Command Palette
Search for a command to run...
La Société d'IA À l'origine De « Instant Universe » a Participé Au Développement De Stable Diffusion Et a Reçu Un Financement De 50 Millions De Dollars l'année dernière.

Cet article a été publié pour la première fois sur le compte officiel WeChat de HyperAI~
Le matin du 13 mars, heure de Pékin, la cérémonie des Oscars 2023 s'est tenue à Los Angeles., le film « Blink of an Eye » a remporté sept prix d'un seul coup et est devenu le plus grand gagnant.L'actrice principale Michelle Yeoh a également remporté l'Oscar de la meilleure actrice pour ce film, devenant ainsi la première actrice chinoise de l'histoire des Oscars.

Il semblerait que l'équipe des effets visuels derrière ce film de science-fiction très controversé ne compte que 5 personnes. Afin de réaliser ces prises de vue à effets spéciaux le plus rapidement possible, ils ont choisi la technologie de Runway pour aider à créer certaines scènes, comme l'outil d'écran vert (The Green Screen) pour supprimer l'arrière-plan de l'image.
« Quelques clics me font gagner des heures, que je peux utiliser pour essayer trois ou quatre effets différents pour améliorer le film », a déclaré le réalisateur et scénariste Evan Halleck dans une interview.

Piste : Participation au développement de la première génération de Stable Diffusion
Fin 2018, Cristóbal Valenzuela et d’autres membres ont fondé Runway.Il s'agit d'un fournisseur de logiciels de montage vidéo d'intelligence artificielle qui s'engage à utiliser les dernières avancées en matière d'infographie et d'apprentissage automatique pour abaisser le seuil de création de contenu pour les concepteurs, les artistes et les développeurs et promouvoir le développement de contenu créatif.

Seulement environ 40 employés
en plus,Runway a également une identité moins connue : elle a été un participant majeur de la version initiale de Stable Diffusion.
En 2021, Runway s'est associé à l'Université de Munich en Allemagne pour créer la première version de Stable Diffusion. Par la suite, la startup britannique Stability AI « a apporté des capitaux au groupe » et a fourni à Stable Diffusion davantage de ressources informatiques et de fonds nécessaires à la formation des modèles. Cependant, Runway et Stability AI ne coopèrent plus.
En décembre 2022, Runway a reçu un financement de série C de 50 millions de dollars américains. Outre l'équipe « Blink », ses clients incluent également les groupes de médias CBS et MBC, les agences de publicité Assembly et VaynerMedia, ainsi que la société de design Pentagram.
Le 6 février 2023, le compte Twitter officiel de Runway a publié le modèle Gen-1.Vous pouvez transformer une vidéo existante en une nouvelle en appliquant n'importe quel style spécifié par des repères textuels ou des images de référence.
Gen-1 : structure + contenu
Les chercheurs ont proposé un modèle de diffusion vidéo guidé par la structure et le contenu – Gen-1, qui peut éditer des vidéos en fonction de la description visuelle ou textuelle du résultat attendu.
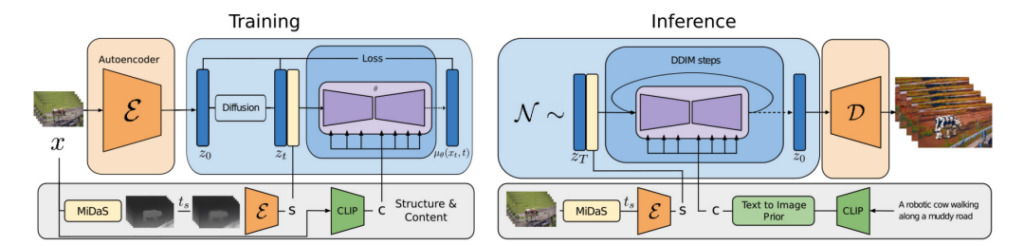
Le contenu fait référence aux caractéristiques qui décrivent l'apparence et la sémantique de la vidéo, telles que la couleur et le style de l'objet cible et l'éclairage de la scène.
La structure fait référence à la description de ses caractéristiques géométriques et dynamiques, telles que la forme, la position et les changements de temps de l'objet cible.
L’objectif du modèle Gen-1 est d’éditer du contenu vidéo tout en préservant la structure de la vidéo.
Au cours du processus de formation du modèle, les chercheurs ont utilisé un ensemble de données à grande échelle composé de vidéos non sous-titrées et de paires texte-image. Dans le même temps, des estimations de profondeur de scène monoculaire ont été utilisées pour représenter la structure, et les intégrations prédites par un réseau neuronal pré-entraîné ont été utilisées pour représenter le contenu.
Cette approche fournit plusieurs modes puissants de contrôle sur le processus de génération :
1. Reportez-vous au modèle de synthèse d'image et entraînez le modèle afin que le contenu vidéo déduit (tel que la présentation ou le style) corresponde à l'image ou à l'invite fournie par l'utilisateur.

2. Se référer au processus de diffusion et effectuer un masquage des informations sur la représentation de la structure, ce qui permet aux développeurs de définir le degré de similitude de l'adhésion du modèle à une structure donnée.
3. Reportez-vous aux conseils sans classificateur et utilisez des méthodes de guidage personnalisées pour ajuster le processus de raisonnement afin de contrôler la cohérence temporelle des clips générés.
Dans cette expérience, les chercheurs :
- Nous étendons le modèle de diffusion latente à la génération de vidéos en introduisant une couche temporelle dans le modèle d'image pré-entraîné et en entraînant conjointement des images et des vidéos.
- Nous proposons un modèle sensible à la structure et au contenu qui peut modifier les vidéos sous la direction d'exemples d'images ou de texte. Le montage vidéo est entièrement réalisé au stade de l'inférence, sans nécessiter de formation vidéo par vidéo ni de prétraitement.
- Contrôle complet sur la cohérence temporelle, du contenu et de la structure. Des expériences montrent que l’entraînement conjoint sur des données d’image et de vidéo peut maintenir la cohérence temporelle pendant l’inférence. Pour assurer la cohérence de la structure, l'entraînement à différents niveaux de détail dans la représentation permet à l'utilisateur de choisir le paramètre souhaité lors de l'inférence.
- Une enquête auprès des utilisateurs a montré que cette méthode était plus populaire que plusieurs autres méthodes.
- En affinant un petit sous-ensemble d’images, le modèle formé peut être davantage personnalisé pour générer des vidéos plus précises de sujets spécifiques.
Pour évaluer les performances de Gen-1, les chercheurs ont utilisé des vidéos de l’ensemble de données DAVIS et une variété d’autres supports.Pour créer automatiquement des invites d’édition, les chercheurs ont d’abord exécuté un modèle de sous-titrage pour obtenir une description du contenu vidéo original, puis ont utilisé GPT3 pour générer des invites d’édition.
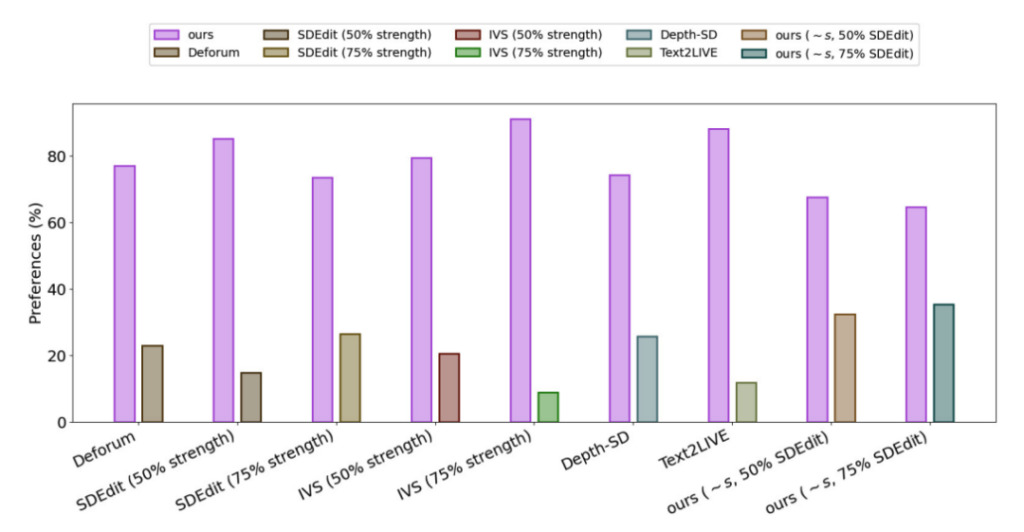
Les résultats expérimentaux montrent que dans l’enquête de satisfaction de toutes les méthodes,Les utilisateurs du 75% préfèrent l'effet de génération Gen-1.
AIGC : avancer malgré la controverse
En 2022, l’IA générative est devenue la technologie la plus accrocheuse depuis l’essor du mobile et du cloud computing il y a plus de dix ans, et nous avons la chance d’assister à l’éclosion de sa couche applicative.De nombreux grands modèles émergent rapidement des laboratoires et sont appliqués à divers scénarios dans le monde réel.
Cependant, malgré ses nombreux avantages tels que l’amélioration de l’efficacité et la réduction des coûts, nous devons également constater que l’intelligence artificielle générative est encore confrontée à de nombreux défis, notamment comment améliorer la qualité de sortie et la diversité du modèle, comment augmenter sa vitesse de génération, ainsi que la sécurité, la confidentialité et les questions éthiques et religieuses pendant le processus de candidature.
Certaines personnes ont remis en question la création artistique de l’IA, et certaines pensent même qu’il s’agit d’une « invasion » de l’art par l’IA. Face à cette voix, le cofondateur et PDG de Runway, Cristóbal Valenzuela, estime que l'IA n'est qu'un outil dans la boîte à outils utilisée pour colorer ou modifier des images et d'autres contenus, pas différent de Photoshop ou LightRoom.Bien que l’IA générative soit encore controversée, elle ouvre la porte à la création pour les personnes non techniques et les personnes créatives, et conduira le domaine de la création de contenu vers de nouvelles possibilités.
Liens de référence :
[1]https://hub.baai.ac.cn/view/23940
[2]https://cloud.tencent.com/developer/article/2227337?








