Critique de l'épisode précédent
-
Soixante ans de développement lent de la traduction automatique
-
Traduction automatique basée sur des règles (RBMT)
-
Traduction automatique basée sur des exemples (EBMT)
")
Cliquez sur l'image pour lire la première partie de cet article
Traduction automatique statistique (SMT)
Au début des années 1990, au centre de recherche IBM, un système de traduction automatique a été présenté pour la première fois, qui ne connaissait rien aux règles et à la linguistique. Il analyse le texte de l'image ci-dessous en deux langues et essaie de comprendre les modèles.
")
L'idée est simple et belle. Dans les deux langues, la même phrase est divisée en plusieurs mots puis réassemblée. Cette opération a été répétée environ 500 millions de fois, par exemple, le mot « Das Haus » a été traduit par « maison » contre « bâtiment » contre « construction » et ainsi de suite.
Si le mot source (par exemple, « Das Haus ») est traduit la plupart du temps par « maison », la machine assumera cette signification. Notez que nous n’avons établi aucune règle ni utilisé de dictionnaire – toutes les conclusions ont été tirées par des machines, guidées par des données et la logique. Lors de la traduction, la machine semblait dire : « Si les gens traduisent de cette façon, je le ferai de cette façon aussi. » C'est ainsi qu'est née la traduction automatique statistique.
")
Ses avantages sont qu’il est plus efficace, plus précis et ne nécessite pas de linguiste. Plus nous utilisons de texte, meilleures sont les traductions que nous obtenons.
")
(Traduction statistique de Google : il montre non seulement la probabilité d'utilisation de cette signification, mais fournit également des statistiques sur d'autres significations)
Une autre question :
Comment une machine relie-t-elle les mots « Das Haus » et « bâtiment » — et comment savons-nous que ces traductions sont correctes ?
La réponse est que nous ne le savons pas.
Au départ, la machine suppose que le mot « Das Haus » a la même association avec n’importe quel mot de la phrase traduite. Ensuite, lorsque « Das Haus » apparaît dans d’autres phrases, l’association avec « maison » augmente. Il s’agit de « l’algorithme d’alignement des mots », qui est une tâche typique de l’apprentissage automatique au niveau scolaire.
La machine a besoin de millions de phrases en deux langues pour collecter des informations statistiques pertinentes sur chaque mot. Comment obtenir ces informations linguistiques ? Nous avons décidé d'utiliser les résumés des réunions du Parlement européen et du Conseil de sécurité des Nations Unies - ces résumés sont présentés dans les langues de tous les États membres, ce qui peut faire gagner beaucoup de temps pour la collecte de matériel.
-
SMT basé sur les mots
Au début, les premiers systèmes de traduction statistique décomposaient les phrases en mots. Parce que cette approche était simple et logique, le premier modèle de traduction statistique d’IBM a été appelé « Modèle 1 ».
Modèle 1 : Panier de mots
")
Le modèle 1 utilisait l'approche classique de division en mots et de comptage des statistiques, mais ne prenait pas en compte l'ordre des mots, et la seule astuce consistait à traduire un mot en plusieurs mots. Par exemple, « Der Staubsauger » peut devenir « L’aspirateur », mais cela ne signifie pas qu’il deviendra « L’aspirateur ».
Modèle 2 : Considérer l'ordre des mots dans une phrase
")
Le manque d’ordre des mots est la principale limitation du modèle 1, qui est très important dans le processus de traduction. Le modèle 2 résout ce problème en mémorisant les positions communes des mots dans la phrase de sortie et en les réorganisant dans les étapes intermédiaires pour rendre la traduction plus naturelle.
Alors, ça s'est amélioré ? Non.
Modèle 3 : Ajout de nouveaux mots
")
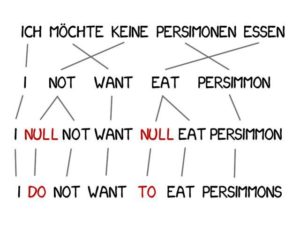
En traduction, il est souvent nécessaire d'ajouter de nouveaux mots pour améliorer la sémantique, comme l'utilisation de « do » en allemand alors que la négation est requise en anglais.L'expression allemande « Ich will keine Persimonen » se traduit en français par « Je ne veux pas de kakis ».
Pour résoudre ce problème, le modèle 3 ajoute deux étapes supplémentaires basées sur les précédentes :
-
Si la machine considère qu'un nouveau mot doit être ajouté, le jeton NULL est inséré ;
-
Choisissez la grammaire ou la paire de mots correcte pour chaque alignement de mots.
Modèle 4 : Alignement des mots
Le modèle 2 prend en compte l’alignement des mots mais ne connaît rien au réordonnancement. Par exemple, les adjectifs échangent souvent leur place avec les noms, et quelle que soit la façon dont l’ordre est mémorisé, il est difficile d’obtenir une traduction subtile sans ajouter de facteurs grammaticaux. Par conséquent, le modèle 4 prend en compte cet « ordre relatif » : si deux mots échangent toujours leur place, le modèle le saura.
Modèle 5 : Correction des erreurs
Le modèle 5 obtient plus de paramètres d’apprentissage et résout le problème du conflit de position des mots. Aussi révolutionnaires qu’ils soient, les systèmes basés sur du texte ne pouvaient toujours pas gérer les homonymes, où chaque mot était traduit d’une seule manière.
Cependant, ces systèmes ne sont plus utilisés car ils ont été remplacés par des traductions plus avancées basées sur des phrases.
-
SMT basé sur des phrases
La méthode repose sur tous les principes de la traduction basée sur les mots : statistiques, réordonnancement et techniques lexicales. Il segmente le texte non seulement en mots mais aussi en phrases, qui sont des séquences continues de plusieurs mots pour être précis.
En conséquence, la machine a appris à traduire des combinaisons de mots stables, ce qui a considérablement amélioré la précision.
")
Le problème est que ces phrases ne sont pas toujours des structures syntaxiques simples, et si l’on est conscient de l’interférence de la linguistique et de la structure des phrases, la qualité de la traduction diminuera considérablement. Frederick Jelinek, un pionnier de la linguistique informatique, a plaisanté un jour : « Chaque fois que j’attaque un linguiste, les performances du système de reconnaissance vocale s’améliorent. »
En plus d’une précision accrue, la traduction basée sur des phrases offre davantage d’options pour les textes bilingues. Pour la traduction basée sur un texte, une correspondance exacte avec la source est cruciale, il est donc difficile d'apporter une valeur ajoutée à une traduction littéraire ou libre.
La traduction basée sur des phrases ne présente pas ce problème et, afin d’améliorer le niveau de traduction automatique, les chercheurs ont même commencé à analyser les sites Web d’information dans différentes langues.
")
Depuis 2006, presque tout le monde utilise cette méthode. Google Translate, Yandex, Bing et d'autres systèmes de traduction en ligne bien connus étaient tous basés sur des phrases avant 2016. Par conséquent, les résultats de ces systèmes de traduction sont soit parfaits, soit dénués de sens, et oui, c'est la caractéristique de la traduction de phrases.
Cette ancienne méthode basée sur des règles produit toujours des résultats biaisés. Google a traduit « trois cents » par « 300 » sans hésitation, mais en fait « trois cents » signifie également « 300 ans ». Il s’agit d’une limitation courante des machines de traduction statistique.
Avant 2016, presque toutes les études considéraient la traduction basée sur des phrases comme la plus avancée, et assimilaient même la « traduction automatique statistique » à la « traduction basée sur des phrases ». Cependant, les gens ont réalisé que Google allait révolutionner toute la traduction automatique.
-
SMT basé sur la syntaxe
Cette méthode doit également être mentionnée brièvement. Bien des années avant l’apparition des réseaux neuronaux, la traduction basée sur la grammaire était considérée comme « l’avenir », mais l’idée n’a pas décollé.
Ses partisans soutiennent qu’elle peut être fusionnée avec des approches fondées sur des règles. Il est possible d'effectuer une analyse grammaticale précise des phrases - en déterminant le sujet, le prédicat et d'autres parties de la phrase, puis en construisant un arbre de phrases. En l'utilisant, les machines apprennent à convertir les unités syntaxiques entre les langues et à traduire par mot ou par phrase. Cela résoudra complètement le problème de « l’erreur de traduction ».
")
L’idée est belle, mais la réalité est très sombre. L'analyse grammaticale fonctionne très mal, même si le problème de sa bibliothèque grammaticale a déjà été résolu (car nous disposons déjà de nombreuses bibliothèques de langues prêtes à l'emploi).
Traduction automatique neuronale (NMT)
En 2014, un article intéressant sur la traduction automatique par réseau neuronal est paru, mais il n'a pas attiré beaucoup d'attention, et seul Google a commencé à approfondir ce domaine. Deux ans plus tard, en novembre 2016, Google a fait une annonce très médiatisée : les règles du jeu de la traduction automatique ont été officiellement modifiées par nous.
L’idée est similaire à la fonctionnalité Prisma qui vous permet d’imiter le style des œuvres d’artistes célèbres. Dans Prisma, les réseaux neuronaux apprennent à reconnaître le style de l’œuvre d’un artiste et les images stylisées qui en résultent peuvent, par exemple, donner à une photo l’apparence d’un Van Gogh. Même si c’est une illusion d’Internet, nous pensons que c’est beau.
")
Et si l’on pouvait transférer un style à une photographie, et si l’on tentait d’imposer un autre langage au texte source ? Le texte serait le « style exact de l’artiste » et nous essaierions de le transmettre tout en préservant l’essence de l’image (en d’autres termes, l’essence du texte).
Imaginez ce qui se passerait si ce type de réseau neuronal était appliqué à un système de traduction ?
Maintenant, en supposant que le texte source soit un ensemble de certaines caractéristiques, cela signifie que vous devez l'encoder, puis demander à un autre réseau neuronal de le décoder en texte dans une langue que seul le décodeur connaît. On ne connaît pas l'origine de ces caractéristiques, mais elles peuvent être exprimées en espagnol.
Il serait intéressant de voir un réseau neuronal encoder uniquement des phrases dans un ensemble spécifique de fonctionnalités, tandis que l’autre ne peut que les décoder en texte. Aucun des deux ne savait qui était l’autre. Ils ne connaissaient chacun que leur propre langue. Ils étaient étrangers l’un à l’autre mais pouvaient néanmoins se coordonner.
")
Cependant, il y a aussi un problème ici : comment trouver et définir ces caractéristiques. Quand on parle de chiens, leurs caractéristiques sont évidentes, mais qu'en est-il du texte ? Vous savez, il y a 30 ans, les scientifiques ont essayé de créer un code linguistique universel, mais ils ont finalement échoué.
Cependant, nous disposons désormais d’un apprentissage profond, qui peut très bien résoudre ce problème car il existe à cette fin. La principale différence entre l’apprentissage profond et les réseaux neuronaux classiques réside dans sa capacité précise à rechercher ces caractéristiques spécifiques, quelle que soit leur nature. Si le réseau neuronal est suffisamment grand et dispose de milliers de cartes vidéo, il peut extraire ces caractéristiques du texte.
En théorie, nous pourrions transmettre les caractéristiques obtenues à partir des réseaux neuronaux aux linguistes, afin qu’ils puissent s’ouvrir des perspectives complètement nouvelles.
Une question est : quel type de réseau neuronal peut être appliqué à l’encodage et au décodage de texte ?
Nous savons que les réseaux neuronaux convolutifs (CNN) ne fonctionnent actuellement que sur des images basées sur des blocs de pixels indépendants, mais il n'y a pas de blocs indépendants dans le texte, et chaque mot dépend de l'environnement qui l'entoure, tout comme le langage et la musique. Les réseaux neuronaux récurrents (RNN) constitueront un choix optimal car ils se souviennent de tous les résultats précédents — dans notre cas, des mots précédents.
Et les réseaux neuronaux récurrents sont déjà utilisés aujourd’hui, comme la reconnaissance vocale RNN-Siri de l’iPhone (il analyse l’ordre des sons, le suivant dépend du précédent), les invites clavier (se souvenir du précédent, deviner le suivant), la génération de musique et même les chatbots.
")
En deux ans, les réseaux neuronaux ont complètement dépassé le travail de traduction des 20 années précédentes. Il a réduit les erreurs d’ordre des mots de 50%, les erreurs de vocabulaire de 17% et les erreurs grammaticales de 19%. Le réseau neuronal a même appris à gérer des problèmes tels que les homonymes dans différentes langues.
Il est remarquable que les réseaux neuronaux soient capables de réaliser une traduction véritablement directe, éliminant ainsi complètement le besoin de dictionnaires. Lors de la traduction entre deux langues non anglaises, il n’est pas nécessaire d’utiliser l’anglais comme langue intermédiaire. Auparavant, si vous vouliez traduire le russe en allemand, vous deviez d’abord traduire le russe en anglais, puis traduire l’anglais en allemand. Cela augmenterait le taux d’erreur des traductions répétées.
")
Google Traduction (depuis 2016)
En 2016, ils ont développé un système appelé Google Neural Machine Translation (GNMT) pour la traduction en neuf langues. Il comprend 8 encodeurs et 8 décodeurs, ainsi qu'une connexion réseau pouvant être utilisée pour la traduction en ligne.
")
Non seulement ils séparent les phrases, mais ils séparent également les mots, c'est ainsi qu'ils traitent un mot rare. Lorsque le mot n’est pas dans le dictionnaire, NMT n’a aucune référence. Par exemple, envisagez de traduire un groupe de lettres « Vas3k ». Dans ce cas, GMNT tente de diviser le mot en morceaux et de récupérer leur traduction.
Astuce : Google Traduction pour les traductions de sites Web dans le navigateur utilise toujours l'ancien algorithme basé sur les phrases. D'une manière ou d'une autre, Google ne l'a pas mis à jour, et les différences sont notables par rapport à la version en ligne.
Cependant, le Google Translate actuellement utilisé dans le navigateur pour la traduction de sites Web utilise toujours un algorithme basé sur des phrases. D'une certaine manière, Google ne l'a pas mis à niveau à cet égard, mais cela nous permet également de voir la différence par rapport au mode de traduction traditionnel.
Google utilise un mécanisme de crowdsourcing en ligne où les gens peuvent choisir la version qu'ils pensent être la plus correcte, et si de nombreux utilisateurs l'aiment, Google continuera à traduire la phrase de cette manière et la marquera avec un badge spécial. C'est très utile pour les phrases courtes et quotidiennes comme « Allons au cinéma » ou « Je t'attends ».
Traduction Yandex (depuis 2017)
Yandex a lancé en 2017 un système de traduction neuronale, qui utilise l'algorithme CatBoost qui combine des réseaux neuronaux avec des méthodes statistiques.
Cette méthode peut compenser efficacement les lacunes de la traduction par réseau neuronal : une distorsion de la traduction est susceptible de se produire pour les phrases qui n'apparaissent pas fréquemment. Dans ce cas, une simple traduction statistique peut rapidement et facilement trouver le mot correct.
")
L’avenir de la traduction automatique ?
Les gens sont toujours enthousiasmés par le concept de « poisson de Babel » – la traduction vocale instantanée. Google a fait un pas dans cette direction avec ses Pixel Buds, mais la réalité est que ce n’est certainement pas parfait car vous devez lui faire savoir quand commencer à traduire et quand se taire et écouter. Mais même Siri ne peut pas faire ça.
Il y a une difficulté qui doit être explorée : tout apprentissage est limité au corpus de l’apprentissage automatique. Même si nous pouvons concevoir des réseaux neuronaux plus complexes, ils sont actuellement limités à l’apprentissage à partir du texte fourni. Les traducteurs humains peuvent compléter le corpus pertinent en lisant des livres ou des articles pour garantir des résultats de traduction plus précis. C’est là que la traduction automatique est loin derrière la traduction humaine.
Mais puisque les traducteurs humains peuvent le faire, en théorie, les réseaux neuronaux peuvent le faire aussi. Et il semble que certaines personnes aient déjà essayé de réaliser cette fonction en utilisant des réseaux neuronaux. Autrement dit, il utilise la langue qu’il connaît pour lire dans une autre langue afin d’acquérir de l’expérience, puis la réinjecte dans son propre système de traduction pour une utilisation ultérieure. Attendons de voir.
Lectures complémentaires
")
Traduction automatique statistique
Par Philipp Koehn
Suivez le compte public et répondez « Traduction automatique statistique » pour télécharger la version PDF
")
")








