Command Palette
Search for a command to run...
Absolument! OpenAI Lancera Un Nouveau Produit À La Fin De l'année. Une Seule Carte Peut Générer Un Nuage De Points 3D En 1 minute. Le Text-to-3D Dit Adieu À l'ère De La Forte Consommation De Puissance De Calcul
Contenu en un coup d'œil :Après DALL-E et ChatGPT, OpenAI a fait un autre effort et a récemment publié Point·E, qui peut générer directement des nuages de points 3D à partir d'invites textuelles. Mots-clés:Nuage de points 3D OpenAI Point E
OpenAI vise des performances de fin d'année. Il y a plus d'un demi-mois, ChatGPT a été publié, mais de nombreux internautes ne l'ont toujours pas compris. Récemment, il a discrètement lancé un autre outil puissant : Point·E, qui peut générer directement des nuages de points 3D à partir d'invites textuelles.
texte en 3D : avec la bonne approche, on peut faire deux choses
Je crois que tout le monde connaît la modélisation 3D. Ces dernières années, la modélisation 3D est apparue dans des domaines tels que la production cinématographique, les jeux vidéo, le design industriel, la réalité virtuelle et la réalité augmentée.
Cependant, créer des images 3D réalistes à l’aide de l’intelligence artificielle reste un processus long et exigeant en main-d’œuvre.Prenons l'exemple de Google DreamFusion : générer des images 3D à partir d'un texte donné nécessite généralement plusieurs GPU et dure plusieurs heures.

D'une manière générale, les méthodes de synthèse texte-3D se répartissent en deux catégories :
Méthode 1 :Entraînez des modèles génératifs directement sur des données appariées (texte, 3D) ou des données 3D non étiquetées.
Bien que ces méthodes puissent générer efficacement des échantillons en exploitant les méthodes de modèles génératifs existantes, elles sont difficiles à étendre à des invites de texte complexes en raison du manque d'ensembles de données 3D à grande échelle.
Méthode 2 :Exploitez des modèles texte-image pré-entraînés pour optimiser les représentations 3D différenciables.
Ces méthodes sont généralement capables de gérer des invites de texte complexes et diverses, mais le processus d’optimisation pour chaque échantillon est coûteux. De plus, en raison de l’absence d’un a priori 3D solide, ces méthodes peuvent tomber dans des minima locaux (qui ne peuvent pas correspondre un à un avec un objet 3D significatif ou cohérent).
Point·E combine un modèle texte-image et un modèle image-3D.En combinant les avantages des deux méthodes ci-dessus,L'efficacité de la modélisation 3D a été encore améliorée, et un seul GPU et une ou deux minutes sont nécessaires pour terminer la conversion du texte en nuage de points 3D.
Analyse de principe : 3 étapes pour générer un nuage de points 3D
Au point E, le modèle texte-image exploite un large corpus (paire texte, image) pour lui permettre de gérer correctement les invites de texte complexes ; le modèle image-3D est formé sur un ensemble de données plus petit (image, paire 3D).
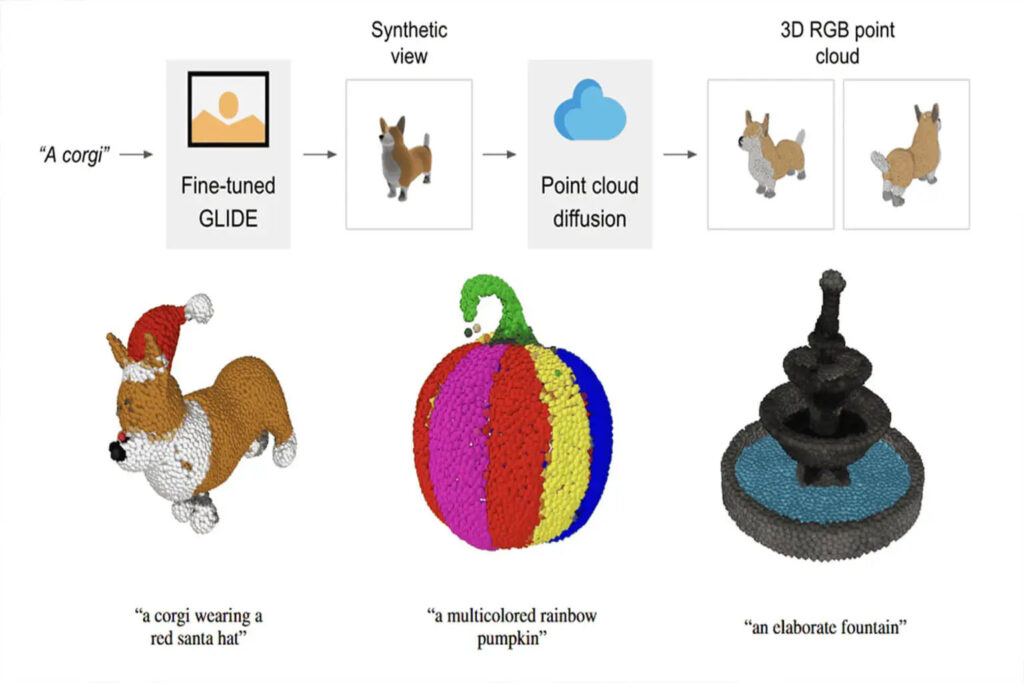
Le processus de génération d'un nuage de points 3D basé sur des invites textuelles à l'aide de Point·E est divisé en trois étapes :
1. Générer une vue synthétique basée sur l'invite de texte
2. Générer un nuage de points grossier (1024 points) basé sur la vue synthétique
3. Générer un nuage de points fin (4096 points) basé sur un nuage de points basse résolution et une vue synthétique

Étant donné que le format et la qualité des données ont un impact considérable sur les résultats de la formation,Point·E a utilisé Blender pour convertir toutes les données de formation dans un format commun.
Blender prend en charge plusieurs formats 3D et est livré avec un moteur de rendu optimisé. Le script Blender unifie le modèle dans un cube englobant, configure une configuration d'éclairage standard et exporte enfin une image RGBAD à l'aide du moteur de rendu en temps réel intégré de Blender.
Script à exécuter dans Blender pour générer un modèle 3D sous forme d'images RGBAD. Exemple d'utilisation : blender -b -P blender_script.py -- \ --input_path ../../examples/example_data/corgi.ply \ --output_path render_out. Passez `--camera_pose z-circular-elevated` pour le rendu utilisé pour calculer les résultats CLIP R-Precision. Le répertoire de sortie contiendra les fichiers JSON de métadonnées pour chaque vue générée, ainsi qu'un fichier de métadonnées global pour le rendu. Chaque image sera enregistrée sous forme de collection de fichiers PNG 16 bits pour chaque canal (RGBAD), ainsi qu'un rendu complet en niveaux de gris de la vue.
Code de script Blender
En exécutant le script, le modèle 3D est rendu uniformément sous la forme d'une image RGBAD
Pour le script complet, voir :
Comparaison précédente de l'IA texte-3D
Au cours des deux dernières années, de nombreuses explorations ont été menées sur la génération de modèles texte en 3D.De grandes entreprises telles que Google et NVIDIA ont également lancé leur propre IA.
Nous avons collecté et compilé trois IA de synthèse texte-3D pour vous permettre de comparer les différences horizontalement.
Champs de rêve
Agence d'édition :Google
Heure de sortie :Décembre 2021
Adresse du projet :https://ajayj.com/dreamfields
DreamFields combine le rendu neuronal avec des représentations d'images et de texte multimodales.En se basant uniquement sur une description textuelle, il est possible de générer une variété de formes et de couleurs d'objets 3D sans supervision 3D.

Dans le processus de génération d'objets 3D par DreamFields,Il s'appuie sur le modèle image-texte pré-entraîné sur un grand ensemble de données d'images textuelles et optimise le champ de rayonnement neuronal sous plusieurs perspectives.Cela permet aux images rendues par le modèle CLIP pré-entraîné d'obtenir de bons résultats sur le texte cible.
DreamFusion
Agence d'édition :Google
Heure de sortie :Septembre 2022
Adresse du projet :https://dreamfusion3d.github.io/
DreamFusion peut réaliser une synthèse texte-3D à l'aide d'un modèle de diffusion texte-image 2D pré-entraîné.
DreamFusion introduit une perte basée sur la distillation de densité de probabilité, qui permet d'utiliser le modèle de diffusion 2D comme préalable pour optimiser le générateur d'images paramétriques.

En appliquant cette perte dans une procédure similaire à DeepDream, Dreamfusion optimise un modèle 3D initialisé aléatoirement (un champ de rayonnement neuronal, ou NeRF) à une perte relativement faible pour les rendus 2D à partir d'angles aléatoires via la descente de gradient.
Dreamfusion ne nécessite pas de données d'entraînement 3D, ni de modifier le modèle de diffusion d'image.L'efficacité du modèle de diffusion d'image pré-entraîné comme a priori est démontrée.
Magic3D
Agence d'édition :NVIDIA
Heure de sortie :Novembre 2022
Adresse du projet :deepimagination.cc/Magic3D/
Magic3D est un outil de création de contenu texte en 3D qui peut être utilisé pour créer des modèles de maillage 3D de haute qualité.En utilisant la technologie de conditionnement d'image et les méthodes d'édition d'invites basées sur du texte, Magic3D offre de nouvelles façons de contrôler la synthèse 3D, ouvrant de nouvelles voies pour une variété d'applications créatives.
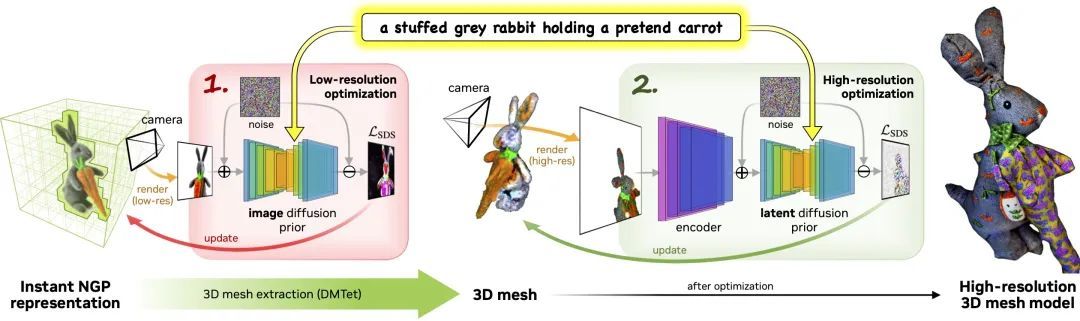
Le processus comprend deux étapes :
Phase 1 :Utilisez une diffusion à basse résolution avant d'obtenir un modèle grossier, et utilisez une grille de hachage et une structure d'accélération clairsemée pour l'accélérer.
Phase 2 :Un modèle de maillage texturé initialisé à partir d'une représentation neuronale grossière est optimisé via un moteur de rendu différentiable efficace interagissant avec un modèle de diffusion latente haute résolution.
Le progrès technologique doit encore dépasser les limites
L’IA texte-3D est progressivement lancée, mais la synthèse 3D basée sur le texte en est encore à ses débuts de développement.Il n’existe pas de référence universellement reconnue dans le secteur qui puisse être utilisée pour évaluer plus équitablement les tâches connexes.
Point·E est d’une grande importance pour la synthèse rapide de texte en 3D.Il améliore considérablement l’efficacité du traitement et réduit la consommation de puissance de calcul.
Mais il est indéniable queLe point E présente encore certaines limites.Par exemple, le pipeline nécessite un rendu synthétique et le nuage de points 3D généré a une faible résolution, ce qui n’est pas suffisant pour capturer des formes ou des textures à grain fin.
Que pensez-vous de l’avenir de la synthèse texte-3D ? Quelle sera la tendance de développement future ? N'hésitez pas à laisser des commentaires dans la section commentaires pour discussion.








