la mesure standard pour ML Perf, les ingénieurs NVIDIA y consacrent beaucoup de temps. Il est relativement rare de surpasser TensorRT sur les modèles standards, ce qui équivaut à battre la technologie la plus avancée du secteur.
Il s'agit d'une comparaison des performances du processeur développé par ARM. TensorIR et ArmComputeLib peuvent être environ 2 fois plus rapides qu'Ansor et PyTorch de bout en bout. La performance n’est pas le plus critique, l’idée d’auto-tensorisation en est le cœur.
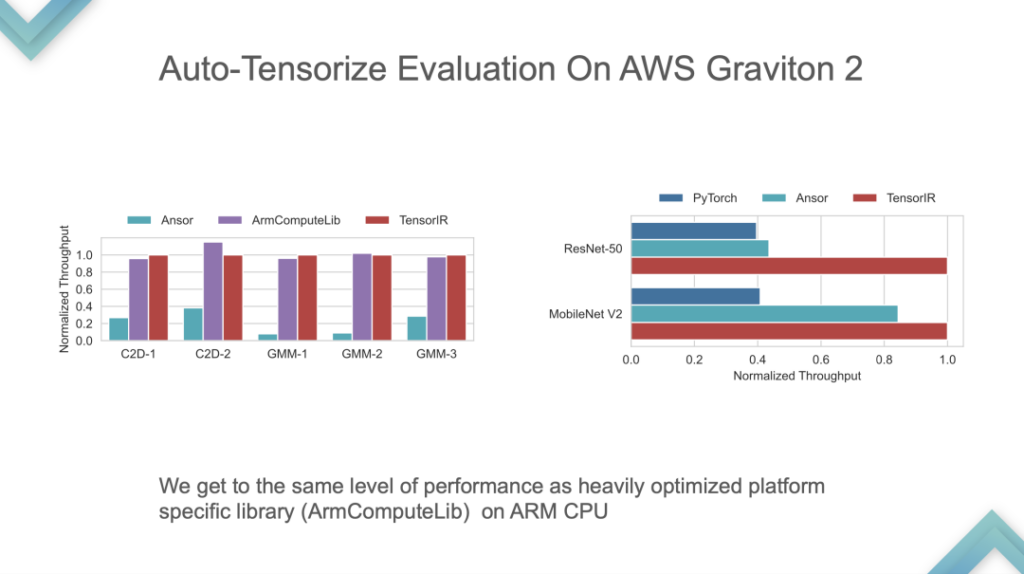
Étape 3 :Un compilateur ML de bout en bout pour le matériel tensorisé. À ce stade, il peut être lancé sur le GPU ou sur une puce d'accélérateur déjà prise en charge, suivi d'un réglage automatique et d'une importation de modèle, formant un système auto-cohérent. À ce stade, le cœur de TVM est de bout en bout. Un modèle peut être développé pour une utilisation directe, mais la personnalisation est très difficile.
Ensuite, je parlerai un peu lentement du développement et de la réflexion sur Relax et Unity, car :
- Personnellement, je pense que Relax et Unity sont plus importants ;
- Il est encore au stade expérimental et de nombreuses choses ne sont que des idées, manquant de démonstration de bout en bout et de code complet.
Limitations de la pile Apache TVM :
- Énorme écart entre le relais et le TIR. Le plus gros problème avec TVM est que le paradigme de compilation du relais au TIR est trop raide ;
- Pipeline fixe pour la plupart des matériels. Le processus standard du TVM est le relais vers le TIR ? Après la compilation, j'ai constaté que de nombreux matériels ne prennent en charge que BYOC ou souhaitent utiliser BYOC+TIR, mais Relay ne le prend pas bien en charge, ni TIR ni Library. En prenant l’accélération GPU comme exemple, les éléments sous-jacents de Relay sont fixes. Vous pouvez soit écrire CUDA pour le réglage automatique, soit utiliser BYOC pour TensorRT, soit utiliser cuBLAS pour régler des bibliothèques tierces. Bien qu’il existe de nombreuses options, il s’agit toujours de choisir l’une ou l’autre. Ce problème a un impact important et est difficile à résoudre sur Relay.
Solution : TVM Unity.
Apache TVM Unity
Les deux couches d'IR, Relax et TIR, sont traitées comme un tout et intégrées dans le paradigme de programmation Graph-TIR. Forme de fusion : En prenant comme exemple le modèle linéaire le plus simple, dans ce cas, l'ensemble de l'IR est contrôlable et programmable. Le langage Graph-TIR résout le problème de la couche inférieure trop raide. Les opérateurs de haut niveau peuvent être modifiés étape par étape et peuvent même être remplacés par n'importe quel BYOC ou appel de fonction.

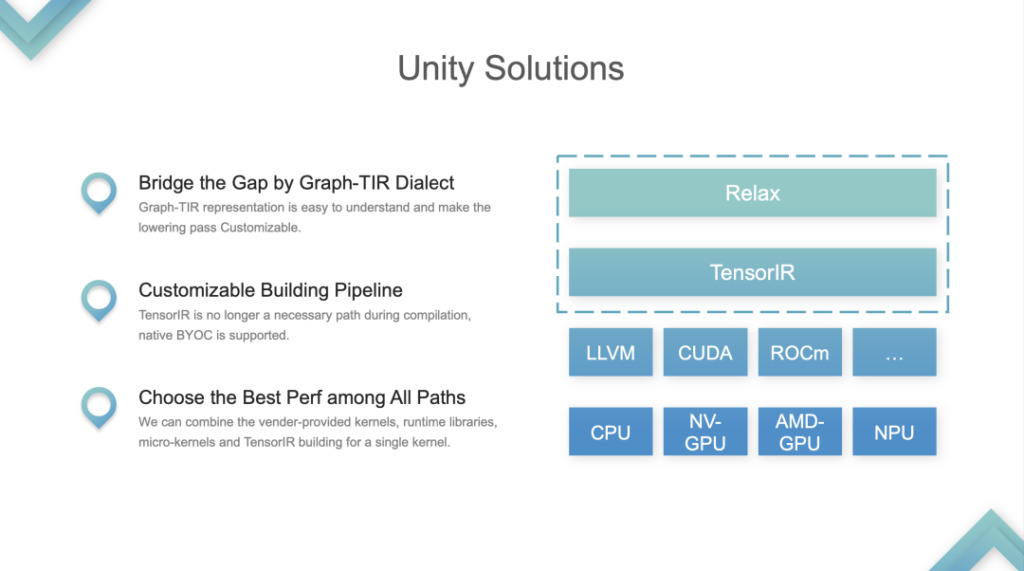
1. Soutenir des solutions personnalisées pour créer des problèmes de pipeline. Le pipeline TVM d'origine consistait à relayer un TIR supplémentaire, puis à effectuer le réglage sur le TIR, puis à le transmettre à LLVM ou CUDA après le réglage. Il s'agissait d'un pipeline à construction fixe. Maintenant, le pipeline a changé.
2. Choisissez la meilleure performance parmi tous les chemins. Les développeurs peuvent choisir entre la bibliothèque ou le TIR et appeler n'importe quoi. C'est le problème le plus important résolu par Unity, et la communauté le considère comme la solution de compilation ML unifiée.
Malentendu
- TVM et MLIR sont en concurrence
En fait, TVM et MLIR n’ont pas de relation concurrentielle claire et de même niveau. TVM se concentre sur la compilation d'apprentissage automatique MLC, tandis que MLIR met l'accent sur le multi-niveau, et ses fonctionnalités peuvent également être utilisées pour la compilation ML. Les développeurs utilisent MLIR pour la compilation de l'apprentissage automatique, d'une part parce que MLIR a une intégration native avec des frameworks tels que PyTorch, et d'autre part parce qu'avant Unity, les capacités de personnalisation de TVM étaient relativement faibles.
- TVM = Moteur d'inférence pour CPU/GPU
TVM n’a jamais été un moteur d’inférence. Il peut effectuer une compilation et les développeurs peuvent l'utiliser pour accélérer l'inférence. TVM est une infrastructure de compilateur, mais pas un moteur d'inférence. L’idée selon laquelle « le TVM ne peut être utilisé que pour l’accélération » est fausse. La raison pour laquelle TVM peut être utilisé pour l'accélération est essentiellement due au compilateur, qui est plus rapide que les méthodes d'exécution en mode impatient telles que PyTorch.
- TVM = Réglage automatique
Avant l'apparition de Relax, la première réaction de tout le monde à l'égard de TVM était qu'ils pouvaient obtenir de meilleures performances grâce au réglage automatique. La prochaine direction de développement de TVM est de diluer ce concept. TVM propose différentes manières d'obtenir de meilleures performances et de personnaliser l'ensemble du processus de compilation. Ce que TVM Unity doit faire, c’est fournir un cadre qui combine divers avantages.
Prochaine étape
Dans l'étape suivante, TVM se développera en une infrastructure de compilateur d'apprentissage automatique multi-couches et s'efforcera de devenir un pipeline de construction personnalisable pour différents backends, prenant en charge la personnalisation sur différents matériels. Cela nécessite de combiner différentes méthodes et d’intégrer les forces des différentes parties.
Questions et réponses
Q 1 : TVM a-t-il des projets d’optimisation de grands modèles ?
A 1 : En termes de grands modèles, nous avons quelques idées préliminaires. Actuellement, TVM a commencé à effectuer un raisonnement distribué et une formation simple, mais il faudra un certain temps avant qu'il puisse être véritablement mis en œuvre.
Q 2 : Quel support et quelle évolution auront Relax dans Dynamic Shape dans le futur ?
A 2 : Relay vm prend en charge la forme dynamique, mais ne génère pas de déduction symbolique. Par exemple, la sortie de la multiplication matricielle de nmk est n et m, mais dans Relay, les trois nmk sont collectivement appelés Any, ce qui signifie dimension inconnue, et sa sortie est également de dimension inconnue. Relay VM peut exécuter ces tâches, mais certaines informations seront perdues pendant la phase de compilation, donc Relax résout ces problèmes. Il s'agit de l'amélioration de Relax sur Relay in Dynamic Shape.
Q 3 : La combinaison de l'optimisation TVM et de l'optimisation des appareils. Si vous utilisez Graph pour générer des instructions directement, TE et TIR ne semblent pas être beaucoup utilisés dans l'optimisation des appareils. Si BYOC est utilisé, il semble que TE et TIR soient également ignorés. Il a été mentionné dans le partage que Relax peut avoir une certaine personnalisation, ce qui semble pouvoir résoudre ce problème.
A 3 : En fait, de nombreux fabricants de matériel ont déjà emprunté la voie TIR, tandis que certains fabricants n'ont pas prêté attention aux technologies associées et choisissent toujours la méthode BYOC. BYOC n'est pas une compilation au sens strict et comporte des restrictions sur le modèle de construction. En général, ce n’est pas que les entreprises ne peuvent pas utiliser la technologie communautaire, mais qu’elles font des choix différents en fonction de leur propre situation.
Q4 : L’émergence de TVM Unity entraînera-t-elle des coûts de migration plus élevés ? Du point de vue de TVM PMC, comment pouvons-nous aider les utilisateurs à effectuer une transition en douceur vers TVM Unity ?
A 4 : La communauté TVM n'a pas abandonné Relay, mais a seulement ajouté l'option Relax. Par conséquent, l'ancienne version continuera d'évoluer, mais afin d'utiliser certaines nouvelles fonctionnalités, une migration de code et de version peut être nécessaire.
Une fois Relax entièrement publié, la communauté fournira des didacticiels de migration et un certain support d'outils pour prendre en charge l'importation directe des modèles Relay dans Relax. Cependant, la migration de la version personnalisée développée sur la base de Relay vers Relax nécessite encore un certain travail, qui prendra environ un mois pour une équipe de plus d'une douzaine de personnes dans l'entreprise.
Q 5 : TensorIR a fait de grands progrès dans Tensor par rapport à avant, mais j'ai remarqué que TensorIR est principalement destiné aux modèles de programmation tels que SIMT et SIMD, qui sont des méthodes de programmation matures. Y a-t-il des progrès dans TensorIR dans de nombreuses nouvelles puces d’IA et modèles de programmation ?
A 5 : Du point de vue de la communauté, la raison pour laquelle TensorIR utilise le modèle SIMT est que seul le matériel SIMT peut être utilisé désormais. Le matériel et les jeux d’instructions de nombreux fabricants ne sont pas open source. Le matériel accessible auprès des grands fabricants se compose essentiellement de CPU, de GPU et de certains SoC de téléphones portables. Les communautés d’autres fabricants n’y ont pratiquement pas accès, elles ne peuvent donc pas s’appuyer sur leurs modèles de programmation. De plus, même si la communauté et les entreprises travaillent ensemble pour créer un TIR d’un niveau similaire, celui-ci ne peut pas être open source en raison de considérations commerciales.
Ce qui précède est un résumé du discours de Feng Siyuan lors du Meet TVM Shanghai Station 2023.Ensuite, le contenu détaillé partagé par les autres invités de cet événement sera également publié sur ce compte officiel l'un après l'autre. S'il vous plaît, continuez à faire attention !
Obtenez le PPT :Suivez le compte public WeChat « HyperAI Super Neural Network » et répondez avec le mot-clé en arrière-plan TVM Shanghai,Obtenez le PPT complet.
Documentation chinoise de TVM :https://tvm.hyper.ai/
Adresse GitHub :https://github.com/apache/tvm








