Command Palette
Search for a command to run...
Correction Des Fautes De Frappe | Déployer 1 Modèle De Correction Orthographique De Texte Chinois
Aperçu du contenu : L’un des types d’erreurs de texte chinois est l’orthographe. Cet article est un didacticiel de déploiement de modèle pour la mise en œuvre de la correction d'erreurs de texte chinois à l'aide de la méthode de pré-formation BART.
Mots-clés : BART, correction orthographique chinoise, PNL
Cet article a été publié pour la première fois sur le compte officiel de WeChat : HyperAI
3 obstacles majeurs aux erreurs de texte chinois : l'orthographe, la grammaire et la sémantique
La correction des erreurs de texte chinois est une branche importante dans le domaine actuel du traitement du langage naturel, qui vise à détecter et à corriger les erreurs de texte chinois.Les erreurs courantes dans les textes chinois comprennent les erreurs d’orthographe, les erreurs grammaticales et les erreurs sémantiques.
1. Erreurs d'orthographe :
Désigne l'utilisation incorrecte de mots ou de phrases en raison des méthodes de saisie, des logiciels de conversion de la parole en texte, etc., se manifestant principalement par l'utilisation incorrecte d'homophones, de caractères similaires, de sons mixtes, etc., tels que « 天气晴郎 – 天气晴 » et « 时侯 – 当时 ».
2. Erreur de syntaxe :
Désigne une collocation de mots manquante, redondante, désordonnée ou incorrecte en raison des méthodes de saisie, d'une écriture manuscrite négligée, d'une reconnaissance OCR désordonnée, etc., comme par exemple « L'humilité fait progresser les gens - L'humilité fait progresser les gens. »
3. Erreur sémantique :
Connaissances et erreurs logiques causées par un manque de compréhension de certaines connaissances ou par un manque de compétences en organisation de la langue, comme « il y a 3 trimestres dans une année - il y a 4 trimestres dans une année ».
Dans cet article, nous utiliserons les fautes d’orthographe les plus courantes comme exemples.Démontrer comment déployer un modèle de correction d’erreurs de texte chinois à l’aide du modèle BART.
Pour exécuter le tutoriel directement, veuillez visiter :
BART : Un modèle SOTA qui s'appuie sur les forces de nombreux
BART signifie Transformateurs Bidirectionnels et Auto-Régressifs.Il s'agit d'un autoencodeur de débruitage conçu pour les modèles seq2seq de pré-formation. Adapté aux tâches de génération, de traduction et de compréhension du langage naturel, proposé par Meta (anciennement Facebook) en 2019.
Pour plus de détails, veuillez visiter :
https://arxiv.org/pdf/1910.13461.pdf
Le modèle BART s'appuie sur les avantages de BERT et de GPT et utilise la structure standard du transformateur comme base :
- Référence du module décodeur GPT : Remplacez la fonction d'activation ReLU par la fonction d'activation GeLU
- Le module codeur est différent de BERT : Le module de réseau neuronal à propagation directe a été abandonné et les paramètres du modèle ont été simplifiés.
- La partie connexion du codec fait référence à Transformer : Chaque couche du décodeur doit effectuer des calculs d'attention croisée sur les informations de sortie de la dernière couche de l'encodeur (c'est-à-dire le mécanisme d'attention encodeur-décodeur)

Dans ce tutoriel,Nous utilisons le modèle nlp_bart_text-error-correction_chinese pour le déploiement du modèle.
Pour plus d'informations, visitez :
Détails du tutoriel : Créer une démonstration de correction de texte en ligne
Préparation de l'environnement
Exécutez la commande suivante dans le terminal Jupyter pour installer les dépendances :
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install fairseqTéléchargement du modèle
Exécutez la commande suivante dans le terminal pour télécharger le modèle :
git clone http://www.modelscope.cn/damo/nlp_bart_text-error-correction_chinese.gitLe téléchargement du modèle prend beaucoup de temps. Le modèle a été téléchargé dans ce conteneur et peut être utilisé directement. nlp_bart_text-error-correction_chinese annuaire.
Utilisation rapide
Déploiement du modèle
Service de rédaction de services
écrire predictor.py document:
- Importer des bibliothèques dépendantes : en plus des bibliothèques utilisées dans l'entreprise, vous devez également dépendre d'openbayes-serving.
import openbayes_serving as serv
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks- Classe de prédicteur : pas besoin d’hériter d’autres classes, au moins fournir init Et prédire les interfaces.
- exister
__init__Spécifiez le chemin du modèle dans le modèle de chargement - exister
predictEffectuer une inférence et renvoyer le résultat
class Predictor:
def __init__(self):
self.model_path = './nlp_bart_text-error-correction_chinese'
self.corrector = pipeline(Tasks.text_error_correction, model=self.model_path)
def predict(self, json):
text = json["input"].lower()
result = self.corrector(text)
return result- Exécuter : démarrer le service
if __name__ == '__main__':
serv.run(Predictor)test
Exécuter dans le terminal python predictor.pyAprès avoir démarré le service avec succès, exécutez le code suivant dans ce bloc-notes à des fins de test.
Remarque : lors des tests dans un conteneur, si la version du flacon est supérieure à 2.1, des erreurs d'enregistrement en double peuvent se produire. Vous pouvez l'exécuter en réduisant la version.
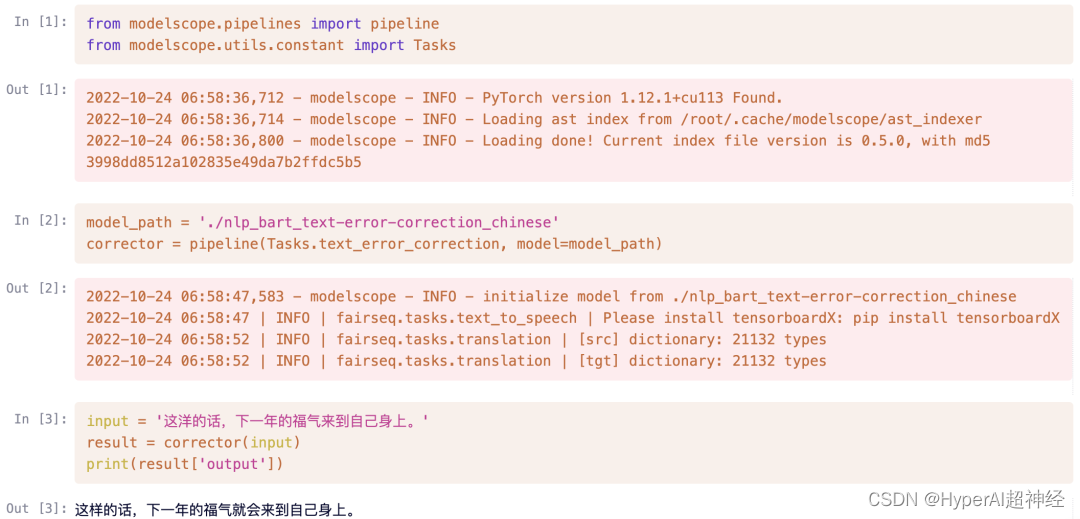
import requests
text = {"input": "这洋的话,下一年的福气来到自己身上。"}
result = requests.post('http://localhost:8080', json=text)
result.json()
{'output': '这样的话,下一年的福气就会来到自己身上。'}En plus d'accéder à l'adresse localement http://localhost:8080,Vous pouvez également le tester via une URL accessible en externe demandée dans le terminal.

Remarque : pour différents conteneurs de puissance de calcul OpenBayes, l’URL accessible en externe est différente. L'utilisation directe du lien dans ce tutoriel n'est pas valide. Vous devez le remplacer par le lien demandé dans le terminal..
result = requests.post('https://openbayes.com/jobs-auxiliary/open-tutorials/t23g93jjm95d', json=text)
result.json()déployer
Une fois le test réussi, arrêtez le conteneur de calcul et attendez que la synchronisation des données soit terminée.
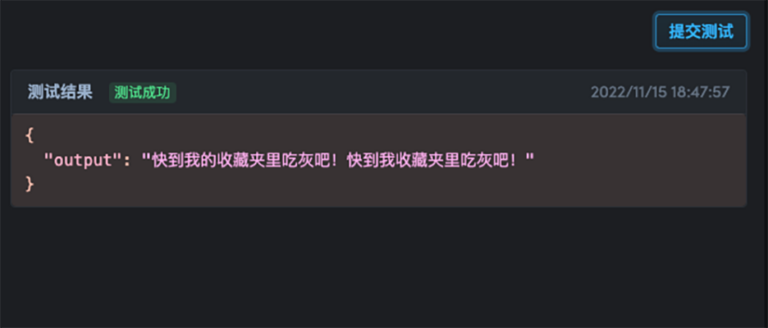
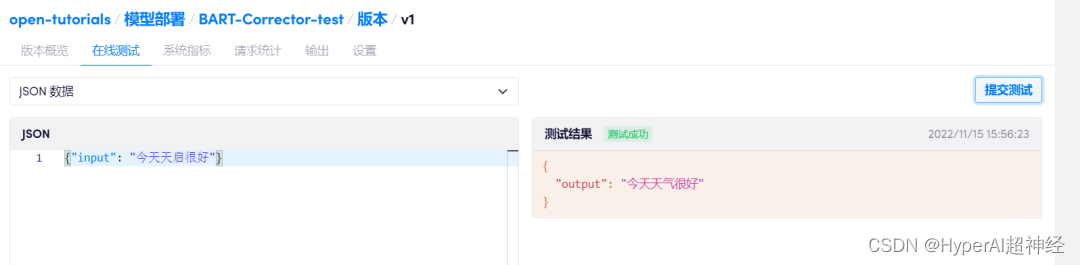
Dans « Conteneur de calcul - Déploiement du modèle », cliquez sur « Créer un nouveau déploiement », sélectionnez la même image que celle utilisée dans le développement, liez ce conteneur de calcul et cliquez sur « Déployer ».Vous pouvez effectuer des tests en ligne.
Pour plus d'informations sur le déploiement du modèle, veuillez consulter :
À ce stade, un modèle de correction d’erreurs de texte chinois prenant en charge les tests en ligne a été formé et déployé !
Pour visualiser et exécuter le didacticiel complet, visitez le lien suivant :
Venez tester votre modèle de correction d'erreurs chinois !
-- sur--
Liens de référence :
[1] https://www.51cto.com/article/715865.html
[2] https://arxiv.org/pdf/1910.1346








