")
Bien que Google Translate existe depuis près de 15 ans, il croit toujours obstinément que les téléphones Android sont très rapides.
La mise à jour majeure la plus récente de GT a été l'introduction d'un système de traduction automatique neuronale (GNMT) en 2016, qui comprend 8 encodeurs et 8 décodeurs pour la traduction en 9 langues.
Non seulement ils séparent les phrases, mais ils séparent également les mots, c'est ainsi qu'ils traitent un mot rare. Lorsque le mot n’est pas dans le dictionnaire, NMT n’a aucune référence. Par exemple, envisagez de traduire un groupe de lettres « Vas3k ». Dans ce cas, GMNT essaie de diviser le mot en morceaux et de récupérer leur traduction.
Mais cela ne peut toujours pas expliquer pourquoi « 卡顿 » a été traduit par « très rapide ». De plus, après que cette traduction soit devenue une blague largement diffusée parmi les ingénieurs nationaux ces derniers jours, la fière correction d'erreurs de crowdsourcing de Google n'a toujours pas réussi à intervenir avec succès dans cette traduction erronée.
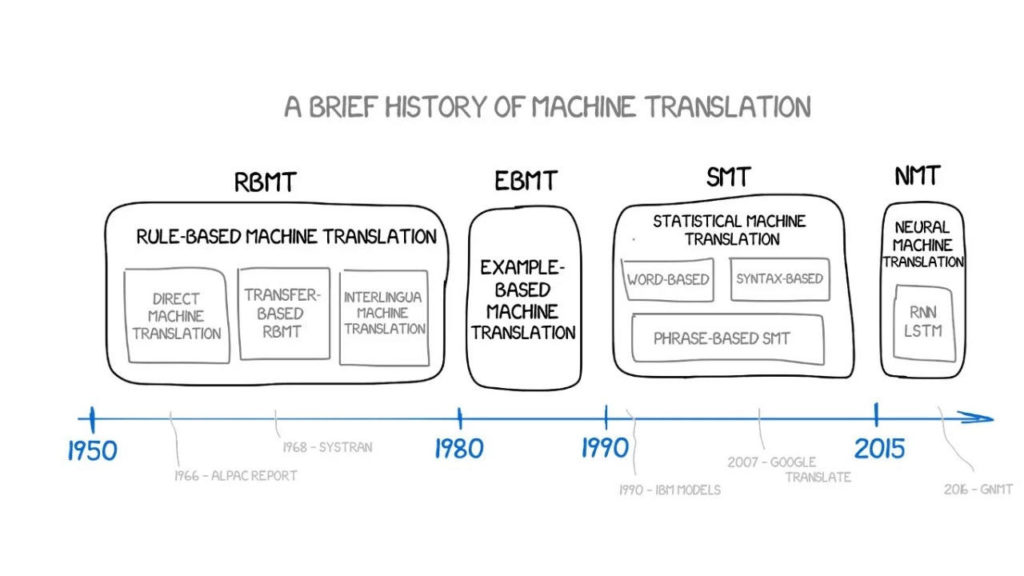
C'est cette petite blague qui nous a donné envie de commencer à faire des recherches sur la traduction automatique. Cet article passera en revue le développement de la traduction automatique au cours des soixante dernières années, y compris les méthodes courantes telles que la traduction automatique basée sur des règles (RBMT), la traduction automatique basée sur des exemples (EBMT), la traduction automatique statistique (SMT), la traduction automatique neuronale (NMT), ainsi que l'analyse des principaux algorithmes de fabricants tels que Google et Yandex.
Vous lisez actuellement la première moitié de cette série d'articles, « Traduction automatique 1933-1984 ».
Les quatre premières décennies de progrès lents
La traduction automatique est apparue pour la première fois en 1933, pendant la guerre froide.
À cette époque, le scientifique soviétique Peter Troyanskii proposa à l'Académie des sciences soviétique de « développer une machine qui pourrait être utilisée pour la traduction de langues et l'impression de textes ». La machine était très simple : juste des cartes en quatre langues différentes, une machine à écrire et une caméra de cinéma à l'ancienne.
L'opérateur prend le premier mot du texte, trouve la carte correspondante, la prend en photo et tape ses caractéristiques morphologiques (nom, pluriel, génitif, etc.) sur une machine à écrire. La machine à écrire traduisait selon certaines de ces caractéristiques et les présentait sur bande magnétique et pellicule photographique.
")
Même s'il pouvait effectuer des traductions simples, il était encore considéré à l'époque comme une invention « inutile ». Malheureusement, Troyanskii a passé 20 ans sur cette invention et est finalement mort d'une angine de poitrine, et l'invention a pris fin. Avant que la machine ne soit découverte par des scientifiques soviétiques en 1965, presque personne dans le monde ne savait qu’elle existait.
Le 7 janvier 1954, au début de la guerre froide, la première véritable machine de traduction de l'histoire, l'IBM 701, fait son apparition au siège d'IBM à New York. Il a traduit avec succès 60 phrases russes en anglais. Il s’agissait de la célèbre expérience Georgetown-IBM.
")
Mais le gadget parfait était de dissimuler un petit détail. Personne n’a mentionné que les exemples traduits ont été soigneusement sélectionnés et testés pour exclure toute ambiguïté. Pour une utilisation quotidienne, ce système n’est pas meilleur qu’un manuel de traduction rapide.
Pourtant, les fondements du traitement moderne du langage naturel ont été créés par des scientifiques, notamment américains, grâce à des expérimentations, des recherches et des développements continus. Tous les moteurs de recherche, filtres anti-spam et assistants personnels d’aujourd’hui sont basés sur cela.
Traduction automatique basée sur des règles (RBMT)
L'idée de la traduction automatique basée sur des règles est apparue pour la première fois dans les années 1970, lorsque des scientifiques ont observé attentivement le travail des traducteurs et ont essayé de forcer les ordinateurs à répéter ces actions. Ces systèmes comprennent :
-
Dictionnaire bilingue (RU -> EN)
-
Chaque langue possède un ensemble de règles linguistiques (par exemple, des noms se terminant par certains suffixes, tels que -heit, -keit, -ung, etc.), qui constituent la partie racine du discours.
Si nécessaire, le système peut également ajouter quelques astuces, telles que des listes de noms, des correcteurs orthographiques et des translittérateurs.
")
PROMPT et Systran sont les exemples les plus célèbres de systèmes RBMT, même s'ils présentent certaines nuances et sous-espèces.
-
Traduction automatique directe
Il s’agit du type de traduction automatique le plus direct. Il traduit les mots du texte un par un et corrige légèrement leur morphologie et coordonne la grammaire pour que l'ensemble du paragraphe paraisse plus précisément traduit. Quant à ces règles de modification, elles sont fixées par des linguistes professionnels.
Cependant, ces règles de traduction échouent parfois et la traduction est médiocre. Bien que les systèmes modernes n’utilisent pas du tout cette règle, elle est très populaire parmi les linguistes modernes.
")
-
Traduction automatique basée sur la structure grammaticale
Par rapport à la traduction littérale, nous déterminons d’abord la structure grammaticale de la phrase, tout comme ce que nos professeurs nous ont enseigné à l’école. Nous analysons ensuite la structure entière plutôt que les mots individuels, ce qui en théorie permet d'obtenir une conversion de l'ordre des mots raisonnablement bonne dans la traduction.
Dans la pratique, cette approche présente toutefois encore des limites. D'une part, cela simplifie les règles grammaticales générales, mais d'autre part, sa traduction devient plus compliquée en raison de l'augmentation des structures de mots par rapport aux mots simples.
")
-
Traduction automatique d'Interlanguage
Dans cette approche, le texte source est converti en une représentation intermédiaire et unifié dans toutes les langues du monde (interlingua). C'est le même dont rêvait Descartes : un métalangage qui suit des règles universelles et transforme la traduction en une simple tâche de « va-et-vient ». Cela permet à Interlingua de traduire dans n'importe quelle langue cible.
En raison de cette conversion, l’Interlingua est souvent confondu avec les systèmes de métalangage basés sur le transfert. La différence est que les règles linguistiques sont spécifiques à chaque langue et à chaque paire de langues, et non à des paires de langues. Cela signifie que nous pouvons ajouter une troisième langue au système interlingua et traduire entre les trois, ce qui est difficile à réaliser dans un système de traduction basé sur la structure grammaticale.
")
Cela semble parfait, mais dans la vraie vie, ce n'est pas le cas. Créer cet interlangage est extrêmement difficile : de nombreux scientifiques ont consacré leur vie entière à l’étudier. Même si elles n’ont pas connu un grand succès, grâce à elles nous disposons aujourd’hui de représentations aux niveaux morphologique, syntaxique et même sémantique.
")
Cependant, la RBMT présente également des avantages, tels que sa précision morphologique (elle ne confond pas les mots), la reproductibilité de ses résultats (tous les traducteurs obtiennent les mêmes résultats) et sa capacité à être adaptée aux domaines d'étude (par exemple, pour enseigner la terminologie aux économistes ou aux ingénieurs).
Même si quelqu'un réussissait à créer un RBMT idéal et que les linguistes continuaient à l'améliorer avec toutes les règles d'orthographe, il y aurait toujours des exceptions auxquelles il ne pourrait pas faire face. Par exemple, les verbes irréguliers en anglais, les préfixes séparables en allemand, les suffixes en russe et les différentes manières dont les gens s'expriment.
Le coût de la réparation de ces différences subtiles serait énorme. N’oubliez pas les homonymes, ce qui signifie que le même mot peut avoir des significations différentes dans des contextes différents, ce qui donne lieu à de nombreuses traductions possibles de la même phrase. Par exemple, lorsque je dis : « J’ai vu un homme utiliser un télescope sur une colline », combien de significations pensez-vous que cela implique ?
La langue ne se développe pas selon un ensemble fixe de règles – un fait que les linguistes apprécient. Au cours des 40 années de la guerre froide, bien que la traduction automatique se soit développée, aucune solution claire n’a été trouvée pour améliorer la précision et la commodité de la traduction.
Par conséquent, RBMT est mort depuis longtemps.
Traduction automatique basée sur des exemples (EBMT)
Dans les années 1980, pour prendre pied le plus rapidement possible dans la mondialisation imminente, le Japon, où peu de gens connaissaient l’anglais, avait un besoin urgent de traduction automatique. Grâce au soutien important des politiques nationales, le Japon est devenu le pays le plus intéressé par la traduction automatique à cette époque.
Étant donné que la traduction automatique basée sur des règles (RBMT) est difficile à traduire de l'anglais vers le japonais, car le processus de traduction nécessite de réorganiser presque tous les mots et implique également de nouveaux mots, cela oblige les Japonais à rechercher de nouvelles idées de traduction.
")
Ainsi, en 1984, Makoto Nagao de l'Université de Kyoto a proposé l'idée de remplacer les traductions répétées par des phrases toutes faites, ce qu'on appelle la traduction automatique basée sur des exemples (EBMT). Plus vous saisissez de cas, plus la traduction sera rapide et précise.
L’émergence de l’idée de l’EBMT a été comme une étincelle qui a enflammé l’inspiration innovante des scientifiques. Cela revêt une grande importance pour le développement de la traduction automatique, même si ce n’est pas encore une innovation révolutionnaire. Mais dans cinq ans, une traduction statistique révolutionnaire émergera sur la base de cela.
Aperçu de l'article suivant
-
L'ère de la traduction automatique des années 1990-2000 dominée par la traduction automatique statistique (SMT) ;
-
La traduction automatique neuronale (NMT) a finalement fait ses débuts en 2015 ;
-
Gameplay avancé de Google et Yandex ;
")
")
Articles historiques (cliquez sur l'image pour lire)
")
Pourquoi le 24 octobre est-il la Journée des programmeurs ? 》
")
"Ce papier est toxique !" 》
")
« Comment expliquer l'intelligence artificielle à vos proches et amis ? »
")
")








