Command Palette
Search for a command to run...
PyTorch 2.0 Est Sorti : Compilez, Compilez Et Compilez !

Aperçu du contenu : Lors de la conférence PyTorch 2022 qui s'est tenue hier soir, PyTorch 2.0 a été officiellement publié. Cet article examinera les plus grandes différences entre PyTorch 2.0 et 1.x. Mots-clés : Compilateur PyTorch 2.0 Machine Learning Cet article a été publié pour la première fois sur le compte officiel WeChat : HypeAI
Lors de la conférence PyTorch 2022, PyTorch a officiellement publié PyTorch 2.0. L'ensemble de l'événement a eu un taux de « compilation » très élevé. Par rapport à la version 1.x précédente, la version 2.0 a subi des changements « perturbateurs ».
PyTorch 2.0 a publié de nombreuses nouvelles fonctionnalités qui suffisent à changer la façon dont vous utilisez PyTorch.Il offre le même mode enthousiaste et la même expérience utilisateur, tout en ajoutant un mode de compilation via torch.compile.Le modèle peut être accéléré pendant la formation et l'inférence, offrant de meilleures performances et une meilleure prise en charge des formes dynamiques et distribuées.
Cet article fournira une introduction détaillée à PyTorch 2.0.
Trop long à lire
- PyTorch 2.0 conserve ses avantages d'origine tout en prenant grandement en charge la compilation
- torch.compile est une fonction facultative qui peut exécuter la compilation avec une seule ligne de code
- 4 technologies importantes : TorchDynamo, AOTAutograd, PrimTorch et TorchInductor
- J'ai essayé de le compiler il y a 5 ans, mais les résultats n'étaient pas satisfaisants.
- Le code PyTorch 1.x n'a pas besoin d'être migré vers la version 2.0* La version stable de PyTorch 2.0 devrait être publiée en mars de l'année prochaine
Support compilé plus rapide et meilleur
Lors de la conférence PyTorch 2022 d'hier soir,torch.compile a été officiellement publié.Il améliore encore les performances de PyTorch et commence à déplacer des parties de PyTorch de C++ vers Python.
Les dernières technologies de PyTorch 2.0 incluent :
TorchDynamo, AOTAutograd, PrimTorch et TorchInductor.
1. TorchDynamo
Il peut obtenir en toute sécurité des programmes PyTorch à l'aide de Python Frame Evaluation Hooks. Cette innovation majeure est un résumé des résultats de recherche et développement de PyTorch en matière de capture de graphes sécurisée au cours des cinq dernières années.
2. AOTAutograd
Surchargez le moteur autograd PyTorch en tant que traçage automatique pour générer des traces arrière avancées.
3. PrimTorch
Les plus de 2 000 opérateurs PyTorch sont résumés dans un ensemble fermé d'environ 250 opérateurs primitifs, et les développeurs peuvent créer un backend PyTorch complet pour ces opérateurs. PrimTorch simplifie considérablement le processus d'écriture de fonctions ou de backends PyTorch.
4. TorchInductor Un compilateur d'apprentissage en profondeur qui génère du code rapide pour plusieurs accélérateurs et backends. Pour les GPU NVIDIA, il utilise OpenAI Triton comme élément de base clé.
TorchDynamo, AOTAutograd, PrimTorch et TorchInductor sont écrits en Python.Et la prise en charge de la forme dynamique (la possibilité d'envoyer des vecteurs de différentes tailles sans recompilation) les rend flexibles et faciles à apprendre, abaissant la barrière d'entrée pour les développeurs et les fournisseurs.
Pour valider ces techniques,PyTorch utilise officiellement 163 modèles open source dans le domaine de l'apprentissage automatique.Il s’agit notamment de tâches telles que la classification d’images, la détection d’objets, la génération d’images et diverses tâches de PNL telles que la modélisation du langage, la réponse aux questions, la classification de séquences, les systèmes de recommandation et l’apprentissage par renforcement.Ces benchmarks sont divisés en trois catégories :
- 46 modèles de HuggingFace Transformers
- 61 modèles de TIMM : Collection de modèles d'images SoTA PyTorch par Ross Wightman
- 56 modèles de TorchBench : une collection de référentiels populaires sur GitHub.
Pour les modèles open source,PyTorch n'a officiellement apporté aucune modification, mais a ajouté un appel torch.compile pour l'encapsulation.
Ensuite, les ingénieurs de PyTorch ont mesuré la vitesse et vérifié la précision de ces modèles, car les accélérations peuvent dépendre du type de données.Par conséquent, l'accélération officielle a été mesurée à la fois sur float32 et sur la précision mixte automatique (AMP).Étant donné que l'AMP est plus courant dans la pratique, le ratio de test est défini sur : 0,75 * AMP + 0,25 * float32.
Parmi ces 163 modèles open source,torch.compile peut fonctionner normalement sur le modèle 93%.Après l'exécution, le modèle a obtenu une amélioration de 43% de la vitesse d'exécution sur le GPU NVIDIA A100. Avec la précision Float32, la vitesse de course est augmentée en moyenne de 21% ; sous la précision AMP, la vitesse de fonctionnement est augmentée en moyenne de 51%.
Remarque : sur les GPU de bureau (tels que le NVIDIA 3090), la vitesse mesurée sera inférieure à celle des GPU de serveur (tels que l'A100). À l'heure actuelle, le backend par défaut TorchInductor de PyTorch 2.0 prend déjà en charge le CPU et les GPU NVIDIA Volta et Ampere, mais ne prend actuellement pas en charge les autres GPU, xPU ou les anciens GPU NVIDIA.
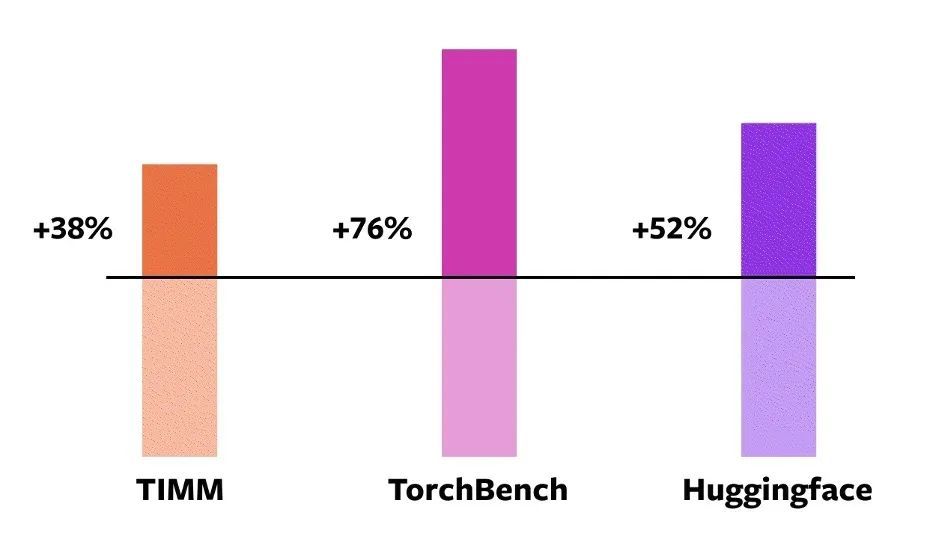 Accélération de la compilation torch.compile en mode enthousiaste du GPU NVIDIA A100 pour différents modèles
Accélération de la compilation torch.compile en mode enthousiaste du GPU NVIDIA A100 pour différents modèles
Essayez torch.compile en ligne :Les développeurs peuvent l'installer et l'essayer via le fichier binaire nocturne. La version stable de PyTorch 2.0 devrait être publiée début mars 2023.
Dans la feuille de route de PyTorch 2.x, les performances et l'évolutivité du mode compilé continueront d'être enrichies et améliorées à l'avenir.
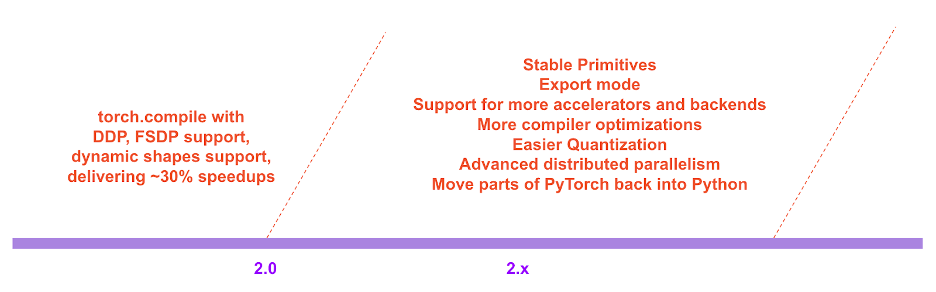 Feuille de route de PyTorch 2.x
Feuille de route de PyTorch 2.x
Contexte de développement
La philosophie de développement de PyTorch a toujours été de donner la priorité à la flexibilité et à la piratage, et la performance en second.Engagé à :
1. Exécution rapide et performante
2. Pythoniser en continu la structure interne
3. Bonne abstraction de la distribution, de l'autodiff, du chargement de données, des accélérateurs, etc.
Depuis l'introduction de PyTorch en 2017, les accélérateurs matériels (tels que les GPU) ont augmenté la vitesse de calcul d'environ 15 fois et la vitesse d'accès à la mémoire d'environ 2 fois.
Afin de maintenir une exécution rapide et performante, la plupart du contenu interne de PyTorch a dû être déplacé vers C++, ce qui a réduit la piratage de PyTorch et augmenté le seuil pour que les développeurs participent aux contributions de code.
Dès le premier jour, les responsables de PyTorch étaient conscients des limites de performance de l’exécution hâtive. En juillet 2017, les responsables ont commencé à travailler sur le développement d'un compilateur pour PyTorch. Le compilateur doit accélérer l’exécution des programmes PyTorch sans sacrifier l’expérience PyTorch.Le critère clé était de maintenir un certain degré de flexibilité : prendre en charge les formes dynamiques et les programmes dynamiques, qui sont largement utilisés par les développeurs.

Détails techniques de PyTorch
Depuis son lancement, plusieurs projets de compilateur ont été construits dans PyTorch.Ces compilateurs peuvent être divisés en 3 catégories :
- Acquisition de graphiques
- Graphique abaissant
- Compilation de graphiques
Parmi eux, l’acquisition de la structure des graphes est celle qui pose le plus de défis.
Au cours des cinq dernières années, nous avons essayé torch.jit.trace, TorchScript, FX tracing et Lazy Tensors, mais certains d'entre eux sont flexibles mais pas assez rapides, certains sont assez rapides mais pas flexibles, certains ne sont ni rapides ni flexibles, et certains ont une mauvaise expérience utilisateur.
Bien que TorchScript soit prometteur,Mais cela nécessite beaucoup de code et de modifications de dépendances, et n’est pas très faisable.
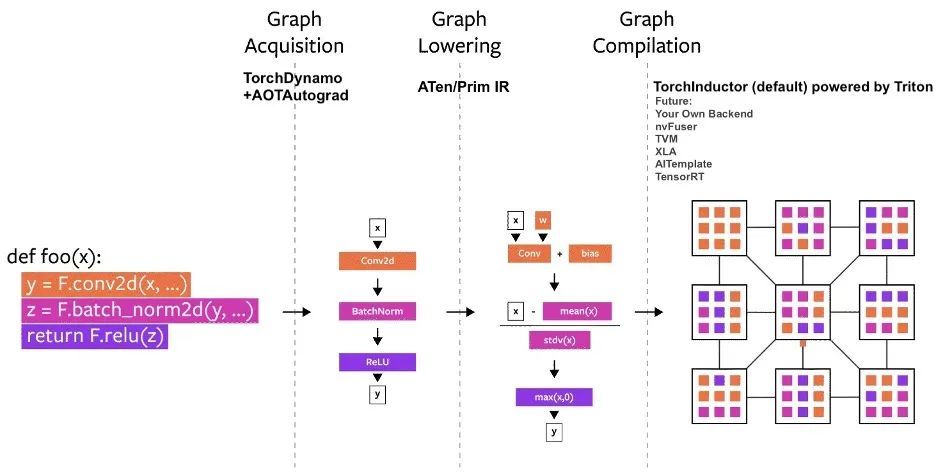 Diagramme du processus de compilation PyTorch
Diagramme du processus de compilation PyTorch
TorchDynamo : obtenir la structure d'un graphe de manière fiable et rapide
TorchDynamo utilise une fonctionnalité CPython introduite dans PEP-0523 appelée Frame Evaluation API. Le responsable a adopté une approche basée sur les données pour vérifier son efficacité sur Graph Capture, en utilisant plus de 7 000 projets Github écrits en PyTorch comme ensemble de validation.
Les expériences montrent queTorchDynamo peut obtenir correctement et en toute sécurité la structure du graphique en temps 99%, et la surcharge est négligeable.Parce qu'il ne nécessite aucune modification du code d'origine.
TorchInductor : génération de code plus rapide avec IR défini par exécution
De plus en plus de développeurs écrivent des noyaux personnalisés hautes performances.Peut utiliser le langage Triton.De plus, pour le nouveau compilateur backend de PyTorch 2.0, le responsable espère également utiliser des abstractions similaires à PyTorch eager, et avoir des performances générales suffisantes pour prendre en charge une large gamme de fonctions dans PyTorch.
TorchInductor utilise l'IR de niveau boucle Pythonic définie par exécution pour mapper automatiquement les modèles PyTorch au code Triton généré sur le GPU et C++/OpenMP sur le CPU.
Le niveau de boucle principal IR de TorchInductor ne contient qu'environ 50 opérateurs et est implémenté en Python, ce qui le rend hautement piratable et extensible.
AOTAutograd : Réutilisation d'Autograd pour les graphiques anticipés
PyTorch 2.0 vise à accélérer la formation en capturant non seulement le code au niveau utilisateur mais également l'algorithme de rétropropagation. Ce serait encore mieux si le système autograd PyTorch éprouvé pouvait être utilisé.
AOTAutograd utilise le mécanisme d'extension PyTorch torch_dispatch pour suivre le moteur Autograd.Permet aux développeurs de capturer les passes en arrière « à l'avance », permettant aux développeurs d'utiliser TorchInductor pour accélérer les passes en avant et en arrière.
PrimTorch : opérateurs primitifs stables
Écrire un backend pour PyTorch n'est pas facile. Torch compte plus de 1 200 opérateurs, et si vous prenez en compte les différentes surcharges de chaque opérateur, le nombre peut atteindre plus de 2 000.
 Aperçu de la classification des opérateurs PyTorch (plus de 2 000)
Aperçu de la classification des opérateurs PyTorch (plus de 2 000)
Par conséquent, l’écriture de fonctionnalités backend ou transversales devient une tâche chronophage. PrimTorch s'efforce de définir un ensemble d'opérateurs plus petit et plus stable. Les programmes PyTorch peuvent être systématiquement réduits à ces ensembles d’opérateurs. L'objectif officiel est de définir deux ensembles d'opérateurs :
* Prim ops contient environ 250 opérateurs de niveau relativement bas. Parce qu’ils sont suffisamment bas niveau, ces opérateurs sont plus adaptés aux compilateurs. Les développeurs doivent fusionner ces opérateurs pour obtenir de bonnes performances.
* ATen ops contient environ 750 opérateurs canoniques adaptés à la sortie directe. Ces opérateurs conviennent aux backends qui ont été intégrés au niveau ATen, ou aux backends qui n'ont pas été compilés pour récupérer les performances de l'ensemble d'opérateurs sous-jacent (tels que les opérations Prim).
FAQ
1. Comment installer PyTorch 2.0 ? Quelles sont les exigences supplémentaires ?
Installez les dernières versions nocturnes :
CUDA 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117CUDA 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116processeur
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu2. Le code PyTorch 2.0 est-il rétrocompatible avec 1.x ?
Oui, la version 2.0 ne nécessite pas de modification du workflow PyTorch, une seule ligne de code modèle = torch.compile(modèle)Vous pouvez ensuite optimiser votre modèle pour utiliser la pile 2.0 et l'exécuter en douceur avec d'autres codes PyTorch. Cette option n'est pas obligatoire et les développeurs peuvent toujours utiliser les versions précédentes.
3. PyTorch 2.0 est-il activé par défaut ?
Non, la version 2.0 doit être explicitement activée dans votre code PyTorch en optimisant le modèle avec un seul appel de fonction.
4. Comment migrer le code PT1.X vers PT2.0 ?
Le code précédent ne nécessite aucune migration. Si vous souhaitez utiliser la nouvelle fonctionnalité de mode compilé introduite dans la version 2.0, vous pouvez d'abord optimiser le modèle avec une ligne de code :modèle = torch.compile(modèle).
L’amélioration de la vitesse se reflète principalement dans le processus de formation. Si le modèle s'exécute plus rapidement que le mode impatient, cela signifie qu'il peut être utilisé pour l'inférence.
import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(\*\*input)5. Quelles fonctionnalités sont obsolètes dans PyTorch 2.0 ?
Actuellement, PyTorch 2.0 n'est pas encore stable et est toujours dans la version nightlies. La prise en charge des formes dynamiques dans torch.compile en est encore à ses débuts et n'est pas recommandée avant la version stable 2.0 en mars 2023.
C'est-à-dire que même pour les charges de travail de forme statique, elles sont toujours construites en mode compilé et certains bugs peuvent survenir. Pour la partie de votre code qui plante, veuillez désactiver le mode compilé et signaler un problème.
Portail de soumission de problèmes :https://github.com/pytorch/pytorch/issues
Ce qui précède est une introduction détaillée à PyTorch 2.0. Nous compléterons l’introduction de PyTorch 2.0 Get Started à l’avenir. S'il vous plaît continuez à nous suivre!
Vous pouvez également rechercher Hyperai01 sur WeChat et rejoindre la discussion du groupe de développement technologique PyTorch avec Neural Star.








