Command Palette
Search for a command to run...
Prenez l'application Animated Drawings Comme Exemple Et Utilisez TorchServe Pour Régler Le Modèle
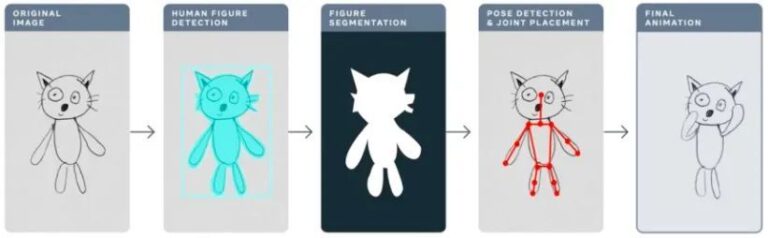
Contenu La section précédente a présenté les cinq étapes du déploiement et du réglage du modèle TorchServe pour déployer le modèle dans un environnement de production. Cette section prend l'application Dessins animés comme exemple pour démontrer l'effet d'optimisation du modèle de TorchServe. Cet article a été publié pour la première fois sur le compte officiel WeChat :Communauté de développeurs PyTorch
L'année dernière, Meta a utilisé l'application Animated Drawings pour « animer » les dessins faits à la main par les enfants avec l'IA, transformant les dessins statiques sur bâton en animations en quelques secondes.


Dessins animéssketch.metademolab.com/
Ce n’est pas facile pour l’IA. L’IA a été conçue à l’origine pour traiter des images du monde réel. Comparés aux images réelles, les dessins des enfants sont très différents dans leur forme et leur style, et sont plus complexes et imprévisibles. Par conséquent, les systèmes d’IA précédents peuvent ne pas être adaptés au traitement de tâches similaires aux dessins animés.
Cet article prendra l'exemple des dessins animés pour expliquer en détail comment utiliser TorchServe pour régler le modèle qui sera déployé dans l'environnement de production.
4 facteurs qui affectent le réglage du modèle dans les environnements de production
Le flux de travail suivant montre l’idée générale de l’utilisation de TorchServe pour déployer un modèle dans un environnement de production.

Dans la plupart des cas, les modèles déployés dans les environnements de production sont optimisés en fonction des accords de niveau de service (SLA) de débit ou de latence.
En général, les applications en temps réel sont davantage préoccupées par la latence, tandis que les applications hors ligne sont davantage préoccupées par le débit.
De nombreux facteurs affectent les performances des modèles déployés dans les environnements de production. Cet article se concentre sur quatre d’entre eux :
1. Optimisations du modèle
Il s'agit d'une étape préalable au déploiement de modèles en production et comprend la quantification, l'élagage, l'utilisation de graphiques IR (TorchScript dans PyTorch), la fusion de noyaux et de nombreuses autres techniques. Actuellement, de nombreuses techniques similaires sont disponibles dans TorchPrep en tant qu’outils CLI.
2. Inférence par lots
Il s’agit d’introduire plusieurs entrées dans un modèle. Il est fréquemment utilisé pendant le processus de formation et est également utile pour contrôler les coûts pendant la phase d’inférence.
Les accélérateurs matériels sont optimisés pour le parallélisme et le traitement par lots permet d'utiliser pleinement la puissance de calcul, ce qui se traduit souvent par un débit plus élevé. La principale différence en matière d’inférence est que vous n’avez pas besoin d’attendre trop longtemps pour obtenir un lot du client, ce que nous appelons souvent le traitement par lots dynamique.
3. Nombre de travailleurs
TorchServe déploie le modèle via des travailleurs. Les travailleurs de TorchServe sont des processus Python qui ont une copie des poids du modèle utilisés pour l'inférence. Trop peu de travailleurs ne bénéficieront pas d’un parallélisme suffisant ; un nombre trop élevé de travailleurs entraînera une diminution des conflits entre les travailleurs et des performances de bout en bout.
4. Matériel
Choisissez un matériel adapté parmi TorchServe, CPU, GPU, AWS Inferentia en fonction de votre modèle, de votre application, de votre latence et de votre budget de débit.
Certaines configurations matérielles sont conçues pour obtenir les meilleures performances de leur catégorie, tandis que d'autres sont conçues pour obtenir un meilleur contrôle des coûts attendus. Les expériences montrent que le GPU est plus adapté lorsque la taille du lot est importante ; lorsque la taille du lot est petite ou qu'une faible latence est requise, le processeur et AWS Inferentia sont plus rentables.
Conseils : éléments à prendre en compte lors de l'optimisation des performances de TorchServe
Avant de commencer,Commençons par partager quelques conseils sur le déploiement de modèles avec TorchServe et l’obtention des meilleures performances.
* Tutoriel officiel d'apprentissage de PyTorch
La sélection du matériel est également étroitement liée à la sélection de l’optimisation du modèle.
* Le choix du matériel pour le déploiement du modèle est étroitement lié à la latence, aux attentes de débit et au coût de chaque inférence.
En raison des différences de taille et d’application des modèles, les environnements de production de CPU ne sont généralement pas en mesure de se permettre le déploiement de modèles de vision par ordinateur similaires.Vous pouvez vous inscrire pour utiliser OpenBayes.com, et vous obtiendrez 3 heures de RTX3090 gratuitement lors de votre inscription, et 10 heures de RTX3090 gratuitement chaque semaine pour répondre aux besoins généraux du GPU.
De plus, les optimisations telles que IPEX récemment ajoutées à TorchServe rendent ces modèles moins chers à déployer et plus abordables en termes de CPU.
Pour plus de détails sur le déploiement du modèle d'optimisation IPEX, veuillez vous référer à
* Le travailleur dans TorchServe appartient au processus Python.Peut fournir des parallèles,Le nombre de travailleurs doit être fixé avec prudence.Par défaut, TorchServe démarre un nombre de travailleurs égal au nombre de VCPU ou de GPU disponibles sur l'hôte, ce qui peut ajouter un temps considérable au démarrage de TorchServe.
TorchServe expose une propriété de configuration pour définir le nombre de travailleurs. Afin de fournir un parallélisme efficace pour plusieurs travailleurs et d'éviter qu'ils ne soient en concurrence pour les ressources, il est recommandé de définir les lignes de base suivantes sur le CPU et le GPU :
Processeur :Définir dans le gestionnaire torche.set_num_threads(1) . Ensuite, définissez le nombre de travailleurs à nombre de cœurs physiques / 2 . Mais la meilleure configuration de thread peut être obtenue en utilisant le script de lancement du processeur Intel.
GPU :Le nombre de GPU disponibles peut être défini dans config.properties nombre_gpus pour le mettre en place. TorchServe utilise le round-robin pour attribuer les travailleurs aux GPU. suggestion:Nombre de travailleurs = (Nombre de GPU disponibles) / (Nombre de modèles uniques). Notez que les GPU pré-Ampère ne fournissent aucune isolation des ressources avec les GPU multi-instances.
* La taille du lot affecte directement la latence et le débit.Afin de mieux utiliser les ressources informatiques, la taille du lot doit être augmentée. Il existe un compromis entre la latence et le débit ; une taille de lot plus importante peut augmenter le débit mais également entraîner une latence plus élevée.
Il existe deux manières de définir la taille du lot dans TorchServe.L’une consiste à configurer le modèle dans config.properties et l’autre à enregistrer le modèle à l’aide de l’API de gestion.
La section suivante montre comment utiliser la suite de tests TorchServe pour déterminer la meilleure combinaison de matériel, de travailleurs et de taille de lot pour l'optimisation du modèle.
Découvrez TorchServe Benchmark Suite
Pour utiliser la suite de tests TorchServe, vous avez d’abord besoin d’un fichier archivé, qui est celui mentionné ci-dessus. .mar document. Ce fichier contient le modèle, le gestionnaire et tous les autres artefacts utilisés pour charger et exécuter l'inférence. L'application de dessin animé utilise le modèle de détection d'objets Mask-rCNN de Detectron2
Exécution de la suite de tests de performances
La suite de référence automatisée de TorchServe peut évaluer plusieurs modèles sous différentes tailles de lots, paramètres de travail et rapports de sortie.
apprendre Suite de benchmarks automatisée
Commencer à courir :
git clone https://github.com/pytorch/serve.git cd serve/benchmarks pip install -r requirements-ab.txt apt-get install apache2-utils
Configurez les paramètres au niveau du modèle dans le fichier yaml :
Model_name : eager_mode : benchmark_engine : « ab » url : « Chemin vers le fichier .mar » workers : - 1 - 4 batch_delay : 100 batch_size : - 1 - 2 - 4 - 8 requests : 10 000 concurrency : 10 input : « Chemin vers l'entrée du modèle » backend_profiling : False exec_env : « local » processors : - « cpu » - « gpus » : « all »
Ce fichier yaml sera benchmark_config_template.yaml Citation. Le fichier YAML contient des paramètres supplémentaires pour générer des rapports et afficher des journaux à l'aide d'AWS Cloud.
benchmarks python/auto_benchmark.py --input benchmark_config_template.yaml
Exécutez le benchmark et les résultats sont enregistrés dans un fichier csv. _/tmp/benchmark/ab_report.csv_ ou rapport complet /tmp/ts_benchmark/report.md Trouvé dans.
Les résultats incluent la latence moyenne de TorchServe, la latence du modèle P99, le débit, la concurrence, le nombre de requêtes, le temps de traitement et d'autres mesures.
Concentrez-vous sur le suivi des facteurs suivants qui affectent le réglage du modèle : la concurrence, la latence du modèle P99 et le débit.
Ces chiffres doivent être pris en compte en conjonction avec la taille du lot, l’équipement utilisé, le nombre de travailleurs et si une optimisation du modèle a été effectuée.
La latence SLA pour ce modèle a été définie à 100 ms. Il s'agit d'une application en temps réel, la latence est un problème important et le débit doit être aussi élevé que possible sans violer le SLA de latence.
En recherchant l'espace, nous exécutons une série d'expériences sur différentes tailles de lots (1 à 32), nombres de travailleurs (1 à 16) et périphériques (CPU, GPU), et résumons les meilleurs résultats expérimentaux, comme indiqué dans le tableau suivant :

Ce modèle a essayé toutes les latences sur le processeur, la taille des lots, la concurrence et le nombre de travailleurs, mais tous n'ont pas réussi à respecter le SLA et ont en fait réduit la latence de 13 fois.
Le déplacement du déploiement du modèle vers le GPU a immédiatement réduit la latence de 305 ms à 23,6 ms.
L'une des optimisations les plus simples que vous puissiez faire pour votre modèle est de réduire sa précision à fp16, qui est un code d'une seule ligne (modèle.half()) , peut réduire la latence du modèle P99 de 32% et augmenter le débit presque du même montant.
Une autre façon d'optimiser le modèle est de convertir le modèle en TorchScript et d'utiliser optimisation_pour_inférence ou d'autres techniques (y compris les optimisations d'exécution onnx ou tensor) qui tirent parti des fusions agressives.
Sur le CPU et le GPU, définissez nombre de travailleurs=1 Cela fonctionne mieux dans le cas de cet article.
* Déployez le modèle sur le GPU et définissez nombre de travailleurs = 1, taille du lot = 1, le débit a été augmenté de 12 fois et la latence a été réduite de 13 fois par rapport au processeur.
* Déployez le modèle sur le GPU et définissez modèle.half(), nombre de travailleurs = 1 , taille du lot = 8, les meilleurs résultats en termes de débit et de latence tolérable peuvent être obtenus. Par rapport au processeur, le débit a été multiplié par 25 et la latence a toujours respecté le SLA (94,4 ms).
Remarque : si vous exécutez une suite d’analyse comparative, assurez-vous de définir les paramètres appropriés. batch_delay, définit la concurrence des requêtes sur un nombre proportionnel à la taille du lot. La concurrence fait ici référence au nombre de requêtes simultanées envoyées au serveur.
Résumer
Cet article présente les considérations relatives au réglage du modèle TorchServe dans un environnement de production et la suite de tests de performance TorchServe pour l'optimisation des performances, offrant aux utilisateurs une compréhension plus approfondie des choix possibles pour l'optimisation du modèle, la sélection du matériel et le coût global.
se concentrer sur Communauté de développeurs PyTorchCompte officiel pour obtenir plus de mises à jour technologiques, de meilleures pratiques et d'informations connexes sur PyTorch !








