Command Palette
Search for a command to run...
La Bibliothèque Officielle PyTorch « nouvelle », TorchMultimodal, Aide l'intelligence Artificielle Multimodale
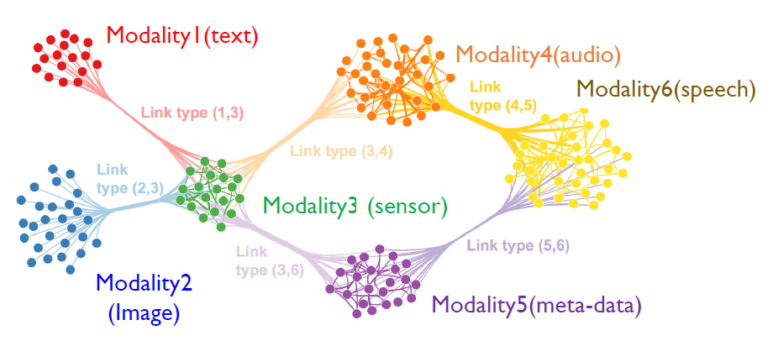
L'intelligence artificielle multimodale est un nouveau paradigme d'IA qui fait référence à plusieurs types de données tels que des images, du texte, de la voix et de la vidéo, combinés à plusieurs algorithmes de traitement intelligents pour obtenir des performances supérieures.
Récemment, PyTorch a officiellement publié une bibliothèque de domaine : TorchMultimodal.Formation à grande échelle de modèles multitâches et multimodaux pour SoTA.
La bibliothèque propose :
- Blocs de construction composables (module, transformations, fonction de perte) pour accélérer le développement de modèles
- Architecture du modèle SoTA extraite de scripts de recherche, de formation et d'évaluation publiés (FLAVA, MDETR, Omnivore)
- Des cahiers pour tester ces modèles
La bibliothèque TorchMultimodal est toujours en cours de développement actif, veuillez prêter attention à :
https://github.com/facebookresearch/multimodal#installation
Contexte du développement multimodal de Torch
À mesure que la technologie progresse, les modèles d’IA capables de comprendre plusieurs types d’entrées (texte, images, vidéos et signaux audio) et d’utiliser cette compréhension pour générer différentes formes de sorties (phrases, images, vidéos) suscitent de plus en plus d’attention.
Des travaux récents de FAIR (tels que FLAVA, Omnivore et data2vec) ont montré queLes modèles multimodaux de compréhension se comparent favorablement aux modèles unimodaux et, dans certains cas, établissent de nouvelles normes SOTA.
Les modèles génératifs tels que Make-a-video et Make-a-scene redéfinissent les capacités des systèmes d’intelligence artificielle modernes.
Promouvoir le développement de l'IA multimodale dans l'écosystème PyTorch, La bibliothèque TorchMultimodal a vu le jour et sa solution est :
- Fournit des blocs de construction composables, Grâce à ces éléments de base, les chercheurs peuvent accélérer le développement et l’expérimentation de modèles dans leurs propres flux de travail. La conception modulaire réduit également la difficulté de migration vers de nouvelles données modales.
- Fournit des exemples de bout en bout pour la formation et l’évaluation de modèles de pointe issus de la recherche. Ces exemples utilisent certaines fonctionnalités avancées telles que le FSDP intégré et le point de contrôle d'activation pour la mise à l'échelle des tailles de modèle et de lot.
Premier aperçu de TorchMultimodal
TorchMultimodal est une bibliothèque de domaine PyTorch.Pour la formation à grande échelle de modèles multimodaux multitâches. Il fournit :
1. Bloc de construction
Les modules sont des collections de blocs de construction composables tels que des modèles, des couches d'ensemble, des fonctions de perte, des ensembles de données et des utilitaires, par exemple :
- Perte de contraste avec la température : Fonctions couramment utilisées pour les modèles de formation, telles que CLIP et FLAVA. Il inclut également des variables telles que ImageTextContrastiveLoss utilisées dans des modèles tels que ALBEF.
- Couche du livre de codes : La compression de données de grande dimension via la recherche du voisin le plus proche dans l'espace vectoriel est également un élément important de VQVAE.
- Fenêtre décalée Attention : La fenêtre est basée sur l'auto-attention multi-têtes et constitue un composant important des encodeurs tels que Swin 3D Transformer.
- Composants CLIP : Publié par OpenAI, c'est un modèle très efficace pour l'apprentissage des représentations de texte et d'images.
- GPT multimodal : Associée à un générateur, l’architecture GPT d’OpenAI peut être étendue à une abstraction plus adaptée à la génération multimodale.
- MultiHeadAttention : Un composant clé des modèles basés sur l’attention qui prend en charge l’auto-régression et le décodage.
2. Exemple
Un ensemble d'exemples montre comment combiner les blocs de construction avec les composants PyTorch et l'infrastructure publique (Lightning, TorchMetrics) pour reproduire les modèles SOTA publiés dans la littérature. Il existe actuellement cinq exemples fournis, notamment :
- FLAVEUR : Code officiel des articles acceptés par le CVPR, y compris un tutoriel sur le réglage fin de FLAVA.
Voir le document :https://arxiv.org/abs/2112.04482
- MDETR : Collaborer avec les auteurs de NYU pour fournir un exemple qui atténue les problèmes d'interopérabilité dans l'écosystème PyTorch, y compris un bloc-notes pour la mise à la terre des phrases et la réponse visuelle aux questions à l'aide de MDETR.
Voir le document :https://arxiv.org/abs/2104.12763
- Omnivore : Premier exemple de modèle dans TorchMultimodal pour le traitement de données vidéo et 3D, incluant des notebooks pour explorer le modèle.
Voir le document :https://arxiv.org/abs/2204.08058
- MUGEN : Travaux fondamentaux sur la génération et la récupération auto-régressives, y compris une démonstration pour la génération et la récupération de texte-vidéo à l'aide du riche ensemble de données synthétiques à grande échelle d'OpenAI coinrun.
Voir le document :https://arxiv.org/abs/2204.08058
- ALBEF : Code modèle, y compris un bloc-notes permettant d'utiliser le modèle pour résoudre un problème de réponse visuelle aux questions.
Voir le document :https://arxiv.org/abs/2107.07651
Le code suivant montre l'utilisation de plusieurs composants TorchMultimodal liés à CLIP :
# instantiate clip transform
clip_transform = CLIPTransform()
# pass the transform to your dataset. Here we use coco captions
dataset = CocoCaptions(root= ..., annFile=..., transforms=clip_transform)
dataloader = DataLoader(dataset, batch_size=16)
# instantiate model. Here we use clip with vit-L as the image encoder
model= clip_vit_l14()
# define loss and other things needed for training
clip_loss = ContrastiveLossWithTemperature()
optim = torch.optim.AdamW(model.parameters(), lr = 1e-5)
epochs = 1
# write your train loop
for _ in range(epochs):
for batch_idx, batch in enumerate(dataloader):
image, text = batch
image_embeddings, text_embeddings = model(image, text)
loss = contrastive_loss_with_temperature(image_embeddings, text_embeddings)
loss.backward()
optimizer.step()Installer TorchMultimodal
Python ≥ 3.7, avec ou sans support CUDA installé.
Le code suivant prend l'installation de conda comme exemple
Prérequis
1. Installer l'environnement conda
conda create -n torch-multimodal python=\<python_version\>
conda activate torch-multimodal2. Installez PyTorch, torchvision et torchtext
Voir la documentation de PyTorch :
https://pytorch.org/get-started/locally/
# Use the current CUDA version as seen [here](https://pytorch.org/get-started/locally/)
# Select the nightly Pytorch build, Linux as the OS, and conda. Pick the most recent CUDA version.
conda install pytorch torchvision torchtext pytorch-cuda=\<cuda_version\> -c pytorch-nightly -c nvidia
# For CPU-only install
conda install pytorch torchvision torchtext cpuonly -c pytorch-nightlyInstaller à partir d'un fichier binaire
Sous Linux, les binaires nocturnes pour Python 3.7, 3.8 et 3.9 sont disponibles via pip wheels. Actuellement, seules les plates-formes Linux sont prises en charge via PyPI.
python -m pip install torchmultimodal-nightlyInstallation de la source
Les développeurs peuvent également créer et exécuter les exemples à partir de la source :
git clone --recursive https://github.com/facebookresearch/multimodal.git multimodal
cd multimodal
pip install -e .Ce qui précède est une brève introduction à TorchMultimodal. En plus du code,PyTorch a officiellement publié un tutoriel de base sur le réglage fin des modèles multimodaux. Et un blog sur la façon de faire évoluer ces modèles à l'aide des techniques PyTorch Distributed PyTorch (FSDP et point de contrôle d'activation).
Nous traduirons ce blog en chinois plus tard. Bienvenue pour continuer à suivre le compte officiel de la communauté des développeurs PyTorch !
-- sur--








