Command Palette
Search for a command to run...
Instructions d'utilisation De La Nouvelle Bibliothèque TorchMultimodal De PyTorch : Étendre Le Modèle Général Multimodal FLAVA À 10 Milliards De Paramètres

Dans l’article précédent, nous avons présenté TorchMultimodal. Aujourd'hui, nous partirons d'un cas spécifique pour démontrer comment étendre le modèle de base multimodal de la bibliothèque TorchMultimodal avec le support de la technologie Torch Distributed.
Ces dernières années, les grands modèles sont devenus un domaine de recherche qui a suscité beaucoup d’attention. Prenons l’exemple du traitement du langage naturel : les modèles de langage sont passés de centaines de millions de paramètres (BERT) à des centaines de milliards de paramètres (GPT-3), jouant un rôle important dans l’amélioration des performances des tâches en aval.
Des recherches approfondies ont été menées dans le secteur sur la manière de faire évoluer les modèles linguistiques à grande échelle. Une tendance similaire peut être observée dans le domaine de la vision, avec de plus en plus de développeurs se tournant vers des modèles basés sur des transformateurs (tels que Vision Transformer et Masked Auto Encoders).
De toute évidence, en raison du développement de modèles à grande échelle, la recherche sur une modalité unique (comme le texte, l’image, la vidéo) a été continuellement améliorée, et les cadres se sont également rapidement adaptés à des modèles plus grands.
Parallèlement, avec les applications concrètes de tâches telles que la récupération d’images et de textes, la réponse visuelle aux questions, le dialogue visuel et la génération de texte en image, la multimodalité a reçu une attention croissante.
L’étape suivante consiste à former des modèles multimodaux à grande échelle. Des efforts ont également été déployés dans ce domaine, comme CLIP d'OpenAI, Parti de Google et CM3 de Meta.
Cet article montrera comment faire évoluer FLAVA jusqu'à 10 milliards de paramètres à l'aide de la technologie PyTorch Distributed à travers une étude de cas.
Lectures complémentaires :HyperAI : un aperçu des outils FX utilisés par Meta : Optimisation des modèles PyTorch avec la transformation graphique
modifier
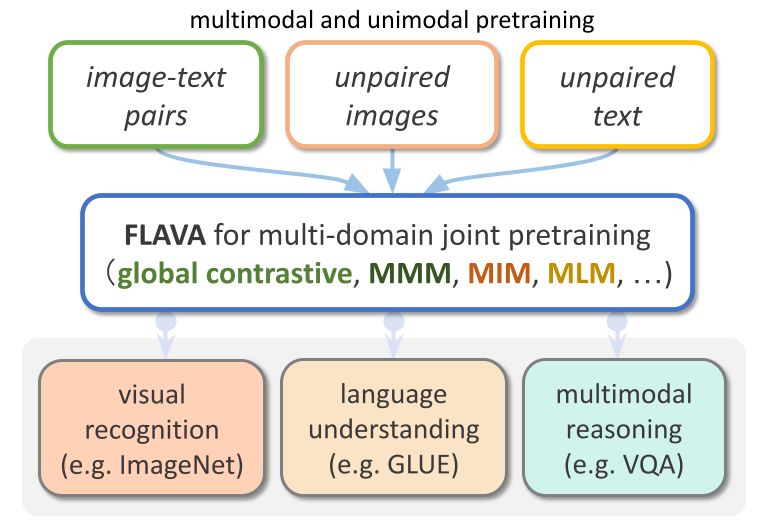
FLAVA est un modèle basé sur la vision et le langage disponible dans TorchMultimodal
FLAVA a montré des avantages de performance exceptionnels dans les tests de performance monomodaux et multimodaux. Cet article montrera comment étendre FLAVA avec des exemples de code pertinents.
Voir le code pour plus de détails :
multimodal/exemples/flava/native sur main · facebookresearch/multimodal · GitHub
Présentation de l'extension FLAVA
FLAVA est un modèle multimodal de base composé d'encodeurs d'images et de texte basés sur des transformateurs et d'un module de fusion multimodal basé sur des transformateurs.
FLAVA est pré-entraîné sur des données unimodales et multimodales avec différentes pertes, notamment des pertes de langage masqué, d'image et de modèle multimodal qui nécessitent que le modèle reconstruise l'entrée d'origine à partir de son contexte (apprentissage auto-supervisé).
De plus, il utilise une perte de correspondance de texte d'image, y compris des exemples positifs et négatifs de paires image-texte alignées, et une perte de contraste de style CLIP.
En plus des tâches multimodales (telles que la récupération d'images et de textes), FLAVA montre également d'excellentes performances sur les tests unimodaux (tels que les tâches GLUE en PNL et la classification d'images visuelles).
modifier
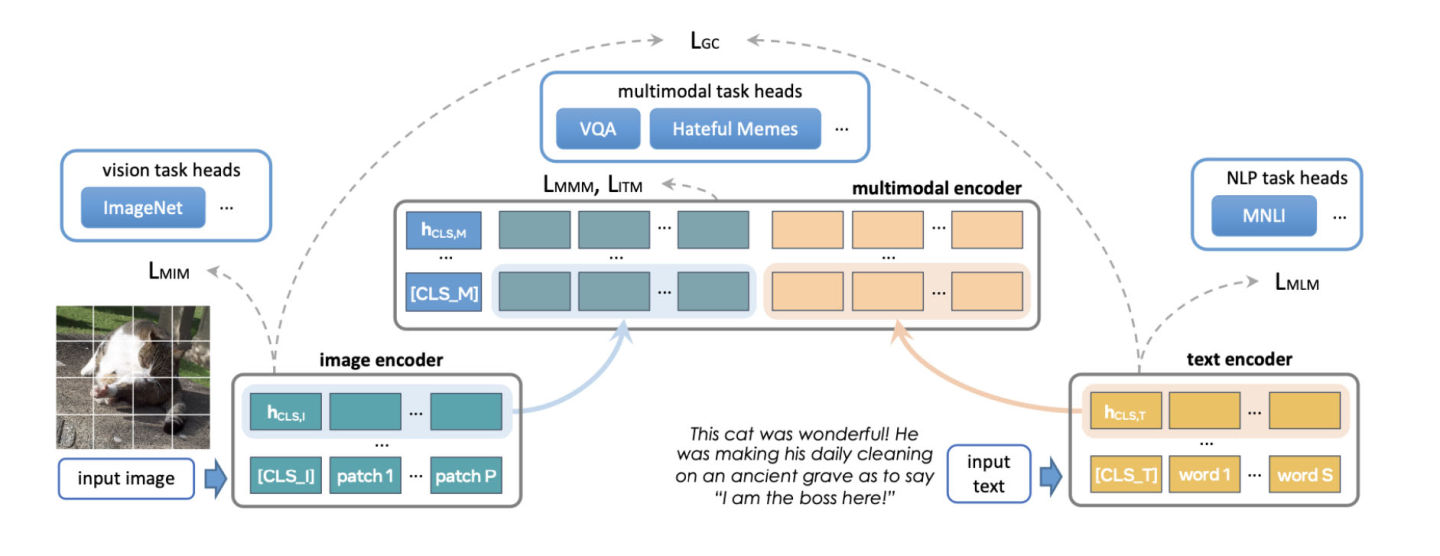
Le modèle FLAVA original comportait environ 350 millions de paramètres et utilisait la configuration ViT-B16 pour les encodeurs d'image et de texte.
Référence:https://arxiv.org/pdf/2010.11929.pdf
Le transformateur de fusion multimodal utilise le même encodeur monomodal, mais le nombre de couches n'est que la moitié du précédent. L'équipe de développement de PyTorch a étudié la possibilité d'augmenter la taille de l'encodeur pour s'adapter à des variantes ViT plus grandes.
Un autre aspect de la mise à l’échelle de FLAVA est d’augmenter la taille du lot. FLAVA exploite intelligemment la perte de contraste négative par lot, qui n'est généralement disponible que dans un grand nombre de tailles.
Référence:https://openreview.net/pdfid=U2exBrf_SJh
En général, l'efficacité ou le débit de formation maximal est atteint lorsque l'on fonctionne à proximité de la plus grande taille de lot possible, qui est déterminée par la quantité de mémoire GPU disponible (voir la section Expériences).
Le tableau suivant illustre la sortie de différentes configurations de modèles, où nous avons déterminé expérimentalement la taille de lot maximale pouvant tenir dans la mémoire pour chaque configuration.

modifier
Présentation de l'optimisation
PyTorch fournit plusieurs techniques natives pour mettre à l'échelle efficacement les modèles. Les sections suivantes décrivent les trois approches en détail et montrent comment appliquer ces techniques pour faire évoluer le modèle FLAVA à 10 milliards de paramètres.
Parallélisme des données distribuées
Un point de départ courant pour la formation distribuée est le parallélisme des données. Le parallélisme des données réplique le modèle entre les GPU et partitionne l'ensemble de données. Différents GPU traitent différentes partitions de données en parallèle et synchronisent leurs gradients (via la réduction globale) avant que les poids du modèle ne soient mis à jour.
La figure suivante montre le processus de traitement d'un parallèle de données (itération vers l'avant, itération vers l'arrière et étape de mise à jour du poids) :

modifier
Pour obtenir le parallélisme des données, PyTorch fournit une API native, DistributedDataParallel (DDP), qui peut être utilisée comme wrapper de module comme indiqué ci-dessous :
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])Parallélisme de données entièrement fragmenté
L'utilisation de la mémoire GPU d'une application de formation peut être grossièrement décomposée en entrée de modèle, stockage d'activation intermédiaire (nécessaire pour les calculs de gradient), paramètres de modèle, gradients et état de l'optimiseur.
Lors de l’extension d’un modèle, ces éléments sont généralement ajoutés ensemble. Lorsqu'un seul GPU manque de mémoire, la mise à l'échelle du modèle à l'aide de DDP peut entraîner une pénurie de mémoire, car il réplique les paramètres, les gradients et les états de l'optimiseur sur tous les GPU.
Pour réduire cette copie et économiser la mémoire GPU, les paramètres du modèle, les gradients et l'état de l'optimiseur peuvent être répartis sur tous les GPU, chaque GPU ne gérant qu'un seul fragment. Cette méthode fait référence à ZeRO-3 proposé par Microsoft.
Une implémentation native de PyTorch de cette approche est disponible sous la forme de l'API FullyShardedDataParallel (FSDP), qui a été publiée en tant que fonctionnalité bêta dans PyTorch 1.12.
Au cours des itérations avant et arrière du module, FSDP intègre les paramètres du modèle (en utilisant all-gather) en fonction des besoins de calcul et les repartage après le calcul. Il utilise un ensemble de réduction de dispersion pour synchroniser les gradients afin de garantir que les gradients des fragments sont globalement moyennés. Les processus d'itération avant et arrière du modèle dans FSDP sont les suivants :

modifier
Lorsque vous utilisez FSDP, vous devez encapsuler les sous-modules du modèle avec une API pour contrôler quand un sous-module spécifique est fragmenté ou non. FSDP fournit une API d'encapsulation automatique prête à l'emploi, plusieurs politiques d'encapsulation et la possibilité d'écrire des politiques.
L'exemple suivant montre comment encapsuler un modèle FLAVA avec FSDP. Spécifiez la politique d'encapsulation automatique : transformer_auto_wrap_policy . Cela encapsulera une seule couche de transformateur (TransformerEncoderLayer), un transformateur d'image (ImageTransformer), un encodeur de texte (BERTTextEncoder) et un encodeur multimodal (FLAVATransformerWithoutEmbeddings) dans une seule unité FSDP.
Cela utilise une approche d’encapsulation récursive pour une gestion efficace de la mémoire. Par exemple, une fois l’itération avant ou arrière d’une seule couche de transformateur terminée, les paramètres sont supprimés, libérant ainsi de la mémoire et réduisant l’utilisation maximale de la mémoire.
FSDP fournit également certaines options configurables pour optimiser les performances de l'application, comme l'utilisation de limit_all_gathers dans cet exemple. Il empêche la collecte prématurée de tous les paramètres du modèle et réduit la pression mémoire sur l'application.
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)point de contrôle d'activation
Comme mentionné ci-dessus, le stockage d'activation intermédiaire, les paramètres du modèle, les gradients et l'état de l'optimiseur affectent l'utilisation de la mémoire GPU. FSDP peut réduire la consommation de mémoire causée par les trois derniers, mais ne peut pas réduire la mémoire consommée par l'activation. La mémoire utilisée par les activations augmente avec la taille du lot ou le nombre de couches cachées.
Le point de contrôle d'activation réduit l'utilisation de la mémoire en recalculant les activations pendant les itérations arrière au lieu de les conserver en mémoire dans le module de point de contrôle spécifique.
Par exemple, en appliquant le point de contrôle d’activation au modèle de 2,7 milliards de paramètres, la mémoire active maximale après une itération vers l’avant a été réduite d’un facteur 4.
PyTorch fournit une API de point de contrôle d'activation basée sur un wrapper. Et checkpoint_wrapper permet aux utilisateurs d'encapsuler un seul module avec check, et apply_activation_checkpointing permet aux utilisateurs de spécifier une stratégie pour encapsuler le module avec checkpointing dans l'ensemble du module.
Ces deux API peuvent être appliquées à la plupart des modèles car elles ne nécessitent aucune modification du code de définition du modèle.
Cependant, si vous avez besoin d'un contrôle plus précis sur les segments contrôlés, comme le contrôle de fonctionnalités spécifiques au sein d'un module, vous pouvez utiliser l'API torch.utils.checkpoint, qui nécessite la modification du code du modèle.
L'application du wrapper de point de contrôle d'activation à une seule couche de transformateur FLAVA (désignée par TransformerEncoderLayer) est illustrée ci-dessous :
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
Comme indiqué ci-dessus, l'enveloppement de la couche de transformation FLAVA avec des points de contrôle d'activation et le modèle global avec FSDP permet de mettre à l'échelle FLAVA à 10 milliards de paramètres.
expérience
Pour les différentes méthodes d’optimisation mentionnées ci-dessus, nous expérimenterons davantage leur impact sur les performances du système.
Arrière-plan:
- Utilisation d'un seul nœud avec 8 GPU A100 40 Go
- Exécutez 1 000 itérations de pré-entraînement
- Entraînement de précision mixte PyTorch utilisant le type de données bfloat16 (précision mixte automatique)
- Activer le format TensorFloat32 pour améliorer les performances de Matmul sur A100
- Définir le débit comme le nombre moyen d'éléments traités par seconde (ignorer les 100 premières itérations lors de la mesure du débit)
- La convergence de la formation et son impact sur les indicateurs de tâches en aval serviront de nouvelle direction pour les recherches futures.
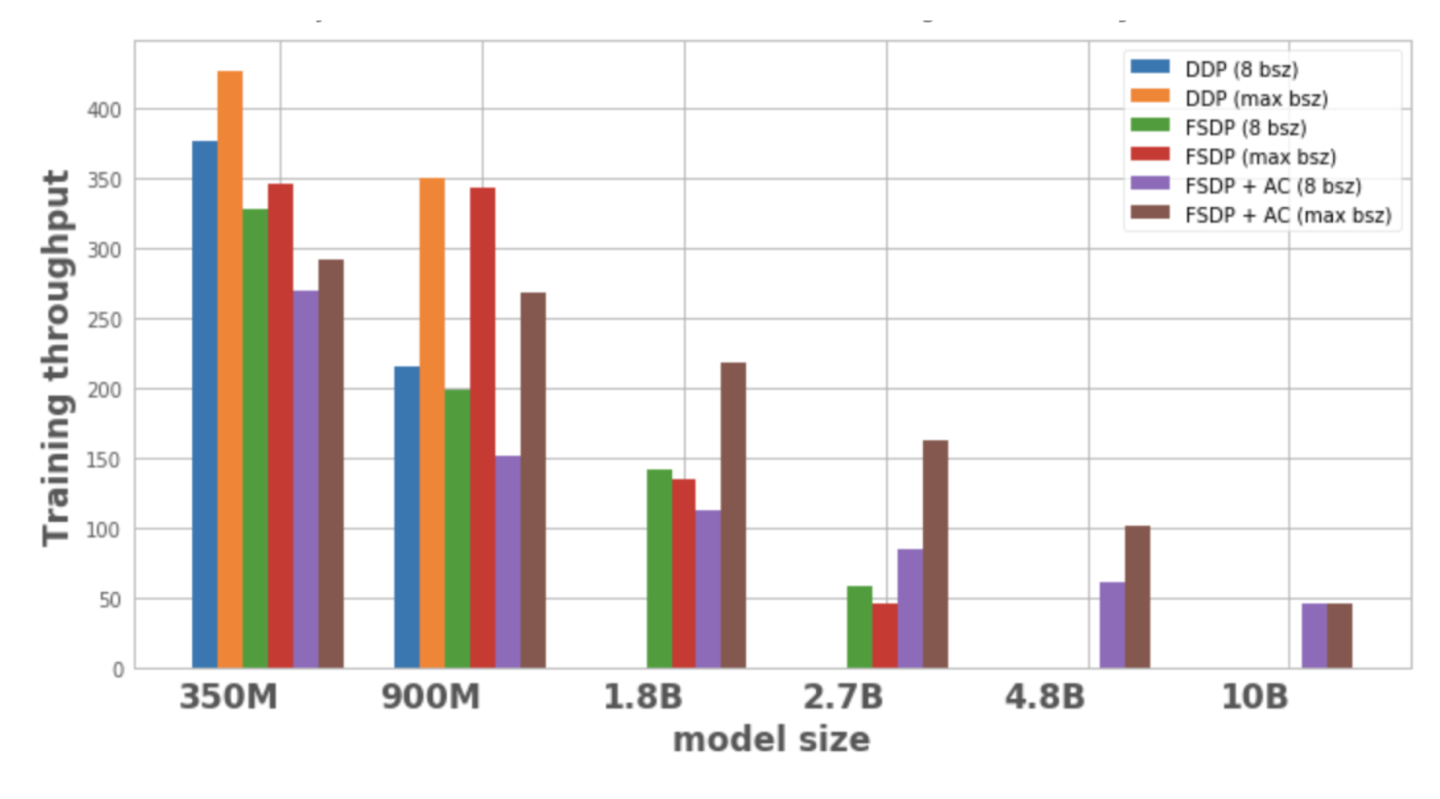
La figure 1 montre le débit pour chaque configuration et optimisation de modèle, avec une taille de lot locale de 8, la taille de lot maximale possible sur 1 nœud. La variante de modèle optimisée ne comporte aucun point de données, ce qui indique que le modèle ne peut pas être formé sur un seul nœud.
modifier
Figure 1 : Débit d'entraînement sous différentes configurations
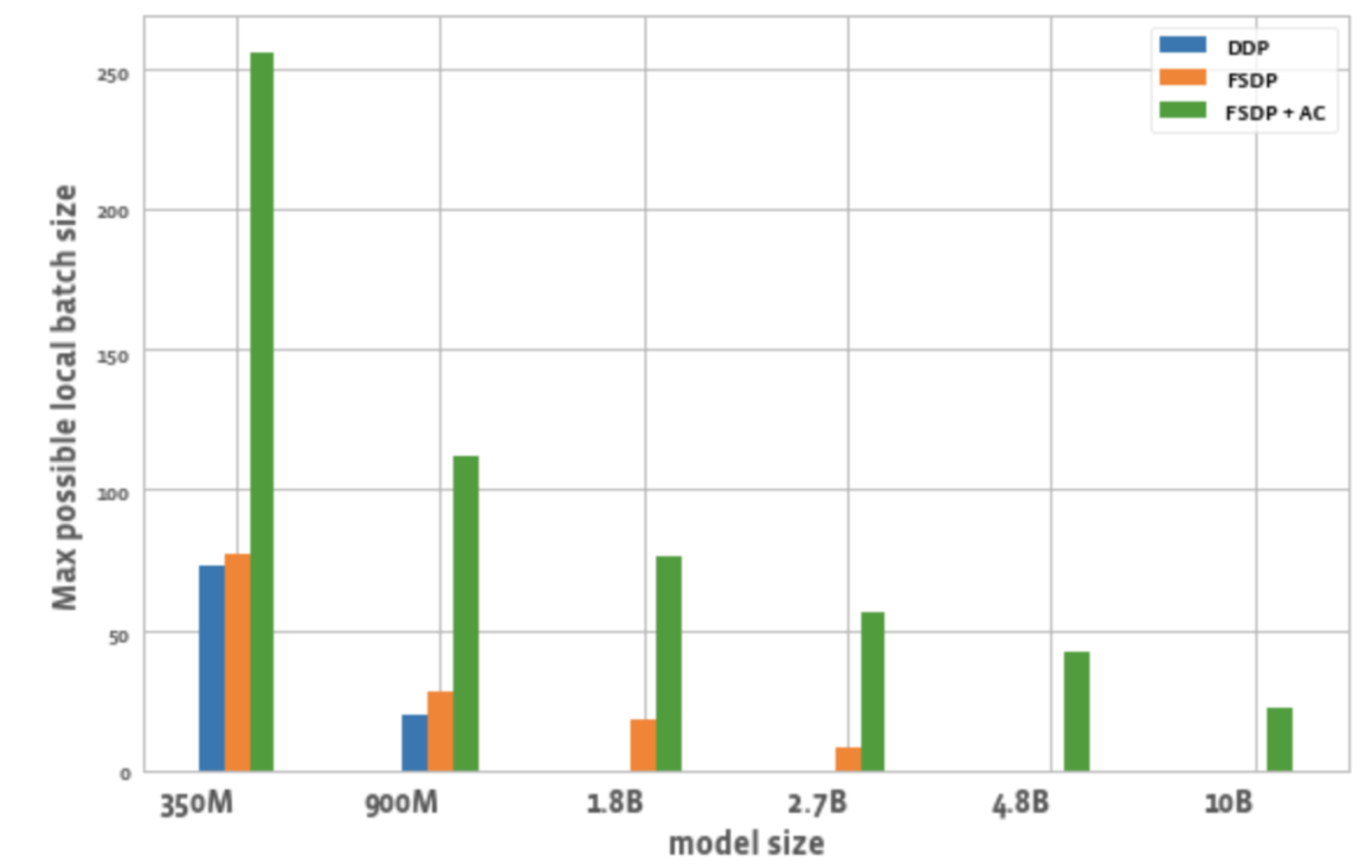
La figure 2 montre la taille de lot maximale possible pour tous les GPU dans chaque optimisation.
modifier
Figure 2 : Taille maximale possible du lot local sous différentes configurations
De cela, nous pouvons observer :
1. Élargissez la taille du modèle :
DDP ne peut accueillir que les modèles 350M et 900M sur un seul nœud. L'utilisation de FSDP permet d'économiser de la mémoire, il est donc possible de former des modèles 3 fois plus grands que DDP (c'est-à-dire 1,8 B et 2,7 B variantes). La combinaison du point de contrôle d'activation (AC) avec FSDP permet de former des modèles plus grands, environ 10 fois plus grands que DDP (comme les variantes 4.8B et 10B).
2. Débit :
– Pour les modèles plus petits, lorsque la taille du lot est de 8, le débit de DDP est légèrement supérieur ou égal à celui de FSDP, ce qui peut s’expliquer par la communication supplémentaire requise par FSDP. La combinaison de FSDP et AC a le débit le plus faible. Cela est dû au fait qu'AC réexécute le canal d'itération avant pointé pendant le processus d'itération arrière, sacrifiant ainsi des calculs supplémentaires pour économiser de la mémoire. Cependant, pour le modèle 2,7B, FSDP + AC a en fait un débit plus élevé que FSDP seul. Cela est dû au fait que le modèle 2,7 B avec FSDP est proche de la limite de mémoire même avec une taille de lot de 8, ce qui déclenche une nouvelle tentative de malloc CUDA, ce qui ralentit la formation. AC aide à réduire la pression de la mémoire qui entraîne l'absence de nouvelle tentative.
– Pour DDP et FSDP + AC, le débit du modèle augmente avec l’augmentation de la taille du lot. Il en va de même pour les variantes plus petites du FSDP. Cependant, pour les modèles de paramètres 1,8B et 2,7B, le débit diminue lorsque la taille du lot augmente. Une raison potentielle est qu'aux limites de la mémoire, la gestion de la mémoire CUDA de PyTorch peut devoir réessayer les appels cudaMalloc ou exécuter une défragmentation coûteuse pour trouver des blocs de mémoire libres pour gérer les besoins de mémoire de la charge de travail, ce qui peut entraîner une formation plus lente.
– Pour les modèles de grande taille (1,8 B, 2,7 B, 4,8 B) qui ne peuvent être formés qu’avec FSDP, le paramètre de débit le plus élevé consiste à passer à la plus grande taille de lot avec FSDP+AC. Pour 10B, on peut observer que le débit pour les tailles de lots petites et maximales est presque égal. Cela est dû au fait que l'AC entraîne un effort de calcul accru et que la taille maximale du lot peut entraîner des opérations de défragmentation coûteuses en raison de l'exécution sous les limites de mémoire CUDA. Cependant, pour ces grands modèles, l’augmentation de la taille du lot compense largement cette surcharge.
3. Taille du lot :
Comparé au DDP, le FSDP seul peut atteindre des tailles de lots légèrement supérieures. Pour le modèle de paramètres 350M, l'utilisation de FSDP+AC peut atteindre une taille de lot 3 fois supérieure à celle du DDP, et pour le modèle de paramètres 900M, elle peut atteindre une taille de lot 5,5 fois supérieure. Même avec 10B, la taille maximale du lot est d'environ 20, ce qui est plutôt bien. FSDP+AC peut essentiellement atteindre une taille de lot globale plus grande avec moins de GPU, ce qui est particulièrement efficace pour les tâches d'apprentissage contrastives.
en conclusion
Avec le développement de modèles de base multimodaux, la mise à l’échelle des paramètres du modèle et la formation efficace deviennent un domaine clé. L'écosystème PyTorch vise à accélérer la formation et la mise à l'échelle de modèles multimodaux en fournissant différents outils.
À l’avenir, PyTorch ajoutera la prise en charge d’autres types de modèles, tels que les modèles génératifs multimodaux, et améliorera l’automatisation des technologies associées. Bienvenue à tous pour continuer à suivre le compte officiel de la communauté des développeurs PyTorch. Vous pouvez également scanner le code QR et noter « PyTorch » pour rejoindre la communauté PyTorch.

Blog officiel de PyTorch, tutoriels
Derniers développements et meilleures pratiques
Scannez le code QR pour rejoindre le groupe de discussion








